一种自适应网络拓扑的分布式ADMM机器学习方法
一种自适应网络拓扑的分布式admm机器学习方法
技术领域
1.本发明属于机器学习技术领域,具体属于一种基于自适应网络拓扑的分布式admm机器学习方法。
背景技术:
2.近年来,随着信息产业高速发展,互联网规模不断扩大,大数据与机器学习在业务中使用的越来越频繁。在机器学习领域,大量的高维数据来自不同的节点,对计算能力提出了很高的要求,在这种情况下,单个节点很难解决此类问题,但分布式机器学习算法则能较好适应这种情况。
3.交替方向乘子法(alternating direction method of multipliers,admm)是机器学习中广泛应用的一种约束问题优化方法。它通过分解全局问题为局部问题,大大降低单次问题的成本,并且局部问题可以通过协调得到最终全局问题解。其有较大的扩展与优化的可能性,从最初的对偶上升、对偶分解与增广拉格朗日乘数法,到由stephen boyd提出admm,再到后期不断有人针对各种特定情况提出变种admm,其在凸优化问题中的处理优势被运用于各种领域中。
4.根据admm机器学习过程中迭代通信的方式,可以将其简单分为集中式与分布式两种模式。这里的集中式区别于常见的单机集中式,即系统仍旧是分布在若干个节点上,但所有节点都会与一个特定的节点进行通信。网络中存在一个中心节点与若干个普通节点,任意两个普通节点之间不会互相通信,任意一个普通节点将会与中心节点进行数据交换。中心节点在与所有普通节点通信后获取所有普通节点的局部子问题最优解,将所有解进行协调运算,得到一次迭代完成后的结果,然后将结果再次下发给所有节点重新运算。不同于集中式,网络中没有某一个特定的中心节点,网络中可以有多个中间节点,普通节点可以就近选择中间节点,最终再由中心节点进行数据汇总协调。将一个节点的压力分散到多个节点,更为符合互联网发展方向。该模式可以通过选择合适的中间节点避开质量较差的链路,从而加快迭代速度。且由于有多个中间节点,不会因为某一个中心节点的瘫痪导致整个系统的崩溃。
5.在分布式计算的情况下,节点之间需要不断通信来进行数据交互,并借此加快数据收敛速度。但由于节点之间通信需要借助网络,整体运行会受到网络情况的影响。若运算中存在不合适的节点交互,受到网络时延的影响,将会大幅度拖慢整体计算过程,且若所选对象不合适,可能会造成相应通信团体的数据被污染,从而导致数据收敛速度的减慢与收敛精度误差的增加。因此如何为每个独立的节点选择合适的通信对象团体成为一个不可避免地问题。本发明针对网络链路中的延迟对分布式系统的影响,提出了一种基于自适应网络拓扑的分布式admm机器学习方法。
技术实现要素:
6.本发明旨在解决以上现有技术的问题。提出了一种提高系统健壮性的情况下通过
自适应网络情况,使得节点分布更为合理,减少网络链路延迟影响自适应网络拓扑的分布式admm机器学习方法。本发明的技术方案如下:
7.一种自适应网络拓扑的分布式admm机器学习方法,其包括以下步骤:
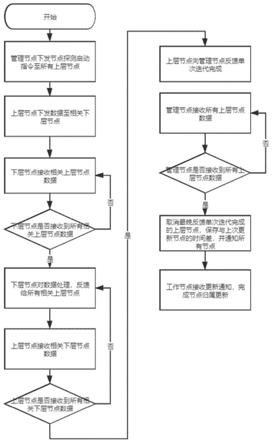
8.将节点分为1个管理节点与多个工作节点,并且将工作节点抽象为上层节点与下层节点;针对连通网络将全局凸优化问题分解成若干个局部凸优化问题并进行求解,并通过协调局部最优解得到全局最优解,其中机器学习方法包含节点探测与迭代计算两部分;节点探测部分包括上下层节点归属更新以及上下层节点通信以及管理节点与上层节点通信,迭代计算部分上下层相关节点数据通信与单次迭代计算。在节点探测过程中,工作节点将会运行迭代计算部分的更新,除此之外由上层节点在每次迭代完成时向管理节点反馈单次迭代完成;在选择上层节点位置时通过贪心思想避免遍历所有可能性,并采用动态选择,使网络中链路延迟的影响尽可能小。
9.进一步的,该方法用于求解正则化线性回归问题,即进一步的,该方法用于求解正则化线性回归问题,即其中a为m
×
n阶矩阵,b为m阶向量,λ为常数,x为n阶向量。
10.进一步的,所述节点探测部分具体包括以下步骤:
11.1)管理节点下发探测启动clustering start指令至上层节点,并记录当前时间t
s
;
12.2)上层节点i接收clustering start指令后下发数据至对应下层节点列表l
i
中的节点;
