基于GA-GRU模型的云服务器老化预测方法
基于ga
‑
gru模型的云服务器老化预测方法
技术领域
1.本发明属于时间序列预测技术领域,具体涉及一种基于门控循环单元(gated recurrent unit,gru)神经网络与遗传算法(genetic algorithm,ga)的模型预测云服务器老化的方法。
背景技术:
2.当今计算机技术和互联网的飞速发展,很多中小型互联网服务商由于没有足够的技术实力或者为了节省资金和方便服务器运维,通常都会采取云服务器的解决方案,这导致了云计算技术和云服务器商业的飞速发展。众所周知,稳定、长期运行、高扩展性和频繁的资源交换是云服务器的特点,所以这也导致了云服务器性能出现问题,即云服务器系统在长期运行过程中,随着故障和资源消耗累积,云服务器系统就会出现缓慢的性能下降,故障率也会增加,甚至导致云服务器的崩溃,造成服务中断,这种现象称为“软件老化”。软件老化的主要原因包括操作系统的资源消耗,误差的日益积累以及系统数据损坏。
3.在采用云服务器的互联网服务商中,例如有电信公司、金融证券公司、互联网商业公司、国防军事服务等。由于云服务器软件复杂性的快速提高,云服务器承受的服务压力也越来越大,云服务器系统的错误因素经常集中在软件方面,其中最重要的问题就是软件老化现象,许多高可用性和可靠性的应用软件也都存在软件老化现象。
4.目前it业界面对云服务器软件老化的主要技术手段是软件再生技术。软件再生技术是一种主动性的纠错技术,现在已经成为了解决软件老化的主要技术手段。1995年at&t实验室huang等人正式提出软件再生的定义。软件再生是指在检测到系统快要发生故障之前,通过周期性地暂停软件的运行,清除持续运行系统的内部状态,重新启动并恢复为干净的初始状态或中间状态,这样可以阻止之后可能发生的严重故障。软件再生技术已经成为了系统可靠性研究方面的一个重要课题,对于具有周期性波动的负载业务类型的长期运行软件系统(如教学视频点播系统,服务器的中间件系统,高性能网络io组件),采用软件再生技术周期性地暂停软件的运行,恢复系统到初始健康状态,可以提高系统的可靠性和稳定性。
5.在对云服务器进行软件老化预测的过程中,最重要的就是计算云服务器的软件老化阈值,软件老化阈值为在线维护提供了重要的理论依据。目前采用的云服务器软件老化趋势的预测技术主要是时间序列数据分析。时间序列预测方法主要是采用深度学习中的循环神经网络、长短期记忆网络、门控循环单元等进行预测,虽然这些深度学习模型适合时间序列预测,但是这些模型却需要大量的软件老化数据,而且存在预测时间长和预测精度不高的问题。另外,也可以采用智能算法的支持向量机进行云服务器软件老化预测,但是效果也不理想。这是因为云服务器软件老化的资源和性能数据具有非线性、随机分布、突发出现的特点,从而导致上述预测方法精度不高,尤其是在软件老化数据波动剧烈的区间里面,这些模型的软件老化预测精度会变的更低。
技术实现要素:
6.本发明的目的是提供一种基于ga
‑
gru模型预测云服务器老化的方法,解决传统的预测方法(比如:svm,lstm等)在对云服务器老化数据波动较大时预测精度不高的问题。
7.本方法采用了智能算法中的遗传算法优化门控循环单元的超参数,这种基于时间序列数据的预测方法,克服了模型在预测过程中容易陷入局部最优解、收敛速度慢、不稳定等问题。相比传统方法,本方法能够精确提取云服务器软件老化的数据波动变化特征,最终能够实现对云服务器软件老化的性能参数进行高精确率的预测和分析。
8.本发明所采用的技术方案是基于ga
‑
gru模型预测云服务器老化的方法,包括以下步骤:
9.步骤1,对云服务器系统的资源和性能数据进行收集;
10.步骤2,获取云服务器的系统资源和性能序列数据,获取的资源和性能序列数据有:cpu空闲率、可用内存、平均负载和响应时间;
11.步骤3,预处理步骤2获取的序列数据;
12.步骤4,使用步骤3预处理后得到的数据构建gru模型,并获得gru模型对步骤3所得数据的预测值;
13.步骤5,利用ga对步骤4得到的gru模型进行参数优化,得到ga
‑
gru模型;
14.步骤6,使用步骤5得到的ga
‑
gru模型预测步骤3得到的数据,并与步骤4得到的预测值对比,可得ga优化超参数后预测精度更高;
15.步骤7,利用ga
‑
gru模型的预测值和现有的序列数据对未来数据进行预测。
16.步骤3中,通过对原始的序列数据进行归一化的方法进行预处理,将原始序列数据映射到[0,1]。
[0017]
步骤3的具体步骤是:
[0018]
步骤3.1,将序列数据的最小值最小值记为x
min
,最大值记为x
max
;
[0019]
步骤3.2,使用序列数据减去x
min
;
[0020]
步骤3.3,使用步骤3.2得到的序列数据除以最大值减最小值即x
max
‑
x
min
。
[0021]
