1.本发明涉及网络信息技术领域,具体涉及一种基于销量与用户偏好的外卖平台餐厅排序方法。
背景技术:2.外卖平台上的餐厅排序效果会直接影响用户体验以及餐厅订单销量,构建一个简单、操作性强且响应快速的排序算法是平台的需求所在。在排序过程中,近期餐厅的销量与用户的偏好是重要的因素,如何充分利用这两组数据,构建一个简单合理的排序方法是平台需要重点考虑的。
技术实现要素:3.为了解决上述问题,本发明使用数据统计、奇异值分解(svd)等技术,提出了一种基于销量与用户偏好的外卖平台餐厅排序方法。该方法首先由运营人员对数据库中餐厅表的菜系类别进行维护补充,然后对近期的订单进行分析与建模,最后根据用户位置、浏览平台时间、餐厅销量、用户偏好等因素对餐厅进行排序。
4.为了达到上述目的,本发明采用如下技术方案:
5.一种基于销量与用户偏好的外卖平台餐厅排序方法,包括如下步骤:
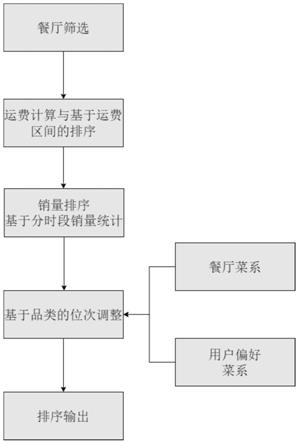
6.步骤1,餐厅数据处理
7.菜系类别是餐厅的重要的特征,也是为用户做餐厅排序推荐时需要考虑的一个重要因素,所以需要提前标记好餐厅的所属菜系类别;一家餐厅根据其主要销售的菜品,有多个菜系标签;
8.步骤2订单数据分析
9.读取平台的历史订单数据,数据中需要包括以下字段:订单id、下单时间、用户id、餐厅id和餐厅菜系;
10.2.1分时段销量统计
11.对读取的历史订单数据以小时为单位,分时段统计各餐厅的订单销量;
12.2.2计算用户菜系偏好
13.使用矩阵分解算法,通过对每一个用户和菜系类别生成一个隐向量,将用户和菜系定位到隐向量表示的空间上,与用户距离相近的菜系表明用户更感兴趣,因此给该类别菜系的餐厅分配更高的曝光率;本发明使用svd算法提前计算出用户对于各菜系的偏好,选择每个用户最偏好的三个菜系类别,供后续排序使用;
14.步骤3餐厅排序
15.当用户使用排序功能时,执行以下操作:
16.3.1餐厅筛选
17.餐厅筛选分为两步,首先获取用户的实时或者输入的位置信息,根据位置信息只保留用户所在城市的餐厅;然后,过滤掉停业、下架状态的餐厅,只保留当日营业的餐厅;
18.3.2运费计算与基于运费区间的排序
19.根据用户的位置,对3.1中筛选出的餐厅根据平台的运费规则,计算餐厅与用户产生的运费;
20.从低到高设置若干运费区间,然后对餐厅按照其所处的运费区间进行标记;
21.使用弱序关系对餐厅按照标记好的运费区间,由低到高进行排序;
22.3.3销量排序
23.近似用户浏览平台的整点时间,使用弱序关系再次对3.2的各运费区间内的餐厅,按照2.1中对应的整点销量数据按照销量由高到低进行排序,得到的结果记做销量排序;销量排序看作是对于每个运费区间内餐厅的一种重排,但是整体上保持较低运费区间的餐厅完全排在较高运费区间的餐厅之前;
24.3.4基于品类的位次调整
25.读取2.2中提前计算好的用户偏好菜系类别,然后对3.3销量排序的结果以每连续的20个餐厅作为一个排序块进行划分;对一个排序块中的20家餐厅,将餐厅的菜系类别与用户的偏好类别一致的餐厅,在这20家餐厅中置顶优先展示,置顶时保持被置顶餐厅的先后次序不变;以此类推,对所有的排序块执行相同的操作;位次调整使得用户偏好菜系的餐厅能够被展示在更靠前的位置,有利于提高点击率与订单转化率;
26.3.5排序输出
27.将最终调整后的排序结果输出并展示;
28.步骤4数据更新
29.考虑到时效性与季节性因素对于订单的影响,需要对于2.1、2.2中的排序每周更新一次。
30.与现有技术相比较,本发明具备如下优点:
31.1)本发明综合考虑餐厅分时段订单销量与用户的个人偏好等因素对外卖平台的餐厅进行排序;
32.2)本发明只需提前处理好订单销量数据与用户偏好数据,排序时使用的数据较少,用户端的加载相应速度较快;
33.3)使用机器学习中的svd算法计算用户对所有菜系(而非所有餐厅)的偏好,很好的解决了传统推荐算法中存在的矩阵稀疏问题;
34.4)展示的餐厅排序列表会每小时更新,不同用户因其偏好不同看到的排序结果也有明显的差别,避免了餐厅展示的千篇一律;
35.5)当用户使用排序功能时,从用户周边当前时段销量最高的餐厅中优先选择其喜欢菜系的餐厅进行展示,有助于提高订单转化率;而后,展示其他菜系的高销量餐厅,提供多样化选择的同时避免过拟合的情况。
附图说明
36.图1为本发明方法流程图。
具体实施方式
37.下面结合和具体实施方式对本发明作进一步详细说明。
