社交网络的下一个兴趣点的推荐方法
本发明涉及技术领域,具体涉及一种社交网络的下一个兴趣点的推荐方法。
背景技术:
下一个兴趣点(poi)推荐是基于位置的社交网络的信息的提要的重要方面,其目的是根据用户的签到记录来预测用户接下来要访问的兴趣点。与一般的兴趣点推荐相比,社交网络的数据更加稀疏,因为一个人的用户行为很少,因此了解用户的下一个兴趣点的推荐会更加困难;此外,社交网络的下一个兴趣点的预测必须依据当前用户的位置,具有连续性。
近些年来人们对下一个兴趣点推荐进行了大量的研究,rnn应用尤为广泛,并且在下一个兴趣点的推荐中性能表现尤为突出。但是,rnn自身耗时长,不能并行计算的缺陷,所以在长期依赖的问题上性能表现不好。
技术实现要素:
本发明所要解决的是社交网络的下一个兴趣点推荐因数据稀疏而导致推荐困难的问题,提供一种社交网络的下一个兴趣点的推荐方法。
为解决上述问题,本发明是通过以下技术方案实现的:
社交网络的下一个兴趣点的推荐方法,包括步骤如下:
步骤1、先从社交网络中采集用户的原始数据,提取原始数据中用户、用户访问的兴趣点、以及用户访问的兴趣点的时间形成用户的一个签到记录,并将每个签到记录进行语义空间映射,得到每个签到记录特征矢量;再将用户的所有签到记录特征矢量组成用户的轨迹特征向量;
步骤2、先构建用户的签到时间差矩阵,该签到时间差矩阵的第i行第j列为用户的第j个签到记录中的用户访问的兴趣点的时间减去用户的第i个签到记录中的用户访问的兴趣点的时间,其中i,j∈[1,n],n为用户的签到记录的个数;再将用户的签到时间差矩阵进行语义空间映射,得到用户的签到时间差特征矩阵;
步骤3、将用户的轨迹特征向量和用户的签到时间差特征矩阵同时送入到transformer模型的encoder层,在transformer模型的encoder层中,利用用户的签到时间差特征矩阵分清用户的轨迹特征向量的各个签到记录特征矢量的先后顺序,并在此基础上捕获用户的轨迹特征向量中每个签到记录特征矢量与其他签到记录特征矢量的关系,得到用户的偏好兴趣点特征矩阵;其中用户的偏好兴趣点特征矩阵由用户的偏好兴趣点特征向量组成,每个用户的偏好兴趣点特征向量包括用户访问该偏好兴趣点的所有签到记录特征矢量;
步骤4、将一天划分为不同的时间窗口,并将用户的偏好兴趣点特征矩阵中的用户的偏好兴趣点特征向量按照其用户访问的该偏好兴趣点的时间划分到对应的时间窗口中,由此得到每个时间窗口所对应的用户的偏好兴趣点特征向量;
步骤5、为每个时间窗口分配一个权重,并基于该权重计算用户的偏好兴趣点状态特征矢量;其中用户的偏好兴趣点状态特征矢量pu为:
式中,
步骤6、先从社交网络的所有兴趣点中选出与用户距离小于设定距离阈值的兴趣点,得到初筛兴趣点集合;再计算初筛兴趣点集合中每个兴趣点的流行度,并从初筛兴趣点集合选出与流行度大于预设流行度阈值的兴趣点,得到候选兴趣点集合;
步骤7、计算候选兴趣点集合中每个兴趣点的评分,并将评分排在前k位的兴趣点推荐给用户;其中k为设定值,每个候选兴趣点的评分
式中,pu表示用户的偏好兴趣点状态特征矢量,et表示当前时间点进行语义空间映射所得到的当前时间特征矢量,eli表示候选兴趣点进行语义空间映射所得到的候选兴趣点特征矢量,[·]t表示转置。
上述步骤4中,根据用户的行为将一天划分为12个时间窗口,并使得每个时间窗口内的签到记录的数量是相同的。
上述步骤5中,时间窗口内的用户的偏好兴趣点特征向量的数量越多,该时间窗口所分配的权重越大;时间窗口内的用户的偏好兴趣点特征向量的数量越少,该时间窗口所分配的权重越小。
上述步骤6中,兴趣点的流行度等于该兴趣点一天被访问的次数除以所有兴趣点一天被访问的次数。