13.3)下层节点j接收数据并保存,直到接收到所有对应上层节点列表u
j
中的节点数据,进行计算操作,完成后将数据返回给所有对应上层节点u
j
;
14.4)上层节点i接收数据并保存,直到接收到所有对应下层节点列表l
i
中的节点数据,进行计算操作,完成后将数据返回给所有对应下层节点l;
15.5)上层节点向管理节点发送一次迭代完成iter over指令;
16.6)管理节点等待接收所有上层节点iter over指令并记录,当仅剩一个上层节点对应信息未收到时,将对应上层节点取消,获取当前时间t
c
,通过t
c
‑
t
s
获得单次完整系统迭代所需时间t
l
,将其保存在迭代时间集合t中,若t
i
为迭代时间集合t中最小值,即t
i
=mint,则保存当前系统上层节点集合u,否则不更新u;
17.7)管理节点下发节点归属更新update指令至所有上层与下层节点,节点收指令后进行对应节点归属更新操作;
18.8)重复流程3至流程7,直到网络中只剩下一个上层节点,此时管理节点保存的上层节点集合u为最终上层节点集合;
19.9)管理节点下发探测完成指令至所有上层节点与下层节点,节点收到指令后进行节点归属更新操作;
20.进一步的,上层节点和下层节点之间包含一种相关节点归属关系,即下层节点和有邻居关系的上层节点以及距离最近的上层节点相关;上层节点和有邻居关系的下层节点相关;若下层节点到该上层节点为到所有上层节点中距离最近,则上层节点与该下层节点也相关;每个下层节点可能与多个上层节点相关,每个上层节点也可能与多个下层节点相关。
21.进一步的,每个下层节点保存本地变量x与每个相关上层节点i对应的u
i
,每个上层节点保存本地变量z,所有变量x,u,z均为n阶向量,最初始状态均为n阶零向量。
22.进一步的,所述迭代计算部分包括以下步骤:
23.在第k次迭代计算中上层节点将下发z
k
至相关下层节点,下层节点通过公式
24.x
k+1
=(a
t
a+ρi)
‑1(a
t
b+ρ(z
k
‑
u
k
)),
25.u
k+1
=u
k
+x
k+1
‑
z
k+1
.
26.更新本地x,u,得到第k次迭代计算后的结果x
k+1
、z
k+1
与u
k+1
,其中a为n维实数闭凸集,i为n阶单位方阵,ρ>0为惩罚参数,并将更新后的x,u返回给相关上层节点,上层节点通过公式
[0027][0028]
更新本地z。其中表示软阈值算子,其形式为
[0029][0030]
进一步的,管理节点将会保存一个当前已完成迭代节点列表,设当前网络中上层节点数量为n,若已完成迭代节点列表长度为n
‑
1,则向整体网络通知去除唯一不在已完成迭代节点列表中的上层节点,将已完成迭代节点列表清空,并保存一份当前系统内上层节点列表s
n
‑1与两次列表清空之间时间间隔t
n
‑1;重复直到网络中只剩下一个上层节点。
[0031]
进一步的,对于i∈{1,...,n
‑
1},选取其中最小的t
i
,并将其对应的上层节点列表s
i
中上层节点作为最终系统内上层节点,通知所有工作节点进行正式的迭代计算部分;工作节点接收到通知后,初始化本地对应x,u,z变量,并进行相关节点归属更新,然后开始与相关节点开始迭代计算通信;当迭代次数达到系统预设的最大迭代次数时停止迭代计算。
[0032]
本发明的优点及有益效果如下:
[0033]
本发明通过分布式方法将计算压力从单个节点分散到整体系统内节点上,整体计算速度不再受限于单个节点的硬件处理能力,将高维数据拆分,维度降低后单个节点的迭代计算压力降低,速度加快。且保证了系统中上层节点数量至少为2个,即不会出现集中式星形模式,保证了系统的可靠性。最终上层节点的数量与位置由算法决定。通过采取类似层次聚类的方式,从最初的所有节点设置为上层节点,不断去除最慢上层节点,减少集群数量,直到最终比较得到单次系统迭代收敛最快对应的上层节点集合。采取贪心思想,避免了枚举所有可能性。确定上层节点集合时将各设备计算能力也考虑在内,而不是仅考虑网络时延却忽略节点之间差异。且由于节点探测部分设备计算时间与网络时延都被计算在单次迭代时间之中,故不需要提前了解各节点的运算能力。一定程度上降低网络延迟、拓扑变化等网络属性对分布式计算造成的影响。
附图说明
[0034]
图1是一种简单拓扑实施例节点对应关系;
