基于多注意力残差特征融合的医学图像超分辨率重建方法
本发明涉及一种基于多注意力残差特征融合的医学图像超分辨率重建方法。
背景技术:
近年来,深度卷积神经网络在单幅图像上的超分辨率上取得了非常好的效果,图像超分辨率的一种常见方法是基于实例的方法,该方法利用高分辨率图像和低分辨率图像的信息,生成近似原始高分辨率图像的超分辨率版本。在医学图像上也存在许多使用超分辨率的方法,医学影像的超分辨率重建有助于提高基于计算机辅助的临床医学诊断和疾病定量分析的准确性和客观性,所以,对需要的医学图像进行超分辨率重建是有必要的。
现有技术存在的缺陷为:现有的大部分超分网络都是基于卷积神经网络进行训练的,网络对输入图片的特征是平等处理的,网络虽然学习到了输入图像的特征,但是这些特征并没有差异,从而会降低超分网络的表征能力。并且现有的超分辨率方法主要专注于设计更深的网络结构,却很少挖掘层间特征的相关性,难以充分利用整个网络中的局部特征信息,从而会降低深度神经网络的学习能力。
技术实现要素:
为了克服现有的不足,本发明针对上述的两个问题进行了改进,提出了一种基于多注意力残差特征融合的医学图像超分辨率重建方法,联合了通道注意力机制和空间注意力机制两个模块,让网络对输入图片的特征进行加权重处理,从而解决输入特征被平等处理而导致网络表征能力不足的问题;提出了残差注意力特征融合模块(raff),将神经网络中局部的特征进行融合,再加上全局的特征融合,可以更充分地利用整个网络中的局部残差特征,从而解决深度神经网络过深而网络学习能力不足的问题。
本发明解决其技术问题所采用的技术方案是:
一种基于多注意力残差特征融合的医学图像超分辨率重建方法,联合通道注意力和空间注意力模块,将输入图片的特征从多方面加以权重,再加上局部和全局的残差特征融合并构建了新颖的超分辨率重建方法,包括以下步骤:
1)训练样本的处理:
为了使所提超分辨率网络模型再训练过程中有对应的高分辨率图像(即hr)和低分辨率图像(即lr),本发明先对512x512分辨率的高清医学图像原图数据集做2倍和4倍的双三次下采样,得到256x256分辨率和128x128分辨率的低分辨率数据集。
2)联合多注意力机制:
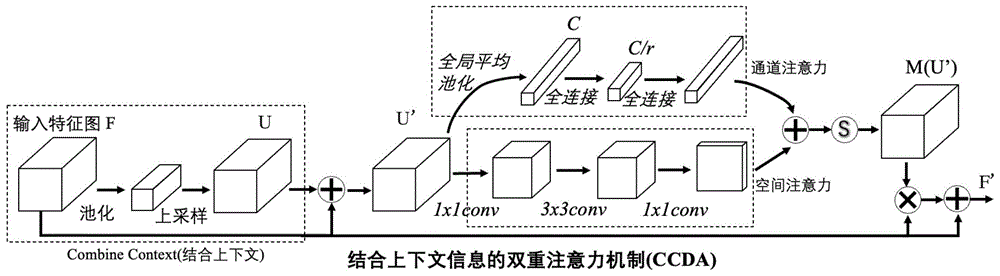
本发明提出了一种多注意力的超分辨率重建网络。当提取到输入图像的特征h×w×c后,会分别进行channelattention和spatialattention的处理,最后将通道注意力权重和空间注意力权重相结合得到一个三维的attentionmapm(u’)。本发明在注意力机制前还添加了一个上下文融合模块combinecontext,目的是让输入图像的特征拥有更多的图像上下文信息,具体操作为:输入一张特征图f:h×w×c,先经过一个池化层变为h/r×w/r×c,再经过上采样变为特征图u:h×w×c,此时h×w上每个像素点都含有周围像素点的信息,见公式(1):
u′=upsample(pool(f))+f(1)
然后再将u’分别输入到两个注意力模块。在通道注意力模块中,先进行全局平均池化(gap)聚合featuremap在每个通道的维度,得到了1×1×c大小的特征图,紧接着用一个全连接层将特征通道数降为c/r,再用一个全连接层将其变为1×1×c,得到了通道注意力的权重特征图mc(u′),计算过程如公示(2):
mc(u′)=bn(fc2(fc1(avgpool(u′))))(2)
在空间注意力模块中,先用1x1的卷基层将特征通道压缩一半,再紧接一个3x3的卷基层和一个1x1的卷积层将特征变为h×w×1,得到了空间注意力的权重特征图ms(u′),计算过程如公式(3):
然后将两个注意力分支中获取到的权重特征图融合起来,由于这两张注意力特征图的形状不一样,于是先将两者扩展到h×w×c,然后再将它们逐项求和,求和后,取一个sigmoid函数σ,将数值控制到0到1范围内,得到既有通道注意力权重也有空间注意力权重的三维注意力特征图m(u’),如公式(4):
m(u′)=σ(mc(u′)+ms(u′))(4)
