事务处理方法、分布式数据库系统、集群及介质与流程
事务处理方法、分布式数据库系统、集群及介质
1.本技术要求于2021年04月06日提交中国国家知识产权局、申请号为202110369369.x、发明名称为“一种分布式内存引擎集群”的中国专利申请的优先权,其全部内容通过引用结合在本技术中。
技术领域
2.本技术涉及数据库技术领域,尤其涉及一种事务处理方法、分布式数据库系统、事务处理系统、集群、计算机可读存储介质以及计算机程序产品。
背景技术:
3.随着数据库技术的不断发展,对数据(例如是员工考勤数据、员工薪资数据、生产数据等)通过数据库进行管理逐渐成为主流趋势。其中,数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。用户可以通过客户端应用程序(以下简称为客户端)访问数据库,以实现数据读取或数据写入。
4.数据读取或数据写入通常是由数据库系统实现的。数据库系统包括数据库管理系统(data base management system,dbms)。数据库系统通过上述dbms实现创建、查询、更新和删除数据。具体地,用户通过客户端触发对数据库中数据的操作,数据库系统响应于该操作执行相应的事务。以数据写入为例,数据库系统执行数据写入操作,将数据写入数据库系统的节点,然后将数据写入至数据库,如共享存储的数据库,从而实现数据持久化。
5.考虑到分布式数据库系统的高可靠性和高可用性,越来越多的用户(例如企业用户)采用分布式数据库系统对数据进行管理。其中,分布式数据库系统可以部署在实时应用集群(real application cluster,rac)。该集群具体是面向磁盘设计的基于数据全共享(shared-everything)架构的分布式数据库存储引擎集群。rac包括两种类型的节点,具体为汇聚节点(hub node)和叶子节点(leaf node)。汇聚节点是集群中的主节点,主节点之间通过点对点网络互连,处理分布式事务,叶子节点间无网络连接,用于处理并发查询和在线上报业务。
6.然而,叶子节点通常只能通过汇聚节点作为代理获取数据。由于叶子节点和汇聚节点通过双边方式进行交互,导致叶子节点需要等待操作系统的调度,并通过较长的访问路径获取汇聚节点上的数据,如此叶子节点通常只能读取到历史数据,难以满足实时性业务对于数据一致性的要求。
技术实现要素:
7.本技术提供了一种事务处理方法。该方法利用共享的全局内存使得分布式数据库系统中的节点如协调节点和参与节点可以跨节点单边访问全局内存,而不必通过双边交互方式进行数据同步,无需经过处理器和操作系统处理,访问路径大幅缩短,而且不需要通过操作系统调度,可以大幅缩短同步时间,实现了协调节点和参与节点之间的实时一致性,满足了实时性业务对实时一致性的需求。本技术还提供了上述方法对应的分布式数据库系
统、事务处理系统、集群、计算机可读存储介质以及计算机程序产品。
8.第一方面,本技术提供了一种事务处理方法。该方法可以由分布式数据库系统执行。该分布式数据库系统可以部署在集群中。该集群例如可以是内存引擎集群。分布式数据库系统在集群中运行时可以实现节点间数据的实时一致性,从而满足实时性业务的需求。具体地,分布式数据库系统包括协调节点和参与节点。协调节点在事务执行过程中承担协调责任,参与节点在事务执行过程中承担执行责任。其中,事务是指访问并可能更新数据库中数据的一个程序执行单元,通常包括有限的数据库操作序列。
9.分布式数据库系统的多个节点的部分内存用于形成全局内存。该全局内存对于分布式数据库系统中的所有协调节点、参与节点可见。协调节点或参与节点中剩余的部分内存为本地内存,该本地内存对于协调节点或参与节点自身可见。对于任意一个协调节点或参与节点,可以通过远端直接内存访问或内存总线等方式访问全局内存中位于其他节点的部分内存。
10.协调节点用于接收客户端发送的多条查询语句,根据多条查询语句中的第一查询语句创建事务,然后根据多条查询语句中的第二查询语句在全局内存中执行上述事务,接着协调节点根据多条查询语句中的第三查询语句提交上述事务,以实现所述协调节点和所述参与节点之间的一致性。
11.在该分布式数据库系统中,协调节点或参与节点中全局内存是共享的,当协调节点执行事务导致全局内存中的部分内存所存储的数据发生变化时,参与节点可以快速感知该变化,参与节点可以跨节点单边访问全局内存中的部分内存,以进行数据同步,而不必通过双边交互方式进行数据同步,由于无需经过处理器和操作系统处理,访问路径大幅缩短,而且不需要通过操作系统调度,可以大幅缩短同步时间,实现了协调节点和参与节点之间的实时一致性,满足了实时性业务对实时一致性的需求。此外,全局内存的容量可以随着节点数扩展,不再受限于单节点内存的容量,提高了并发控制能力。
12.在一些可能的实现方式中,所述分布式数据库系统部署在集群,所述全局内存来自于所述集群。该集群是指至少一组计算机形成的计算网络,用于为分布式数据库系统提供计算能力,以使分布式数据库系统基于上述计算能力对外提供服务。
13.该方法通过利用来自于集群的全局内存,使得分布式数据库系统的节点之间可以跨节点单边访问全局内存,无需经过处理器和操作系统处理,也无需等待操作系统的调度,实现了节点间(例如是协调节点、参与节点之间)的实时一致性。
14.在一些可能的实现方式中,所述全局内存包括所述协调节点和/或所述参与节点的部分内存。具体地,分布式数据库系统中的多个节点(例如是每一个节点)可以提供部分内存,用于形成全局内存,剩余的内存作为对应节点的本地内存。其中,全局内存对于分布式数据库系统中的节点是共享的。这些节点可以通过远端直接内存访问或者是内存总线直接实现跨节点单边访问,无需经过操作系统和处理器,也无需等待操作系统的调度,因而能够实现节点间的实时一致性。
15.在一些可能的实现方式中,协调节点的节点类型为主节点。相应地,该协调节点可以根据所述多条查询语句中的第一查询语句创建读写事务。如此可以满足实时读写业务的需求。
16.在一些可能的实现方式中,所述协调节点的节点类型为第一从节点。所述第一从
节点用于与节点类型为主节点的节点保持实时一致。基于此,该第一从节点也可以称作实时从节点。相应地,该协调节点可以根据所述多条查询语句中的第一查询语句创建只读事务。如此可以满足实时只读业务的需求。
17.在一些可能的实现方式中,分布式数据库系统还可以包括节点类型为第二从节点的节点。第二从节点用于与节点类型为主节点的节点保持准实时一致。因此,第二从节点也可以称作准实时从节点。该准实时从节点用于处理对实时性要求不高的业务,例如非实时分析业务。例如,准实时从节点用于接收与非实时分析业务关联的查询语句,然后返回相应的查询结果。如此可以满足非实时分析业务的需求。
18.在一些可能的实现方式中,在所述协调节点接收客户端发送的多条查询语句之前,所述分布式数据库系统(例如是分布式数据库系统中的协调节点和参与节点)可以接收集群管理节点发送的表记录在所述全局内存中的副本数量。然后分布式数据库系统保存所述表记录在所述全局内存中的副本数量。
19.如此,当分布式数据库系统在写数据时,可以根据上述表记录在全局内存中的副本数量写入相应数量的副本,保障数据安全性。其中,分布式数据库系统可以基于表粒度设置副本数量,满足了不同业务的个性化需求。
20.在一些可能的实现方式中,所述表记录存储在所述分布式数据库系统的全局内存中,所述表记录的索引树和管理头存储在所述分布式数据库系统的本地内存中。该方法将有限的全局内存用于存储表记录,采用本地内存存储表记录的索引树和管理头,以对表记录进行版本管理,一方面实现跨节点单边访问全局内存,保证节点间的实时一致性,另一方面避免了索引树等占用全局内存,提高了资源利用率。
21.在一些可能的实现方式中,协调节点在提交事务时可以基于事务提交协议实现。具体地,协调节点根据所述多条查询语句中的第三查询语句,通过运行于所述协调节点和所述参与节点的事务提交协议,提交所述事务,以实现所述协调节点和所述参与节点的实时一致性。
22.通过事务提交协议对协议节点、参与节点进行约束,使得需要进行数据写入(包括数据插入或更新)的节点(如协调节点、参与节点)执行的事务操作要么同时完成,要么同时回滚,如此避免了一些副本节点写入完成,另一些副本节点写入失败,导致节点实时不一致的情况发生,进一步保障了节点间的实时一致性。
23.在一些可能的实现方式中,所述事务发生写冲突时,例如事务与其他事务发生读写冲突或者是写写冲突时,所述协调节点触发悲观并发控制,所述参与节点触发乐观并发控制。其中,悲观并发控制的原理为,假设多用户并发的事务在处理时彼此互相影响,因此,可以通过阻止一个事务来修改数据。具体地,如果一个事务执行的操作如读某行数据应用了悲观并发控制(悲观锁),那么只有当这个事务释放权限后,其他事务才能够执行冲突的操作。乐观并发控制的原理为,假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
24.通过上述并发控制,一方面可以避免写写冲突或者读写冲突,保证协调节点和参与节点之间的一致性,另一方面可以减少协调节点与参与节点的交互,缩短同步时间,实现
