基于语义和时空关联的路网LBS兴趣点查询隐私保护方法
基于语义和时空关联的路网lbs兴趣点查询隐私保护方法
技术领域
1.本发明涉及移动通信中路网环境下基于位置服务的隐私保护,具体地,涉及一种基于语义和时空关联的路网lbs兴趣点查询隐私保护方法。
背景技术:
2.互联网络高速发展推动了基于位置的服务(location
‑
based service,lbs)的发展进程。其中,兴趣点(point of interest,poi)查询一直是广泛使用的一项服务。
3.然而,用户在享受lbs兴趣点查询服务带来的便利的同时,可能面临位置隐私泄露的风险。一方面,攻击者不仅窃取中心匿名服务器提交给lbs提供商的假位置匿名集合,而且还知道用户当前的查询内容,通过查询内容的语义和匿名集合位置语义之间的时间关联关系过滤掉一些不切实际的假位置,使得攻击成功的概率大大增加;另一方面,攻击者根据位置语义信息,结合兴趣点历史查询数据、路网等背景知识,对假位置匿名集合进行分析,从而推测出用户的爱好、生活习惯、职业甚至健康等隐私信息。
4.现有的位置隐私保护方法很少结合查询内容对位置信息进行保护,也很少考虑匿名集合包含的位置语义,甚至只关注自由环境而忽略了更为复杂、贴近现实的路网环境。同时,现有的假位置生成方法无法抵御同时存在的语义推断攻击和时间关联攻击,一旦攻击者窃取了中心匿名服务器提交给lbs供应商的假位置匿名集合和用户当前的查询内容,就会造成用户位置隐私泄露的危险。
5.因此,急需要提供一种能够有效防止语义推断攻击、时间关联攻击的基于语义和时空关联的路网lbs兴趣点查询隐私保护方法来解决上述技术难题。
技术实现要素:
6.本发明的目的是提供一种基于语义和时空关联的路网lbs兴趣点查询隐私保护方法,该方法能够有效防止语义推断攻击、时间关联攻击,安全性高,保护效果好。
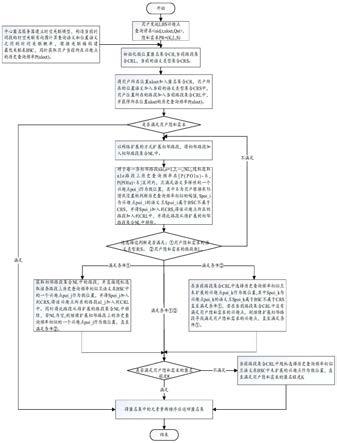
7.为了实现上述目的,本发明提供了一种基于语义和时空关联的路网lbs兴趣点查询隐私保护方法,包括:
8.步骤a、中心匿名服务器初始化路网数据、兴趣点数据库、历史查询数据,并根据历史查询数据计算历史兴趣点查询频率;
9.步骤b、移动用户向中心匿名服务器发送lbs兴趣点查询请求;
10.步骤c、中心匿名服务器获取当前查询时间的历史查询数据,建立时空关联模型计算查询语义和位置语义之间的时间关联概率,定义关联熵构造当前时刻最优关联表;
11.步骤d、中心匿名服务器结合最优关联表、用户发起查询时所在兴趣点的历史查询频率以及用户个性化隐私需求,利用假位置生成方法生成匿名集合并重新排序匿名集合;
12.步骤e、中心匿名服务器将查询内容和匿名集合发送给lbs服务器;
13.步骤f、lbs服务器根据接收到的匿名集合和查询内容进行查询,并将查询结果发送给中心匿名服务器;
14.步骤g、中心匿名服务器根据用户精确位置将接收到的结果集进行过滤,并将相应查询结果返回给用户。
15.优选地,步骤b中用户发起的兴趣点查询请求qu用一个四元组表示<uid,t,uloc
t
,qs
t
>;其中,
16.uid为用户请求lbs兴趣点查询时的唯一标识符,t为发起查询的时间,uloc
t
为用户在t时发起查询时所处在的兴趣点位置,qs
t
为用户在t时查询兴趣点的语义,查询兴趣点的语义包括酒店、餐厅、医院、学校、公园、酒吧等。
17.优选地,步骤c中时空关联模型的提出包括:
18.步骤c1、中心匿名服务器获取用户的历史查询数据;
19.步骤c2、中心匿名服务器根据查询请求的时间t,获取对应查询请求的时间段,并根据历史每个用户发起查询请求时的所在的位置uloc
t