[0035]
图2是本发明提供优选实施例小世界仿真网络拓扑图;
[0036]
图3是节点探测部分流程图;
[0037]
图4是正式迭代计算过程图解。
具体实施方式
[0038]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
[0039]
本发明解决上述技术问题的技术方案是:
[0040]
一种基于自适应网络拓扑的分布式admm机器学习方法,针对连通网络将全局凸优化问题分解成若干个局部凸优化问题并进行求解,并通过协调局部最优解得到全局最优解。
[0041]
进一步的,将整个机器学习方法分解为节点探测与迭代计算两部分。
[0042]
进一步的,将系统中节点分为一个管理节点与其余工作节点,将工作节点抽象为上层节点与下层节点两个属性,其中工作节点必定为下层节点,但不一定为上层节点,这将由算法决定。
[0043]
进一步的,提出一种相关节点归属方法,由于节点分为上层节点与下层节点,故归属更新也分为上下两部分。
[0044]
下层节点self归属更新部分流程为:
[0045]
1)遍历所有邻居节点,若邻居节点为上层节点,则将其添加至自己对应的上层节点列表u
self
中;
[0046]
2)遍历所有上层节点,获取该下层节点到所有上层节点u的时延t
u
,选取其中时延最短t
x
对应的上层节点x,将其加入下层节点i对应的上层节点列表u
self
中。
[0047]
由于上下层节点关系是对应的,即所有下层节点确定对应的相关上层节点后,上层节点对应的相关下层节点也已经确定,故可以从下层节点归属更新的流程逆推出上层节点u对应的相关下层节点列表l
u
,其流程为:
[0048]
1)遍历所有邻居节点,将邻居节点添加至对应的下层节点列表l
u
中;
[0049]
2)遍历所有下层节点,该下层节点到所有上层节点的时延{t1,...,t
n
}中,若至当前上层节点的时延t
i
=min{t1,...,t
n
},则添加该节点至对应的下层节点列表l
u
。
[0050]
进一步的,每个下层节点可能与多个上层节点相关,每个上层节点可能与多个下层节点相关。
[0051]
进一步的,每个下层节点保存本地变量x与每个相关上层节点i对应的u
i
,每个上层节点保存本地变量z。
[0052]
进一步的,在第k迭代计算中上层节点将下发z
k
至相关下层节点,下层节点通过公式
[0053]
x
k+1
:=(a
t
a+ρi)
‑1(a
t
b+ρ(z
k
‑
u
k
)),
[0054]
u
k+1
:=u
k
+x
k+1
‑
z
k+1
.
[0055]
更新本地x,u,其中a为n维实数闭凸集,i为n阶单位方阵,并将更新后的x,u返回给相关上层节点,上层节点通过公式
[0056]
[0057]
更新本地z。
[0058]
进一步的,在节点探测过程中,工作节点将会运行迭代计算部分的更新,并在此之外由上层节点在每次迭代完成时向管理节点反馈单次迭代完成。
[0059]
进一步的,管理节点将会保存一个当前已完成迭代节点列表,设当前网络中上层节点数量为n,若已完成迭代节点列表长度为n
‑
1,则向整体网络通知去除唯一不在已完成迭代节点列表中的上层节点,将已完成迭代节点列表清空,并保存一份当前系统内上层节点列表s
n
‑1与两次列表清空之间时间间隔t
n
‑1,重复直到网络中只剩下一个上层节点。
[0060]
进一步的,工作节点接收到管理节点通知的上层节点更新指令后,将会进行新的相关节点归属更新,重复直到网络中只剩下一个上层节点。
[0061]
进一步的,对于i∈{1,...,n
‑
1},选取其中最小的t
i
,并将其对应的上层节点列表s
i
中上层节点作为最终系统内上层节点,通知所有工作节点进行正式的迭代计算部分。
[0062]
进一步的,工作节点接收到通知后,初始化本地对应x,u,z变量,并进行相关节点归属更新,然后开始与相关节点开始迭代计算通信。当迭代次数达到系统预设的最大迭代次数时停止迭代计算。
[0063]
