基于规则匹配和深度学习的用户质检需求分类方法及系统
本发明涉及检验检测服务领域以及机器学习领域,具体涉及一种基于规则匹配和深度学习的用户质检需求分类方法及系统。
背景技术:
国内第三方检验检测网站内有各行业检验检测机构入驻,提供产品的质量检验检测服务,用户可通过主动联系或发布质检需求信息的方式联系机构。面对大量专业的检测服务,用户倾向于在网站内发布产品检测需求信息,让符合检测条件的机构联系。为实现用户需求与检测服务的准确匹配,将质检需求按行业分类是关键步骤。目前质检需求信息的分类主要由用户手动分类完成,效率较低且常出现误分类的情况。用户质检需求信息由检测待检测样品名称、检测内容、检测地点等组成,各行业发布的质检需求数量不均衡,且用户发布的文本信息较短、口语化、特征稀疏,为实现用户质检需求按行业自动分类需设计合适的分类模型,以提高质检需求文本分类的效率和准确率。为此,可利用自然语言处理和深度学习方法自动学习质检需求文本与行业标签间的联系,将训练好的分类模型应用于质检需求的分类,以此实现用户质检需求按行业自动、高效分类。
目前,现有用户质检需求分类方法包括:(1)目前质检需求文本的行业分类主要依靠用户手动分类为主,用户需要从众多的行业类别中选择特定的标签,分类效率低且受限于用户的知识储备,常出现误分类情况,影响检验检测服务的质量。(2)基于机器学习方法做质检需求文本分类,如支持向量机、k近邻、朴素贝叶斯等算法适用于小规模数据集,存在对文本的特征提取繁琐、模型泛化性能弱等不足;(3)基于卷积神经网络的文本分类方法,通过设置输入层、卷积层、池化层和输出层的参数预测文本类别,训练速度快,但无法获取文本的语序和语义信息,分类效果一般;(4)基于长短期记忆网络的文本分类方法,考虑了文本的上下文信息,分类性能较好,但在小规模数据集的分类效果一般;(5)fasttext:是一种快速的文本分类算法,但未充分考虑质检需求文本短小、专业词汇较多的特点,需要考虑文本特点设计合适的分类模型。
与新闻、用户评论等其它中文文本相比,用户发布的质检需求文本具有以下特点:(1)专业词汇较多,如“蛋白质/射频天线/氙灯/镇流器等”,这些词汇出现频率较低,但对分类结果影响较大,常用的文本分类方法未充分考虑这些文本特征,分类效果一般。(2)分类的行业类别数量达20多个,且各行业内的数据量不均衡。常见的深度学习模型在大规模数据集得到充分的学习训练,针对各行业的质检需求的数据量不均衡(多则几千条,少的百余条),利用深度学习模型的分类效果较差。(3)文本特征稀疏,质检需求由不同用户发布,在描述方面比较口语化,文本特征稀疏,质检需求的文本长度一般在15~150个字符间,一般由“待检测样品名称”、“检测内容”、“检测地点要求”字段组成,不同字段的分类能力不同,一般的文本分类方法未考虑这一点。
综上所述,基于用户经验的质检需求分类,预先设定多个行业类别,如:食品、农产品、环境、医药、电子电器、生物等20多个行业类别,用户根据自身知识储备进行分类,对于行业属性较模糊的产品易造成误分类。基于机器学习的文本分类方法,该类方法对文本特征提取的质量依赖性较强,且提取过程较繁琐,模型的泛化能力较弱。用户的质检需求量大且多样,需要一个高效、泛化性能较好的分类模型。基于深度学习的文本分类方法可自动学习文本与标签之间的联系,模型的泛化性能较好。常见的深度学习模型直接用于质检需求文本分类效果一般,质检需求文本与新闻、用户评论等文本数据相比,具有特征稀疏、文本短小和数据分布不均衡的特点,需要充分考虑质检需求文本特点,设计合适的分类方法。
技术实现要素:
本发明要解决的技术问题:针对现有技术的上述问题,考虑到与新闻、用户评论等文本数据相比,质检需求文本具有特征稀疏、文本短小和专业词汇较多的特点,提供一种基于规则匹配和深度学习的用户质检需求分类方法及系统,能够针对用户质检需求文本实现质检需求文本按所属行业自动、准确的分类。
为了解决上述技术问题,本发明采用的技术方案为:
一种基于规则匹配和深度学习的用户质检需求分类方法,包括:
