一种食品供应链危害物预测方法及装置
1.本技术涉及时间序列预测领域,尤其涉及一种食品供应链危害物预测方法及装置。
背景技术:
2.食品供应链由原料供应商、生产商、销售商、消费者等复杂的环节组成,其跨越的地域范围广,对各环节的质量要求很高。一旦出现食品安全问题,不仅会使整个供应链遭受损失,而且会造成恶劣的社会影响。因此透明度较低的多层食品供应链是否安全成为人们关注的重点。
3.随着物联网技术的发展,人们可以获得食品供应链上越来越多的信息。近来,机器学习尤其是深度学习方法的应用越来越广泛。循环神经网络(recurrent neural network,rnn)作为深度学习领域中的重要神经网络,为序列数据的分析提供了更加有效的解决方法。目前结合机器学习或深度神经网络的食品供应链安全预测系统越来越多,但是这些食品安全预测模型有较大的潜在风险。
4.深度学习模型可以有效的进行预测和辅助决策,在时序预测,自动驾驶,推荐和个性化技术,以及其他相关领域都有广泛地应用。但是在食品安全领域,由于实际测量的食品危害物含量可能因为传感器性能、读数错误、仪器损坏等原因,不可避免的会出现测量噪声及错误的情况。在深度学习模型的训练过程中,损失函数的选择是一个重要的部分,它会决定模型的训练效果。由于食品供应链危害物数据的强非线性和强随机性,在含噪数据分析阶段很难完全去除噪声的影响,这就导致得到的估计真值仍然存在噪声,在训练中模型对数据中的噪声过分学习,噪声的随机性就会导致预测性能的下降,并且对噪声的学习也会影响模型的鲁棒性。
技术实现要素:
5.为解决上述技术问题之一,本发明提供了一种食品供应链危害物预测方法及装置。
6.本发明实施例第一方面提供了一种食品供应链危害物预测方法,所述方法包括:
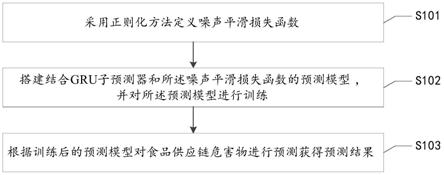
7.采用正则化方法定义噪声平滑损失函数;
8.搭建结合gru子预测器和所述噪声平滑损失函数的预测模型,并对所述预测模型进行训练;
9.根据训练后的预测模型对食品供应链危害物进行预测获得预测结果。
10.优选地,所述噪声平滑损失函数包括衡量输入数据拟合程度和衡量输入数据平滑程度两部分,所述衡量输入数据拟合程度部分通过预测值和真实值之间的平均绝对误差表示,所述衡量输入数据平滑程度通过衡量输入数据中每三个点平滑程度的矩阵的范数表示。
11.优选地,所述衡量输入数据中每三个点平滑程度的矩阵的范数的计算过程包括:
12.定义对输入数据进行平滑度惩罚的惩罚矩阵,并根据所述惩罚矩阵与输入数据计算获得衡量输入数据中每三个点平滑程度的矩阵;
13.对所述衡量输入数据中每三个点平滑程度的矩阵进行范数计算获得所述衡量输入数据中每三个点平滑程度的矩阵的范数。
14.优选地,所述对所述预测模型进行训练的过程为:根据物联网平台采集的危害物含量源数据对所述预测模型进行训练。
15.优选地,所述方法还包括:
16.通过贝叶斯优化算法对所述预测模型的超参数进行优化获得最优超参数;
17.根据所述最优超参数对所述预测模型进行训练获得最优预测模型;
18.根据所述最优预测模型对食品供应链危害物进行预测获得预测结果。
19.本发明实施例第二方面提供了一种食品供应链危害物预测装置,所述装置包括处理器,所述处理器,其被配置有处理器可执行的操作指令,以执行如下操作:
20.采用正则化方法定义噪声平滑损失函数;
21.搭建结合gru子预测器和所述噪声平滑损失函数的预测模型,并对所述预测模型进行训练;
22.根据训练后的预测模型对食品供应链危害物进行预测获得预测结果。
23.优选地,所述噪声平滑损失函数包括衡量输入数据拟合程度和衡量输入数据平滑程度两部分,所述衡量输入数据拟合程度部分通过预测值和真实值之间的平均绝对误差表示,所述衡量输入数据平滑程度通过衡量输入数据中每三个点平滑程度的矩阵的范数表示。
24.优选地,所述处理器,其被配置有处理器可执行的操作指令,以执行如下操作:
25.定义对输入数据进行平滑度惩罚的惩罚矩阵,并根据所述惩罚矩阵与输入数据计算获得衡量输入数据中每三个点平滑程度的矩阵;
26.对所述衡量输入数据中每三个点平滑程度的矩阵进行范数计算获得所述衡量输入数据中每三个点平滑程度的矩阵的范数。
27.优选地,所述处理器,其被配置有处理器可执行的操作指令,以执行如下操作:
28.根据物联网平台采集的危害物含量源数据对所述预测模型进行训练。
29.优选地,所述处理器,其被配置有处理器可执行的操作指令,以执行如下操作:
30.通过贝叶斯优化算法对所述预测模型的超参数进行优化获得最优超参数;
31.根据所述最优超参数对所述预测模型进行训练获得最优预测模型;
