一种基于正则化贪心森林算法非侵入式负荷辨识方法
1.本发明涉及一种基于正则化贪心森林算法非侵入式负荷辨识方法,特别适合涉及在非侵入式负荷监测系统中。
背景技术:
2.随着智能电网广泛普及,居民用户侧成为其重要消耗端之一,通过对用户用电量的分项计量及实时反馈,能够引导居民自行产生合理用电习惯,对缓解能源危机起着至关重要的作用,同时帮助电网侧深入探究居民端的节能潜力和需求响应潜力;而非侵入式负荷监测是用电量分项计量的实现途径,负荷辨识作为非侵入式负荷监测的重要组分之一,具有重要研究意义;本发明针对现有高精度的基于深度学习的负荷识别算法运算复杂度高,无法用于家庭嵌入式设备的问题,公布了一种基于正则化贪心森林算法的非侵入式负荷辨识方法,该方法能够提高负荷识别精度,且模型具有良好的泛化能力,具有一定的应用价值。
技术实现要素:
3.本发明的主要目的是提出一种基于正则化贪心森林算法非侵入式负荷辨识方法。
4.本方法包括以下步骤:
5.step1使用某一区域的居民用电数据,对数据进行预处理;
6.step2选择v
‑
i轨迹作为负荷特征,轨迹特征的提取方法是通过映射将原始v
‑
i轨迹转化为二维v
‑
i轨迹,分析该特征轨迹图与样本数据的标签的相关性,使用与样本数据标签有相关性的负荷特征是为了提高负荷辨识的准确性;
7.step3使用基于正则化贪心森林算法的非侵入式负荷辨识方法进行负荷辨识,并得到辨识的结果。
8.本发明公开了一种基于正则化贪心森林算法非侵入式负荷辨识方法,首先提取某一区域的居民用电数据,对数据进行预处理;其次选择v
‑
i轨迹作为负荷特征,该特征的提取方法是通过二值映射法将原始v
‑
i轨迹转化为二维v
‑
i轨迹,同时分析该特征轨迹图与样本数据的标签的相关性,使用与样本数据标签有相关性的负荷特征是为了提高负荷辨识的准确性;最后使用基于正则化贪心森林算法的非侵入式负荷辨识方法进行负荷辨识,并得到辨识的结果;本发明方法可以提高负荷识别精度,避免了如深度学习的负荷识别算法的运算复杂度高且无法用于家庭嵌入式设备的问题,且模型的泛化能力良好,具有一定的应用价值。
附图说明
9.为了让读者更清晰地了解本专利实施方案,下面将对本专利具体实施方式中的附图作简单介绍:
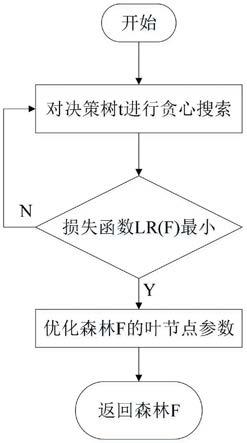
10.图1为本发明实施的正则化贪心森林算法流程图
11.图2为本发明实施的一种基于正则化贪心森林算法非侵入式负荷辨识方法结构图
具体实施方式
12.本发明的主要目的是提出了一种基于正则化贪心森林算法非侵入式负荷辨识方法。
13.本方法包括以下步骤:
14.采用正则化贪心森林算法在处理数据不平衡时以及在识别的具有相似特征轨迹时,具有较强的泛化能力,且算法运算复杂度较低,提高了算法的识别精度,具体包括以下步骤:
15.step1使用某一区域的居民用电数据,对数据进行预处理;
16.step2选择v
‑
i轨迹作为负荷特征,轨迹特征的提取方法是通过映射将原始v
‑
l轨迹转化为二维v
‑
i轨迹,分析该特征轨迹图与样本数据的标签的相关性,使用与样本数据标签有相关性的负荷特征是为了提高负荷辨识的准确性;
17.step3使用基于正则化贪心森林算法的非侵入式负荷辨识方法进行负荷辨识,并得到辨识的结果。
18.2.如权利要求1所述对获取的数据进行预处理,并获取该范围内各用户用电设备的相关信息,其特征在于:
19.采用某一区域的居民用电数据,对该数据进行预处理,因为样本出现数据不平衡时,少数类样本特征训练不充分,会导致算法的辨识准确率出现精度偏移;因此采用svmsmote算法对少数类样本进行扩充,以此生成新的数据样本;其合成的策略是使用支持向量机分类器产生支持向量,然后再生成新的少数类样本,最后使用smote过采样算法合成样本。
20.3.如权利要求2所述的选择v
‑
i轨迹作为负荷特征,并分析该特征轨迹图与样本数据的标签的相关性,其特征在于:
21.在用电设备稳定运行时一个周期内,高频电压u和i电流的波形数据,横坐标为u,纵坐标为i,绘制原始v
‑
i轨迹;
22.将v
‑
i二维平面分割为2n
×
2n的网格,每个网格的长度(即电压标准值)和高度(即电流标准值)计算如下:
[0023][0024]
初始化一个维度为2n
×
2n的二维矩阵β,其内的元素都赋值为1,即网格内的颜色初始化为白色,对原始v
‑
i轨迹中的数据点(u
j
,i
j
)(j=1,2,
…
,j),它在矩阵β中占据位置的索引为(x
j
,y
j
),如果0<x
j
<2n+1且0<y
j
<2n+1,则矩阵β的元素b(x
j
,y
j
)设置为0,表示设备的v
‑
i轨迹经过此单元格,标记为黑色:
[0025][0026]
4.如权利要求3所述的使用正则化贪心森林算法进行负荷辨识,其特征在于:
[0027]
在一棵决策树中,样本从根节点到子节点(不论是叶子节点还是非叶子节点)的这
样一条路径就形成了一条分类规则,所以对于决策树的一个子节点v来说,可以如下公式描述从根节点到这个子节点v的这个规则:
[0028][0029]
函数i(x)表示当括号中为真时结果为1,否则为0;如果b
v
(x)=1说明x经过决策树节点的判断,能够到达v这个节点,反之则无法到达;一个样本从根节点到子节点的过程中,在每个非叶子节点处都进行某个特征维度的值的二元测试(不是大于阈值就是小于阈值),在经过的全部非叶子节点处的测试中,有j个测试满足的是小于当前非叶子节点出的阈值的条件,有k个满足的是大于当前非叶子节点出的阈值条件;于是在决策树里面每一个节点v(叶子节点和非叶子节点)都可以用b
v
(x)来表示;因此,单棵决策树中,每个有着v1、v2两个子节点的节点v,都可以表示为子节点的组合:
[0030]
b
v
(x)=b
v1
(x)+b
v2
(x).
ꢀꢀꢀ
(4)
[0031]
因此决策森林模型可以类比成叶结点的组合模型,而不是决策树模型的组合:
[0032][0033]
当v不是叶子节点的时,a
v
=0;a
v
表示节点的权重参数;f表示决策森林;有了决策森林模型的叶子组合模型的表示,正则化贪心森林算法可以直接利用森林的结构直接学习贪心森林,而不是每次迭代的时候只是生成单棵决策树加入决策森林。
[0034]
本专利具有一定的普适性,在本发明的技术构思范围内对本发明的技术方案进行多种等同变换,又如直接或间接运用在其他相关的技术领域均在本发明的专利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1