1)对待分类文本与各个行业的专有名词词典进行匹配,并计算与各个行业对应的行业标签之间匹配的行业概率pi,选择值最大的行业概率pi记为最大行业概率值p;
2)若最大行业概率值p大于等于预设阈值g,则将最大行业概率值p对应的行业标签作为分类结果输出;否则,跳转执行下一步;
3)对待分类文本利用深度学习模型预测行业标签并计算预测的行业概率值h;针对最大行业概率值p、预测的行业概率值h两者,选择其中概率较大者所对应的行业标签作为最终的分类结果输出。
可选地,步骤1)包括:
1.1)首先提取待分类文本中的待检测样品名称和检测内容,然后分别将待检测样品名称和检测内容与各个行业的专有名词词典中的待检测样品名称和检测内容的专有词汇进行匹配,从而得到待检测样品名称的匹配状态s以及检测内容匹配的单词个数n;
1.2)根据待检测样品名称的匹配状态s以及检测内容匹配的单词个数n计算与各个行业对应的行业标签之间匹配的行业概率值pi;
1.3)选择值最大的行业概率值pi记为最大行业概率值p。
可选地,步骤1.2)中行业概率值pi的计算函数表达式为:
pi=a1*s+a2*n,
上式中,a1为待检测样品名称的权重,a2为每匹配一个词汇权重值增加的权重,s为待检测样品名称的匹配状态,待检测样品名称的匹配状态取值为0或1,0表示不匹配,1表示匹配,n为检测内容匹配的单词个数,其中a2*n在超过上限值时取上限值。
可选地,步骤1)之前还包括构建各个行业的专有名词词典的步骤:首先对各个行业的质检需求中的待检测样品名称和检测内容进行汇总,然后进行分词、去停用词和去重复词处理,最终得到各个行业的专有名词词典。
可选地,所述待分类文本为待检测样品名称增强的待分类文本,所述待检测样品名称增强是指待分类文本中待检测样品名称的出现频率为两次以上。
可选地,所述待分类文本的组合形式为a+a+b,其中a为待检测样品名称,b为检测内容。
可选地,步骤3)中的深度学习模型为基于注意力机制的长短期记忆网络模型lstm_a,所述基于注意力机制的长短期记忆网络模型lstm_a包括:
输入层,用于对待分类文本去除标点符号和单个数字字母、文本分词、去停用词和文本向量化表示,最终得到词向量矩阵x={x1,x2,…,xt};
lstm层,用于根据词向量矩阵x={x1,x2,…,xt}的时序性构建句向量,得到融合词序和语义的词向量集合h={h1,h2,…,ht},lstm层包括与词向量一一对应的多个lstm单元;
注意力层,用于将融合词序和语义的词向量集合h={h1,h2,…,ht}进行注意力层调整得到注意力层调整后的向量o={o1,o2,…,ot};
输出层,用于将注意力层调整后的向量o={o1,o2,…,ot}通过relu激活函数计算,然后经全连接层计算,最后利用归一化处理激活函数对数据进行归一化处理,得到当前待分类文本在各个行业类别中的概率h,并选取概率h最大的行业标签作为输出结果。
可选地,步骤3)之前还包括训练基于注意力机制的长短期记忆网络模型lstm_a的步骤,且训练时采用的损失函数为最小化交叉熵损失函数。
此外,本发明还提供一种基于规则匹配和深度学习的用户质检需求分类系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述基于规则匹配和深度学习的用户质检需求分类方法的步骤。
此外,本发明还提供一种计算机可读存储介质,该计算机可读存储介质中存储有被编程或配置以执行所述基于规则匹配和深度学习的用户质检需求分类方法的计算机程序。
和现有技术相比,本发明具有下述优点:针对现有技术的上述问题,考虑到与新闻、用户评论等文本数据相比,质检需求文本具有特征稀疏、文本短小和专业词汇较多的特点,本发明首先对待分类文本与各个行业的专有名词词典进行匹配,并计算与各个行业对应的行业标签之间匹配的行业概率值pi,选择值最大的行业概率值pi记为最大行业概率值p;若最大行业概率值p大于等于预设阈值g,则将最大行业概率值p对应的行业标签作为分类结果输出;否则,对待分类文本利用深度学习模型预测行业标签并计算预测的行业概率值h;针对最大行业概率值p、预测的行业概率值h两者,选择其中概率较大者所对应的行业标签作为最终的分类结果输出,通过上述规则匹配和深度学习的用户质检需求分类方式,能够针对用户质检需求文本实现质检需求文本按所属行业自动、准确的分类。