构造时空关联序列ct;
20.步骤c3、中心匿名服务器根据时空关联序列ct构造时空关联有向图gt,计算查询语义与位置语义之间的时间关联概率。
21.优选地,步骤c2中时空关联序列是指若在时间段[ta,tb]内,任一用户us分别在时刻ta和tb发起的两次相邻查询为qus
ta
=<usid,ta,usloc
ta
,qs
ta
>、qus
tb
=<usid,tb,usloc
tb
,qs
tb
>,其中ta≤ta<tb≤tb;若tb时刻所在的位置usloc
tb
的语义与ta时刻查询的语义qs
ta
相等,则称ta时刻所在的位置语义与在该时刻发起的查询语义qs
ta
在时间段[ta,tb]内存在一个时间关联,记为统计所有用户在两次相邻查询中出现的次数为nf,则称为在时间段[ta,tb]的一个长度为1的时空关联序列,其中tn为时间段[ta,tb]的编号且tn∈[0,1,...,23]。
[0022]
优选地,步骤c3中当前时间段的时空关联有向图为gt=(v,e),由时空关联序列c={ct1,ct2,...,ct
|c|
}构成,包含一组顶点v和边e;每个顶点v∈v表示语义类别,每个顶点的出度表示时空关联序列中此位置语义sloc到其它查询语义qs={qs1,qs2,...qs
|qs|
}的时间关联的次数nf={nf1,nf2,...,nf
|nf|
}之和其中,nf集合与qs集合元素存在一一对应关系;每条边e∈e表示一个时空关联序列中此位置语义locs到特定查询语义qs
m
(m∈1,2,..,|qs|)出现的次数nf
n
(n∈1,2,...,|nf|);
[0023]
步骤c3中查询语义与位置语义之间的时间关联概率的计算为:如果顶点v的出度非0,即位置语义和查询语义之间的时间关联概率为否则,若则pt=0。
[0024]
优选地,步骤c中构建最优关联表包括:
[0025]
步骤c1’、将用户所处的位置语义放入最优关联表bsc;
[0026]
步骤c2’、根据查询语义和位置语义的时间关联概率选择一个与最优关联表bsc中关联熵最大的语义放入到最优关联表bsc;
[0027]
步骤c3’、重复执行步骤c2’直至最优关联表中元素个数达到用户自定义的最优关
联表长度阈值dsem。
[0028]
优选地,步骤c2’中关联熵用于描述当前查询时间段位置集合中位置语义与查询内容语义的不可区分程度;熵值越大,攻击者越难根据查询语义和位置语义之间的时间关联过滤位置集合;
[0029]
给定一个位置集合sloc={loc1,loc2,...,loc
sloc
}和查询内容语义qs,若表示位置集合中的位置语义和查询内容语义之间的时间关联概率,则关联概率集合为关联熵的计算公式为:
[0030][0031]
其中,为位置语义和查询内容语义之间的时间关联概率的归一化处理。
[0032]
优选地,步骤c3’中最优关联表阈值dsem由用户自定义,其中,s≤dsem≤st,s为用户个性化隐私需求中假位置匿名集合至少包含s个语义类别,st为整个路网空间包含的所有语义类别。
[0033]
优选地,步骤d中用户个性化隐私需求pr为:pr=(k,l,s),其中,k为匿名集合中的假位置的个数,l为匿名集合中假位置至少分布在l条路段上,s为匿名集合中的假位置至少包含s个语义类别。
[0034]
优选地,步骤e中假位置生成方法包括:
[0035]
步骤e1、初始化假位置匿名集合cr,当前路段集合crl,当前的语义类型集合crs;
[0036]
步骤e2、将用户所在兴趣点位置uloc
t
加入匿名集合cr,用户所在的位置语义加入当前的语义类型集合crs中,用户位置所在的路段加入当前路段集合crl中,并获得所在兴趣点位置的历史查询频率p(uloc