步骤4中构建gru模型具体方法是:构建5个功能模块,包括输入层、隐藏层、输出层、网络训练以及网络预测;输入层负责对原始响应时间序列进行归一化和划分数据集处理,以满足网络输入要求,隐藏层采用gru细胞搭建单层网络,输出层提供预测结果网络,网络预测采用迭代的方法逐点预测。
[0022]
步骤5中,利用ga优化gru模型的具体方法是:
[0023]
对种群基因进行编码,随机产生第一代n个个体,然后规定数据格式,进行归一化处理,然后训练gru网络;比较预测值与期望值,看是否达到了预期要求,否则就进行遗传算法的复制、交叉、变异,产生新一代n个个体,新一代的个体是更优秀的;之后选择最优秀的网络模型形成了ga
‑
gru云服务器老化预测模型。
[0024]
步骤5中利用ga优化gru模型的具体步骤如下:
[0025]
步骤5.1,种群初始化:个体编码使用二进制编码,每个个体均为一个二进制串,由输入层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值、输出层阈值四部分组成,每个权值和阈值使用m位的二进制编码,将所有权值和阈值的编码连接起来即成为一个个体的编码;
[0026]
步骤5.2,适应度参数:在用遗传算法优化gru网络时候,预测值与期望值的残差尽可能小,所以选择预测样本的预测值与期望值的误差矩阵的范数作为目标函数的输出;
[0027]
步骤5.3,选择算子:选择算子采用随机遍历抽样;
[0028]
步骤5.4,交叉算子:交叉算子采用最简单的单点交叉算子;
[0029]
步骤5.5,变异算子:变异以一定概率产生变异基因数,用随机方法选出发生变异的基因;如果所选的基因的编码为1,则变为0;反之,则变为1;
[0030]
步骤5.6,当迭代次数或者输出误差不满足要求,重复上述操作。
[0031]
gru模型包括输入层、隐藏层和输出层,将步骤3所得到的归一化处理后的序列数据和步骤4中gru模型的预测结果作为输入层的输入,通过ga优化gru网络中的超参数,所述输出层为ga
‑
gru模型的预测结果。
[0032]
本发明的有益效果是:本发明提供一种基于ga
‑
gru模型预测云服务器老化的方法,解决传统的预测方法(比如:svm,lstm等)对云服务器波动比较大的老化数据预测时存在精度不高的问题,并且本方法采用了智能算法中的遗传算法优化门控循环单元的超参数,这种基于时间序列数据的预测方法,克服了模型在预测过程中容易陷入局部最优解、收敛速度慢、不稳定等问题。相比传统方法,本方法能够精确提取云服务器老化的数据波动变化特征,最终能够实现对云服务器软件老化的性能参数进行高精确率的预测和分析。
附图说明
[0033]
图1为本发明基于ga
‑
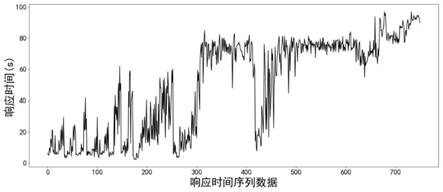
gru模型的云服务器老化预测方法中云服务器系统数据库查询响应时间图;
[0034]
图2为本发明基于ga
‑
gru模型的云服务器老化预测方法中的响应时间映射值图;
[0035]
图3为本发明基于ga
‑
gru模型的云服务器老化预测方法中的时间序列预测框图;
[0036]
图4为本发明基于ga
‑
gru模型的云服务器老化预测方法中的单个gru隐藏层细胞结构图;
[0037]
图5为本发明基于ga
‑
gru模型的云服务器老化预测方法中的ga优化gru超参数流程图;
[0038]
图6为本发明基于ga
‑
gru模型的云服务器老化预测方法中的ga
‑
gru模型与lstm模型以及svm模型预测效果对比图;
[0039]
图7为本发明基于ga
‑
gru模型的云服务器老化预测方法中的ga
‑
gru模型与lstm模型以及svm模型绝对误差值对比图。
具体实施方式
[0040]
下面结合附图和具体实施方式对本发明进行详细说明。
[0041]
本发明基于ga
‑
gru模型预测云服务器老化的方法,包括以下步骤:
[0042]
步骤1,对云服务器系统的资源和性能数据进行收集;
[0043]
步骤2,获取云服务器的系统资源和性能序列数据,获取的资源和性能序列数据有:cpu空闲率、可用内存、平均负载和响应时间;
[0044]
步骤3,预处理步骤2获取的序列数据;
[0045]
步骤4,使用步骤3预处理后得到的数据构建gru模型,并获得gru模型对步骤3所得
数据的预测值;
[0046]
步骤5,利用ga对步骤4得到的gru模型进行参数优化,得到ga
‑
gru模型;
[0047]
步骤6,使用步骤5得到的ga
‑
gru模型预测步骤3得到的数据,并与步骤4得到的预测值对比,可得ga优化超参数后预测精度更高;
[0048]
步骤7,利用ga
‑
gru模型的预测值和现有的序列数据对未来数据进行预测。
[0049]
步骤3中,通过对原始的序列数据进行归一化的方法进行预处理,将原始序列数据映射到[0,1]。
