基于互信息校准点云数据长尾分布的语义分割方法
1.本发明涉及语义分割技术领域,尤其是涉及基于互信息校准点云数据长尾分布的语义分割方法。
背景技术:
2.大规模的3d场景分割,旨在为每个点分配语义类别标签,在近期得到了广泛而积极的研究,并且是对于各种挑战性和有意义的应用(例如自动驾驶,机器人技术和位置识别)。为了有效地完成此类任务,我们需要将模糊的形状与模糊的部分区分开,并考虑具有不同外观的对象。例如,在嵌入空间中没有很好地编码结构信息和判别特征,则可以轻松地将相邻的椅子和桌子混淆并分组为一个统一的类。
3.现有的方法采用与2d图像中典型的卷积神经网络类似的设计理念,主要是为了学习更丰富的局部结构并捕获点云的更广泛的上下文信息而提出的。尽管在公共数据集上已经取得了一系列成果,但仍然存在一些问题以待解决。
4.首先,尽管在深度学习模型中获得了全局表示,但尚未明确利用点云之间的复杂全局关系,这对于更好的分割至关重要。例如,墙壁和门的区域通常是无法区分的,并且桌子和椅子的部件可能会受到它们相似结构的影响。有必要增强特征表示的判别能力以进行点级识别。elgs方法从2d图像任务中借鉴了通道和空间注意机制的方法。mprm方法在不对2d图像任务中的通道和空间注意机制进行结构更改的情况下用1
×
1conv替换了卷积。pt方法和pct方法设计了用于点云处理的转换器层。两者都利用自注意算子代替神经网络中的卷积算子。但是,所有上述方法都只能使用点数有限的整个点云的子云进行操作,无法处理大型3d场景点云。其次,现有的3d方法很少关注3d现实世界数据本身的固有属性。一方面,从现实世界中收集的点云通常表现出不平衡或长尾标签分布,其中几个常见类别在数量上绝对占主导地位,从而导致模型偏向这些主导类别并忽略数量较少的类别。例如,几乎在每个室内场景中都会出现墙壁和地板等类,而在室外场景中,道路和建筑物等类则占据了大部分位置。另一方面,3d数据是固有的,没有遮挡或比例尺模糊,因此对象的点数在3d场景中不变。相反,在2d图像中,由于不同的相机距离和角度,同一物体将被成像为不同数量的像素。每个对象的占用像素/点数(表示为占用率)在2d图像上是不可预测的,但可以从3d场景中可靠地预测。最近的randla
‑
net方法有效地分割了大型点云,而忽略了现实世界中的长尾分布和不平衡问题点云数据。
技术实现要素:
5.为解决现有技术的不足,通过引入用于大规模3d场景分割的相邻区域细模块以及旨在解决网络训练的平衡问题的两个损失函数,提出了一种新颖的框架,在满足处理大规模点云特征输入的同时,实现避免大规模点云场景语义分割中的类间不一致和类内不确定的目的,本发明采用如下的技术方案:
6.基于互信息校准点云数据长尾分布的语义分割方法,包括如下步骤:
7.s1,输入大规模3d点云数据;
8.s2,点云特征提取;
9.s3,获取支持大规模输入的空间位置注意力;
10.s4,获取扩展的通道位置注意力;
11.s5,特征融合,将支持大规模输入的空间位置注意力和扩展的通道位置注意力输出的特征图进行拼接,再进行注意力特征融合后,进行上采样,使其输出的点云规模与输入的点云规模相当;
12.s6,构建联合损失函数,强制神经网络学习输入点的固有属性:
[0013][0014]
表示联合成本函数,表示失衡调整损失函数,用于进行不平衡和长尾标签分布的失衡调整,表示占用率回归损失函数,用于回归每个点所属类别的占用大小,表示交叉熵损失函数,用于最终语义分割预测;
[0015]
s7,点云分割结果输出。
[0016]
进一步地,所述s3,包括如下步骤:
[0017]
s31,从特征提取网络中获取n
×
c’个输出特征图a,并通过将a馈送到两个不同的1
×
1卷积层,得到不同的特征图b和c,n表示点数,c’表示维度;
[0018]