附图说明
图1为本发明实施例方法的基本流程示意图。
图2为本发明实施例方法的基本原理示意图。
图3为本发明实施例方法的核心流程示意图。
图4为本发明实施例中输入层的结构示意图。
图5为本发明实施例中lstm层和注意力层构成的特征提取单元的结构示意图。
图6为本发明实施例中lstm单元的结构示意图。
图7为本发明实施例中输出层的结构示意图。
具体实施方式
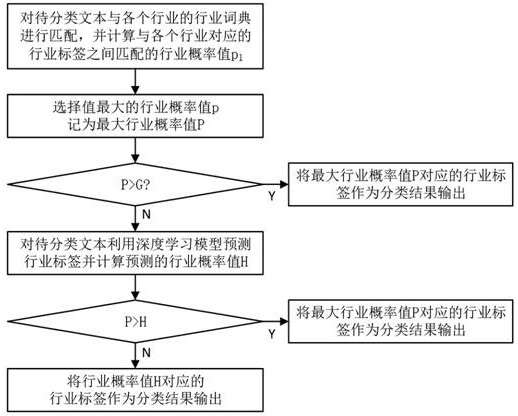
如图1所示,本实施例基于规则匹配和深度学习的用户质检需求分类方法包括:
1)对待分类文本与各个行业的专有名词词典进行匹配,并计算与各个行业对应的行业标签之间匹配的行业概率pi,选择值最大的行业概率pi记为最大行业概率值p;
2)若最大行业概率值p大于等于预设阈值g,则将最大行业概率值p对应的行业标签作为分类结果输出;否则,跳转执行下一步;
3)对待分类文本利用深度学习模型预测行业标签并计算预测的行业概率值h;针对最大行业概率值p、预测的行业概率值h两者,选择其中概率较大者所对应的行业标签作为最终的分类结果输出。
参见图2和图3,本实施例中步骤1)包括:
1.1)首先提取待分类文本中的待检测样品名称和检测内容,然后分别将待检测样品名称和检测内容与各个行业的专有名词词典中的待检测样品名称和检测内容的专有词汇进行匹配,从而得到待检测样品名称的匹配状态s以及检测内容匹配的单词个数n;
1.2)根据待检测样品名称的匹配状态s以及检测内容匹配的单词个数n计算与各个行业对应的行业标签之间匹配的行业概率值pi;
1.3)选择值最大的行业概率值pi记为最大行业概率值p。
参见图2,本实施例中,步骤1.2)中行业概率值pi的计算函数表达式为:
pi=a1*s+a2*n,
上式中,a1为待检测样品名称的权重,a2为每匹配一个词汇权重值增加的权重,s为待检测样品名称的匹配状态,待检测样品名称的匹配状态取值为0或1,0表示不匹配,1表示匹配,n为检测内容匹配的单词个数,其中a2*n在超过上限值时取上限值。
本实施例中,步骤1)之前还包括构建各个行业的专有名词词典的步骤:首先对各个行业的质检需求中的待检测样品名称和检测内容进行汇总,然后进行分词、去停用词和去重复词处理,最终得到各个行业的专有名词词典。。
针对质检需求文本短小、特征稀疏和专业词汇较多的特点,提出基于规则匹配和深度学习相结合的用户质检需求文本分类方法。质检需求文本示例如表1所示,选取“检测待检测样品名称”、“服务内容”字段作为待分类文本。
表1用户质检需求文本示例。
在文本预处理阶段进行关键词特征增强,利于后续深度学习模型获取关键特征信息。由于质检需求文本长度较短,关键词特征稀疏。测试发现,“检测待检测样品名称”具有较强的分类能力,在文中出现频率较低,一般由1~3个名词组成(如“直流/电源/检验”)。通过调整“待检测样品名称”在文本中出现频率的方式做特征增强。因此,本实施例中待分类文本为待检测样品名称增强的待分类文本,所述待检测样品名称增强是指待分类文本中待检测样品名称的出现频率为两次以上。
作为一种可选的实施方式,本实施例中选择的待分类文本的组合形式为a+a+b,其中a为待检测样品名称,b为检测内容。且要求输入文本中待检测样品名称和检测内容用特殊符号#分隔,以便于取出待检测样品名称和检测内容组成待分类文本的组合形式a+a+b。
本实施例中,步骤2)中的预设阈值g=0.6,权值a1设为0.45,a2设为0.05,若最大行业概率值p大于等于预设阈值0.6,则将最大行业概率值p对应的行业标签作为分类结果输出;否则,对待分类文本利用深度学习模型预测行业标签并计算预测的行业概率值h;针对最大行业概率值p、预测的行业概率值h两者,选择其中概率较大者所对应的行业标签作为最终的分类结果输出。