实时一致。
25.第二方面,本技术提供一种分布式数据库系统。所述分布式数据库系统包括协调节点和参与节点,所述协调节点和所述参与节点共享全局内存。
26.所述协调节点,用于接收客户端发送的多条查询语句;
27.所述协调节点,还用于根据所述多条查询语句中的第一查询语句创建事务,根据所述多条查询语句中的第二查询语句在所述全局内存中执行所述事务,以及根据所述多条查询语句中的第三查询语句提交所述事务。
28.在一些可能的实现方式中,所述分布式数据库系统部署在集群,所述全局内存来自于所述集群。
29.在一些可能的实现方式中,所述全局内存包括所述协调节点和/或所述参与节点的部分内存。
30.在一些可能的实现方式中,所述协调节点的节点类型为主节点,所述协调节点具体用于:
31.根据所述多条查询语句中的第一查询语句创建读写事务。
32.在一些可能的实现方式中,所述协调节点的节点类型为第一从节点,所述第一从节点用于与节点类型为主节点的节点保持实时一致,所述协调节点具体用于:
33.根据所述多条查询语句中的第一查询语句创建只读事务。
34.在一些可能的实现方式中,所述协调节点,还用于接收并保存集群管理节点发送的表记录在所述全局内存中的副本数量;
35.所述参与节点,还用于接收并保存所述集群管理节点发送的表记录在所述全局内存中的副本数量。
36.在一些可能的实现方式中,所述表记录存储在所述分布式数据库系统的全局内存中,所述表记录的索引树和管理头存储在所述分布式数据库系统的本地内存中。
37.在一些可能的实现方式中,所述协调节点具体用于:
38.根据所述多条查询语句中的第三查询语句,通过运行于所述协调节点和所述参与节点的事务提交协议,提交所述事务,以实现所述协调节点和所述参与节点的实时一致性。
39.在一些可能的实现方式中,所述协调节点具体用于所述事务发生写冲突时,触发悲观并发控制;所述参与节点具体用于所述事务发生写冲突时,触发乐观并发控制。
40.第三方面,本技术提供一种事务处理系统。所述事务处理系统包括客户端和如本技术第二方面任意一种实现方式所述的分布式数据库系统,所述分布式数据库系统用于根据所述客户端发送的查询语句,执行对应的事务处理方法。
41.第四方面,本技术提供一种集群。该集群包括多台计算机。所述计算机包括处理器和存储器。所述处理器、所述存储器进行相互的通信。所述处理器用于执行所述存储器中存储的指令,以使得集群执行如第一方面或第一方面的任一种实现方式中的事务处理方法。
42.第五方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,所述指令指示计算机执行上述第一方面或第一方面的任一种实现方式所述的事务处理方法。
43.第六方面,本技术提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面的任一种实现方式所述的事务处理方法。
44.本技术在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
附图说明
45.为了更清楚地说明本技术实施例的技术方法,下面将对实施例中所需使用的附图作以简单地介绍。
46.图1为本技术实施例提供的一种事务处理系统的系统架构图;
47.图2为本技术实施例提供的一种节点配置方法的流程图;
48.图3为本技术实施例提供的一种配置副本数量方法的流程图;
49.图4为本技术实施例提供的一种事务处理方法的交互流程图;
50.图5为本技术实施例提供的一种事务开始及执行阶段的流程图;
51.图6为本技术实施例提供的一种事务提交阶段的流程图;
52.图7为本技术实施例提供的一种事务完成阶段的流程图;
53.图8为本技术实施例提供的一种事务回滚阶段的流程图;
54.图9为本技术实施例提供的一种集群的结构示意图。
具体实施方式
55.本技术实施例中的术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。
56.为了便于理解本技术实施例,首先,对本技术涉及的部分术语进行解释说明。
57.数据库应用是指基于底层的数据库向用户提供数据管理服务的应用。其中,数据管理服务包括数据创建、数据查询、数据更新和数据删除等中的至少一种。典型的数据库应用包括考勤管理系统、薪资管理系统、生产报表系统、证券交易系统等信息管理系统。数据库应用通常包括数据库系统和面向用户的客户端。用户可以通过客户端触发数据创建、查询、更新或删除操作,客户端可以响应于上述操作,通过数据库系统对数据库中的数据进行相应的处理。
58.数据库系统可以根据部署方式分为集中式数据库系统和分布式数据库系统。其中,分布式数据库系统是部署在包括多台计算机的集群中的数据库系统。在本技术中,集群中的计算机也可以称作节点(node)。节点之间可以通过网络进行通信,从而协同完成数据处理。
59.数据库系统可以通过存储引擎决定数据在内存、磁盘等存储介质中的存储方式以及数据读取方式。存储引擎具体是数据库系统的核心组件。不同类型的数据库系统可以采用不同的存储引擎,从而提供不同的存储机制、索引方式、锁定机制。当数据库系统分布式地部署在集群的不同节点时,还可以根据集群中节点存储数据的存储介质类型不同,将集群分为磁盘引擎集群和内存引擎集群。
60.目前,业界广泛应用的rac是面向磁盘设计的、基于数据全共享架构的分布式数据库存储引擎集群(例如是磁盘引擎集群)。rac包括两种类型的节点,具体为汇聚节点(hub node)和叶子节点(leaf node)。其中,汇聚节点是集群中的主节点,主节点之间通过点对点
网络互连,用于处理分布式事务,叶子节点之间无网络连接,用于处理并发查询和在线上报业务。然而,叶子节点通常只能通过汇聚节点作为代理获取数据。其中,叶子节点和汇聚节点通过双边交互获取汇聚节点中的数据。双边交互需要双方的中央处理器(central processing unit,cpu)参与处理,导致访问路径过长,例如访问路径可以为叶子节点的cpu到叶子节点的网卡,然后到汇聚节点的网卡,接着到汇聚节点的cpu,最后到汇聚节点的缓存。此外,上述交互需要等待操作系统的调度,由此导致较大的时延,叶子节点上通常只能读取到历史数据,难以满足实时性业务对于数据一致性的要求。
61.有鉴于此,本技术实施例提供了一种分布式数据库系统。该分布式数据库系统可以部署在集群中。该集群例如可以是内存引擎集群。分布式数据库系统在集群中运行时可以实现节点间数据的实时一致性,从而满足实时性业务的需求。具体地,分布式数据库系统包括协调节点和参与节点。协调节点在事务(transaction)执行过程中承担协调责任,参与节点在事务执行过程中承担执行责任。其中,事务是指访问并可能更新数据库中数据的一个程序执行单元,通常包括有限的数据库操作序列。
62.分布式数据库系统的多个节点的部分内存用于形成全局内存(global memory,gm)。该全局内存对于分布式数据库系统中的所有协调节点、参与节点可见。协调节点或参与节点中剩余的部分内存为本地内存,该本地内存对于协调节点或参与节点自身可见。对于任意一个协调节点或参与节点,可以通过远端直接内存访问(remote direct memory access,rdma)或内存总线(memory fabric)等方式访问全局内存中位于其他节点的部分内存。
63.协调节点用于接收客户端发送的多条查询语句,根据多条查询语句中的第一查询语句创建事务,然后根据多条查询语句中的第二查询语句在全局内存中执行上述事务,接着协调节点根据多条查询语句中的第三查询语句提交上述事务,以实现所述协调节点和所述参与节点之间的一致性。
64.在该分布式数据库系统中,协调节点或参与节点中全局内存是共享的,当协调节点执行事务导致全局内存中的部分内存所存储的数据发生变化时,参与节点可以快速感知该变化,参与节点可以通过rdma或memory fabric跨节点单边访问全局内存中的部分内存,以进行数据同步,而不必通过双边交互方式进行数据同步,由于无需经过处理器和操作系统处理,访问路径大幅缩短,而且不需要通过操作系统调度,可以大幅缩短同步时间,实现了协调节点和参与节点之间的实时一致性,满足了实时性业务对实时一致性的需求。此外,全局内存的容量可以随着节点数扩展,不再受限于单节点内存的容量,提高了并发控制能力。
65.基于上述分布式数据库系统,本技术实施例还提供一种事务处理系统。下面结合附图对本技术实施例提供的事务处理系统的进行详细说明。
66.参见图1所示的事务处理系统的系统架构图,事务处理系统10包括分布式数据库系统100、客户端200和数据库300。客户端200与分布式数据库系统100连接,分布式数据库系统100与数据库300连接。
67.分布式数据库系统100包括协调节点和参与节点。协调节点和参与节点可以通过高速网络的rdma或者memory fabric连接。协调节点和参与节点运行有事务提交协议。该事务提交协议中定义协调节点为事务的接入节点,参与节点为分布式数据库系统100中除协
调节点之外的主节点和第一从节点。
