融合非对称卷积和注意力机制的遥感图像特征提取方法
1.本发明涉及图像特征提取方法领域,具体是一种融合非对称卷积和注意力机制的遥感图像特征提取方法。
背景技术:
2.深度残差网络(deep residual network,resnet)是2015年被提出,其通过特征提取实现分类,在imagenet分类任务上获得第一,刷新了cnn模型在imagenet上的历史。从经验来看,随着网络层数的不断加深,网络可以对更加复杂的特征进行提取,但经过实验发现网络层数加深时,网络准确度趋于饱和,甚至在下降。在深层网络进行训练的过程中存在着梯度消失和爆炸的现象,在论文《deep residual learning for image recognition》中,何凯明博士提出了残差学习来解决此问题,使用一种恒等映射(identity mapping)(具体构造如图1所示),将原网络的几层改成一个残差学习单元。
3.在何凯明博士提出的残差学习单元中,计算公式如下:
4.x
i+1
=x
i
+f(x
i
,w
i
)
ꢀꢀꢀꢀꢀꢀꢀ
(1)
5.公式(1)中,x
i
为残差学习单元的输入,w
i
为残差学习单元的权重,f(x
i
,w
i
)为残差映射,x
i+1
为残差学习单元的输出。从残差学习单元的输出可以观察到当网络层数加深时,该模型的性能至少不会下降,但其在特征提取时未能显著区分遥感图像的目标对象,模型的关键特征提取能力还需进一步提高。
技术实现要素:
6.本发明的目的是提供一种融合非对称卷积和注意力机制的遥感图像特征提取方法,以解决现有技术存在的在特征提取时未能显著区分遥感图像的目标对象问题。
7.为了达到上述目的,本发明所采用的技术方案为:
8.融合非对称卷积和注意力机制的遥感图像特征提取方法,包括以下步骤:
9.(1)、获取待提取特征的遥感图像数据;
10.(2)、生成第一神经网络模型,所述第一神经网络模型的网络架构采用包含五个依次串联的特征提取模块的resnet50,其中第一个特征提取模块包括一个卷积层,第二个特征提取模块包括三个依次串联的残差学习单元构成的卷积层,第三个特征提取模块包括四个依次串联的残差学习单元构成的卷积层,第四个特征提取模块包括六个依次串联的残差学习单元构成的卷积层,第五个特征提取模块包括三个依次串联的残差学习单元构成的卷积层;
11.每个残差学习单元分别包括三个依次串联的卷积核子单元,其中第一个卷积核子单元是大小为1
×
1的卷积核;第二个卷积核子单元由大小为3
×
3、1
×
3、3
×
1共三个卷积核并联构成;第三个卷积核子单元是大小为1
×
1的卷积核;每个残差学习单元中分别依次由第一个卷积核子单元进行压缩维度、第二个卷积核子单元进行卷积处理、第三个卷积核子单元进行恢复维度;
12.(3)、向步骤(2)生成的第一神经网络模型中每个残差学习单元的输出分别连接混合域注意力机制模块,得到第二神经网络模型;混合域注意力机制模块包括特征图提取子模块、融合子模块、分解子模块、sigmoid激活函数子模块、scale操作子模块,其中:
13.所述特征图提取子模块从对应的残差学习单元的输出中提取出水平和垂直两个方向的特征图;
14.所述融合子模块对水平和垂直方向的特征图进行特征融合,得到融合结果;
15.所述分解子模块将融合结果按水平方向的维度和垂直方向的维度进行分解,得到水平方向和垂直方向的分解结果;
16.所述sigmoid激活函数子模块对水平方向和垂直方向的分解结果进行激活处理;
17.所述scale操作子模块对sigmoid激活函数子模块的激活处理结果进行scale操作;
18.(4)、将步骤(1)获取的遥感图像数据,送入至步骤(3)中的第二神经网络模型,经第二神经网络模型处理后提取得到遥感图像的特征。
19.所述的融合非对称卷积和注意力机制的遥感图像特征提取方法,每个残差学习单元的第二个卷积核子单元中,三个并联的卷积核输出进行批量归一化处理后进行相加,作为第二个卷积核子单元的输出。
20.所述的融合非对称卷积和注意力机制的遥感图像特征提取方法,步骤(3)所述的混合域注意力机制模块中,特征图提取子模块将残差学习单元的输出首先分解为水平、垂直两个方向上一维的特征张量,并对两个一维的特征张量进行全局池化操作,以沿着水平方向和垂直方向分别进行聚合,得到对应方向的一维的特征图。
21.所述的融合非对称卷积和注意力机制的遥感图像特征提取方法,步骤(3)所述的混合域注意力机制模块中,融合子模块采用两个全连接和非线性relu操作,对水平和垂直方向的特征图进行处理,使水平和垂直方向的特征图进行特征融合。