32.根据所述最优预测模型对食品供应链危害物进行预测获得预测结果。
33.本发明的有益效果如下:本发明提出了一种结合gru子预测器和采用正则化涉及的噪声平滑损失函数的预测模型,能够减少预测模型对随机噪声的拟合程度,提高了预测的准确度,在实际应对噪声大、出现测量错误等问题概率较大的预测任务中有更好的效果。
附图说明
34.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
35.图1为本发明实施例1所述的食品供应链危害物预测方法的流程图;
36.图2为实例中所提供的各环节don浓度、镉浓度、铅浓度示意图;
37.图3为实例中所提供的三种损失函数预测结果对比图;
38.图4为实例中所提供的三种损失函数的收敛情况对比图;
39.图5为实例中所提供的环节11镉金属含量预测样例图;
40.图6为实例中所提供的环节11铅金属含量预测样例图;
41.图7为实例中所提供的环节11don危害物含量预测样例图。
具体实施方式
42.为了使本技术实施例中的技术方案及优点更加清楚明白,以下结合附图对本技术的示例性实施例进行进一步详细的说明,显然,所描述的实施例仅是本技术的一部分实施例,而不是所有实施例的穷举。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
43.实施例1
44.如图1所示,本实施例提出了一种食品供应链危害物预测方法,该方法包括:
45.s101、采用正则化方法定义噪声平滑损失函数;
46.s102、搭建结合gru子预测器和所述噪声平滑损失函数的预测模型,并对所述预测模型进行训练;
47.s103、根据训练后的预测模型对食品供应链危害物进行预测获得预测结果。
48.具体的,正则化广泛地应用于机器学习与深度学习中。它的作用在于限制模型中的参数,让模型的参数不会太大,从而减少模型过拟合的可能。在本实施例中,为了减少模型因为过度学习供应链数据中的随机噪声而导致模型过拟合,设计的噪声平滑损失函数(noise smoothing loss,nsl损失函数)的公式为:
[0049][0050]
其中y
i
是预测值,是真实值,β是正则化项,p
y
是衡量数据中每三个点平滑程度的矩阵。噪声平滑损失函数的计算公式中包括两个部分,第一部分衡量数据拟合程度,表示将实际序列与拟合序列之间的残差平方和最小化的目标;第二部分,衡量平滑程度,表示训练过程中对序列平滑度的需求。其中,拟合程度用平均绝对误差表示,平滑程度通过计算p
y
的范数来实现。其中β是正则化项,将其视为在拟合与平滑两个目标之间的权衡取舍。
[0051]
p
y
的计算是实现噪声平滑损失函数的关键,计算时首先需要定义一个矩阵p,该矩阵对数据进行平滑度惩罚。p矩阵如下所示:
[0052][0053]
p矩阵的维度由输入数据决定,假设输入数据长度为t,则p的维度为(t,t),然后通过p与输入数据组成矩阵的乘法计算得到矩阵p
y
,最后通过矩阵范数的计算得到可以表示
数据每三个点间平滑程度的范数。
[0054]
在训练过程中进行对数据的平滑处理,即在训练模型的过程中实现平滑,这使训练时模型学习的是平滑后的数据,这样可以进一步提高模型的鲁棒性。
[0055]
gru是长短期记忆网络(long short term memory,lstm)的一个变体,两者均属于循环神经网络。较lstm网络而言,gru网络结构中只有更新门和重置门,gru网络更简单且效果更好。本实施例基于keras tensorflow框架,使用gru对数据进行拟合,同时训练时的优化目标替换为本实施例所提出的nsl损失函数。
[0056]
gru算法伪代码:
[0057]
(1)对数据集θ进行归一化
[0058][0059]
(2)模型对训练数据进行学习
[0060]
learn hbased on θ
[0061]
return h
[0062]
深度学习模型的超参数选择直接决定了模型的性能,本实施例中采用hyperopt库实现贝叶斯优化算法的一种:基于序列模型的优化(smbo)。优化的超参数主要包括gru中的神经元数、dropout率、训练次数、批处理大小、优化器。
[0063]
贝叶斯优化方法在确定模型参数时,使用代理模型来拟合真实的目标函数,并根据拟合结果主动选择最“潜在”的评估点。所以需要定义一个目标函数g(w)和优化的超参数空间。目标函数表示通过贝叶斯优化需要达到的最小化的目标,本实施例使用模型的均方根误差作为目标函数,找到此度量上产生最佳得分的模型超参数。
[0064][0065]
其中m为输入样本数量,y
i