t
);
[0037]
步骤e3、检测当前用户的匿名集合cr是否满足用户个性化隐私需求pr=(k,l,s);若不满足用户个性化隐私需求pr,执行步骤e4;否则,满足用户个性化隐私需求pr,匿名结束,返回匿名集合cr;
[0038]
步骤e4、以网络扩展的方式扩展相邻路段,将相邻路段加入相邻路段集合nl中;
[0039]
步骤e5、对于每一条相邻路段nl
e
∈nl(e=1,2,...,|nl|),随机选取nl
e
路段上历史查询频率在[p(uloc
t
)
‑
δ,p(uloc
t
)+δ]区间内,且满足语义多样性的一个兴趣点poi_i作为假位置;其中,δ为用户根据实际情况设置的判断历史查询频率相似的阈值,为兴趣点poi_i的语义,即在每条路段上随机选择一个历史查询频率相似但是语义类别不同且语义在bsc中的兴趣点作为假位置,并且在一条相邻路段nl
e
上只选择一个兴趣点;并将spoi_i加入到crs,将该兴趣点所在的路段nl
e
加入到crl中,并将此路段nl
e
从待扩展的相邻路段集合nl中移除;边选择边判断如下两个条件:
[0040]
条件一、当前语义类型集合crs是否满足用户个性化隐私需求的语义类型数s;
[0041]
条件二、当前路段集合crl是否满足用户个性化隐私需求的路段数l;
[0042]
若上述两个条件满足其一或都满足,则执行步骤e6;否则,返回步骤e4、步骤e5;
[0043]
步骤e6、若满足条件一不满足条件二,执行步骤e7;若满足条件二不满足条件一,执行步骤e8;若两个条件都满足,执行步骤e9;
[0044]
步骤e7、逐一选择相邻路段集合nl中的剩余相邻路段nl
e
(nl
e
∈nl,e=el,el+1,el+2,...,|nl|,el∈(1,|nl|]),随机选取每条路段nl
e
上历史查询频率相似且语义在bsc中的一个兴趣点poi_j作为假位置直至满足条件二;
[0045]
同时,若则将其加入到crs中,并将该兴趣点所在的路段nl
e
加入到crl中,从待扩展的路段集合nl中移除该路段;若则继续扩展相邻路段并选择满足用户个性化隐私需求的兴趣点作为假位置,直至满足条件二;若已满足条件二,执行步骤e9;
[0046]
步骤e8、在当前路段集合crl中的路段上选择历史查询频率相似且未选择的兴趣点poi_k作为假位置;其中,spoi_k为兴趣点poi_k的语义且spoi_k∈bsc,直至满足条件一;若在当前路段集合crl中没有满足用户个性化隐私需求的兴趣点,则继续扩展相邻路段寻找满足用户个性化隐私需求的兴趣点作为假位置,直至满足条件一,执行步骤e9;
[0047]
步骤e9、若满足用户个性化隐私需求的假位置匿名个数k,则匿名结束,将匿名集合cr重新排序后返回;否则,在当前路段集合crl中随机选择历史查询频率相似、语义在bsc中且未被选择的兴趣点作为假位置,直至满足用户个性化隐私需求,将匿名集合cr重新排序后返回。
[0048]
根据上述技术方案,本发明利用历史查询数据建立时空关联模型计算查询语义和位置语义之间的关联概率,定义关联熵构造当前时间段最优关联表,根据最优关联表采取网络扩张的方法为用户生成一组分布在不同路段上的可抵御语义推断攻击和时间关联攻击的假位置匿名集合,使得攻击者无法获得用户位置隐私信息,从而实现用户在lbs兴趣点查询时位置隐私的保护。
[0049]
本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
[0050]
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