22.一种遥感图像特征提取系统,包括处理器和存储器,所述存储器中存储有能够被处理器识别和运行的程序指令,所述处理器运行程序指令时执行权利要求1所述的遥感图像特征提取方法。
23.所述的一种遥感图像特征提取系统,所述程序指令包括第一子程序、第二子程序和第三子程序,所述处理器运行程序指令中第一子程序时执行所述步骤(1),所述处理器运行程序指令中第二子程序时执行所述步骤(2)、(3),所述处理器运行程序指令中第三子程序时执行所述步骤(4)。
24.与现有技术相比,本发明的优点为:
25.本发明提出了一种融合非对称卷积和注意力机制的遥感图像特征提取方法,该方法以resnet50网络为基础网络架构,并在resnet50网络中使用的残差学习单元的第二卷积核子单元采用非对称卷积,得到融合后的卷积,增强了模型在对数据集中的图像翻转和旋转的鲁棒性,同时将通道注意力特征和空间注意力特征融合提出获取特征位置信息的混合域注意力机制,提高了resnet50网络对遥感图像目标对象特征的提取能力。
26.通过实验证明,本发明方法在ucmerced_landuse数据及上总体分类精度为96.43%,在nwpu
‑
resisc45数据集上总体分类精度为92.71%,进而大大提高了基于特征提取的原始网络的分类效果。
附图说明
27.图1是现有技术残差学习单元原理图。
28.图2是resnet50残差学习单元原理图。
29.图3是本发明融合后的3
×
3卷积原理图。
30.图4是本发明采用非对称卷积的残差学习单元原理图。
31.图5是现有技术se模块原理图。
32.图6是se
‑
resnet结构原理图。
33.图7是本发明scam模块原理图。
34.图8是本发明scam_resnet结构原理图。
35.图9是ucmerced_landuse数据集部分样本。
36.图10是nwpu
‑
resisc45数据集部分样本。
37.图11是ucmerced_landuse数据集准确率和损失值随循环次数的变化结果。
38.图12是不同训练集占比的resnet与ac_scam_resnet50对比。
39.图13是nwpu
‑
resisc45数据集下实验二准确率和损失值随循环次数的变化结果。
40.图14是nwpu
‑
resisc45数据集下实验一准确率和损失值随循环次数的变化结果。
具体实施方式
41.下面结合附图和实施例对本发明进一步说明。
42.本发明包括以下步骤:
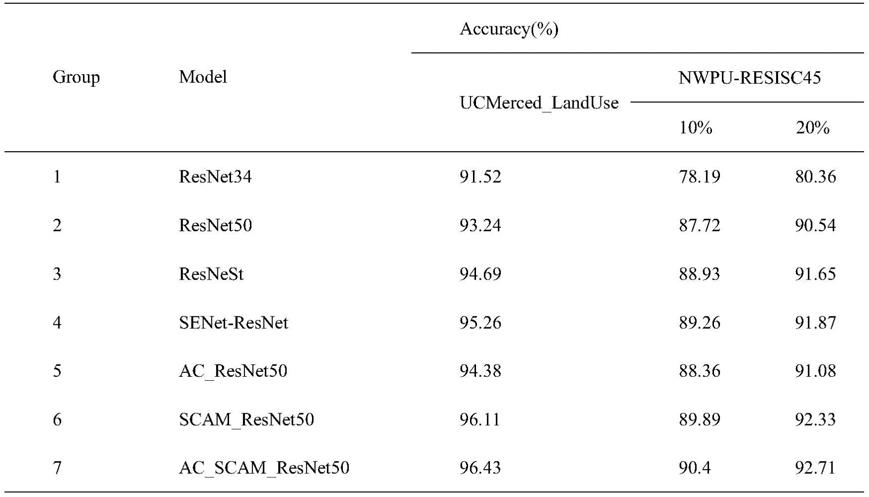
43.(1)、获取待提取特征的遥感图像数据;
44.(2)、生成基于resnet50网络的第一神经网络模型;
45.(3)、基以第一神经网络模型生成第二神经网络模型;
46.(4)、将步骤(1)获取的遥感图像数据,送入至步骤(3)中的第二神经网络模型,经第二神经网络模型处理后提取得到遥感图像的特征。
47.本发明还公开了一种遥感图像特征提取系统,该系统可为计算机、服务器等任何具备处理器和存储器的电子系统,存储器中存储有能够被处理器识别和运行的程序指令,程序指令包括第一子程序、第二子程序和第三子程序,处理器运行程序指令中第一子程序时执行所述步骤(1),处理器运行程序指令中第二子程序时执行所述步骤(2)、(3),处理器运行程序指令中第三子程序时执行步骤(4)。
48.本发明步骤(2)中,第一神经网络模型主要使用resnet50网络结构来进行改进,resnet50共有五个特征提取模块,第一个特征提取模块只有一个卷积层对输入进行提取,第二个特征提取模块包含由三个依次串联的残差学习单元构成的卷积层,第三个特征提取模块包含由四个依次串联的残差学习单元构成的卷积层,第四个特征提取模块包含由六个依次串联的残差学习单元构成的卷积层,第五个特征提取模块包含由三个依次串联的残差学习单元构成的卷积层。
49.对比resnet34,resnet50的残差学习单元发生了变化(如图2所示),每个残差学习单元由大小分别为1
×
1、3
×
3、1
×
1的三个卷积核串联构成,分别对应用于压缩维度、卷积处理和恢复维度。
50.在卷积的性质中有这样一条,如果几个具有兼容大小的二维内核在相同的输入上
以相同的步幅运行以产生具有相同的输出,可以将这些内核在相应的位置上相加,获得将产生相同输出的等效内核。可见二维卷积核是可以进行相加的,即使是不同大小的卷积核。
51.所以christian szegedy在论文《rethinking the inception architecture for computer vision》提出了可以通过1
