一种面向实时数据库的写快照断点续传的方法与流程
1.本发明属于实时数据库技术领域,特别是涉及一种面向实时数据库的写快照断点续传的方法。
背景技术:
2.随着我国经济的不断增长和信息化社会的建设,信息化技术的在电力行业的应用越来越普及,发电企业建立了以实时数据库为平台的信息体系,以实现对设备运行的远程实时监控、性能诊断、事故预警,提高发电质量,保证发电设备安全、可靠运行。
3.电力信息系统对实时数据的采集和存储有着强实时作业的要求,更加注重数据采集的完整性和一致性。由于工控系统网络的复杂性、硬件设备问题或者实时数据库系统自身的原因,时常会出现某个时段向实时数据库传输数据中断,如果处理不当就会造成数据的丢失,严重影响实时数据的完整性。
4.现有解决方案采用数据通讯监测和数据缓存技术,在数据通讯恢复后将缓存数据文件通过写历史的方式重新写入实时数据库,没有考虑数据文件中的数据测点特性,不对数据文件做任何处理。而实时数据库在组织历史数据时,通常采用链表的方式将同一标签的所有数据按照的时间戳先后顺序安排在若干个历史数据存档文件中,当向实时数据库补写历史数据时,实时数据库会根据补录标签数据的时间戳将数据值插入对应标签的历史记录中,同时重新调整历史数据存档文件。如果同一标签存在多个数据值需要补录,实时数据库会对该标签进行多次写历史操作,反复对历史存档文件进行调整,严重影响实时数据库的性能。
技术实现要素:
5.为了解决上述问题,本发明提供了一种面向实时数据库的写快照断点续传的方法,解决了电力实时数据传输中间件向实时数据库传输快照数据中断后自动断点续传的问题,在保证数据完整性的同时提高了数据补写的性能。
6.本发明采用如下技术方案来实现的:
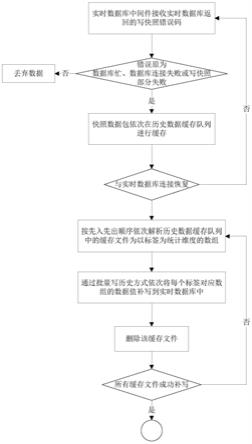
7.一种面向实时数据库的写快照断点续传的方法,包括以下步骤:
8.步骤1:实时数据库中间件接收实时数据库返回的写快照错误码,判断错误原因,获取符合条件的写入失败的快照数据包,丢弃不符合条件的快照数据包;
9.步骤2:符合条件的快照数据包依次在数据缓存模块的历史数据缓存队列进行缓存;
10.步骤3:待实时数据库中间件与实时数据库连接恢复后,历史数据缓存解析模块按照先入先出顺序依次解析历史数据缓存队列中的缓存文件为以标签为统计维度的数组;
11.步骤4:后台写历史伺服线程通过批量写历史方式依次将每个标签对应数组的数据值补写到实时数据库中;
12.步骤5:当一个缓存文件中所有数据被成功补写,删除该缓存文件,返回步骤3,直
至所有缓存文件被成功补写。
13.实时数据库中间件接收实时数据库返回的写快照错误码,判断错误原因,获取符合条件的写入失败的快照数据包,所述条件指的是写快照失败原因是数据库忙、数据库连接失败或写快照部分失败。
14.所述历史数据缓存队列为先进先出队列结构。
15.符合条件的快照数据包依次在数据缓存模块的历史数据缓存队列进行缓存,数据缓存的存储介质为磁盘文件,配置每个缓存文件的最大字节数,缓存文件默认大小为50m,超过该最大字节数时自动切换缓存文件。
16.步骤3中待实时数据库中间件与实时数据库连接恢复后,历史数据缓存解析模块按照先入先出顺序依次解析历史数据缓存队列中的缓存文件为以标签为统计维度的数组,具体包括以下步骤:
17.步骤31:待实时数据库中间件与实时数据库连接恢复后,历史数据缓存解析模块按照先入先出顺序依次解析历史数据缓存队列中的缓存文件,获取单个缓存文件中所有标签,重复标签只获取一次;
18.步骤32:为每个标签建立一个可变长数组;
19.步骤33:获取每个标签在该缓存文件中的所有数据值;
20.步骤34:按快照时间先后顺序数据值添加到该标签对应的可变长数组中。
21.本发明至少具有以下有益的技术效果:
22.本发明提供的方法通过自动监测实时数据库写快照的返回结果,当向实时数据库传输快照数据中断后自动缓存写入失败的数据,并在实时数据库连接恢复后,自动向实时数据库进行数据补写,保证了电力信息系统采集数据的完整性;
23.本发明提供的方法在向实时数据库补写数据前,根据标签重新整合缓存数据,针对同一标签采用批量写历史的方法补写数据,从而极大减少了实时数据库调用补写历史数据方法的次数及对历史存档文件调整的次数,进一步提高了断点续传过程中向实时数据库补写数据的性能。
附图说明
24.图1是本发明实施例的基本流程示意图;
25.图2为本发明实施例步骤3的流程示意图;
26.图3为本发明方法中以标签为统计维度的数组示意图。
具体实施方式
27.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
28.图1是本发明实施例的基本流程示意图,如图1所示的一种面向实时数据库的写快照断点续传的方法,包括以下步骤:
29.步骤1:实时数据库中间件接收实时数据库返回的写快照错误码,判断错误原因,获取符合条件的写入失败的快照数据包,丢弃不符合条件的快照数据包。
30.所述条件指的是写快照失败原因是数据库忙、数据库连接失败或写快照部分失败。
31.常见的不符合条件的错误原因为:标签在实时数据库不存在,时标/数据类型错误,这种情况需要在实时数据库重新配置标签或修正时标/数据类型。
32.步骤2:符合条件的快照数据包依次在数据缓存模块的历史数据缓存队列进行缓存。
33.所述历史数据缓存队列为先进先出(fifo)队列结构。数据缓存的存储介质为磁盘文件,可配置每个缓存文件的最大字节数,缓存文件默认大小为50m,超过该最大字节数时自动切换缓存文件。
34.步骤3:待实时数据库中间件与实时数据库连接恢复后,历史数据缓存解析模块按照先入先出顺序依次解析历史数据缓存队列中的缓存文件为以标签为统计维度的数组,如图2所示,具体包括以下步骤:
35.步骤31:待实时数据库中间件与实时数据库连接恢复后,历史数据缓存解析模块按照先入先出顺序依次解析历史数据缓存队列中的缓存文件,获取单个缓存文件中所有标签,重复标签只获取一次;
36.步骤32:为每个标签建立一个可变长数组;
37.步骤33:获取每个标签在该缓存文件中的所有数据值;
38.步骤34:按快照时间先后顺序数据值添加到该标签对应的可变长数组中。如图3所示,为一个标签对应的可变长数组示意图,每个数据值由三部分组成:时戳(timestamp)、质量(quality)和数据值(value)。timestamp1<timestamp2<timestamp3<
…
<timestampn,数组按照数据值中时戳先后顺序将该标签数据值整合在数组中,以便后续一次性批量写入该标签所有数据值。n为该标签在该数据文件中存在的数据值个数,每个标签会有所差异。
39.步骤4:后台写历史伺服线程通过批量写历史方式依次将每个标签对应数组的数据值补写到实时数据库中;
40.步骤5:当一个缓存文件中所有数据被成功补写,删除该缓存文件,返回步骤3,直至所有缓存文件被成功补写。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1