[0051]
图1是本发明提供的基于语义和时空关联的路网lbs兴趣点查询隐私保护方法的流程图;
[0052]
图2是本发明提供的基于语义和时空关联的路网lbs兴趣点查询隐私保护方法的系统架构图;
[0053]
图3是本发明提供的基于语义和时空关联的路网lbs兴趣点查询隐私保护方法的实施例的示意图;
[0054]
图4是本发明提供的基于语义和时空关联的路网lbs兴趣点查询隐私保护方法的实施例的时空关联有向图。
具体实施方式
[0055]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0056]
在本发明中,在未作相反说明的情况下,包含在术语中的方位词仅代表该术语在常规使用状态下的方位,或为本领域技术人员理解的俗称,而不应视为对该术语的限制。
[0057]
参见图1和图2,本发明提供一种基于语义和时空关联的路网lbs兴趣点查询隐私保护方法,包括:
[0058]
步骤a、中心匿名服务器初始化路网数据、兴趣点数据库、历史查询数据,并根据历史查询数据计算历史兴趣点查询频率;
[0059]
步骤b、移动用户向中心匿名服务器发送lbs兴趣点查询请求;
[0060]
其中,步骤b中用户发起的兴趣点查询请求qu用一个四元组表示<uid,t,uloc
t
,qs
t
>;uid为用户请求lbs兴趣点查询时的唯一标识符,t为发起查询的时间,uloc
t
为用户在t时发起查询时所处在的兴趣点位置,qs
t
为用户在t时查询兴趣点的语义,查询兴趣点的语义包括酒店、餐厅、医院、学校、公园、酒吧等。
[0061]
步骤c、中心匿名服务器获取当前查询时间的历史查询数据,建立时空关联模型计算查询语义和位置语义之间的时间关联概率,定义关联熵构造当前时刻最优关联表;
[0062]
其中,步骤c中时空关联模型的提出包括:
[0063]
步骤c1、中心匿名服务器获取用户的历史查询数据;
[0064]
步骤c2、中心匿名服务器根据查询请求的时间t,获取对应查询请求的时间段,并根据历史每个用户发起查询请求时的所在的位置uloc
t
构造时空关联序列ct;
[0065]
步骤c2中时空关联序列是指若在时间段[ta,tb]内,任一用户us分别在时刻ta和tb发起的两次相邻查询为qus
ta
=<usid,ta,usloc
ta
,qs
ta
>、qus
tb
=<usid,tb,usloc
tb
,qs
tb
>,其中ta≤ta<tb≤tb;若tb时刻所在的位置usloc
tb
的语义与ta时刻查询的语义qs
ta
相等,则称ta时刻所在的位置语义与在该时刻发起的查询语义qs
ta
在时间段[ta,tb]内存在一个时间关联,记为统计所有用户在两次相邻查询中出现的次数为nf,则称为在时间段[ta,tb]的一个长度为1的时空关联序列,其中tn为时间段[ta,tb]的编号且tn∈[0,1,...,23]。
[0066]
步骤c3、中心匿名服务器根据时空关联序列ct构造时空关联有向图gt,计算查询语义与位置语义之间的时间关联概率。
[0067]
其中,步骤c3中当前时间段的时空关联有向图为gt=(v,e),由时空关联序列c={ct1,ct2,...,ct
|c|
}构成,包含一组顶点v和边e;每个顶点v∈v表示语义类别,每个顶点的出度表示时空关联序列中此位置语义sloc到其它查询语义qs={qs1,qs2,...qs
|qs|
}的时间关联的次数nf={nf1,nf2,...,nf
|nf|
}之和其中,nf集合与qs集合元素存在一一对应关系;每条边e∈e表示一个时空关联序列中此位置语义locs到特定查询语义qs
m
(m∈1,2,..,|qs|)出现的次数nf