s32,对b和a的转置之间进行矩阵乘法,即attention操作,起到特征增强的效果,得到c
’×
1输出矩阵d,d上的注意力值公式表示如下:
[0019][0020]
下标i和j分别表示点i和点j,a
j
表示特征图a中的第j个点的位置,b
i
表示特征图b中的第i个点的位置;
[0021]
s33,将d的转置进行转换为另外两个1
×
1卷积层,作为瓶颈转换表示:
[0022]
f
j
=relu(ln(d
j
))
[0023]
其中ln表示归一化层,而relu是激活函数;
[0024]
s34,将图d和c之间的矩阵乘法,即attention操作,起到特征增强的效果,表示为:
[0025][0026]
s35,在求和过程中,使用两个比例参数α和β加权聚合后的特征图e和f,其中α和β是初始化为0的可学习参数,我们生成表示为的空间注意图g,即attention操作,起到特征增强的效果:
[0027]
g
j
=αe
j
+βf
j
+a
j
。
[0028]
进一步地,所述s4,包括如下步骤:
[0029]
s41,在转置的a和原始a之间执行矩阵乘法,在这里,我们得到一个c
×
c通道注意图b;
[0030]
s42,使用b和原始a之间的矩阵乘法来传播特征图c,利用attention操作,起到特征增强的效果,表示为:
[0031][0032]
其中,m是通道维,下标i,j表示通道i和通道j,c
j
表示特征图c中的第j个位置;
[0033]
s43,定义跨通道算子以捕获相邻通道关系,用内核大小为h的1
×
1卷积实现,然后,本地跨通道交互,即attention操作,起到特征增强的效果,表示为:
[0034][0035]
其中,w是一个h
×
m参数矩阵,h表示跨步时的相邻通道(即内核大小),σ是s型函数(即sigmoid函数)。
[0036]
s44,设置权重参数λ,并生成表示为的频道关注图e:
[0037]
e
j
=λc
j
+d
j
+a
j
。
[0038]
进一步地,所述s6中的失衡调整损失函数采用最小化softmax交叉熵:
[0039][0040]
其中,θ表示神经网络的参数,(x,y)~d表示训练数据,其中x表示数据,y表示监督信息,d表示分布,p
θ
(y∣x)表示未知分布;
[0041]
设f
y
(x;θ)是softmax函数之前的结果,即logit,因此得到:
[0042][0043]
其中,f
y
(x;θ)表示神经网络的当前的参数分布,k表示候选语义类别数;
[0044]
根据观察的经验,例如在会议室中,某些类别(例如桌椅)经常同时出现;而其他班级(例如沙发和立柱)则倾向于相互避免。为描述这种情况,我们需要一个数量来表示“在同一个3d场景中,两个类别共存的概率是它们随机遭遇的概率的多少倍?”,我们采用逐点互信息pmi来描述这种现象,因为它是度量同时采样的两个随机变量之间的关系的数量,表示为:
[0045][0046]
其中,p(y1)、p(y2)分别是类别y1、y2的频率,如果pmi远大于0,则两个类别倾向于同时出现,否则,倾向于相互避免;
[0047]
根据以上讨论,逐点互信息(pmi)是一种有效的措施,实际上揭示了类之间的内部关系。因此,我们让模型直接适合pmi,以便网络学习更多基本知识,我们对pmi进行建模并表述为:
[0048][0049]
使用softmax函数将其重新规范化,表示为:
[0050]
log p
θ
(y∣x)~f
y
(x;θ)+log p(y)
[0051]
为概括起见,添加一个调整因子τ,得到的不平衡调整损失函数表示为:
[0052][0053]
我们提出的不平衡调整损失对每个logit应用了依赖于标签的偏移;通过将pmi嵌入场景语义之间并将其引入分段任务中,可以帮助网络减少类间混淆问题。
[0054]
进一步地,所述调整因子τ=1。
[0055]