再将该三维注意力图与最开始的输入特征f相乘,然后再将其添加到f上,得到带有双重注意力权重的特征图f’,图1的整个过程称为ccda(combinecontextdualattention),如公式(5):
3)局部和全局残差特征融合:
该网络框架主要有三个模块构成:head、body和tail。
3.1)、headmodule:使用一个卷基层提取输入图像的初始特征图,可以描述为公式(6):
f0=h(ilr)(6)
其中ilr表示输入图像,f0表示提取到的浅层特征,h表示提取输入图浅层特征的卷积操作;
3.2)、bodymodule:本模块是整个网络的重点部分,包含了g个ccda模块,但是直接堆加模块而加深网络深度的话,难以充分利用整个网络中的局部特征信息,从而会降低深度神经网络的学习能力。于是本发明在网络结构中加入了局部特征融合,将每一个ccda模块的输出都直接和最后一个ccda模块的输出进行汇聚,这样最后的特征图不仅拥有网络最终输入的结果还会有网络中间结果的信息。此外,在bodymodule的最后还加入了一个全局的特征融合,用于融合f0和fdf的特征,还具有加速训练收敛的作用,该过程描述为公式(7):
fdf=hraff(f0)=f0+bg(fg-1(…))+bg-1(fg-2(…))+…+b0(f0)(7)
其中fdf表示提取到的深层特征,hraff表示本发明提出的残差注意力特征融合模块(residualattentionfeaturefusion),其中包含了g个ccda模块,bg表示第g个堆叠的ccdablock。
3.3)、tailmodule:包含上采样模块和重建模块,以head和body的输出作为输入,输出重建图像,该部分描述为公式(8):
其中isr表示最终超分辨率重建的图像,hup表示上采样模块,hrec表示重建模块,ilr是输入给神经网络的低分辨率图。
最后用l1损失函数对该网络模型进行优化,给定一个训练集
其中,θ表示该网络的参数集,并采用随机梯度下降的方法对损失函数进行了优化。
本发明的技术构思为:当一张低分辨率图像输入给网络模型,首先在head模块进行浅层特征的提取,下一步进入body模块进行深层特征的提取,该模块中包含了多个ccda模块,每个ccda模块中有结合上下文信息机制、通道注意力机制和空间注意力机制,可以让网络更加有效地提取到图像的深层特征。最后进入tail模块,进行图像的上采样和最终的超分辨率图像重建。
本发明方法的内容主要包括:1)联合了通道注意力机制和空间注意力机制两个模块,让网络对输入图片的特征进行加权重处理,从而解决输入特征被平等处理而导致网络表征能力不足的问题。2)提出了残差注意力特征融合模块(raff),将神经网络中局部的特征进行融合,再加上全局的特征融合,可以更充分地利用整个网络中的局部残差特征,从而解决深度神经网络过深而网络学习能力不足的问题。
本发明的有益效果主要表现在:1、该新颖的融合残差特征的多注意力卷积神经网络模型可以有效地对医学图像进行超分辨率重建。2、该网络模型联合了通道注意力和空间注意力模块,从而解决了神经网络的输入特征被平等处理而导致网络表征能力不足的问题。3、本发明中的残差注意力特征融合模块(raff),可以更充分地利用整个网络中的局部残差特征,从而解决深度神经网络过深而网络学习能力不足的问题,可以提高较深的超分辨率网络的图像超分重建性能。
附图说明
图1是所提网络中的ccda模块,包含了通道注意力和空间注意力的融合机制。
图2是所提超分网络的整体框架以及各部分组件的简介,其中,①表示headmodule,一层卷积提取输入图像的浅层特征;②表示bodymodule,包含g个ccda模块、局部特征融合、全局特征融合;③表示tailmodule,上采样模块和重建模块。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1和图2,一种基于多注意力残差特征融合的医学图像超分辨率重建方法,联合通道注意力和空间注意力模块,将输入图片的特征从多方面加以权重,再加上局部和全局的残差特征融合并构建了新颖的超分辨率重建方法,包括以下步骤:
1)训练样本的处理:
为了使所提超分辨率网络模型再训练过程中有对应的高分辨率图像(即hr)和低分辨率图像(即lr),本发明先对512x512分辨率的高清医学图像原图数据集做2倍和4倍的双三次下采样,得到256x256分辨率和128x128分辨率的低分辨率数据集。
