一种智能监控的手势识别方法、装置、设备和存储介质
1.本发明涉及智能监控技术领域,具体而言,涉及一种智能监控的手势识别方法、装置、设备和存储介质。
背景技术:
2.为了能够及时的发现老人或者小孩子发生意外,往往会在老人和小孩活动的地方安装摄像头进行实时拍摄。同时,为了能够更加及时的知道老人或者小孩是否发生意外,会通过本地服务器、云服务器等设备对摄像头拍到的画面进行实时的分析,在判断到目标人物发生意外的时候生成警报通知相关人员。
3.特别地,在先技术中,能够通过分析监控视频中人物的手部动作来判断目标人物是否发生意外。由于人体手部比较灵活。因此,在先技术中,对手部的识别的计算量比较大,识别速率往往比较慢。有时甚至会出现服务器死机,导致无法及时的发出警报的问题。
技术实现要素:
4.本发明提供了一种智能监控的手势识别方法、装置、设备和存储介质,以改善相关技术中的手势识别速度慢的问题。
5.第一方面、
6.本发明实施例提供了一种智能监控的手势识别方法,其包含如下步骤:
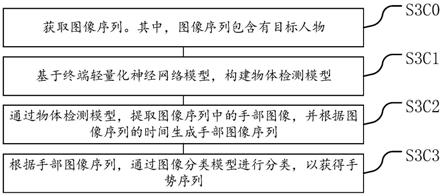
7.s3c0、获取图像序列。其中,图像序列包含有目标人物。
8.s3c1、基于终端轻量化神经网络模型,构建物体检测模型。
9.s3c2、通过物体检测模型,提取图像序列中的手部图像,并根据图像序列的时间生成手部图像序列。
10.s3c3、根据手部图像序列,通过图像分类模型进行分类,以获得手势序列。
11.可选地,终端轻量化模型为mnasnet模型。物体检测模型为ssd模型。
12.可选地,步骤s3c1具体包括:
13.s3c11、构建以mnasnet模型为主干网络的ssd模型。其中,主干网络依次包括:1层卷积核为3x3的conv,1层卷积核为3x3的speconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,4层卷积核为3x3的mbconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,1层卷积核为3x3的mbconv,1层pooling或者1层fc。
14.可选地,步骤s3c2具体包括:
15.s3c21、将图像序列逐帧输入主干网络,以使主干网络逐层对图像进行卷积。
16.s3c22、提取卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100的五个中间层进行回归分析,以获得手部图像的区域s3c23、根据区域从图像中提取手部图像。
17.可选地,步骤s3c0具体包括步骤s1和s2:
18.s1、接收目标区域的不同角度的多个监控视频。
19.s2、根据多个监控视频,分别获取目标区域中的各个人物的图像序列。
20.可选地,步骤s2具体包括:
21.s21、根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
22.s22、根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
23.s23、根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
24.第二方面、本发明实施例提供一种智能监控的手势识别装置,其包含:
25.序列模块,用于获取图像序列。其中,图像序列包含有目标人物。
26.模型模块,用于基于终端轻量化神经网络模型,构建物体检测模型。
27.检测模块,用于通过物体检测模型,提取图像序列中的手部图像,并根据图像序列的时间生成手部图像序列。
28.分类模块,用于根据手部图像序列,通过图像分类模型进行分类,以获得手势序列。
29.可选地,终端轻量化模型为mnasnet模型。物体检测模型为ssd模型。
30.可选地,模型模块具体用于:
31.构建以mnasnet模型为主干网络的ssd模型。其中,主干网络依次包括:1层卷积核为3x3的conv,1层卷积核为3x3的speconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,4层卷积核为3x3的mbconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,1层卷积核为3x3的mbconv,1层pooling或者1层fc。