68.其中,协调节点的节点类型可以是主节点或者是第一从节点,该第一从节点用于与节点类型为主节点的节点保持实时一致。因此,第一从节点也称作实时从节点。例如针对读写事务,协调节点的节点类型可以是主节点,针对只读事务,协调节点的节点类型可以是实时从节点。需要说明的是,主节点具有处理只读事务的能力,因此针对只读事务,协调节点的节点类型也可以是主节点。
69.在一些可能的实现方式中,分布式数据库系统100还包括非事务节点,例如是第二从节点。该第二从节点用于与节点类型为主节点的节点保持准实时一致。因此,第二从节点也称作准实时从节点。考虑到一些业务(如非实时分析业务)对于实时性要求不高,分布式数据库系统100可以通过第二从节点对这些业务进行处理。例如,分布式数据库系统100中的第二从节点可以接收与非实时分析业务关联的查询语句,第二从节点根据该查询语句返回查询结果。
70.其中,分布式数据库系统100中的多个节点(例如是每个节点)的部分内存可以用于形成全局内存。该全局内存可以通过软件模块例如是全局内存管理模块实现内存编址、内存申请和释放管理。其中,全局内存管理模块可以是分布式数据库系统100的软件模块。
71.全局内存管理模块可以对分布式数据库系统100中的节点的内存进行管理。具体地,全局内存管理模块可以支持单副本或多副本的内存申请和释放。其中,内存申请和释放为字节级内存申请和释放。使用单副本全局内存的数据通常缓存在一个节点,当该节点故障时,该数据在缓存中不可访问,在接管阶段,该数据从存储系统中载入后才能继续访问。使用多副本全局内存的数据通常缓存在多个节点,当某个节点故障时,仍可以通过其他节点寻址并进行访问。其中,全局内存管理模块可以针对由多个节点上的部分内存形成的全局内存提供小块内存的申请和释放。具体地,全局内存管理模块可以提供全局内存接口。该全局内存接口可以用于申请指定长度的小块内存。
72.全局内存接口返回的单副本内存或多副本内存由全局内存管理模块统一编址,上述单副本内存或多副本内存的地址称作全局内存地址gmaddr。对于指定全局内存地址,分布式数据库系统100中的任意节点均可以访问该地址的数据。进一步地,全局内存管理模块还可以根据全局内存地址确定对应节点的节点标识以及偏移位置。基于节点标识和偏移位置可以实现本地或远端的读写访问。
73.客户端200可以是通用客户端如浏览器,或者是专用客户端如各种信息管理系统的客户端。用户可以根据查询语言,例如是结构化查询语言(structured query language,sql),通过客户端200编写查询语句,分布式数据库系统100(例如是分布式数据库系统100中的协调节点)接收到多条查询语句,可以根据多条查询语句中的第一查询语句创建事务,然后根据多条查询语句中的第二查询语句在全局内存中执行事务,接着根据多条查询语句中的第三查询语句提交事务,从而实现创建、查询、更新和/或删除数据。其中,对于协调节点、参与节点均可见的全局内存可以保障协调节点和参与节点的实时一致性。并且,协调节点、参与节点上运行的事务提交协议使得事务的操作要么同时被执行,要么同时回滚,进一步保障了协调节点和参与节点的实时一致性。
74.数据库300用于对数据进行持久化存储。例如,数据库300可以对日志数据进行持久化存储。当分布式数据库系统100中的节点从故障中恢复,或者分布式数据库系统100整
体重新上电恢复时,分布式数据库系统100可以从数据库300载入数据至内存。
75.需要说明的是,数据库300可以是共享存储系统(shared storage system)中的数据库。该共享存储系统包括裸设备(raw device)、自动存储管理(automatic storage management,asm)设备或者网络附属存储(network attached storage,nas)设备中的任意一种或多种。共享存储系统具有共享访问能力。分布式数据库系统100中的节点可以接入共享存储系统,并访问该共享存储系统。共享存储系统可以使用跨节点副本或者跨节点纠删码(erasure code)保障数据的可靠性,以及保障数据写入的原子性(atomicity)。原子性是指一个事务中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节,事务在执行过程中发生错误,会被回滚到事务开始前的状态。
76.在本实施例中,分布式数据库系统100可以部署在集群中,例如分布式数据库系统100可以部署在内存引擎集群中。相应地,事务处理系统10还可以包括集群管理节点400。该集群管理节点400与分布式数据库系统100连接。
77.集群管理节点400用于对集群(例如是集群中的分布式数据库系统100)进行运维。具体地,集群管理节点400可以用于发现分布式数据库系统100中的节点,对分布式数据库系统100中节点的状态进行管理,或者是对元数据进行管理。该元数据可以包括节点属性信息和数据表模式(schema)中的至少一种。节点属性信息包括节点标识(identity,id)、节点网络地址(internet protocol address,ip)、节点类型和节点状态中的任意一种或多种。数据表schema包括表名、表id、表类型、字段个数、字段类型描述等中的任意一种或多种。
78.在一些可能的实现方式中,事务处理系统10还包括授时服务器500。授时服务器500与分布式数据库系统100连接。授时服务器500用于提供单调递增的时钟服务。该时钟具体可以是逻辑时钟、真实时间(true time)时钟或者混合逻辑时钟。其中,混合逻辑时钟是指混合有物理时钟(如真实时间)的逻辑时钟。授时服务器500可以向分布式数据库系统100提供当前时刻的时间戳。该时间戳具体可以是表征时间的、长度为8字节或16字节的数值。分布式数据库系统100可以获取时间戳以确定事务对数据的可见性。
79.在进行事务处理之前,可以先安装分布式数据库系统100。安装分布式数据库系统100过程中,可以提示用户配置分布式数据库系统100中的节点。为了便于理解,下面结合附图,对本技术实施例提供的节点配置方法进行介绍。
80.参见图2所示的节点配置方法的交互流程图,该方法包括:
81.s202:分布式数据库系统100中的节点配置节点ip,安装日志文件系统,以及设置节点类型。
82.分布式数据库系统100可以包括多个节点。针对任意一个节点,可以基于ip地址池自动配置节点ip。在一些实施例中,节点也可以接收管理员人工配置的节点ip,从而实现节点ip配置。
83.类似地,节点可以自动配置节点类型,或者接收管理员人工配置的节点类型,从而实现节点类型配置。其中,节点类型可以包括主节点和实时从节点,进一步地,节点类型还可以包括准实时从节点。在一些实施例中,主节点可以用于处理读写事务,实时从节点可以用于处理只读事务,准实时从节点可以用于处理非事务请求,例如是与分析业务关联的查询请求。如此可以满足不同业务的需求。
84.考虑到分布式数据库系统100中的内存为易失性存储介质,为了保证事务相关数
据的可持久性,可以在事务的日志文件如再执行(redolog)日志持久化成功后,再向客户端200返回事务提交成功通知消息。日志文件直接写入共享存储系统(例如是共享存储系统中的数据库)可以增加事务提交时延,导致事务在分布式数据库系统100侧处理较快,但是日志文件持久化较慢,从而影响整体时延和性能。
85.为此,分布式数据库系统100中的一些节点(例如是主节点)还可以配置高速持久化介质,以用于日志文件的持久化。该高速持久化介质包括但不限于保电内存、非易失性随机访问存储器(non-volatile random access memory,nvram)或者其他非易失性的3d-point介质。节点可以安装日志文件系统(log file system,logfs),以便通过日志文件系统对本地的高速持久化介质进行管理。日志文件系统还可以提供文件语义的访问接口,以用于持久化日志文件,如redolog文件。
86.进一步地,实时从节点也可以配置高速持久化介质,以便于主节点故障时,可以将实时从节点的节点类型修改为主节点。准实时从节点主要用于处理非事务请求,无需在本地进行日志文件持久化,因而无需配置高速持久化介质。
87.由于redolog文件的数据量随着事务提交数量的增加而膨胀,因此redolog文件可以由后台任务(例如是分布式数据库系统100中的节点触发的任务)从日志文件系统中搬移写入到共享存储系统中。该搬移过程由后台任务完成,不影响事务执行时延。
88.需要说明的是,高速持久化介质的容量需求较小。例如,单节点的事务处理能力为100万事务/秒,日志文件如redolog文件的数据量为1吉字节(gigabyte,gb)/秒,当后台任务每0.5秒搬移一次,那么高速持久化介质的容量配置为1gb即可满足1个节点的redolog文件写入。而redolog文件被搬移到共享存储系统之前,为保证其可靠性,可以在多个节点写入。假设在3个节点写入,那么高速持久化介质的容量可以配置为1gb*3=3gb。