2)联合多注意力机制:
本发明提出了一种多注意力的超分辨率重建网络,如图1所示。当提取到输入图像的特征h×w×c后,会分别进行channelattention和spatialattention的处理,最后将通道注意力权重和空间注意力权重相结合得到一个三维的attentionmapm(u’)。本发明在注意力机制前还添加了一个上下文融合模块combinecontext,目的是让输入图像的特征拥有更多的图像上下文信息,具体操作为:输入一张特征图f:h×w×c,先经过一个池化层变为h/r×w/r×c,再经过上采样变为特征图u:h×w×c,此时h×w上每个像素点都含有周围像素点的信息,见公式(1):
u′=upsample(pool(f))+f(1)
然后再将u’分别输入到两个注意力模块。在通道注意力模块中,先进行全局平均池化(gap)聚合featuremap在每个通道的维度,得到了1×1×c大小的特征图,紧接着用一个全连接层将特征通道数降为c/r,再用一个全连接层将其变为1×1×c,得到了通道注意力的权重特征图mc(u′),计算过程如公示(3):
mc(u′)=bn(fc2(fc1(avgpool(u′))))(2)
在空间注意力模块中,先用1x1的卷基层将特征通道压缩一半,再紧接一个3x3的卷基层和一个1x1的卷基层将特征变为h×w×1,得到了空间注意力的权重特征图ms(u′),计算过程如公式(3):
然后将两个注意力分支中获取到的权重特征图融合起来,由于这两张注意力特征图的形状不一样,于是先将两者扩展到h×w×c,然后再将它们逐项求和,求和后,取一个sigmoid函数σ,将数值控制到0到1范围内,得到既有通道注意力权重也有空间注意力权重的三维注意力特征图m(u’),如公式(4):
m(u′)=σ(mc(u′)+ms(u′))(4)
再将该三维注意力图与最开始的输入特征f相乘,然后再将其添加到f上,得到带有双重注意力权重的特征图f’,图1的整个过程称为ccda(combinecontextdualattention),如公式(5):
3)局部和全局残差特征融合:
网络的整体框架如图2所示,该网络框架主要有三个模块构成:head、body和tail。
3.1)、headmodule:使用一个卷基层提取输入图像的初始特征图,可以描述为公式(6):
f0=h(ilr)(6)
其中ilr表示输入图像,f0表示提取到的浅层特征,h表示提取输入图浅层特征的卷积操作;
3.2)、bodymodule:本模块是整个网络的重点部分,包含了g个ccda模块(即图1的过程),但是直接堆加模块而加深网络深度的话,难以充分利用整个网络中的局部特征信息,从而会降低深度神经网络的学习能力。于是本发明在网络结构中加入了局部特征融合,将每一个ccda模块的输出都直接和最后一个ccda模块的输出进行汇聚,这样最后的特征图不仅拥有网络最终输入的结果还会有网络中间结果的信息。此外,在bodymodule的最后还加入了一个全局的特征融合,用于融合f0和fdf的特征,还具有加速训练收敛的作用,该过程描述为公式(7):
fdf=hraff(f0)=f0+bg(fg-1(…))+bg-1(fg-2(…))+…+b0(f0)(7)
其中fdf表示提取到的深层特征,hraff表示本发明提出的残差注意力特征融合模块(residualattentionfeaturefusion),其中包含了g个ccda模块,bg表示第g个堆叠的ccdablock。
3.3)、tailmodule:包含上采样模块和重建模块,以head和body的输出作为输入,输出重建图像,该部分可以描述为公式(8):
其中isr表示最终超分辨率重建的图像,hup表示上采样模块,hrec表示重建模块,ilr是输入给神经网络的低分辨率图。
最后用l1损失函数对该网络模型进行优化,给定一个训练集
其中,θ表示该网络的参数集,并采用随机梯度下降的方法对损失函数进行了优化。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!