与现有技术相比,本发明具有如下特点:
1、基于transformer模型提取的长期偏好是复杂多样的,并行计算能力强,且对用户的长期行为的依存关系表现良好;
2、将获得的多样的长期偏好划分成多个时间窗口,从而能够精确地了解用户的不同时间范围的用户兴趣;
3、利用注意力机制来测量各种输入的相关性,从而提取与用户下一步行为相关的偏好,降低了计算复杂性。
附图说明
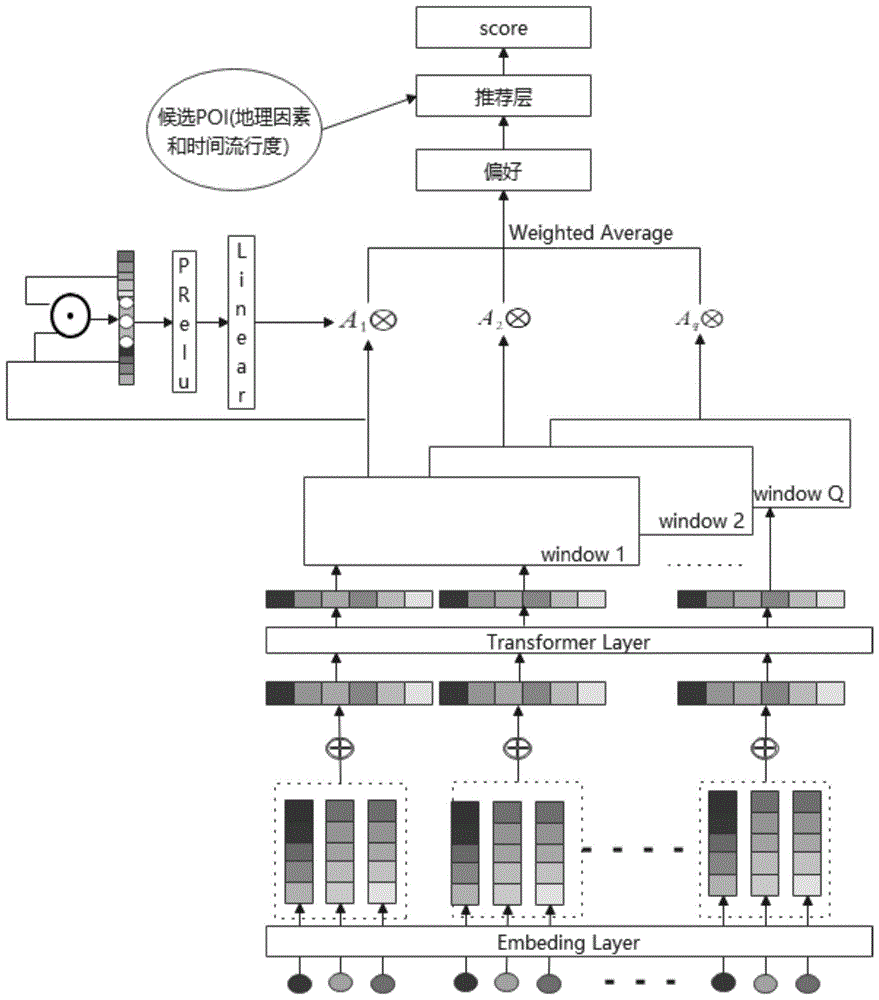
图1为社交网络的下一个兴趣点的推荐方法的原理图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实例,对本发明进一步详细说明。
一般来说,用户过去的历史轨迹都显示出用户的偏好。首先,由于用户在不同的时间显示出用户不同的偏好。例如,用户在工作日期间,会偏好于公司周围附近的poi;在周末,用户会偏向于家的附近的poi。同时用户在一天中的不同时间范围内也呈现出不同的兴趣偏好。例如,在下午茶时间,用户可能选择咖啡馆这类的休闲的poi;在晚饭时间,用户可能吃完晚饭,可能选择去酒吧这类poi。所以,用户在不同时间呈现出不同的偏好。因此本发明采用transformer模型来学习用户复杂多样的长期偏好。其次,由于用户的近期偏好又是呈动态偏好的,用户的历史轨迹所涉及的时空上下文信息对用户的下一步行为起着至关重要的作用,因此本发明将获得的偏好划分成多个时间窗口,从而获取不同时间范围的兴趣偏好。再者,由于不同的用户在同一时间段的兴趣偏好是不同的,而且对于同一用户在不同的时间段的兴趣偏好也会有所不同,因此本发明要针对用户在时间窗口要赋予不同的权重。最后,将候选poi融入推荐层,根据地理影响因素和候选poi的时间流行度以及用户的近期偏好来计算用户可能去下一个poi的可能性。
具体来说,本发明所提出的社交网络的下一个兴趣点的推荐方法,如图1所示,其包括步骤如下:
步骤1、先从社交网络中采集用户的原始数据,提取原始数据中用户、用户访问的兴趣点、以及用户访问的兴趣点的时间形成用户的一个签到记录,并将每个签到记录进行语义空间映射,得到每个签到记录特征矢量;再将用户的所有签到记录特征矢量组成用户的轨迹特征向量。
用户u的签到记录为<u,l,t>,其中u表示用户,l表示用户u访问的兴趣点,t表示用户u访问的兴趣点l的时间。用户u的轨迹序列h={(u,l1,t1),(u,l2,t2),…,(u,ln,tn)},其中n为签到记录的个数。
步骤2、先构建用户的签到时间差矩阵,该签到时间差矩阵的第i行第j列为用户的第j个签到记录中的用户访问的兴趣点的时间减去用户的第i个签到记录中的用户访问的兴趣点的时间,其中i,j∈[1,n],n为用户的签到记录的个数;再将用户的签到时间差矩阵进行语义空间映射,得到用户的签到时间差特征矩阵。
签到时间差矩阵δt是签到序列的时间度量,相对较短的时间通常表示两个签入活动强烈相关。签到时间差矩阵
步骤3、将用户的轨迹特征向量和用户的签到时间差特征矩阵同时送入到transformer模型的encoder层,在transformer模型的encoder层中,利用用户的签到时间差特征矩阵分清用户的轨迹特征向量的各个签到记录特征矢量的先后顺序,并在此基础上捕获用户的轨迹特征向量中每个签到记录特征矢量与其他签到记录特征矢量的关系,得到用户的偏好兴趣点特征矩阵。