32.可选地,检测模块,包括:
33.卷积单元,用于将图像序列逐帧输入主干网络,以使主干网络逐层对图像进行卷积。
34.分析单元,用于提取卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100的五个中间层进行回归分析,以获得手部图像的区域
35.提取单元,用于根据区域从图像中提取手部图像。
36.可选地,序列模块包括:
37.接收单元,用于接收目标区域的不同角度的多个监控视频。
38.骨架单元,用于根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
39.区域单元,用于根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
40.图像单元,用于根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
41.第三方面、本发明实施例提供一种智能监控的手势识别设备,其包括处理器、存储器,以及存储在存储器内的计算机程序。计算机程序能够被处理器执行,以实现如第一方面所说的手势识别方法。
42.第四方面、本发明实施例提供一种计算机可读存储介质,计算机可读存储介质包括存储的计算机程序,其中,在计算机程序运行时控制计算机可读存储介质所在设备执行
如第一方面所说的智能监控的手势识别方法。
43.通过采用上述技术方案,本发明可以取得以下技术效果:
44.本发明通过物体检测模型,从图像序列中提取手部的图像,然后再用图像分类模型识别手部的动作,大大提高了手势识别的效率,具有很好的实际意义。
45.为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
46.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
47.图1是本发明第一实施例提供的安全监控方法的流程示意图。
48.图2是目标区域的摄像头布局示意图。
49.图3是lstm模型的结构框图。
50.图4是ssd模型的结构框图。
51.图5是本发明第一实施例提供的安全监控方法的流程框图。
52.图6是人体骨骼模型的示意图。
53.图7是本发明第二实施例提供的安全监控装置的结构示意图。
54.图8是本发明第五实施例提供的安全监控方法的流程示意图。
55.图9是本发明第六实施例提供的安全监控装置的结构示意图。
56.图10是本发明第九实施例提供的安全监控方法的流程示意图。
57.图11是本发明第十实施例提供的安全监控装置的结构示意图。
58.图中标记:0
‑
序列模块、1
‑
视频模块、2
‑
图像模块、3
‑
系数模块、4
‑
等级模块、5
‑
人体模型模块、6
‑
人体坐标模块、7
‑
人体参数模块、8
‑
人体姿态模块、9
‑
区域模块、10
‑
表情模块、11
‑
初始模块、12
‑
最终模块、13
‑
模型模块、14
‑
检测模块、15
‑
分类模块。
具体实施方式
59.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
60.为了更好的理解本发明的技术方案,下面结合附图对本发明实施例进行详细描述。
61.应当明确,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
62.下面结合附图与具体实施方式对本发明作进一步详细描述:
63.实施例一、
64.请参阅图1至图6,本发明第一实施例提供的安全监控方法,其可由安全监控设备来执行,特别地,由安全监控设备内的一个或多个处理器来执行,以实现步骤s1至步骤s4。
65.s1、接收目标区域的不同角度的多个监控视频。
66.具体地,安全监控设备电连接于目标区域的监控系统,能够接收监控系统拍摄的到的监控画面并进行分析。如图2所示,该监控系统具有安装在目标区域的至少三个摄像头,摄像头安装在高于底面2.5m以上的地方,使得摄像头的拍摄视角和目标区域内的人像之间的夹角不大于45
°
。至少三个摄像头,分别布设在目标区域的不同角度。
67.需要说明的是,安全监控设备可以是云端的服务器,或者本地的服务器,又或者是本地的计算机,本发明对此不做具体限定。