38.如图1所示,本发明一种基于销量与用户偏好的外卖平台餐厅排序方法,包括如下步骤:
39.步骤1,餐厅数据处理
40.菜系类别是餐厅的一个很重要的特征,也是为用户做餐厅排序推荐时需要考虑的一个重要因素,所以需要提前标记好餐厅的所属菜系类别。通常来看,主要可以分为以下类别:甜品奶茶,粤港澳沪,川香麻辣,日韩料理,早点小吃,汉堡快餐,西式正餐等。菜系类别过多会导致后续矩阵计算中存在稀疏的问题,建议10个左右。一家餐厅可以根据其主要销售的菜品,有多个标签。
41.步骤2订单数据分析
42.考虑到季节和时效的因素,只读取过去两周的平台订单数据。数据中需要包括以下字段:订单id、下单时间、用户id、餐厅id和餐厅菜系。
43.2.1分时段销量统计
44.对读取的历史订单数据以小时为单位,统计过去两周以每个小时前30分钟与后30分钟的时间段内,所有各餐厅的订单销量。例如,中午12点的订单销量计算过去两周每天11:31至12:30时间段内的所有餐厅各自的累计销量。该数据需要提前计算好,供排序时使用。
45.2.2计算用户菜系偏好
46.矩阵分解算法是一种非常经典的排序推荐算法,通过对每一个用户和菜系类别生成一个隐向量,将用户和菜系定位到隐向量表示的空间上,与用户距离相近的菜系表明用户更感兴趣,进而在排序过程中,可以将这些菜系的餐厅给予一个更高的曝光量。奇异值分解svd(singular value decomposition)是矩阵分解中的一种常用方法。本发明使用svd算法提前计算出用户对于菜系的偏好。
47.对已读取到的订单数据进行处理,生成用户id与餐厅菜系的共现矩阵m,共现矩阵m的行代表用户,共现矩阵m的列代表菜系,统计过去两周历史订单中用户i在菜系标签为j的餐厅中的下单次数作为元素mij的取值。假设矩阵m是一个m
×
n的矩阵,则可以将其分解为m=u∑v
t
,其中u是m
×
m的正交矩阵,y是n
×
n的正交矩阵,∑是m
×
n的对角阵。取对角阵∑中较大的k个元素作为隐含特征,删除∑的其他维度以及u和v中对应的维度,矩阵m被分解为m≈m
′
=u
m
×
k
∑
k
×
k
v
k
×
nt
,至此完成了隐性量维度为k的矩阵分解。
48.从矩阵m
′
中,选择每个用户偏好值最大的三个菜系作为该用户的偏好菜系。该数据需要提前计算好,供排序时使用。
49.步骤3餐厅排序
50.当用户使用排序功能时,执行以下操作:
51.3.1餐厅筛选
52.餐厅筛选分为两步,首先获取用户的实时或者输入的位置信息,根据位置信息只保留用户所在城市的餐厅。然后,过滤掉停业、下架等状态的餐厅,只保留当日营业的餐厅。
53.3.2运费计算与基于运费区间的排序
54.根据用户的位置,对3.1中筛选出的餐厅根据平台的运费规则,计算餐厅与用户产生的运费。
55.从低到高设置若干运费区间,如区间a=[a,b),区间b=[b,c),区间c=[c,d)等。
然后对餐厅按照其所处的运费区间进行标记。
[0056]
弱序关系(weak ordering relation)是一种二元关系,在排序领域有广泛应用。一个二元关系被称作弱序关系如果满足以下两个条件,
[0057]
不对称:
[0058]
负传递:
[0059]
使用弱序关系(weak ordering relation)对餐厅按照标记好的运费区间,由低到高进行排序。
[0060]
3.3销量排序
[0061]
近似用户浏览平台的整点时间,如11:31至12:30使用整点12。使用弱序关系(weak ordering relation)再次对3.2的各运费区间内的餐厅,按照2.1中对应的整点销量数据按照销量由高到低进行排序,得到的结果记做销量排序。销量排序可以看作是对于每个运费区间内餐厅的一种重排,但是整体上保持较低运费区间的餐厅完全排在较高运费区间的餐厅之前。
[0062]
3.4基于品类的位次调整
[0063]
读取2.2中提前计算好的用户偏好菜系类别。然后对3.3中产生的排序结果以每连续的20个餐厅作为一个排序块进行划分。对一个排序块中的20家餐厅,将餐厅的菜系类别与用户的偏好类别一致的餐厅,在这20家餐厅中置顶优先展示,置顶时保持被置顶餐厅的先后次序不变。以此类推,对所有的排序块执行相同的操作。位次调整使得用户偏好菜系的餐厅可以被展示在更靠前的位置,有利于提高点击率与订单转化率。
[0064]
3.5排序输出
[0065]
将最终调整后的排序结果输出展示。
[0066]
步骤4数据更新
[0067]
考虑到时效性与季节性等因素对于订单的影响,需要对于2.1、2.2中的排序每周更新一次。