89.基于分布式数据库系统100的上述结构可以从逻辑上将分布式数据库系统100分为索引层、表记录层、近端持久层。索引层用于存储数据表中表记录的索引树和表记录的管理头rhead。其中,rhead用于记录该版本表记录的全局内存地址和日志文件地址如redolog文件地址。索引层通常使用本地内存实现,通过本地访问方式进行访问。该索引树和rhead在分布式数据库系统100中所有节点上均存在,其中,主节点和实时从节点上的索引树和rhead实时一致,具体是事务提交完成时形成一致数据。表记录层用于存储数据表的表记录record。表记录层通常使用全局内存实现,可以通过远程访问方式如rdma或memory fabric进行访问。近端持久层用于对日志文件如redolog文件进行持久化存储。近端持久层通常使用高速持久化介质实现。
90.s204:分布式数据库系统100中的节点向集群管理节点400上报节点配置信息。
91.其中,节点配置信息可以包括节点ip和节点类型。进一步地,节点配置信息还可以包括内存容量、日志文件系统容量中的任意一种或多种。
92.s206:集群管理节点400检查各节点类型对应的节点数量,当节点数量满足设定条件时,保存节点配置信息到系统节点表sysnodetbl。
93.分布式数据库系统100中至少包括主节点,在一些可能的实现方式中,分布式数据库系统100还包括实时从节点和准实时从节点中的至少一种。基于此,集群管理节点400可以检查主节点数量nm是否满足如下设定条件:nm>0。可选地,集群管理节点400可以检查实时从节点数量nr和准实时从节点数量nq是否满足如下设定条件:nr≥0,nq≥0。
94.进一步地,考虑到分布式数据库系统100扩展的成本,主节点数量nm和实时从节点数量nr之和通常设定有上限值,该上限值可以为第一预设值q1。类似地,准实时从节点数量nq也设定有上限值,该上限值可以为第二预设值q2。基于此,集群管理节点400可以检查主节点数量nm和实时从节点数量nr之和是否满足如下设定条件:nm+nr≤q1,以及检查准实时从节点数量nq是否满足如下设定条件:nq≤q2。其中,q1和q2可以根据经验值设置,例如q1可以设置为8,q2可以设置为64。
95.当节点数量(例如单一类型节点数量和/或不同类型节点数量之和)满足设定条件时,表明节点配置合法,集群管理节点400可以保存节点配置信息到系统节点表sysnodetbl。
96.s208:集群管理节点400向分布式数据库系统100中的节点返回配置成功提示。
97.s210:分布式数据库系统100中的节点向客户端200返回配置成功提示。
98.具体地,集群管理节点400向分布式数据库系统100中的各个节点返回配置成功提示,然后各个节点向客户端200返回配置成功提示。
99.需要说明的是,当节点数量不满足设定条件时,如节点数量超过上限值,或者节点数量低于下限值,表明节点配置不成功。相应地,集群管理节点400还可以返回配置失败提示,以便重新进行节点配置。
100.s212:客户端200设置系统节点表sysnodetbl生效标记。
101.s214:客户端200发送系统节点表sysnodetbl生效标记至集群管理节点400。
102.具体地,生效标记用于标识系统节点表sysnodetbl,客户端200设置该生效标记,并将生效标记发送至集群管理节点400可以实现将系统节点表sysnodetbl生效。
103.s216:集群管理节点400向分布式数据库系统100中的节点返回系统节点表sysnodetbl。
104.s218:分布式数据库系统100中的节点保存系统节点表sysnodetbl。
105.s220:集群管理节点400向客户端200返回节点配置信息。
106.具体地,集群管理节点400向客户端200返回各个节点的节点配置信息,如各个节点的节点ip、节点类型等。如此,客户端200不仅可以获得节点配置信息,还可以根据各节点的节点配置信息获得节点数量,如各节点类型的节点数量。
107.需要说明的是,上述s210至s220为本技术实施例提供的节点配置方法的可选步骤,在本技术其他可能的实现方式中,可以不执行上述s210至s220。
108.在节点配置完成后,还可以配置表记录在全局内存中的副本数量recordmemrepnum。其中,recordmemrepnum的最小值可以设置为1。考虑到分布式数据库系统100中主节点和实时从节点中的数据保持实时一致,如果全局内存中的副本数量超过主节点数量nm和实时从节点数量nr之和即nm+nr,会增加内存的消耗且对可用性没有提升,基于此,最大值可以设置为nm+nr。
109.当业务对于恢复时间要求较高时,可以配置recordmemrepnum大于1。如此,当某个节点故障时,缓存在该节点上的表记录无法访问,但处于正常状态的协调节点或者参与节点依然可以直接从该数据表的内存副本节点的内存中访问表记录。此时,恢复时间目标(recovery time objective,rto)=0。
110.当业务对于恢复时间要求较低时,可以配置recordmemrepnum等于1。如此,当某个
节点故障时,其他节点(如处于正常状态的协调节点或参与节点)无法访问缓存在该故障节点上的表记录,那么访问该表记录的事务可以等待分布式数据库系统100中某节点接管了故障节点,并从共享存储系统中恢复,或者从日志文件如redolog文件中回放后,再继续执行。此时,rto》0。
111.在配置recordmemrepnum时,还可以向对用户进行信息提示,例如提示recordmemrepnum的最小值和最大值,以便于用户参考该最小值和最大值进行配置。在配置完成后,集群管理节点400还可以将recordmemrepnum作为表属性,保存在系统元数据表sysmetatbl中,分布式数据库系统100中的节点也可以在本地内存中更新系统元数据表sysmetatbl。
112.接下来,结合附图对本技术实施例提供的配置recordmemrepnum的方法进行介绍。
113.参见图3所示的配置recordmemrepnum的方法的交互流程图,该方法包括:
114.s302:客户端200向分布式数据库系统100中的主节点发送创建表命令,表命令中包括recordmemrepnum。
115.创建表命令中包括表参数,该表参数可以包括表记录在全局内存中的副本数量即recordmemrepnum。在一些可能的实现方式中,表参数还可以包括表名、列名、列类型中的一种或多种。
116.s304:主节点转发创建表命令至集群管理节点400。
117.主节点可以执行创建表命令,以创建数据表。并且,主节点还转发创建表命令,例如是转发创建表命令中的recordmemrepnum参数至集群管理节点400,以设置recordmemrepnum。
118.如此,可以实现以数据表为粒度配置表记录在全局内存中的副本数量recordmemrepnum,满足了不同数据表的可用性需求,并且可以根据数据表的需求控制内存消耗。
119.s306:集群管理节点400检查recordmemrepnum是否在预设范围内。若是,则执行s308;若否,则执行s320。
120.预设范围是recordmemrepnum的取值范围。该范围可以是大于等于1且小于等于主节点的数量nm和实时从节点的数量nr之和即nm+nr。集群管理节点400检查recordmemrepnum是否大于等于1且小于等于nm+nr。若是,则表征配置的recordmemrepnum是合法的,可以执行s308;若否,则表征配置的recordmemrepnum是不合法的,可以执行s320。
121.s308:集群管理节点400在系统元数据表sysmetatbl中保存recordmemrepnum。
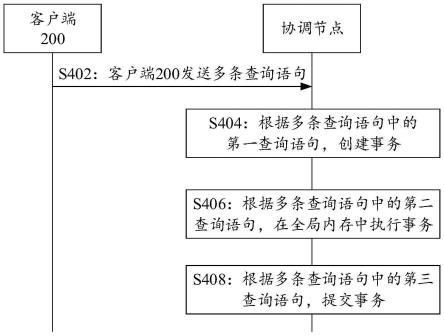
122.具体地,集群管理节点400在系统元数据表sysmetatbl中增加表记录,该表记录具体用于记录recordmemrepnum,集群管理节点400可以对表记录中的上述数据进行持久化存储。
123.s310:集群管理节点400向主节点、实时从节点、准实时从节点发送系统元数据表sysmetatbl。
124.其中,集群管理节点400可以向分布式数据库系统100中的节点发送上述系统元数据表sysmetatbl。当分布式数据库系统100不包括实时从节点或者准实时从节点时,也可以不执行向实时从节点、准实时从节点发送系统元数据表sysmetatbl的步骤。
125.s312:分布式数据库系统100中的主节点、实时从节点和准实时从节点在本地内存中更新系统元数据表sysmetatbl。
126.s314:分布式数据库系统100中的主节点、实时从节点和准实时从节点向集群管理节点400发送更新完成通知。
127.其中,更新完成通知用于通知集群管理节点400已在分布式数据库系统100各节点的本地内存完成对系统元数据表sysmetatbl的更新。
128.s316:集群管理节点400向分布式数据库系统100中的主节点发送配置成功响应。
129.s318:主节点向客户端200发送配置成功响应。
130.在一些可能的实现方式中,集群管理节点400也可以直接向客户端200发送配置成功响应,以通知客户端200对于recordmemrepnum的配置已完成。