(w)是预测值,是预测值。贝叶斯优化的代理函数以等式形式可以表示为:
[0066][0067]
其中w
*
为贝叶斯优化确定的最优参数,w为输入的一组超参数,w为多维超参数的参数空间。
[0068]
贝叶斯优化主要由两个步骤组成:首先通过第t+1步估计和更新高斯过程,然后通过最大化代理函数来指导超参数的采样。在高斯过程中,本实施例设置目标函数g(w)服从如下高斯分布:
[0069]
g(w)~gp(μ(w),k(w,w
′
))
[0070]
其中μ(w)为g(w)的均值,k(w,w
′
)为g(w)的协方差矩阵,初始的k(w,w
′
)可以表示为:
[0071]
[0072]
在进行贝叶斯优化时,高斯过程的协方差矩阵会随着迭代过程改变,假设在第t+1步输入的一组参数为w
t+1
,则此时协方差矩阵可以表示为:
[0073][0074]
其中k=[k(w
t+1
,w1),k(w
t+1
,w2),...,k(w
t+1
,w
t
)],这时本实施例可以得到目标函数的后验概率:
[0075][0076]
其中θ为观测数据,μ
t+1
(w)为第t+1步g(w)的均值,为第t+1步g(w)的方差。
[0077]
在得到后验概率后,接下来通过超参数搜索方法来寻找最优超参数,本发明使用ucb采集函数来完成超参数搜索:
[0078][0079]
其中ζ
t+1
是一个常数,s(w|θ
t
)为ucb采集函数,w
t+1
是选取出的第t+1步的超参数。
[0080]
贝叶斯优化算法的伪代码为:
[0081]
输入:θ是数据集,g(w)是模型的rmse,w是超参数空间(w∈w),h(w|θ
i
)是ucb采集函数,t是需要选择的超参数个数,l是小波分解的子序列个数。
[0082]
输出:最优超参数w
*
。
[0083]
(1)进行初始化,θ
(l)
←
initsamples(g(w),θ,l)
[0084]
(2)
[0085]
(3)对目标函数g(w)建模,计算后验概率
[0086]
(4)使用ucb采集函数进行参数更新,w
*
←
arg max h(w|θ
i(l)
)
[0087]
(5)使用w
*
超参数对本发明提出模型进行训练,得到预测y
i
←
g(w
*
),计算并更新
[0088]
(6)
[0089]
(7)endfor
[0090]
(8)
[0091]
(9)return w
*
[0092]
本实施例所述的预测模型在训练时gru子预测器的超参数均由贝叶斯优化算法确定。使用同一数据测试集对gru_nsl和rnn、lstm采用不同损失函数的模型进行对比测试,通过计算均方根误差(root mean square error,rmse)、平均绝对误差(mean absolute error,mae)、皮尔逊相关系数(pearson correlation coefficient,r)来评估模型性能。其中rmse和mae两个指标越小表示预测越准确,而皮尔逊相关系数的值越大表示观测值与预测值的拟合关系越紧密。其中评价指标的计算公式为:
[0093]
[0094][0095][0096]
其中,m为样本数,y为实际值,为预测值,为数据真实值的平均值,表示预测结果的平均值。
[0097]
实施例2
[0098]
对应实施例1,本实施例提出了一种食品供应链危害物预测装置,所述装置包括处理器,所述处理器,其被配置有处理器可执行的操作指令,以执行如下操作:
[0099]
采用正则化方法定义噪声平滑损失函数;
[0100]
搭建结合gru子预测器和所述噪声平滑损失函数的预测模型,并对所述预测模型进行训练;
[0101]
根据训练后的预测模型对食品供应链危害物进行预测获得预测结果。
[0102]
具体的,本实施例所提出装置的具体工作原理可参照实施例1所记载的内容,在此不再进行赘述。本实施例提出了一种结合gru子预测器和采用正则化涉及的噪声平滑损失函数的预测模型,能够减少预测模型对随机噪声的拟合程度,提高了预测的准确度,在实际应对噪声大、出现测量错误等问题概率较大的预测任务中有更好的效果。
[0103]
下面通过两个具体实例进一步说明本发明所提出的预测方法的预测过程以及所呈现的实际效果。
[0104]
实例1
[0105]
利用搭建的食品供应链危害物预测模型,使用前六环节(x1~x6)危害物含量预测后五环节(x7~x
11
)危害物含量数据。实验使用gru与平均绝对误差(mean absolute error,mae)、均方误差(mean square error,mse)损失函数的组合与本发明提出的模型作为对比,控制网络层数等变量保持一致。使用rmse,mae,r三个评价指标评估系统的性能。