进一步地,所述s6中的占用率回归损失函数在2d图像中,由于不同的相机距离和角度,对象将被成像为不同数量的像素,这导致每个对象的占用像素/点数(表示为占用率)是不可预测的,相反,3d数据是固有的,没有遮挡或比例尺模糊,因此对象的点数在3d场景中不变,这意味着对象可以包含固定数量的点,结果,相同的标记点往往具有稳定的数量,我们称之为占用规模;对于室内和室外场景,我们使用大小为4cm和6cm的子网格划分点云,每个小网格中的点仅由一个带有标签(重心)的点表示,此步骤类似于将点云体素化的操作,我们可以从每个点云中采样固定数量的点10^5作为输入,对于场景中未标记的点,这些点不会放入损失函数中进行计算,因此,o
i
的设置可以帮助网络纠正训练过程中数据不平衡的问题,此外,对于我们实验中采用的点云数据集,从任何角度看,原始设置是每个标记点只有一个标签,而未标记点则没有标签;对于第k个语义类中的第i个点,预测一个正值o
i
来指示当前语义类所占据的点数,o
i
的平均值用作当前语义类的预计占用量,为了进行更可靠的预测,我们将对点数而不是原始值进行回归:
[0056][0057]
其中,n
k
是第k个语义类中的点数,k表示语义类别数,占用率回归损失返回到每个点的类的占用率大小,即每个3d类对象的固有属性,占用率回归损失在训练过程中调节每个语义类别的比例,这可以通过有效防止类别内部不一致来使网络受益。
[0058]
进一步地,所述s2中,将输入的点云数据描述为其为具有f维的原始无序点集,n是点的数量,p
i
是特征向量,包含坐标、颜色、标签。
[0059]
进一步地,所述s2中,对输入的点云数据进行数据增强,包括随机打乱点的顺序、随机旋转点云进行数据增强、随机旋转空间坐标和法向量。
[0060]
进一步地,所述s43中,将h设置为3。
[0061]
进一步地,所述s44中,λ=0.1,此时,效果最好。
[0062]
本发明的优势和有益效果在于:
[0063]
本发明提出的相邻区域细化模块,包含两种类型的注意力块,大规模支持空间注意力,以并行方式预先形成的扩展通道注意力,它可以一次处理大量点(例如105,而传统方法最多一次性处理104数量的输入点云),而不会增加计算复杂度和时间成本;本发明提出两个损失函数,共同利用3d场景中固有的长尾标签分布,指导网络解决类内不一致和类间混淆;本发明可以以端到端的方式对网络进行培训,并且在效率和有效性方面都优于传统的方法;本发明提出的模型和训练损失函数,能在大规模场景点云分割上都达到更好的效果。
附图说明
[0064]
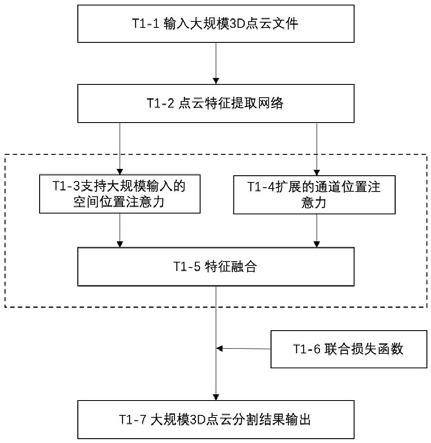
图1是本发明的方法流程图。
[0065]
图2是本发明中支持大规模输入的空间位置注意力模块示意图。
[0066]
图3是本发明中扩展的通道位置注意力模块示意图。
具体实施方式
[0067]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0068]
如图1所示,基于互信息校准点云数据长尾分布的语义分割方法,包括如下步骤:
[0069]
步骤t1
‑
1输入大规模3d点云文件。
[0070]
输入数据的格式,数据的存储形式为txt格式,关键字为:xyz,rgb,label,关键字索引的数据维度分别为:xyz(40960,3),rgb(40960,3),label(40960,1)。
[0071]
步骤t1
‑
2点云特征提取网络。
[0072]
我们用randla
‑
net作为点云特征提取网络来处理大规模点云,为每个点生成丰富的语义表示。将输入数据描述为其为具有f维的原始无序点集,其中n是点的数量,p
i