131.s320:集群管理节点400向分布式数据库系统100中的主节点发送配置失败响应。
132.s322:主节点向客户端200发送配置失败响应。
133.在一些可能的实现方式中,集群管理节点400也可以直接向客户端200发送配置失败响应,以通知客户端200对于recordmemrepnum的配置失败。基于此,客户端200还可以调整表参数,然后重新发送创建表命令。
134.需要说明的是,上述s314至s322为本技术实施例提供的配置recordmemrepnum的方法的可选步骤,在本技术其他可能的实现方式中,可以不执行上述s314至s322。
135.在完成节点配置和表记录在全局内存中的副本数量的配置后,可以基于上述事务处理系统10进行事务处理。接下来,结合附图对本技术实施例提供的事务处理方法进行详细说明。
136.参见图4所示的事务处理方法的流程图,该方法包括:
137.s402:客户端200向分布式数据库系统100中的协调节点发送多条查询语句。
138.查询语句是指通过查询语言编写的、用于对数据库300中数据进行处理的语句。其中,对数据库300中数据进行处理包括数据创建、数据查询、数据更新和数据删除等中的任意一种或多种。
139.客户端200可以接收用户通过查询语言编写的多条查询语句,然后向分布式数据库系统100中的协调节点发送上述多条查询语句。其中,查询语言可以由用户从数据库300支持的查询语言列表中确定。例如,查询语言可以是sql,相应地,用户编写的查询语句可以是sql语句。
140.其中,客户端200发送多条查询语句时,可以一次性地发送多条查询语句,如此可以提高吞吐率。在一些可能的实现方式中,客户端200也可以逐条发送查询语句。具体地,客户端200可以先发送一条查询语句,在该查询语句被执行后,再发送下一条查询语句。
141.在一些可能的实现方式中,多条查询语句可以用于组成一个事务。客户端200根据查询语句确定事务的类型。其中,事务的类型包括读写事务和只读事务。只读事务不支持事务内进行插入(insert)、删除(delete)、更新(update)等操作。客户端200可以根据查询语句是否指示插入、删除或更新表记录,从而确定事务的类型为读写事务或只读事务。例如,多条查询语句中至少有一条查询语句指示插入、删除或更新表记录,则客户端200可以确定事务的类型为读写事务,否则确定事务的类型为只读事务。
142.当事务的类型为读写事务时,客户端200可以从分布式数据库系统100的主节点中
确定协调节点,向该协调节点发送多条查询语句。当事务的类型为只读事务时,客户端200可以从分布式数据库系统100的实时从节点中确定协调节点,向该协调节点发送多条查询语句。在一些可能的实现方式中,事务的类型为只读事务时,客户端200也可以从主节点中确定协调节点,本技术实施例对此不作限定。
143.s404:分布式数据库系统100中的协调节点根据多条查询语句中的第一查询语句创建事务。
144.第一查询语句可以是指示事务开始的查询语句。例如,第一查询语句为sql查询语句时,该第一查询语句可以包括开始(begin)命令。协调节点可以执行第一查询语句,从而创建事务。其中,协调节点的节点类型为主节点时,协调节点可以根据第一查询语句创建读写事务。协调节点的节点类型为实时从节点时,协调节点可以根据第一查询语句创建只读事务。
145.参见图5所示的事务开始阶段的流程图,协调节点(例如是分布式数据库系统100中的主节点1)可以根据表征事务开始的第一查询语句(如图5中所示的begin),创建事务。具体地,协调节点可以创建全局事务,申请全局事务唯一标识gtxid,以及从本地内存申请本地事务控制块,获得本地事务控制块唯一标识lotxid。此外,协调节点还可以从授时服务器500获取开始时间戳(begin time stamp,begints)。
146.其中,gtxid可以根据节点标识和节点内的序列号确定,例如可以是节点标识和节点内的序列号拼接所得的字符串。全局事务包括多个子事务(例如是协调节点和参与节点上的本地事务),多个子事务之间可以通过gtxid进行关联。当协调节点发生异常,被其他节点接管时,其他参与节点可以通过gtxid中的节点标识,向集群管理节点400查询接管节点的节点标识,从而向接管节点发起全局事务状态重新确认流程。
147.本地事务控制块具体是本地内存中用于过程状态控制的一段内存空间。本地事务控制块唯一标识即lotxid可以是严格单调递增的数值,该数值可以是8字节的数值。lotxid可以记录到索引层的rhead中。当本节点上其他事务需要等待本事务提交完成时,可以通过lotxid找到本事务,并将其他事务加入本事务的等待队列。
148.事务开始时间戳即begints可以记录在本地事务控制块中,用于为事务可见性判断提供依据。具体地,事务开始时,协调节点从授时服务器500获取当前时间戳作为begints,协调节点可以基于开始时间戳,通过可见性规则判断表记录对于事务的可见性。下面对基于可见性规则判断可见性过程进行详细说明。
149.具体地,一个版本的表记录的rhead中包括该版本的表记录的生存时间窗。生存时间窗可以通过表征起始时间的最小时间戳tmin和表征终止时间的最大时间戳tmax表征。协调节点可以基于事务的begints和一个版本的表记录的rhead中tmin、tmax的大小关系,判断该版本的表记录对于事务的可见性。
150.在tmin和tmax都记录时间戳(而不是gtxid)的情况下,如果begints》=tmin且begints《tmax,则该版本的表记录对于该事务可见,否则不可见。在tmin或者tmax中的至少一个记录gtxid(而不是时间戳)的情况下,则协调节点可以根据rhead中记录的lotxid找到本地事务,将该事务加入本地事务的等待队列,当事务从等待队列中唤醒后,再读取tmin和tmax进行可见性的判断。
151.s406:分布式数据库系统100中的协调节点根据多条查询语句中的第二查询语句
在全局内存中执行事务。
152.第二查询语句可以是指示事务操作的查询语句。其中,事务操作包括数据操作语言(data manipulation language,dml)操作。其中,dml操作可以包括insert、delete或者update操作。事务操作也可以包括查询(query)操作。
153.其中,第二查询语句为指示执行insert操作的语句时,第二查询语句还可以携带待插入的表记录的记录数据。第二查询语句为指示执行update操作的语句时,第二查询语句还可以携带待更新的表记录的主键以及更新的记录数据。第二查询语句为指示执行delete操作的语句时,第二查询语句还可以携带表记录的主键。第二查询语句为指示执行query操作的语句时,第二查询语句还可以携带查询条件。其中,查询条件可以包括表记录的主键或谓词条件。谓词用于表示比较运算,谓词条件包括通过比较运算表达的查询条件。谓词条件用于缩小查询所返回的结果集的范围。
154.协调节点可以执行该第二查询语句,从而在全局内存中执行事务,例如协调节点可以在全局内存中执行数据插入、删除、更新或者读取等操作中的至少一种。其中,第二查询语句可以包括一条或多条。下面以第二查询语句分别为指示执行insert操作、执行delete操作、执行update操作和执行query操作的语句,对执行事务的过程进行说明。
155.参见图5所示的事务执行阶段的流程图,第二查询语句为指示执行insert操作的语句时,协调节点(例如是分布式数据库系统100中的主节点1)可以查询系统元数据表sysmetatbl得到表属性,该表属性包括表记录在全局内存中的副本数量,其中,表记录在全局内存中的副本数量可以记作recordmemrepnum。协调节点可以调用全局内存管理模块的提供的全局内存接口申请指定副本数量的全局内存空间(例如可以记作gm1),然后在gm1中填写记录数据。其中,指定副本数量等于recordmemrepnum。
156.具体地,协调节点可以调用全局内存接口获得gm1的副本所在节点列表,然后根据副本所在节点列表,在第一个副本的节点(例如是协调节点)的全局内存中填写新增的记录数据。其中,tmin可以设置为gtxid,tmax可以设置为-1(用于表示无穷infinite)。需要说明,tmin在提交之前设置为gtxid,在提交之后设置为时间戳,tmax在提交前后保持不变。
157.进一步地,协调节点可以查询系统节点表sysnodetbl。如果副本所在节点列表中存在准实时从节点,则继续在该准实时从节点的全局内存中填写新增的记录数据。其中,tmin设置为gtxid,tmax设置为-1。