[0106]
首先对实验所用数据进行说明,本实验使用的数据来自于小麦粉供应链,分别采集小麦粉供应链中脱氧雪腐镰刀菌烯醇(don)、铅、镉三种危害物的含量。该供应链共有清理、润麦、加工1等10个环节,设原粮为x1,净麦为x2,润麦为x3,加工一(1m芯)为x4,加工二(2m芯)为x5,加工三(3m芯)为x6,加工四(4m芯)为x7,加工五(5m芯)为x8,加工六(6m芯)为x9,包装为x
10
,仓储(现有数据中的流通环节检测值)为x
11
。通过对各环节中小麦粉的抽检,最终分别获得镉金属、铅金属、don三种危害物含量的数据。其中don 396组、铅1061组、镉2057组,数据格式分别为(396,11)、(1061,11)、(2057,11),各个环节的危害物含量见图2。
[0107]
本次对比实验仅使用镉危害物的含量数据。其中划分训练集格式为(1857,6),标签格式为(1857,5);测试集为(200,6),标签为(200,5)。训练集标签主要用于调整训练过程中模型各神经元权重与偏置,测试集标签用于检验预测结果。
[0108]
表1为在镉危害物数据集上,gru与nsl、mae、mse三种损失函数组合下的训练结果。结果表明:本发明提出的gru_nsl表现最好,rmse达到2.4484。其中,gru_nsl模型较相对最
优的gru_mae模型在rmse、mae、r三个指标上分别提升9.73%、6.31%、0.11%。
[0109]
表1
[0110][0111]
图3为gru模型分别在三种损失函数下训练模型的预测结果,可以看到nsl损失函数具有明显的优势。为了凸显nsl训练过程的情况,图4中展示了三种损失函数在gru模型的训练过程中迭代相同次数的收敛情况,nsl在迭代过程中下降速度最快,loss值最终稳定在0.40,该稳定值为考虑噪声方差后的loss值,因此会比mae、mse损失稍大。
[0112]
实验结果表明:在模型进行前6个环节危害物含量预测后5个环节危害物含量的任务中,使用正则化后的损失函数结合gru模型,可以达到提高食品供应链危害物预测模型的预测性能的效果。
[0113]
实例2:
[0114]
利用搭建的食品供应链危害物预测模型,进行前十环节危害物含量预测第十一环节危害物含量数据。
[0115]
本实验基于上述小麦粉供应链11个环节中抽检的镉金属、铅金属、don含量数据进行实验。由于仓库储存环节是食品流入市场的最后一个环节,代表了市场中小麦粉的质量,因此实验设置使用前10个环节预测最后的仓库储存环节的结果。实验使用本发明提出的gru_nsl模型与rnn、lstm、gru模型进行对比,训练集占总数据的80%,其余作为测试集。实验使用rmse、mae、r三种指标进行结果评估。根据食品安全国家标准规定,在农产品中食品中镉金属标准值不高于0.05mg/kg,铅金属不高于0.1mg/kg,don不高于1000μg/kg。
[0116]
表2、表3、表4分别为镉数据、铅数据、don数据的实验结果,所有结果统一单位为ug/kg。gru_nsl模型在三组数据的预测任务中表现出色,其中在镉数据应用中,rmse达到0.2595ug/kg,远小于国家食品标准的镉金属含量上限,gru_nsl模型在gru模型rmse指标基础上提升46.37%。在铅数据应用中,gru_nsl模型的rmse达到0.2700ug/kg,在gru的rmse指标基础上提升50.52%。在don数据应用中,gru_nsl模型rmse达到1.5245ug/kg,远小于国家指标,模型在gru的rmse基础上提升70.06%。
[0117]
表2
[0118][0119][0120]
表3
[0121][0122]
表4
[0123][0124]
图5至图7为部分预测结果的展示,分别从三组应用实验的结果中随机抽取2组预测结果,每组结果展示rnn、lst、gru和gru_nsl模型的预测结果,其中gru_nsl模型预测出的结果与真实值最接近。
[0125]
因此,通过实验验证,gru_nsl模型在预测任务中表现更为出色,且nsl可以进一步提升其对含噪时序数据的分析能力。由此可见,gru_nsl深度学习单元可以有效的分析含噪时间序列数据,对于食品供应链危害物等含噪数据有良好的预测性能。
[0126]
显然,本领域的技术人员可以对本技术进行各种改动和变型而不脱离本技术的精神和范围。这样,倘若本技术的这些修改和变型属于本技术权利要求及其等同技术的范围之内,则本技术也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1