×
n卷积和后面接一个n
×
1卷积替换任何n
×
n卷积,可以是参数计算量能节省,但精度却有明显的下降。
52.为了改善这一现象,本发明提出非对称卷积(asymmetric convolution)。在非对称卷积中,使用三个并联的n
×
n正方形卷积核,1
×
n水平卷积核和n
×
1垂直卷积核来替代n
×
n卷积,使用1
×
n和n
×
1卷积是为了增强模型在对数据集中的图像翻转和旋转的鲁棒性,这样组合不同层的输出来提高学习表示的质量。故在本发明resnet50网络中使用非对称卷积,将每个残差学习单元中大小为3
×
3的卷积核,以3
×
3、1
×
3和3
×
1三个并联的卷积核来取代,得到融合后的3
×
3卷积,如图3所示。
53.并且,本发明步骤(1)中与标准的cnn做法类似,在每个残差学习单元中并联的卷积核之后加上批量归一化操作(batch normalization),3
×
3、1
×
3和3
×
1三个并联的卷积核的并联输出作为对特征进行提取,采用非对称卷积的残差学习单元如图4所示。
54.注意力机制(attention mechanism)的思想是让网络学会注意力,能够忽略无关信息关注重要信息,本质是对区域的加权,突出显著的区域。近几年来,深度学习与注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。注意力机制可分为两类,一类是软注意力(soft attention),另一类是强注意力(hard attention)。软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成。强注意力是更加关注点延伸出来的注意力,同时强注意力是一个随机的预测过程,更强调动态变化,训练过程往往是通过强化学习(reinforcement learning)来完成的。
55.目前热门的注意力机制有通道注意力模块(channel attention module)、空间注意力模块(spatial attention module)和混合域注意力模块(mix attention module)。通道注意力就是对通道生成掩码,从而产生不同的权重,权重代表该通道与关键信息的相关度,权重越大表示相关度越高,也就是越需要去注意的通道了。代表作有senet,senet主要是通过显式地建模通道之间的相互依赖关系,学习了通道间的相关性,筛选出的面向通道的注意力,自适应地重新校准通道的特征响应。空间注意力就是对空间生成掩码,利用不同特征图之间的空间关系,以此来使模型注意特征图的哪些特征空间位置。代表作有spatial transformer networks(stn)模型。空间转换器(spatial transformer)模块,将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来,故stn模型能将原始图片中的空间信息变换到另一个空间中并保留了关键信息。对比这两种注意力,空间注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络其他层的可解释性不强。而通道注意力是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息,这种做法其实也是比较暴力的行为。所以提出混合域注意力机制模型。代表作有cbam(convolutional block attention module),cbam就是先后集成了通道注意力模块和空间注意力模块,来分
别在通道和空间维度上学习关注什么、在哪里关注,强调空间和通道这两个维度上的有意义特征。
56.在se
‑
resnet中,将se模块嵌入到resnet网络中,使用全局平均池化gap(global average gap)作为squeeze操作,也就是将h
×
w
×
c的输入转换为1
×1×
c的输出,这样能够获得全局的感受野。所以在给定输入x对其第c个通道的squeeze操作的公式为:
[0057][0058]
公式(2)中,x
c
(i,j)为输入图像样本,x
c
为输入图像的通道特征,w为特征维度,h为特征高度,f
sq
为进行squeeze操作。在excitation操作中,使用两个全连接来输出和输入相同数目特征的权重,第一个全连接w1的维度是c/r*c,r是缩放参数,是为了减少通道个数从而降低计算量,随后接一下非线性的relu操作使得输出维度不变,然后第二个全连接w2的维度为c*c/r,因此输出的维度为1
×1×