158.协调节点还可以申请本地内存,用于存储rhead和间接索引indirect。其中,rhead中填写insert的记录数据的全局内存地址、物理地址和lotxid。其中,由于事务尚未提交,物理地址可以为0。indirect指向rhead。接着协调节点在本地索引树中插入新增的记录数据。如果存在键冲突,则insert失败,释放之前申请的全局内存和本地内存。协调节点还可以返回错误信息。该错误信息可以指示insert失败,进一步地,错误信息可以指示insert失败的原因。如果insert成功,则将indirect修改为指向新增的记录数据,然后协调节点可以在本地事务写集合(write set,wset)中记录操作类型为insert,并向客户端200返回插入成功。其中,本地事务写集合下文简称为写集合。
159.第二查询语句为指示执行update操作的语句时,协调节点(例如是分布式数据库系统100中的主节点1)可以查询系统元数据表sysmetatbl得到表属性,该表属性包括recordmemrepnum。协调节点查找update操作的表记录的版本,根据begints和rhead中的
tmin、tmax确定表记录对于事务的可见性,并返回正确版本的表记录。
160.具体地,协调节点根据update操作的表记录的主键,在索引数据如索引树中查找该表记录的版本链表,即rhead链表。然后协调节点根据rhead记录的全局内存地址,读取表记录对应的tmin和tmax,根据tmin和tmax进行可见性判断。如果该版本中tmin或者tmax为gtxid而不是时间戳,则将本事务加入rhead中的lotxid所标识的本地事务控制块的等待队列中,本事务被唤醒后,可以重新执行rhead链表的遍历过程。其中,gtxid或时间戳可以通过高位bit区分,tmin或者tmax的高位bit为1则tmin或者tmax为gtxid,tmin或者tmax的高位bit不为1,则tmin或者tmax为时间戳。如果该版本中tmin或者tmax均为时间戳,当begints在[tmin,tmax)内时,则表明该版本的表记录对于事务可见,协调节点可以返回该版本的表记录以及rhead,当begints不在[tmin,tmax)内时,表明该版本的表记录对于事务不可见,协调节点可以根据rhead记录的前一个版本的地址继续遍历前一个版本。
[0161]
协调节点可以根据返回的版本的rhead得到表记录的全局内存地址,然后根据全局内存地址尝试在表记录中标记更新。具体地,如果返回的版本的tmax不是-1,则表明该版本不是当前版本,已经被其他事务更新,即产生写写冲突,协调节点可以返回标记失败通知给客户端200。如果返回的版本的tmax是-1,则表明是最新版本,协调节点可以调用全局内存接口得到内存副本的节点列表,对第一个副本节点的全局内存中对应表记录的tmax发起比较并替换(compare and swap,cas)原子操作,将tmax标记为gtxid。如果cas原子操作返回失败,说明写写冲突,返回标记失败通知至客户端200,如果cas原子操作返回成功,说明标记成功,协调节点可以执行对表记录的更新。
[0162]
其中,协调节点对表记录进行更新时,可以先调用全局内存接口申请指定副本数量的全局内存,然后填写更新的记录数据。其中,协调节点申请全局内存以及在全局内存中填写更新的记录数据的具体实现可以参考insert操作相关内容描述,在此不再赘述。然后协调节点申请本地内存,用于存储rhead,rhead中填写更新的表记录的全局内存地址和lotxid、物理地址。此时,物理地址可以为0。
[0163]
接着,协调节点安装新版本链,具体是将更新的表记录的管理头newrhead指向前一版本的rhead的地址,以及将indirect指向newrhead。协调节点在本地事务控制块中的写集合wset中记录操作类型为update以及记录rhead(也即oldrhead)的地址和newrhead的地址。在完成上述操作时,协调节点可以向客户端200返回更新成功通知。
[0164]
第二查询语句为指示执行delete操作的语句时,协调节点(例如是分布式数据库系统100中的主节点1)可以查找待delete的表记录的版本,根据begints和rhead中的tmin、tmax确定表记录对于事务的可见性,并返回正确版本的表记录。然后协调节点根据返回的版本的rhead得到表记录的全局内存地址,在表记录中标记更新。其中,协调节点确定可见性、返回正确版本的表记录、以及标记更新的具体实现可以参见update操作相关内容描述,在此不再赘述。
[0165]
接着,协调节点在本地事务控制块中写集合中记录操作类型为delete,以及记录rhead的地址。在完成上述操作时,协调节点可以向客户端200返回删除成功通知。
[0166]
第二查询语句为指示执行query操作的语句时,协调节点(例如是分布式数据库系统100中的主节点1)可以根据查询条件查找query的表记录的版本,根据begints和rhead中的tmin、tmax确定表记录对于事务的可见性,并返回正确版本的表记录。其中,协调节点确
定可见性以及返回正确版本的表记录的具体实现可以参见update操作相关内容描述。然后,协调节点还可以在本地事务读集合(read set,rset)中遍历读取记录,检查幻影(phantom),以对读写冲突进行验证。当验证通过时,可以返回上述正确版本的表记录,以对query操作进行响应。其中,本地事务读集合下文可以简称为读集合。
[0167]
经过上述处理,对于insert/update操作,协调节点已经为表记录的新版本技术了指定副本数量的全局内存,并且针对第一个副本节点(例如是协调节点)填写了表记录的记录数据,并设置了tmin和tmax。如果副本节点中包括准实时从节点,则还针对该准实时从节点填写表记录的记录数据,以及设置tmin和tmax。并且协调节点为表记录的新版本技术了rhead,rhead中记录了记录数据或更新的记录数据的全局内存地址,且已经安装到本地索引树及indirect中。对于update/delete操作,原有版本的第一个副本节点的tmax已经cas为gtxid,由此实现与其他事务的并发冲突处理。本地事务控制块中的写集合中已经记录了gtxid、begints以及newrhead的地址。本地事务控制块中的读集合中已经记录了读取记录以及查询条件(例如是谓词条件)。其中,读取记录可以用于读写冲突验证。
[0168]
s408:分布式数据库系统100中的协调节点根据多条查询语句中的第三查询语句提交事务。
[0169]
第三查询语句可以是指示事务提交的查询语句。例如,第三查询语句为sql查询语句时,该第三查询语句可以包括提交(commit)命令。协调节点可以执行第三查询语句,从而提交事务。协调节点可以执行第三查询语句,从而提交事务,以使新增的记录数据、更新的记录数据、删除的记录数据或者查找的记录数据在协调节点、参与节点之间实时一致。
[0170]
参见图6所示的事务提交阶段的流程图,协调节点(例如是分布式数据库系统100中的主节点1)可以查询本地缓存的系统节点表sysnodetbl,得到其他主节点和实时从节点列表,这些节点即为参与节点。协调节点根据写集合中的操作类型(例如是insert、update、delete中的一个或多个)以及newrhead的地址、oldrhead的地址,将操作类型和新旧版本表记录的全局内存地址和新版本表记录的记录数据,打包到预同步(也可以称作preinstall)请求消息中。预同步请求消息中包括gtxid和begints。协调节点将预同步请求消息发送至参与节点(例如是分布式数据库系统100中的主节点2、主节点3、实时从节点1、实时从节点2等)。参与节点接收到预同步请求消息,各自在本节点创建本地事务并得到lotxid。
[0171]
参与节点遍历预同步请求消息中的写集合,根据操作类型执行下述处理:
[0172]
对于insert操作,参与节点为新版本技术本地内存,该本地内存用于存储newrhead。参与节点在newrhead中记录预同步请求消息中所携带的全局内存地址、loxid和物理地址,其中,物理地址为0,然后对indirect赋值以使其指向newrhead。接着参与节点检查新版本的全局内存地址在本节点是否有副本,若有副本,且不是第一个副本,则在本节点的副本中填写记录数据,以及设置tmin=gtxid,tmax=-1。最后参与节点根据新增的记录数据的主键在索引树中插入该记录数据,如果存在键冲突,则发送预同步失败通知给协调节点,否则插入成功。需要说明,此时如果有其他事务发现该记录数据,则将本事务加入rhead中的lotxid对应的本地事务控制块的等待队列。
[0173]
对于update操作,参与节点为新版本技术本地内存,该本地内存用于存储newrhead。参与节点在newrhead中记录预同步请求消息中所携带的全局内存地址和loxid、物理地址。此时,物理地址为0。参与节点检查新版本的全局内存地址在本节点是否有副本,
若有副本,且不是第一个副本,则在本节点的副本中填写记录数据,以及设置tmin=gtxid,tmax=-1。然后参与节点根据旧版本表记录的主键,在本地索引数中查找indirect地址,并根据该地址得到其指向的rhead,将newrhead指向当前rhead。参与节点根据旧版本记录数据的全局内存地址,检查全局内存在本节点有副本且并非第一个副本时,则可以在本节点的副本中将tmax修改为gtxid。