transformer模型ashishvaswan等人在2017年提出了一种新的简单的网络架构,由encoder层和decoder层两部分组成,其完全基于注意力机制,完全消除了重复和卷积,在机器翻译任务中,性能方面有明显的优势,具有很高的并行性,并且所需的训练时间明显更少。本发明只利用transformer模型的encoder层,并没有利用到transformer的decoder层。由于encoder层的注意力网络不具备位置关系,因此将用户的轨迹特征向量作为encoder层的序列嵌入,将用户的签到时间差特征矩阵作为encoder层的相对位置嵌入,在transformer模型的encoder层中,其自注意力层通过捕获用户的轨迹序列中与其他签到记录的关系来学习每个签到记录的深层表示,其前馈反向层使得用户签到的偏好兴趣点表示的表达能力更强,更加能够表示用户签到与上下文中其他签到之间的作用关系,则encoder层输出的是一个用户的偏好兴趣点特征矩阵
步骤4、将一天划分为不同的时间窗口,并将用户的偏好兴趣点特征矩阵中的用户的偏好兴趣点特征向量按照其用户访问的该偏好兴趣点的时间划分到对应的时间窗口中,由此得到每个时间窗口所对应的用户的偏好兴趣点特征向量。
由于用户的偏好兴趣点特征向量
步骤5、为每个时间窗口分配一个权重,并基于该权重计算用户的偏好兴趣点状态特征矢量;其中用户的偏好兴趣点状态特征矢量pu为:
式中,
由于用户的一天的兴趣分布会有所不同,因此每个时间窗口会有不同的权重,本实施例根据以下原则进行权重设定:时间窗口内的用户的偏好兴趣点特征向量的数量越多,该时间窗口所分配的权重越大;时间窗口内的用户的偏好兴趣点特征向量的数量越少,该时间窗口所分配的权重越小。
步骤6、先从社交网络的所有兴趣点中选出与用户距离小于设定距离阈值的兴趣点,得到初筛兴趣点集合;再计算初筛兴趣点集合中每个兴趣点的流行度,并从初筛兴趣点集合选出与流行度大于预设流行度阈值的兴趣点,得到候选兴趣点集合。
根据兴趣点(poi)的地理因素和流行度两层过滤得出一批新的距离用户较近并且流行度很高的候选poi的集合。首先,根据poi的距离来剔除一些距离较远的poi,由于poi的访问符合幂律分布,即poi间的距离越小,用户访问的可能性就越高,因此我们根据用户当前的地理位置,过滤掉距离用户超过距离阈值如五公里以外的poi,则得到初筛兴趣点集合。然后,根据poi的流行度来剔除一些不是很热门的poi,由于poi的访问次数越高,说明该poi流行度就越高,因此我们根据poi的流行度滤掉流行度较低的poi,得到候选兴趣点集合。其中兴趣点的流行度等于该兴趣点一天被访问的次数除以所有兴趣点一天被访问的次数。
步骤7、计算候选兴趣点集合中每个兴趣点的评分,并将评分排在前k位的兴趣点推荐给用户;其中k为设定值,每个候选兴趣点的评分
式中,pu表示用户的偏好兴趣点状态特征矢量,et表示当前时间点进行语义空间映射所得到的当前时间特征矢量,
本发明着重解决的是下一个poi数据稀疏的问题。首先,利用transformer的encoder层获取用户的偏好兴趣点的集中表示;其次,将获得的用户偏好兴趣点的集中表示送到划分好的时间窗口中去;接着,针对同一用户在不同的时间窗口的兴趣偏好分布有所不同,在不同的时间窗口中赋予不同的权重,根据得到的权重来获取用户的偏好兴趣点状态;最后,根据地理因素信息和商家流行度从所有poi过滤出候选poi,并基于用户的偏好兴趣点状态计算候选poi的评分,将top_k个poi推荐给用户。
需要说明的是,尽管以上本发明所述的实施例是说明性的,但这并非是对本发明的限制,因此本发明并不局限于上述具体实施方式中。在不脱离本发明原理的情况下,凡是本领域技术人员在本发明的启示下获得的其它实施方式,均视为在本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!