n
(n∈1,2,...,|nf|);
[0068]
步骤c3中查询语义与位置语义之间的时间关联概率的计算为:如果顶点v的出度
非0,即位置语义和查询语义之间的时间关联概率为否则,若则pt=0。
[0069]
此外,步骤c中构建最优关联表包括:
[0070]
步骤c1’、将用户所处的位置语义放入最优关联表bsc;
[0071]
步骤c2’、根据查询语义和位置语义的时间关联概率选择一个与最优关联表bsc中关联熵最大的语义放入到最优关联表bsc;
[0072]
其中,步骤c2’中关联熵用于描述当前查询时间段位置集合中位置语义与查询内容语义的不可区分程度;熵值越大,攻击者越难根据查询语义和位置语义之间的时间关联过滤位置集合;
[0073]
给定一个位置集合sloc={loc1,loc2,...,loc
|sloc|
}和查询内容语义qs,若表示位置集合中的位置语义和查询内容语义之间的时间关联概率,则关联概率集合为关联熵的计算公式为:
[0074][0075]
其中,为位置语义和查询内容语义之间的时间关联概率的归一化处理。
[0076]
步骤c3’、重复执行步骤c2’直至最优关联表中元素个数达到用户自定义的最优关联表长度阈值dsem。
[0077]
步骤c3’中最优关联表阈值dsem由用户自定义,其中,s≤dsem≤st,s为用户个性化隐私需求中假位置匿名集合至少包含s个语义类别,st为整个路网空间包含的所有语义类别。
[0078]
步骤d、中心匿名服务器结合最优关联表、用户发起查询时所在兴趣点的历史查询频率以及用户个性化隐私需求,利用假位置生成方法生成匿名集合并重新排序匿名集合;
[0079]
步骤d中用户个性化隐私需求pr为:pr=(k,l,s),其中,k为匿名集合中的假位置的个数,l为匿名集合中假位置至少分布在l条路段上,s为匿名集合中的假位置至少包含s个语义类别。
[0080]
步骤e、中心匿名服务器将查询内容和匿名集合发送给lbs服务器;
[0081]
进一步的,步骤e中假位置生成方法包括:
[0082]
步骤e1、初始化假位置匿名集合cr,当前路段集合crl,当前的语义类型集合crs;
[0083]
步骤e2、将用户所在兴趣点位置uloc
t
加入匿名集合cr,用户所在的位置语义加入当前的语义类型集合crs中,用户位置所在的路段加入当前路段集合crl中,并获得所在兴趣点位置的历史查询频率p(uloc
t
);
[0084]
步骤e3、检测当前用户的匿名集合cr是否满足用户个性化隐私需求pr=(k,l,s);若不满足用户个性化隐私需求pr,执行步骤e4;否则,满足用户个性化隐私需求pr,匿名结
束,返回匿名集合cr;
[0085]
步骤e4、以网络扩展的方式扩展相邻路段,将相邻路段加入相邻路段集合nl中;
[0086]
步骤e5、对于每一条相邻路段nl
e
∈nl(e=1,2,...,|nl|),随机选取nl
e
路段上历史查询频率在[p(uloc
t
)
‑
δ,p(uloc
t
)+δ]区间内,且满足语义多样性的一个兴趣点poi_i作为假位置;其中,δ为用户根据实际情况设置的判断历史查询频率相似的阈值,为兴趣点poi_i的语义,即在每条路段上随机选择一个历史查询频率相似但是语义类别不同且语义在bsc中的兴趣点作为假位置,并且在一条相邻路段nl
e
上只选择一个兴趣点;并将spoi_i加入到crs,将该兴趣点所在的路段nl
e
加入到crl中,并将此路段nl
e
从待扩展的相邻路段集合nl中移除;边选择边判断如下两个条件:
[0087]
条件一、当前语义类型集合crs是否满足用户个性化隐私需求的语义类型数s;
[0088]