c,最后经过sigmoid激活函数得到的输出为:
[0059]
s=f
ex
(z
c
,w)=σ(w2relu(w1z
c
))
ꢀꢀꢀꢀꢀꢀ
(3)
[0060]
公式(3)中,σ为sigmoid激活函数,w1为第一个全连接层的维度,w2为第二个全连接层的维度,z
c
为经过squeeze操作的输出,f
ex
为进行excitation操作。
[0061]
excitation操作的输出表示了输入x中特征图的权重,这个权重是通过前面的全连接和relu操作得到的,因此可以端到端进行训练。最后的scale操作就是对通道进行相乘,也就是:
[0062]
f
scale
(x
c
,s)=x
c
*s
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0063]
公式(4)中,x
c
为原始的输入图像样本,s为excitation操作后的输出图像。se模块图如图5所示,se模块的灵活性使其可以嵌入到inception或resnet中,嵌入到resnet网络得到se_resnet结构如图6所示。
[0064]
虽然se
‑
resnet考虑通过对通道关系进行建模来重新权衡每个通道的重要性,但其忽略了位置信息,因此本发明步骤(3)中对此进行了改进,在se模块基础上提出一种新的混合域注意力机制模块scam(split and concat attention mechanism),由此得到第三神经网络,将特征图的准确位置信息融合到通道注意力中,这样可以增强对特征的表示,更准确地定位和识别特征,获取到要关注特征的准确位置信息。
[0065]
本发明步骤(3)中,混合域注意力机制模块(以下简称scam)将本发明步骤(2)中对应残差学习单元的输出分解为两个一维的特征张量,这两个一维的特征张量进行全局池化操作后,将沿着水平方向和垂直方向将输入信息分别去聚合两个方向的特征图,所以水平方向的输出为
[0066][0067]
式中x
c
(h,i)为输入图像在水平方向映射的样本对象。垂直方向的输出为:
[0068][0069]
公式(5)、(6)中,x
c
(j,w)为输入图像在垂直方向映射的样本对象,w为特征水平方向的维度,h为特征垂直方向的高度。
[0070]
紧接着将两个方向的特征图进行融合,跟se模块一样使用两个全连接和非线性relu操作,输出为:
[0071]
f
fc
=w2relu(w1[z
c
(h),z
c
(w)])
ꢀꢀꢀꢀꢀꢀ
(7)
[0072]
公式(7)中的[z
c
(h),z
c
(w)]为特征融合操作,w1为第一个全连接层的维度,w2为第二个全连接层的维度。
[0073]
随后将融合后的特征图分别沿着水平方向其维度w
h
为c
×
h、垂直方向其维度w
w
为w
×
c进行分解,并经过sigmoid函数激活处理得到:
[0074]
s
w
=σ(w
w
f
fc
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0075]
s
h
=σ(w
h
f
fc
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0076]
公式(8)、(9)中,σ均为sigmoid激活函数,s
w
为融合后的特征图分解后垂直方向的输出,s
h
为融合后的特征图分解后水平方向的输出,w
w
为垂直方向特征维度,w
h
为水平方向特征维度。
[0077]
最后进行的scale操作输出为:
[0078]
f
scale
(x
c
,s
w
,s
h
)=x
c
*s
w
*s
h
ꢀꢀꢀꢀꢀꢀ
(10)
[0079]
公式(10)中,x
c
为原始的输入图像样本,s
w
为融合后的特征图分解后垂直方向的输出,s
h
为融合后的特征图分解后水平方向的输出。scam模块图如图7所示,嵌入到resnet网络得到scam_resnet结构如图8所示。
[0080]
本发明实验及结果分析如下:
[0081]
1、数据集
[0082]
实验数据集采用遥感图像场景分类两大数据集ucmerced_landuse和nwpu
‑
resisc45。ucmerced_landuse中的数据选自美国地质调查局国家城市地图中的航空影像,包含农田、居民区、森林、油罐等21类场景,每类场景由100幅分辨率约为0.3m、大小为256
×
256像素的彩色影像组成,共计2100幅,图9为该数据集的部分样本示例。
[0083]
nwpu
‑