本发明通过将工作节点抽象为上层节点与下层节点,利用分布式admm算法求解凸优化问题的解,同时考虑到网络中链路延迟对不同节点间迭代计算时通信速度的影响,在选择上层节点位置时通过贪心思想避免遍历所有可能性,并通过动态选择,使网络中链路延迟的影响尽可能小。如图1所示,一个由5个工作节点与1个管理节点组成的简单拓扑网络,其中序号相同的上下层节点代表同一物理设备实体,由于每个工作节点的相关节点不局限于一个,故可以有多对多关系,如图1中上层节点1、3、5,以及下层节点2,3,4.。
[0064]
对于小世界仿真网络,选择1个管理节点与16个工作节点,任意一个工作节点有4个邻居工作节点,每条链路有90%的可能性被重置至其他两个节点间,大致拓扑如图2所示,其中不包含管理节点。
[0065]
最初,将所有工作节点都设为上层节点与下层节点。最初进入节点探测部分:
[0066]
1)管理节点下发探测启动(clustering start)指令至上层节点,并记录当前时间t
s
;
[0067]
2)上层节点i接收clustering start指令后下发数据至对应下层节点列表l
i
中的节点;
[0068]
3)下层节点j接收数据并保存,直到接收到所有对应上层节点列表u
j
中的节点数据,进行计算操作,完成后将数据返回给所有对应上层节点u
j
;
[0069]
4)上层节点i接收数据并保存,直到接收到所有对应下层节点列表l
i
中的节点数据,进行计算操作,完成后将数据返回给所有对应下层节点l;
[0070]
5)上层节点向管理节点发送一次迭代完成(iter over)指令;
[0071]
6)管理节点等待接收所有上层节点iter over指令并记录,当仅剩一个上层节点对应信息未收到时,将对应上层节点取消,获取当前时间t
c
,通过t
c
‑
t
s
获得单次完整系统迭代所需时间t
l
,将其保存在迭代时间集合t中,若t
i
为迭代时间集合t中最小值,即t
i
=mint,则保存当前系统上层节点集合u,否则不更新u;
[0072]
7)管理节点下发节点归属更新(update)指令至所有上层与下层节点,节点收指令后进行对应节点归属更新操作;
[0073]
8)重复流程3至流程7,直到网络中只剩下一个上层节点,此时管理节点保存的上层节点集合u为最终上层节点集合;
[0074]
9)管理节点下发探测完成指令至所有上层节点与下层节点,节点收到指令后进行节点归属更新操作;
[0075]
图3展示了上述步骤中单次聚类探测不同节点的通信过程,但探测过程会一直持续到网络中只剩下一个上层节点,并最终确定系统内上层节点。
[0076]
至此所有节点的归属已完成,网络中最终的上层节点确定,保存在u中,即节点聚类中心的数量与位置确定。上层节点确定后,下层节点的归属关系也可以较为容易通过归属更新部分得到。需要注意的是,这里选定的上层节点只是每一次探测迭代中选取的当前最优解,这是由贪心思想所决定的,相比遍历所有可能性并在正式计算前的聚类探测部分花去绝大部分时间,选择局部最优解更符合实际需求。
[0077]
在确定上层节点后,为了解决
[0078][0079]
x,u,z的更新如下所示
[0080]
x
k+1
=(a
t
a+ρi)
‑1(a
t
b+ρ(z
k
‑
u
k
)),#
ꢀꢀꢀ
(2)
[0081][0082]
u
k+1
=u
k
+x
k+1
‑
z
k+1
.#
ꢀꢀꢀ
(4)
[0083]
如图4所示,上层节点将会保存各自的z
i
,而各下层节点则保存自己的x
i
以及和相关上层节点数量相同的u
i
,即每个相关的上层节点在下层节点处都会有一个对应的u
i
,最初上层节点下发自己的z
i
给所有与自己相关的下层节点,下层节点收到后将其通过公式2与公式4的关系进行更新自己所拥有的u
i
与x
i
,并将两者返回给与自己相关的上层节点,上层节点收到所有下层节点的相关u
i
与x
i
后,通过公式3进行更新自己所拥有的z
i
,至此一次迭代完成。
[0084]
每次迭代完成后,上层节点都会根据当前的x,u,z求取问题1中的结果l
i
,并保存在本地,最终完成指定次数迭代后,对所有上层节点的每次迭代结果l
i
取平均,得到最终根据来判定结果收敛时间以及收敛时需要的迭代次数i。
[0085]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0086]
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1