68.s2、根据多个监控视频,分别获取目标区域中的各个人物的图像序列。
69.具体地,由于监控系统具有不同角度拍摄的多个摄像头。因此,监控视频中包含了目标区域中的各个人物的不同角度的视频流。需要从这些视频中选取各个人物的最适合进行后续分析操作的图像数据来进行后续的分析。
70.在上述实施例的基础上,本发明一可选实施例中,步骤s2具体包括步骤s21至步骤s23。
71.s21、根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
72.s22、根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
73.s23、根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
74.需要说明的是,当一个人进入到目标区域时,openpose模型会在多个监控视频流中,为同一个人进行同一个标识,并持续跟踪这个人。openpose模型能够标识出视频流中的人物的骨架信息。
75.在本实施例中,以骨架所占面积的大小来作为被摄像头拍摄到的人像的面积。针对目标区域中的各个人物,只提取其骨架面积最大的那个方向的摄像头所采集的图像来作为分析的依据。即,根据骨架信息,从多个视频流中,把每个人的骨架面积最大的图像信息提取出来,根据视频流的时间顺序,排序成图像序列。
76.可以理解的是,在图像中一个人的骨架面积最大的图像所对应的往往是一个人的正面。因此,提取出来的图像序列中,包含有各个人物的人脸表情信息、以及肢体手势信息。
77.在其它实施例中,还可以结合人脸识别模型,进一步保证所提取出来的图像序列为目标区域中,人物的正面的图像序列,以保证信息的有效性。
78.s3、根据图像序列,获取各个人物的身体姿态、面部表情序列和手势序列,并进行回归分析,以获得各个人物的安全系数。
79.具体地,通过一个人的身体姿态,面部表情和手势序列,能够判断出一个人的所处的状态。是否处于生气、剧烈运动的暴乱状态,或者安静平和的正常状态,根据采集到的这些状态和预先设置好的状态的序列进行回归分析,获得当前装下的安全系数。
80.在上述实施例的基础上,本发明一可选实施例中,步骤s3具体包括步骤s3a1至步骤s3a4。
81.s3a1、根据图像序列,获取关节点数据,并建立人体骨骼模型。其中,关节点数据包
括头部、颈部关节、躯干关节、右肩关节、右肘关节、右腕关节、左肩关节、左肘关节、左腕关节、右踝关节、左膝关节、左踝关节、左髋关节、左膝关节和左踝关节。
82.具体地,openpose模型已经将各个人物的各个关节点标识出来,并进行追踪。如图6所示,在本实施例中,从openpose模型定位出的多个关节点中,选取了以上15个关节点,从而建立一个足够构成肢体语言,关节点又相对较少,便于计算的人体骨骼模型。在其它实施例中,还可以选取更多或更少的关节点,本发明对此不做具体限定。
83.s3a2、根据人体骨骼模型,以躯干关节为原点,躯干关节指向颈部关节为z轴,左肩关节指向右肩关节为x轴,人体朝向方向为y轴建立人体动态坐标系,如图6所示。
84.s3a3、根据人体动态坐标系,将各个关节的坐标根据身高进行归一化处理后,计算身体参数。其中,参数包括身高、头到x轴的第一距离、右脚到x轴的第二距离、左脚到x轴的第三距离、身体倾斜角度、脚部角速度、肩部中心角速度和矩信息。
85.具体地,为了能够进一步分析目标区域中的各个人物的肢体语言信息,需要为每个图像序列中的人物建立一个坐标系,以分析各个关节点的位置信息,进一步的分析出肢体信息。
86.需要说明定的是,为了能够适应不同场景的区别,提高肢体语言判断的正确率。在本实施例中,将人体动态坐标系中的坐标信息,根据每个人的身高信息进行了归一化处理。在其它实施例中,为了减少计算量,也可以不进行归一化处理,本发明对此不做具体限定。在归一化处理后,根据各个关节点的坐标信息,计算出图像序列中任务的身体参数。归一化处理为现有技术,本发明在此不再赘述。
87.s3a4、根据身体参数,通过svm模型进行分类,以获得图像序列中人物的身体姿态。