如图2所示,作为一种优选的实施方式,本实施例步骤3)中的深度学习模型为基于注意力机制的长短期记忆网络模型lstm_a,包括:
输入层,用于对待分类文本去除标点符号和单个数字字母、文本分词、去停用词和文本向量化表示,最终得到词向量矩阵x={x1,x2,…,xt};
lstm层,用于根据词向量矩阵x={x1,x2,…,xt}的时序性构建句向量,得到融合词序和语义的词向量集合h={h1,h2,…,ht},lstm层包括与词向量一一对应的多个lstm单元;
注意力层,用于将融合词序和语义的词向量集合h={h1,h2,…,ht}进行注意力层调整得到注意力层调整后的向量o={o1,o2,…,ot};
输出层,用于将注意力层调整后的向量o={o1,o2,…,ot}通过relu激活函数计算,然后经全连接层计算,最后利用归一化处理激活函数对数据进行归一化处理,得到当前待分类文本在各个行业类别中的概率h,并选取概率h最大的行业标签作为输出结果。
如图4所示,本实施例中输入层的处理过程包括:①分词和去停用词:本方法采用jieba分词工具的精确分词模式将质检需求文本分割成单独的词汇。去停用词,停用词是语言中的功能词,其本身无实际含义却常出现语言中,常见的停用词有:“的、了、那么”等。依照《哈工大停用词表》并补充质检需求中对分类结果无影响的单词构建停用词表,通过查表匹配的方式去除停用词。②文本向量化表示,本方法采用word2vec词嵌入模型,将分词后的文本作为word2vec模型的输入。输入文本分词后,首先映射单词的索引,将文本转换为固定长度的onehot(独热)词向量形式,设置onehot向量的长度为n;然后利用word2vec模型学习文本的特征联系,得到各个单词的词向量表示。
基于注意力机制的长短期记忆网络模型lstm_a将lstm和注意力机制相结合,利用lstm网络提取文本特征,基于注意力机制计算各个特征的注意力分数,以提取输入文本中的重要特征。其中lstm层和注意力层构成的特征提取单元的结构如图5所示,lstm层的输入为word2vec模型转换的词向量矩阵x={x1,x2,…,xt},lstm单元的个数设置为120,词向量矩阵维度与此一致。根据词向量时序性构建句向量,lstm层通过计算输出融合词序和语义的词向量集合h={h1,h2,…,ht}。
如图6所示,lstm单元分别包括遗忘门、输入门和输出门,其计算过程包括:
遗忘门接收上一lstm单元的输出ht-1和当前输入xt,利用sigmoid函数(用σ表示)将其映射为0~1间的数值,控制历史信息的遗忘程度,计算函数表达式为:
输入门由两部分组成:第一部分由σ函数产生输入门控制信号it,控制
细胞状态ct更新,首先确定上一细胞ct-1的保留信息,然后确定当前输入需保留的信息,将两部分相加得到当前细胞状态ct,计算过程为:
输出门读取更新过的细胞状态,该门由两部分组成:第一部分由σ函数产生控制信号ot,第二部分将ct经过tanh函数处理,并与ot相乘得到输出值ht,计算过程为:
其中wxf,whf,wxi,whi,wxo,who,wxc,whc为各个门的权值矩阵,bf,bi,bc,bo,为偏移系数矩阵。通过反向传播运算对各个门控单元的权值更新,控制各个门打开的程度,达到提取长期与短期文本特征的目的。
基于注意力机制的长短期记忆网络模型lstm_a的注意力层的计算过程为:将lstm层输出的h={h1,h2,…,ht}作为输入,将其变换为的3个值相同向量q(请求)、k(键)、v(值),各向量组合成以下形式:{q1,k1,v1;q2,k2,v2;…qt,kt,vt;}。注意力权重系数计算有3个阶段,首先利用点积的方式计算请求query和任意第i个键keyi的相似性si(query,keyi),计算式为:
si(query,keyi)=query·keyi
上式中,si(query,keyi)表示请求query和第i个键keyi的相似性,·为点积;
然后利用softmax函数对相似性值做归一化处理,其中lx为输入文本长度,计算式为:
上式中,αi为归一化处理得到的权值系数,si表示请求query和第i个键keyi的相似性si(query,keyi),sj表示请求query和第j个键keyj的相似性si(query,keyj)。
最终用将归一化处理得到的权值系数αi与valuei的加权求和运算,得到加权的特征值输出,计算式为:
上式中,αi为归一化处理得到的权值系数,valuei表示第i个值。
基于注意力机制的长短期记忆网络模型lstm_a的输出层的处理流程如图7所示。首先将注意力层调整后的向量o={o1,o2,…,ot}通过relu激活函数计算,然后经全连接层计算,最后利用softmax激活函数对数据进行归一化处理,得到当前输入文本在各个类别中的概率值,选取概率最大的类别标签作为输出结果。
本实施例中,步骤3)之前还包括训练基于注意力机制的长短期记忆网络模型lstm_a的步骤,且训练时采用的损失函数为最小化交叉熵损失函数。训练过程中,对采集用户质检需求信息按比例划分为训练集、验证集和测试集,采用dropout正则化策略,从训练集中随机抽取的一定数量的样本作为输入,通过前向推导得到预测结果。模型的训练目标为最小化交叉熵损失函数l,通过计算预测结果与实际结果的交叉熵损失值。使用梯度下降算法训练,利用adam优化器对模型的参数做自后向前的更新,通过重复前向推导和反向传播运算,使l不断逼近设定的训练目标值,达到后停止训练。
综上所述,用户的产品质检需求所属的行业类目数有20多个,每个行业发布的需求量不均衡。深度学习方法对于样本量不均衡的分类任务处理效果较差,利用规则匹配的方法可通过建立专有名词词典,实现样本量少的行业数据准确分类。本实施例方法通过两种方法的结合可提高模型对质检需求信息的分类性能。针对用户质检需求文本短小、特征稀疏和专业词汇多的特点,对分类能力较强的“待检测样品名称”字段增强处理,并在lstm分类模型引入注意力机制,提高模型对重要文本特征的提取能力。本实施例方法考虑待分类行业数量多且各行业的质检需求量分布不均衡,将基于规则匹配和深度学习方法结合,规则匹配方法的设计为,首先根据采集的语料信息构建各行业专业词典,对分词和去停用词的文本按规则匹配计算行业概率,当概率大于设定的阈值g直接输出分类结果。小于阈值g则利用深度学习模型预测,设计基于注意力机制的长短期记忆网络(lstmbasesonattentionmechanism,lstm_a)深度学习模型预测当前文本在各行业的概率,将基于规则匹配和深度学习两个模型预测的行业概率比较,取较大值作为行业标签的输出,可实现质检需求文本按所属行业自动、准确的分类。本实施例方法的特点包括:(1)针对用户手动分类质检需求信息的方式效率低,易出现误分类的情况,本方法提出基于规则和深度学习方法结合的用户质检需求文本分类方法,实现质检需求文本按设定的行业自动、准确的分类;(2)针对用户质检需求待分类的行业类别多,各行业的需求量不均衡,且质检需求文本短小、特征稀疏的特点,利用规则匹配的方式降低数据量分布不均衡带来的误分类,同时对于特征不明显的文本利用深度学习模型预测。经文本分类实验,该方法的文本分类准确率可达95.6%。(3)针对质检需求文本特征稀疏问题,对质检需求文本做关键特征增强处理,实验结果表明,特征增强处理提高文本分类的准确率,可提升1.0%~1.3%。本实施例方法可用于在第三方检验检测网站内将用户发布的质检需求分类至指定的行业,有助于检测需求与检测服务的匹配。
此外,本实施例还提供一种基于规则匹配和深度学习的用户质检需求分类系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行前述基于规则匹配和深度学习的用户质检需求分类方法的步骤。
此外,本实施例还提供一种计算机可读存储介质,该计算机可读存储介质中存储有被编程或配置以执行前述基于规则匹配和深度学习的用户质检需求分类方法的计算机程序。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!