是特征向量,并且可能包含3d空间坐标(x,y,z),颜色(r,g,b),和标签(label)。我们将f=3设置为仅使用3d坐标作为输入。考虑到在现实世界中点云中的样本数量可能非常庞大,由于每组点集中的每个点对其他点的权重分配/影响都非常小,因此允许每个点都参与计算将导致高昂的计算成本和梯度消失的问题。训练时,首先对输入点云进行随机降采样,数量至40960个点,然后设定训练epoch为250步,batch size大小为8,学习率为0.001,基于梯度下降的momentum设置为0.9,优化器为adam。在训练过程中,设置每个点云的邻居节点数量为16。点云数据输入网络之后,在训练过程中需要对其进行数据增强,数据增强包括:随机打乱点的顺序、随机旋转点云进行数据增强、随机旋转x,y,z空间坐标和法向量。
[0073]
步骤t1
‑
3支持大规模输入的空间位置注意力。
[0074]
如图2所示,从特征提取网络中获取n
×
c’(n表示点数,c’表示维度)个输出特征图a,并将其馈送到两个不同的1
×
1卷积层,得到特征图b和c。然后,对b和a的转置之间进行矩阵乘法,即attention操作,起到特征增强的效果,得到c
×
1输出矩阵d。d上的注意力值公式表示如下:
[0075][0076]
下标i和j分别表示点i和点j,a
j
表示特征图a中的第j个点的位置,b
i
表示特征图b中的第i个点的位置。
[0077]
然后,将d的转置转换为另外两个1
×
1卷积层,作为瓶颈转换表示:
[0078]
f
j
=relu(ln(d
j
))
[0079]
其中ln表示归一化层,而relu是激活函数。
[0080]
将图d和c之间的矩阵乘法,即attention操作,起到特征增强的效果,表示为:
[0081][0082]
此后,在求和过程中,使用两个比例参数α和β加权聚合后的特征图e和f,其中α和β是初始化为0的可学习参数。我们生成表示为的空间注意图g,即attention操作,起到特征增强的效果:
[0083]
g
j
=αe
j
+βf
j
+a
j
[0084]
步骤t1
‑
4扩展的通道位置注意力
[0085]
如图3所示,我们直接在转置的a和原始a之间执行矩阵乘法。在这里,我们得到一个c
×
c通道注意图b,然后,我们使用b和原始a之间的矩阵乘法来传播特征图c,利用attention操作,起到特征增强的效果,表示为:
[0086][0087]
其中m是通道维,下标i,j表示通道i和通道j,c
j
表示特征图c中的第j个位置。然后,我们定义跨通道算子以捕获相邻通道关系,用内核大小为h的1
×
1卷积实现。然后,本地跨通道交互,即attention操作,起到特征增强的效果,可以表示为:
[0088][0089]
其中w是一个h
×
m参数矩阵,h表示跨步时的相邻通道(即内核大小),我们将h设置为3,σ是一个s型函数(即sigmoid函数)。
[0090]
之后,我们设置权重参数λ=0.1并生成表示为的频道关注图e:
[0091]
e
j
=λc
j
+d
j
+a
j
[0092]
步骤t1
‑
5特征融合。
[0093]
这一步将步骤t1
‑
3支持大规模输入的空间位置注意力和步骤t1
‑
4扩展的通道位置注意力输出的特征图先拼接起来,然后通过一层1
×
1conv,来进行注意力特征融合,随后在通过三层1
×
1conv(卷积层)对点云进行上采样,使其输出的点云规模与输入的点云规模相当。
[0094]
步骤t1
‑
6联合损失函数。
[0095]
为了共同利用3d现实世界数据的固有性质,我们设计了两个有效的损失来强制(引导)网络学习输入点的固有属性,即失衡调整损失和占用率回归损失。网络受过训练,以使联合成本函数最小化:
[0096][0097]
其中是在实际3d场景中进行不平衡和长尾标签分布的失衡调整损失函数。是占用回归损失函数,用于回归每个点所属类别的占用大小。用于最终语义分割预测的常规交叉熵损失。