条件二、当前路段集合crl是否满足用户个性化隐私需求的路段数l;
[0089]
若上述两个条件满足其一或都满足,则执行步骤e6;否则,返回步骤e4、步骤e5;
[0090]
步骤e6、若满足条件一不满足条件二,执行步骤e7;若满足条件二不满足条件一,执行步骤e8;若两个条件都满足,执行步骤e9;
[0091]
步骤e7、逐一选择相邻路段集合nl中的剩余相邻路段nl
e
(nl
e
∈nl,e=el,el+1,el+2,...,|nl|,el∈(1,|nl|]),随机选取每条路段nl
e
上历史查询频率相似且语义在bsc中的一个兴趣点poi_j作为假位置直至满足条件二;
[0092]
同时,若则将其加入到crs中,并将该兴趣点所在的路段nl
e
加入到crl中,从待扩展的路段集合nl中移除该路段;若则继续扩展相邻路段并选择满足用户个性化隐私需求的兴趣点作为假位置,直至满足条件二;若已满足条件二,执行步骤e9;
[0093]
步骤e8、在当前路段集合crl中的路段上选择历史查询频率相似且未选择的兴趣点poi_k作为假位置;其中,spoi_k为兴趣点poi_k的语义且spoi_k∈bsc,直至满足条件一;若在当前路段集合crl中没有满足用户个性化隐私需求的兴趣点,则继续扩展相邻路段寻找满足用户个性化隐私需求的兴趣点作为假位置,直至满足条件一,执行步骤e9;
[0094]
步骤e9、若满足用户个性化隐私需求的假位置匿名个数k,则匿名结束,将匿名集合cr重新排序后返回;否则,在当前路段集合crl中随机选择历史查询频率相似、语义在bsc中且未被选择的兴趣点作为假位置,直至满足用户个性化隐私需求,将匿名集合cr重新排序后返回。
[0095]
步骤f、lbs服务器根据接收到的匿名集合和查询内容进行查询,并将查询结果发送给中心匿名服务器;
[0096]
步骤g、中心匿名服务器根据用户精确位置将接收到的结果集进行过滤,并将相应查询结果返回给用户。
[0097]
由此可见,该方法既可以有效的防止攻击者利用查询内容语义和匿名集合位置语义之间的时间关联关系推测出用户所处的位置,又可以有效的防止匿名集合中语义过于单一造成的语义推断攻击;同时,避免了假位置分布过于集中的问题,增强lbs兴趣点查询服
务下对用户位置隐私的保护程度。
[0098]
如下,提供本发明的一个具体的实施例,用于进一步详细阐述本发明:
[0099]
步骤a、中心匿名服务器初始化路网数据、语义位置数据库、历史兴趣点查询频率。如图3所示,路段编号由1
‑
14表示,路段起始节点和终止节点由
ⅰ‑ⅵ
(路网边缘)和
①‑⑦
表示,每条路段上的位置表示为a
‑
t。语义类别为学校、餐厅、医院、酒店、银行、小区、酒吧、公园。
[0100]
步骤b、用户a向中心匿名服务器发送基于位置的服务查询请求<aid,10:00,j学校,餐馆>,当前j学校的历史查询频率为0.03,查询频率相似性阈值δ=0.005,用户自定义的dsem=4,用户a的个性化隐私需求pr=(6,5,4);
[0101]
步骤c、中心匿名服务器获取用户a的查询,根据查询时间10:00获取历史10:00
‑
11:00时间段的查询数据,构建时空关联序列:<10,学校
→
餐厅,10>、<10,学校
→
酒店,8>、<10,学校
→
酒吧,2>、<10,公园
→
餐厅,9>、<10,公园
→
学校,6>、<10,酒店
→
餐厅,1>、<10,酒店
→
公园,8>、<10,酒店
→
酒吧,1>、<10,小区
→
餐厅,2>、<10,小区
→
学校,8>、<10,银行
→
餐厅,8>、<10,银行
→
酒店,4>、<10,银行
→
学校,3>、<10,餐厅
→
餐厅,6>、<10,餐厅