[0174]
对于delete操作,参与节点根据旧版本表记录的主键,在本地索引树中查找indirect的地址,得到indirect指向的rhead,将newrhead指向当前rhead。然后,参与节点根据旧版本记录数据的全局内存地址,检查全局内存在本节点有副本且并非第一个副本时,则可以在本节点的副本中将tmax修改为gtxid。
[0175]
接着,参与节点发送预同步响应消息至协调节点。当协调节点集齐各参与节点发送的预同步响应消息,且预同步响应消息均标识预同步成功,则协调节点获取当前时间戳作为终止时间戳endts。
[0176]
协调节点可以确定事务的隔离级别,当事务的隔离级别为可串行化的快照隔离级别(serializable snapshot isolation,ssi)时,协调节点可以检查读写冲突。具体地,协调节点可以遍历读集合rset,使用endts检查rset中rhead对应的表记录的可见性,从而确定是否发生读写冲突。其中,协调节点可以按照谓词条件重新执行表记录的查询,检查基于endts可见的表记录和基于begints可见的记录是否相同,若是,则表示事务执行过程中谓词条件覆盖的表记录无读写冲突。如果某个表记录不可见,则表明有其他事务修改了该表记录,即产生读写冲突,协调节点可以终止事务,执行回滚操作,并通知其他参与节点终止事务,向客户端200返回错误响应。需要说明,当事务的隔离级别为其他隔离级别如读已提交(read commited,rc)、快照隔离(snapshot isolation,si)时,协调节点可以不用执行该步骤,以对读写冲突进行检查。
[0177]
协调节点根据系统节点表中节点配置信息,获得配置有日志文件系统如logfs的节点的列表。协调节点可以根据预先设置的副本数量,从该列表中选择相应数量的节点写日志文件。例如,预先设置的副本数量为n,协调节点可以写日志文件,并向其他配置有logfs的n-1个节点发送同步请求(也可以称作prepare请求),以通知上述节点写日志文件(例如redolog文件)。该日志文件记录由gtxid、endts、新增的记录数据及其全局内存地址以及删除的记录数据。然后协调节点等待上述节点的同步响应。其中,如果redolog不满足在先设置的副本数量的要求,例如在先设置的副本数量为3,而配置有高速持久化介质的节点数量为2,则协调节点可以直接将redolog写入共享存储系统。当协调节点确定事务的rc或si时,可以直接生成日志文件,如redolog文件。
[0178]
参与节点收到同步请求,在本地logfs的相同文件名中写入日志文件,如写入redolog文件,然后向协调节点返回同步响应。其中,参与节点在写入日志文件之前,也可以先验证读写冲突和写写冲突。其中,参与节点验证读写冲突的过程可以参考协调节点验证读写冲突的具体实现。参与节点验证写写冲突可以通过如下方式实现:参与节点根据事务的写集合中至少一个表记录的索引,确定是否发生写写冲突。例如参与节点在索引中插入写记录索引项时,发生唯一性冲突,则表明发生写写冲突。参与节点确定未发生写写冲突时,则生成redolog文件;参与节点确定发生写写冲突,则可以向协调节点返回错误响应。协调节点收到同步响应(也称提交响应,commit reply)后,可以进入事务完成(complete)流
程。
[0179]
具体地,参见图7所示的事务完成阶段的流程图,协调节点(例如是分布式数据库系统100中主节点1)向各参与节点(例如是分布式数据库系统100中主节点2、主节点3、实时从节点1、实时从节点2等)发送事务完成请求,该事务完成请求携带各参与节点的loxid。协调节点遍历本地事务中的写集合,应用本次事务的修改。
[0180]
协调节点应用本次事务的修改,可以是将新版本表记录在全局内存的第一个副本以及准实时从节点副本(如果有准实时从节点副本)中的tmin设置为endts,将rhead中的物理地址设置为redolog文件标识及偏移位置。然后协调节点将旧版本表记录在全局内存的第一个副本以及准实时从节点副本(如果有准实时从节点副本)中的tmax设置为endts,将rhead中的物理地址更新为redolog文件标识及偏移位置。协调节点将所有写集合中的rhead记录的lotxid设置为0。此时,协调节点取出本地事务中等待确定可见性的本地事务列表,全部唤醒。其中,被唤醒的事务会重新检查表记录的可见性。协调节点将本地事务加入回收链表,等待所有活动事务结束后,进行旧版本链的回收和索引的删除。
[0181]
参与节点收到事务完成请求后,采用与协调节点相似的处理方式。具体地,参与节点遍历写集合,应用本次事务的修改。其中,写集合中的新版本表记录在本节点有副本,则参与节点将新版本表记录的tmin设置为endts,rhead中的物理地址设置为redolog文件标识及偏移位置。参与节点还将写集合中的旧版本表记录的tmax设置为endts,rhead中的物理地址更新为redolog文件标识及偏移位置。参与节点将所有写集合中的rhead记录的lotxid设置为0。此时,参与节点取出本地事务中等待确定可见性的本地事务列表,全部唤醒。然后参与节点将本地事务加入回收链表,等待所有活动事务结束后,进行旧版本链的回收和索引的删除。接着参与节点可以向协调节点事务完成响应。
[0182]
需要说明的是,协调节点在基于隔离级别验证读写冲突时,如果某个表记录不可见,则说明其他事务修改了该表记录,产生读写冲突。协调节点可以终止事务,对事务进行回滚。在一些实施例中,协调节点接收参与节点的预同步响应时,如果包括错误响应,则协调节点也可以终止事务,对事务进行回滚。下面对回滚过程进行详细说明。
[0183]
具体地,参见图8所示的事务回滚阶段的流程图,协调节点(例如是分布式数据库系统100中的主节点1)向各参与节点(例如是分布式数据库系统100中的主节点2、主节点3、实时从节点1、实时从节点2等)发送事务回滚请求(如图8中所示的final-abort),该事务回滚请求携带各参与节点的lotxid。协调节点遍历本地事务中的写集合,回滚本次事务的修改。具体地,协调节点从索引树中删除写集合中的新版本表记录的索引,将写集合中的旧版本表记录在全局内存的第一个副本以及准实时从节点副本(如果有准实时从节点副本)的tmax设置为-1,将写集合中的旧版本表记录的indirect恢复成指向该旧版本,将所有写集合中的rhead记录的lotxid设置为0。此时,协调节点取出本地事务中的等待确定可见性的本地事务列表,全部唤醒。需要说明,被唤醒的事务会重新检查记录的可见性。然后协调节点将本地事务加入回收链表,等待所有活动事务结束后,进行新版本表记录的全局内存和本地内存回收。
[0184]
参与节点接收到事务回滚请求后,可以采用类似协调节点的处理。具体地,参与节点遍历写集合,应用本次事务的修改。其中,如果写集合中的旧版本表记录的全局内存在本节点有副本,将tmax设置为-1,然后将写集合中的旧版本表记录的indirect恢复成指向该
旧版本,将所有写集合中的rhead记录的lotxid设置为0。此时,参与节点取出本地事务中的等待确定可见性的本地事务列表,全部唤醒。参与节点将本地事务加入回收链表,等待所有活动事务结束后,进行新版本表记录的全局内存和本地内存的回收。
[0185]
对于query操作,协调节点(节点类型为主节点或实时从节点)可以确定可见的版本,直接向客户端返回表记录的记录数据。具体地,当事务隔离级别为ssi,该表记录尚未提交(tmin或tmax用于表示gtxid时,表明未提交)且本事务的begints>未提交记录对应的本地事务的begints,协调节点可以将本事务加入对方事务的等待队列,否则直接返回该表记录的记录数据。
[0186]
在一些可能的实现方式中,分布式数据库系统100还包括准实时从节点。该准实时从节点可以接收客户端发送的与分析业务关联的查询请求,通过回放redolog,在本地生成索引树和数据副本。具体地,准实时从节点可以定时(例如是间隔0.5秒)回放所有的redolog,通过redolog中记录的表记录的内容和全局内存地址,回放生成本地的索引树和新版本表记录的记录数据。
[0187]
为了保证回放redolog内容的一致性,准实时从节点可以取集群中所有活动事务的最小endts作为回放的截止时刻,redolog中小于该endts的事务日志会被回放。
[0188]
在本实施例中,事务提交协议定义了写冲突(写写冲突或读写冲突)控制方法。具体地,协调节点采用悲观并发控制(也称悲观锁),参与节点采用乐观并发控制(也称乐观锁),一方面可以避免写写冲突或者读写冲突,保证协调节点和参与节点之间的一致性,另一方面可以减少协调节点与参与节点的交互,缩短同步时间,实现实时一致。
[0189]
其中,悲观并发控制的原理为,假设多用户并发的事务在处理时彼此互相影响,因此,可以通过阻止一个事务来修改数据。具体地,如果一个事务执行的操作如读某行数据应用了悲观并发控制(悲观锁),那么只有当这个事务释放权限后,其他事务才能够执行冲突的操作。乐观并发控制的原理为,假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