resisc45数据集是西北工业大学创建的遥感图像场景分类可用基准,在ucmerced_landuse数据集的基础上又增加了岛屿、船只、教堂、发电站等更加详细的场景,涵盖了45个场景类别,每个类别由大小为256
×
256像素、分辨率为从30m到0.2m不等的700张影像组成,共计31500幅,图10为该数据集的部分样本示例。nwpu
‑
resisc45比ucmerced_landuse数据集,场景更加复杂,分类的难度和挑战更大。由图10可以看出,高分辨率遥感影像的场景类别多样,不同类别的场景影像具有较大的相似性,同一类别的影像具有较大的差异性,如根据居民区的建筑物的稠密程度分为稀疏居民区、中等住宅区、密集住宅区等,同一类别的森林、河流等的影像在颜色和纹理具有较大的差异性,飞机、油罐等场景类别中既包含只有单个目标的图像又包含存在多个目标的图像,以上这些因素增加了其分类的难度。
[0084]
2、实验设置
[0085]
试验平台为intel(r)i7
‑
7700hk处理器、32g运行内存,并利用nvidia teslap100 16g显存加速运算,深度学习框架版本采用pytorch1.4。在训练过程中采用adam优化器,学习率设置为3e
‑
4,损失函数采用交叉熵损失函数,训练次数为400,确保模型的可靠性。实验结果中的loss曲线、准确率曲线均是由tensorboard可视化得到的数据绘制而成,以此用来分析网络的收敛情况。
[0086]
为了验证本发明算法的有效性,以及与其他论文结果进行对比,采用同等数据集划分方法。在ucmerced_landuse数据集和nwpu
‑
resisc45数据集分别进行实验。在ucmerced_landuse数据集上随机选取80%作为训练集,剩余20%作为测试集。由于nwpu
‑
resisc45数据集较为庞大,设置两类实验,实验一每类场景图像随机取10%作为训练集,剩余90%作为测试集;实验二每类场景图像随机取20%作为训练集,剩余80%作为测试集。
[0087]
3、实验结果及分析
[0088]
3.1 resnet系列对比实验
[0089]
在ucmerced_landuse数据集和nwpu
‑
resisc45数据集上分别就resnet34、resnet50、resnest、senet
‑
resnet、加入非对称卷积的ac_resnet50、scam_resnet50以及ac_scam_resnet50进行对比实验。实验结果如表1所示:
[0090]
表1 resnet系列网络在两大数据集的实验结果
[0091][0092]
在nwpu
‑
resisc45数据集下,本发明发现在两次实验中resnet34精度均大幅度落后于其他网络,这是由于其网络层数较浅,对特征的提取能力较弱。ac_resnet50比原始的resnet50分别提高了0.42%和0.54%,这说明在对3*3卷积核进行非对称分解后是有效的。resnest、senet
‑
resnet均是在resnet基础上加入了注意力机制,对遥感影像的特征提取能力均优于原始的resnet,scam_resnet50比resnest分别提高了0.96%和0.68%,比senet
‑
resnet分别提高了0.63%和0.46%,这说明在se模块基础上加入了空间位置信息是有效的,获取特征的通道信息的同时还获取其准确的位置信息,对特征的提取更加全面。在融合两种改进的模块后,ac_scam_resnet50网络的特征提取能力得到最大幅度的提升,分类精度达到90.4%和92.71%,比原始的resnet50分别提高了2.68%和2.17%。
[0093]
在ucmerced_landuse数据集进行实验的过程中,发现resnet34的精度并没有大幅度落后于resnet50,这是因为ucmerced_landuse数据集较小,网络层数的深浅对特征的提取能力影响有限,此时加深网络层数并不能对分类精度进行提高,甚至会出现过拟合。所以选择resnet50进行实验,ac_resnet50比原始的resnet50提高了1.14%,这说明在改进的非对称卷积对小数据集进行分类时提升较大,这是由于改进的非对称卷积使得高低层的特征
进行融合提高了网络的特征提取能力。scam_resnet50比resnest和senet
‑
resnet分别提高了1.42%和0.85%,充分说明了混合的注意力机制比单一的注意力机制更加有效,特征提取能力更强。ac_scam_resnet50比原始的resnet50提高了3.19%,说明了本发明方法的改进是有效的。
[0094]
3.2主流网络对比实验