→
公园,3>、<10,餐厅
→
学校,4>、<10,医院
→
餐厅,9>、<10,医院
→
公园,1>、<10,医院
→
学校,1>、<10,医院
→
医院:1>。根据时空关联序列建立时空关联有向图如图4所示,并计算当前查询时间段内查询语义和位置语义之间的关联概率:学校
→
餐厅:公园
→
餐厅:酒店
→
餐厅:小区
→
餐厅:银行
→
餐厅:餐厅
→
餐厅:医院
→
餐厅:酒吧
→
餐厅:0。
[0102]
接着,中心匿名服务器首先将当前用户a所在的兴趣点“j学校”的语义“学校”加入到最优关联表中,当前最优关联表为:{“学校”},候选语义:公园、酒店、小区、银行、餐厅、医院、酒吧。然后计算关联熵(只给出一个详细计算):
[0103][0104]
e
{学校、酒店}
→
餐厅
≈0.6500、e
{学校、小区}
→
餐厅
≈0.8631、e
{学校、银行}
→
餐厅
≈0.9994、e
{学校、餐厅}
→
餐厅
≈0.9987、e
{学校、医院}
→
餐厅
≈0.9706、e
{学校、酒吧}
→
餐厅
=0,选择一个熵值最大的加入最优关联表中:{“学校”、“银行”},此时|bsc|=2<dsem,剩余候选语义:公园、酒店、小区、餐厅、医院、酒吧,再次计算关联熵(此处只列出一个详细计算):
[0105][0106][0107]
e
{学校、银行、九点}
→
餐厅
≈1.3424、e
{学校、银行、小区}
→
餐厅
≈1.4774、e
{学校、银行、餐厅}
→
餐厅
≈1.5825、e
{学校、银行、医院}
→
餐厅
≈1.5604、e
{学校、银行、酒吧}
→
餐厅
≈0.9994,选择一个熵值最大的加入最优关联表
中:{“学校”、“银行”、“餐厅”},此时|bsc|=3<dsem,剩余候选语义:公园、酒店、小区、医院、酒吧,重复上述计算,每一次选择一个熵值最大的加入最优关联表中,直至满足用户自定义的dsem,经过计算,最优关联表为:{“学校”、“银行”、“餐厅”、“公园”}。
[0108]
步骤e、将用户所在的路段加入当前路段集合crl,发起查询时所在兴趣点的语义加入到当前的语义类型集合crs,并将用户发起查询时的兴趣点加入到匿名集合cr,即匿名集合cr={“h学校”}、crl={“6”}、crs={“学校”}。
[0109]
以网络扩张的方式寻找匿名位置,获得相邻路段集nl={“3”、“7”、“9”、“12”},已知h学校的查询频率为0.3,c公园的历史查询频率为0.028,e餐馆的历史查询频率为0.03,n银行的历史查询频率为0.027,p银行的查询频率为0.031。对于集合中的每一条路段,根据语义在最优关联表里并且其历史查询频率在区间[0.025,0.035]内随机选择路段上的兴趣点,即随机选择路段3上c公园和e餐馆中的其中之一作为假位置。将c公园加入到匿名集cr,同时将c公园所在的路段从相邻路段集中删除,此时cr={“h学校”、“c公园”}、crl={“6”,“4”}、crs={“学校”、“公园”}、nl={“7”,“9”,“12”}。此时|crs|=2<4、|crs|=2<5,不满足用户个性化隐私需求,继续边选择边判断。由于路段7、路段9中的兴趣点并不在最优关联表中,所以将路段7、路段9从相邻路段集中移除。将路段12上的随机选择的p银行加入匿名集合cr中,即cr={“h学校”、“c公园”,“p银行”},crl={“6”,“3”,“12”},crs={“学校”、“公园”,“银行”}。此时|crs|=3<4、|crs|=3<5,不满足用户个性化隐私需求。
[0110]