[0190]
基于上述内容描述,本技术实施例提供了一种事务处理方法。该方法中,分布式数据库系统100的多个节点的部分内存通过用于形成全局内存。该全局内存对于分布式数据库系统100中的协调节点、参与节点可见。也即协调节点或参与节点中全局内存是共享的,当协调节点执行事务导致全局内存中的部分内存所存储的数据发生变化时,参与节点可以快速感知该变化,并基于事务提交协议通过rdma或memory fabric跨节点访问全局内存中的部分内存,以进行数据同步,而不必通过消息交互方式进行数据同步,如此大幅缩短同步时间,实现了协调节点和参与节点之间的实时一致性,满足了实时性业务对实时一致性的需求。此外,全局内存的容量可以随着节点数扩展,不再受限于单节点内存的容量,提高了并发控制能力。
[0191]
相较于传统的面向磁盘介质的磁盘引擎集群,本技术实施例提供的面向内存介质的内存引擎集群无页面且无回滚日志,具有较好性能。而且,本技术实施例提供不同类型的节点如主节点、实时从节点和准实时从节点,可以满足实时读写业务需求(如交易场景的需求)、实时只读业务需求(如实时分析场景的需求)或者是非实时只读业务需求(如非实时分
析场景)的需求。本技术实施例还可以按照表粒度设置表记录在全局内存中的副本数量,一方面可以控制内存占用,另一方面可以满足不同数据表的高可用性需求。
[0192]
上文结合图1至图8对本技术实施例提供的事务处理方法进行了详细介绍,下面将结合附图对本技术实施例提供的分布式数据库系统100、事务处理系统10进行介绍。
[0193]
参见图1所示的分布式数据库系统100的结构示意图,该分布式数据库系统100包括:
[0194]
协调节点,用于接收客户端发送的多条查询语句;
[0195]
协调节点,还用于根据所述多条查询语句中的第一查询语句创建事务,根据所述多条查询语句中的第二查询语句在所述全局内存中执行所述事务,以及根据所述多条查询语句中的第三查询语句提交所述事务。
[0196]
在一些可能的实现方式中,所述分布式数据库系统部署在集群,所述全局内存来自于所述集群。
[0197]
在一些可能的实现方式中,所述全局内存包括所述协调节点和/或所述参与节点的部分内存。
[0198]
在一些可能的实现方式中,所述协调节点的节点类型为主节点,所述协调节点具体用于:
[0199]
根据所述多条查询语句中的第一查询语句创建读写事务。
[0200]
在一些可能的实现方式中,所述协调节点的节点类型为第一从节点,所述第一从节点用于与节点类型为主节点的节点保持实时一致,所述协调节点具体用于:
[0201]
根据所述多条查询语句中的第一查询语句创建只读事务。
[0202]
在一些可能的实现方式中,所述协调节点,还用于接收并保存集群管理节点发送的表记录在所述全局内存中的副本数量;
[0203]
所述参与节点,还用于接收并保存所述集群管理节点发送的表记录在所述全局内存中的副本数量。
[0204]
在一些可能的实现方式中,所述表记录存储在所述分布式数据库系统的全局内存中,所述表记录的索引树和管理头存储在所述分布式数据库系统的本地内存中。
[0205]
在一些可能的实现方式中,所述协调节点具体用于:
[0206]
根据所述多条查询语句中的第三查询语句,通过运行于所述协调节点和所述参与节点的事务提交协议,提交所述事务,以实现所述协调节点和所述参与节点的实时一致性。
[0207]
在一些可能的实现方式中,所述协调节点具体用于所述事务发生写冲突时,触发悲观并发控制;
[0208]
所述参与节点具体用于所述事务发生写冲突时,触发乐观并发控制。
[0209]
根据本技术实施例的分布式数据库系统100可对应于执行本技术实施例中描述的方法,并且分布式数据库系统100的各个模块/单元的上述和其它操作和/或功能分别为了实现图4所示实施例中的各个方法的相应流程,为了简洁,在此不再赘述。
[0210]
基于本技术实施例提供的分布式数据库系统100,本技术实施例还提供了一种事务处理系统10。参见图1所示的事务处理系统10的结构示意图,该事务处理系统10包括:分布式数据库系统100和客户端200。
[0211]
其中,分布式数据库系统100用于根据所述客户端200发送的查询语句,执行对应
的事务处理方法,例如执行如图4所示的事务处理方法。具体地,客户端200用于向分布式数据库系统100发送多条查询语句,分布式数据库系统100的协调节点用于接收到多条查询语句,根据多条查询语句中的第一查询语句创建事务,根据所述多条查询语句中的第二查询语句在所述全局内存中执行所述事务,以及根据所述多条查询语句中的第三查询语句提交所述事务。
[0212]
在一些可能的实现方式中,事务处理系统10还包括数据库300,分布式数据库系统100执行事务处理方法,以对数据库300中的数据进行管理,例如插入新的记录数据,更新记录数据或者删除记录数据等等。
[0213]
类似地,事务处理系统10还包括集群管理节点400。该集群管理节点400用于对部署在集群中的分布式数据库系统的节点进行配置,例如对节点ip、节点类型等进行配置。事务处理系统10还可以包括授时服务器500,授时服务器500用于为分布式数据库系统100提供时间戳,以便根据时间戳确定数据对事务的可见性。
[0214]
本技术实施例还提供了一种集群90。该集群90包括多台计算机。该计算机可以是服务器,例如是私有数据中心中的本地服务器,或者是云服务提供商提供的云服务器。该计算机也可以是终端。终端包括但不限于台式机、笔记本电脑、智能手机等。集群90具体用于实现分布式数据库系统100的功能。
[0215]
图9提供了一种集群90的结构示意图,如图9所示,集群90包括多台计算机900。设备900包括总线901、处理器902、通信接口903和存储器904。处理器902、存储器904和通信接口903之间通过总线901通信。
[0216]
总线901可以是外设部件互连标准(peripheral component interconnect,pci)总线或扩展工业标准结构(extended industry standard architecture,eisa)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图9中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0217]
处理器902可以为中央处理器(central processing unit,cpu)、图形处理器(graphics processing unit,gpu)、微处理器(micro processor,mp)或者数字信号处理器(digital signal processor,dsp)等处理器中的任意一种或多种。
[0218]
通信接口903用于与外部通信。例如,通信接口903可以用于接收客户端200发送的多条查询语句,从授时服务器500获取开始时间戳、终止时间戳,或者是向客户端200返回提交响应等等。
[0219]
存储器904可以包括易失性存储器(volatile memory),例如随机存取存储器(random access memory,ram)。存储器904还可以包括非易失性存储器(non-volatile memory),例如只读存储器(read-only memory,rom),快闪存储器,硬盘驱动器(hard disk drive,hdd)或固态驱动器(solid state drive,ssd)。
[0220]
存储器904中存储有可执行代码,处理器902执行该可执行代码以执行前述事务处理方法。
[0221]
具体地,在实现图1所示实施例的情况下,且图1实施例中所描述的分布式数据库系统100的各组成部分为通过软件实现的情况下,执行图1中的各组成部分功能所需的软件或程序代码存储在存储器904中。处理器902执行存储器904中存储的各组成部分对应的程序代码,以执行前述事务处理方法。
[0222]
本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质包括指令,所述指令指示计算机900执行上述应用于分布式数据库系统100的事务处理方法。
[0223]
需要说明的是,该计算机可读存储介质中的指令可以被集群90中的多台计算机900执行,因此,每台计算机900也可以执行上述应用于分布式数据库系统100的事务处理方法的一部分。例如,一些计算机可以执行上述事务处理方法中由协调节点执行的步骤,另一些计算机可以执行上述事务处理方法中由参与节点执行的步骤。
[0224]
本技术实施例还提供了一种计算机程序产品,所述计算机程序产品被计算机执行时,所述计算机执行前述事务处理方法的任一方法。该计算机程序产品可以为一个软件安装包,在需要使用前述事务处理方法的任一方法的情况下,可以下载该计算机程序产品并在计算机上执行该计算机程序产品。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1