[0095]
为了更好的进行对比,加入了目前深度学习领域主流网络和相同数据集下文献结果来参与实验。在ucmerced_landuse数据集下加入了经典的alexnet和vggnet,以及segnet、u
‑
net和deeplabv2,还有相同数据集下的文献如gbrcnn和se
‑
vgg16,分类结果如下表所示:
[0096]
表2主流网络在ucmerced_landuse数据集的实验结果
[0097][0098]
通过表2的结果可以看出,ac_scam_resnet50比经典网络alexnet和vggnet在分类精度上分别提高了4.07%和3.21%,与segnet、u
‑
net和deeplabv2相比提高了3.81%、3.19%和3.05%,同gbrcnn和se
‑
vgg16相比提高了1.9%和6.98%。
[0099]
在nwpu
‑
resisc45数据集下做实验二,也就是选取每类场景图像随机取20%作为训练集,剩余80%作为测试集。加入了densenet,fcn,以及deeplabv3和attentionu
‑
net,还有相同数据集下的文献如ecnn和resnet101
‑
cbam,分类结果如下表所示:
[0100]
表3主流网络在nwpu
‑
resisc45数据集的实验结果
[0101][0102]
通过表3结果可以看出ac_scam_resnet50比经典网络densenet和fcn在分类精度上分别提高了2.55%和3.02%,与attentionu
‑
net和deeplabv3相比提高了2.32%和1.17%,同ecnn和resnet101
‑
cbam相比提高了2.78%和0.21%。
[0103]
在与主流网络进行对比的结果中,可以发现在改进的非对称卷积和加入能够获取特征的准确位置信息的注意力机制的resnet50能够很大程度加强对遥感图像特征的提取能力,能够增强特征的表示,更好地实现场景分类。
[0104]
3.3结果分析
[0105]
为了更好的分析本发明方法在遥感图像场景分类中的有效性,图11展示了在两个实验数据集上准确率和损失值随循环次数的变化。
[0106]
图11是在ucmerced_landuse数据集下的准确率和损失值随循环次数的变化图,观察准确率曲线可以发现在通过约128次迭代后,分类精度趋于稳定,保持下93%上下,同时训练损失函数值也趋于稳定,在迭代387次后精度达到最佳为96.43%。
[0107]
由于ucmerced_landuse数据集类别数跟总数量较少,故为了比较在不同比例的训练集下的测试精度,将resnet50和ac_scam_resnet50分别进行实验,得到的结果绘制图如图12所示。从图12可以看出,在改进的resnet50实验中,随着训练集的增加,测试精度在上升,10%到20%的提升格外明显,精度从69%到81.37%,训练集比例为50%时,ac_scam_resnet50精度就已经达到91.34%,训练集比例为80%达到最高,但随着训练集的再次增加到90%时,精度却下降了1.91%,在resnet50实验中也有相同的现象,这是因为此时产生了过拟合,过少的测试集中的样本产生的干扰所导致的。
[0108]
图13是在nwpu
‑
resisc45数据集下实验二的准确率和损失值随循环次数的变化图,观察曲线可以发现准确率曲线可以发现在通过约99次迭代后,分类精度趋于稳定,保持下91%上下,同时训练损失函数值也趋于稳定,在迭代368次后精度达到最佳为92.71%。
[0109]
图14是在nwpu
‑
resisc45数据集下实验一的准确率和损失值随循环次数的变化图,观察曲线可以发现准确率曲线可以发现在通过约60次迭代后,分类精度趋于稳定,保持下88%上下,同时训练损失函数值也趋于稳定,在迭代360次后精度达到最佳为90.4%。
[0110]
本发明方法改进下的resnet50在两个数据集的实验中,测试数据集的准确率均能取得很好的效果,所以在遥感图像场景分类中融合改进的非对称卷积和注意力机制的resnet网络是有效的。
[0111]
本发明所述的实施例仅仅是对本发明的优选实施方式进行的描述,并非对本发明构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域中工程技术人员对本发明的技术方案作出的各种变型和改进,均应落入本发明的保护范围,本发明请求保护的技术内容,已经全部记载在权利要求书中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1