[0050]
步骤3的具体步骤是:
[0051]
将序列数据的最大值和最小值,分别记为x
max
和x
min
;
[0052]
通过把序列数据中的每一个数据都去减x
min
,再除以x
max
‑
x
min
即可得到归一化后的数据值;
[0053]
x
i
是输入层里面第i个样本通过归一化得到的数据值;x
min
是输入层里面归一化之后最小样本的数据值;x
max
是输入层里面归一化之后最大样本的数据值。
[0054]
步骤4中构建gru模型具体方法是:构建5个功能模块,包括输入层、隐藏层、输出层、网络训练以及网络预测;输入层负责对原始响应时间序列进行归一化和划分数据集处理,以满足网络输入要求,隐藏层采用gru细胞搭建单层网络,输出层提供预测结果网络,网络预测采用迭代的方法逐点预测。
[0055]
步骤5中,利用ga优化gru模型的具体方法是:
[0056]
对种群基因进行编码,随机产生第一代n个个体,然后规定数据格式,进行归一化处理,然后训练gru网络;比较预测值与期望值,看是否达到了预期要求,否则就进行遗传算法的复制、交叉、变异,产生新一代n个个体,新一代的个体是更优秀的;之后选择最优秀的网络模型形成了ga
‑
gru云服务器老化预测模型。
[0057]
步骤5中利用ga优化gru模型的具体步骤如下:
[0058]
步骤5.1,种群初始化:个体编码使用二进制编码,每个个体均为一个二进制串,由输入层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值、输出层阈值四部分组成,每个权值和阈值使用m位的二进制编码,将所有权值和阈值的编码连接起来即成为一个个体的编码;
[0059]
步骤5.2,适应度参数:在用遗传算法优化gru网络时候,预测值与期望值的残差尽可能小,所以选择预测样本的预测值与期望值的误差矩阵的范数作为目标函数的输出;
[0060]
步骤5.3,选择算子:选择算子采用随机遍历抽样;
[0061]
步骤5.4,交叉算子:交叉算子采用最简单的单点交叉算子;
[0062]
步骤5.5,变异算子:变异以一定概率产生变异基因数,用随机方法选出发生变异的基因;如果所选的基因的编码为1,则变为0;反之,则变为1;
[0063]
步骤5.6,当迭代次数或者输出误差不满足要求,重复上述操作。
[0064]
所述gru模型包括输入层、隐藏层和输出层,将步骤3所得到的归一化处理后的序列数据和步骤4中gru模型的预测结果作为输入层的输入,通过ga优化gru网络中的超参数,所述输出层为ga
‑
gru模型的预测结果。
[0065]
实施例
[0066]
这里使用云服务器数据库查询响应时间作为例子,数据序列如图1所示,响应时间
应映射值如图2所示,时间序列预测框图如图3所示,单个gru隐藏层细胞结构图如图4所示,ga优化gru参数流程图如图5所示,ga
‑
gru模型预测结果与svm以及lstm的预测结果比较图如图6所示,ga
‑
gru模型与lstm模型以及svm模型绝对误差值对比图如图7所示。不同模型的误差对比如表1所示,分别使用均方根误差rmse、平均绝对误差mae以及平均绝对百分比误差mape作为评价指标,由公式(1)(2)(3)所示,其中rmse是标准差,n是数据样本的个数,y
predictive
为预测值,y
true
为实际值。
[0067][0068][0069][0070]
表1不同模型的预测误差对比
[0071][0072]
具体步骤如下:
[0073]
步骤1,对云服务器系统的资源和性能数据进行收集;
[0074]
步骤2,获取云服务器的系统资源和性能序列数据,获取的资源和性能序列数据有:cpu空闲率、可用内存、平均负载和响应时间;
[0075]
步骤3:数据预处理。对云服务器进行老化预测前,需要对数据进行预处理,否则模型预测过程的收敛性差,从而数据训练难度和时间增加,最后导致预测误差较大。我们采用归一化处理方法,将云服务器原始数据映射到[0,1]区间,使得预测模型稳定且预测收敛速度快,处理结果如图2所示。具体包括以下步骤:
[0076]
步骤3.1,求得序列数据的最小值和最大值,最小值记为x
min
,最大值记为x
max
;
[0077]
步骤3.2,使用序列数据减去x
min
;
[0078]
步骤3.3,使用步骤3.2得到的序列数据除以最大值减最小值即x
max
‑
x
min
。
[0079]
步骤4中,构建gru模型的5个功能模块,包括输入层、隐藏层、输出层、网络训练以及网络预测。输入层通过对原始的响应时间序列初步处理,得到满足网络输入要求的数据,然后隐藏层搭建单层的神经网络,输出层提供预测结果网络,网络预测模块使用反复迭代
的方法进行逐点预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1