[0098]
首先对进行分析及定义,从现实世界中收集的3d点云通常呈现出不平衡或长尾的标签分布。在这种情况下,与高频类别相比,训练期间采样的批次几乎没有机会对低频类
别进行采样,这很容易导致模型忽略它们,但是实际上,我们通常更关心低频的识别结果。考虑到有k个候选语义类别,训练数据为(x,y)~d,x表示数据,y表示监督信息,d表示分布,对于未知分布p
θ
(y|x),通常,一个最小化softmax交叉熵:
[0099][0100]
θ表示神经网络的参数,我们假设f
y
(x;θ)(神经网络的当前的参数分布)是softmax函数之前的结果,即logit,因此,我们得到:
[0101][0102]
根据观察的经验,例如在会议室中,某些类别(例如桌椅)经常同时出现;而其他班级(例如沙发和立柱)则倾向于相互避免。为描述这种情况,我们需要一个数量来表示“在同一个3d场景中,两个类别共存的概率是它们随机遭遇的概率的多少倍?”。我们采用逐点互信息(pmi)来描述这种现象,因为它是度量同时采样的两个随机变量之间的关系的数量,表示为:
[0103][0104]
其中,p(y1)、p(y2)分别是类别y1、y2的频率,如果pmi远大于0,则意味着这两个类别倾向于同时出现,相反,它们倾向于相互避免。
[0105]
根据以上讨论,逐点互信息(pmi)是一种有效的措施,实际上揭示了类之间的内部关系。因此,我们让模型直接适合pmi,以便网络学习更多基本知识。我们对pmi进行建模并表述为:
[0106][0107]
然后,我们使用softmax函数将其重新规范化,表示为:
[0108]
log p
θ
(y| x)~f
y
(x;θ)+log p(y)
[0109]
为概括起见,我们添加一个调整因子τ,我们将τ设置为1,得到的不平衡调整损失表示为:
[0110][0111]
我们提出的不平衡调整损失对每个logit应用了依赖于标签的偏移。通过将pmi嵌入场景语义之间并将其引入分段任务中,可以帮助网络减少类间混淆问题。
[0112]
其次对进行分析及定义。在2d图像中,由于不同的相机距离和角度,对象将被成像为不同数量的像素,这导致每个对象的占用像素/点数(表示为占用率)是不可预测的。相反,3d数据是固有的,没有遮挡或比例尺模糊,因此对象的点数在3d场景中不变。这意味着对象可以包含固定数量的点。结果,相同的标记点往往具有稳定的数量,我们称之为占用规模。
[0113]
对于室内和室外场景,我们使用大小为4cm和6cm的子网格划分点云,让每个小网格中的点仅由一个带有标签(重心)的点表示。此步骤类似于将点云体素化的操作。我们可以从每个点云中采样固定数量的点10^5作为输入,在我们的实验设置中,该点的数量为
40960。对于场景中未标记的点,这些点不会放入损失函数中进行计算。因此,oi的设置可以帮助网络纠正训练过程中数据不平衡的问题。此外,对于我们实验中采用的点云数据集,从任何角度看,原始设置是每个标记点只有一个标签,而未标记点则没有标签。
[0114]
对于第k个语义类中的第i个点,我们预测一个正值o
i
来指示当前语义类所占据的点数。然后,o
i
的平均值将用作当前语义类的预计占用量语义类。为了进行更可靠的预测,我们将对数而不是原始值进行回归,并用以下表达式表示:
[0115][0116]
其中n
k
是第k个语义类中的点数。提议的占用率回归损失返回到每个点的类的占用率大小,即每个3d类对象的固有属性。占用率回归损失在训练过程中调节每个语义类别的比例,这可以通过有效防止类别内部不一致来使网络受益。
[0117]
步骤t1
‑
7大规模3d点云分割结果输出。将模型预测的点云语义分割结果输出。
[0118]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1