nl为空集,继续扩展相邻路段,将路段1、2、5、8、10、11、13、14加入到相邻路段集。已知a餐馆的历史查询频率为0.015,k餐馆的历史查询频率为0.032,f公园的历史查询频率为0.022,r银行的历史查询频率为0.029。由于满足语义多样性但不满足历史查询频率所以排除路段1上的a餐馆,由于语义“医院”不在最优关联表中排除路段2,虽然f公园的语义在最优关联表中但其不满足历史查询频率所以从nl中移除路段5。路段8中的k餐馆满足语义多样性且在最优关联表中,将餐馆加入到匿名集合cr中,即cr={“h学校”、“c公园”、“p银行”、“k餐馆”}、crl={“6”,“3”,“12”,“8”}、crs={“学校”、“公园”、“银行”、“餐馆”}、nl={“10”、“11”、“13”、“14”}。此时满足用户个性化隐私需求的语义多样性|crs|=4,但是不满足用户个性化隐私需求的路段数,继续在nl中寻找待扩展的假位置。由于路段10中l小区不在最优关联表中,所以从nl中移除路段10。将路段11中的r银行加入到匿名集合cr中,此时cr={“h学校”、“c公园”、“p银行”、“k餐馆”、“r银行”},crl={“6”,“3”,“12”,“8”,“11”},crs={“学校”、“公园”、“银行”、“餐馆”},满足语义多样性且满足用户隐私要求的路段数。
[0111]
但是匿名集合|cr|=5<k,继续在当前路段crl中寻找兴趣点,路段3中的e餐馆和路段12中的n银行满足条件,随机选择其中之一作为假位置,即cr={“h学校”、“c公园”、“p银行”、“k餐馆”、“r银行”、“e餐馆”},满足用户个性化隐私需求,并重新排序匿名集合为{“r银行”、“c公园”、“e餐馆”、“h学校”、“k餐馆”、“p银行”}。
[0112]
中心匿名服务器将查询内容“餐馆”和匿名集合{“r银行”、“c公园”、“e餐馆”、“h学校”、“k餐馆”、“p银行”}发送给lbs服务器;
[0113]
步骤f、lbs服务器根据接收到的匿名集合和查询内容进行查询,并将查询结果发送给中心匿名服务器;
[0114]
步骤g、中心匿名服务器根据用户精确位置将接收到的结果集进行过滤,并将相应结果返回给用户,查询结束。
[0115]
通过上述技术方案,本发明利用历史查询数据建立时空关联模型计算查询语义和位置语义之间的关联概率,定义关联熵构造当前时间段最优关联表,根据最优关联表采取网络扩张的方法为用户生成一组分布在不同路段上的可抵御语义推断攻击和时间关联攻击的假位置匿名集合,使得攻击者无法获得用户位置隐私信息,从而实现用户在lbs兴趣点查询时位置隐私的保护。
[0116]
由此可见,该方法提出了一种时空关联模型衡量查询语义和位置语义之间的时间关联关系。通过历史查询数据构造时空关联序列,并根据时空关联序列建立时空关联有向图,利用出度情况计算时间关联概率。
[0117]
同时,定义了一种关联熵来计算位置集合中的位置语义和查询语义的不可区分程度。其中熵值越大,攻击者越难根据位置集合的位置语义和查询语义的时间关联分析过滤假位置。
[0118]
并且,还提出了一种满足用户个性化隐私需求的假位置生成方法。通过形式化用户个性化隐私需求,利用所提假位置生成方法为用户生成一组分布在不同路段上的可抵御语义推断攻击和时间关联攻击的假位置匿名集合。
[0119]
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
[0120]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
[0121]
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1