88.具体地,将上述身体参数输入到svm模型,通过svm模型来获取图像序列中的任务的主体语言,例如:站立不动、缓慢匀速行走、匀速推缩手臂、水平方向挥臂、垂直方向挥臂等一系列人的动作姿势。通过svm模型分析人体行为特征,属于现有技术,本发明在此不再赘述。
89.在上述实施例的基础上,本发明一可选实施例中,步骤s3还包括步骤s3b1至步骤s3b4。
90.s3b1、通过人脸检测模型,获得图像序列中的人脸区域。
91.具体地,步骤s2中获取的图像序列中,包含有人物的正面信息。因此,通过人脸检测模型,从图像序列中检测出来人脸的区域,然后把这部分区域的图像提取出来,从而进一步分析人物的表情信息。
92.优选地,人脸检测模型为yolov3人脸识别模型。yolov3人脸识别模型具有良好的迁移性和多目标识别能力以及对小物体的识别能力。能够准确的从图像序列中将人脸区域识别出来。训练能够识别人脸的yolov3人脸识别模型为本领域技术人员的常规技术手段,本发明在此不再赘述。在其它实施例中,人脸识别模型可以为其它人脸识别模型,本发明对此不做具体限定。
93.s3b2、通过表情识别模型,获得人脸区域中的表情信息。
94.优选地,表情识别模型为vgg16表情分类模型。表情信息包括x类。其中,x类包括neutral、serious、panic、curious、surprise、happiness、despise。训练能够识别x类表情信息的vgg16表情分类模型为本领域技术人员的常规技术手段,本发明在此不再赘述。具体
地,通过yolov3人脸识别模型将人脸区域识别出来之后,将人脸区域提取出来输入到vgg16表情分类模型中,以获得图像序列中的人物的表情信息。在其它实施例中,表情识别模型可以为其它表情识别模型,本发明对此不做具体限定。
95.s3b3、根据图像序列的时间顺序和表情信息,生成初始表情序列。
96.在上述实施例的基础上,本发明一可选实施例中,步骤s3b3具体包括步骤s3b31和s3b32。
97.s3b31、图像序列中各帧的时间信息,生成时间序列t。
98.s3b32根据时间序列,对表情信息进行排序,以获得初始表情序列i。
99.具体地,将vgg16表情分类模型的识别结果按照时间顺序进行排序,从而获得初始表情序列i,时间顺序会影响预测模型的预测效果。因此,通过依次生成初始表情序列,能够为后续的预测模型提供良好的输入数据。具有很好的实际意义。
100.s3b4、根据初始表情序列,通过预测模型进行校正,以获得面部表情序列。
101.具体地,通过人脸识别模型和表情分类模型,能够快速的识别图像序列中的表情信息。但是由于这些信息是直接识别出来的,可能会存在个别帧识别错误的情况。为了避免识别错误的情况,在本实施例中,通过lstm预测模型来对vgg16表情分类模型的识别结果进行校正。从而避免表情识别错误的情况发生。其中,lstm预测模如图3所示,lstm模型的输入长度为n,单位长度的特征包括x类。其中,x类对应的就是前面vgg16表情分类模型所判断出来的图像序列中人脸的表情信息,对应的x中类别的表情的概率。在其它实施例中,预测模型可以使用其它现有的预测模型,本发明对此不做具体限定。
102.在上述实施例的基础上,本发明一可选实施例中,步骤s3b4具体包括步骤s3b41至s3b43。
103.s3b41、根据初始表情序列,分割成长度为n的输入序列。其中,输入长度n为11帧。在其它实施例中,输入长度还可以是其它帧数,本发明对此不做具体限定。
104.具体地,人脸表情的变化在时间序列上的表现往往是分段连续的,而并非离散,即在某一时间段内,表情出现突变的概率很低。因此,我们将初始表情序列分割成长度为n的输入序列进行分析,根据小邻域内的检测结果变化,来对其进行校正,提高其准确率。为得到最优的n的个数,发明人统计了整个样本,发现由vgg16分割得到的相同表情的持续时间序列区间为[11
‑
58],故发明人设计在10
‑
15之间找到最优的n,最终得到最优设计时间序列个数n=11。在本实施例中,选择输出元为11作为一次lstm的校正序列数量,实现了对表情识别能力的提高。
[0105]
s3b42、将输入序列输入至预测模型,以获得长度为n的输出序列。
[0106]
s3b43、根据输出序列,获得面部表情序列。
[0107]
具体地,将vgg16表情分类模型识别的结果,按照时间顺序排序,将排序后的表情序列序列记为i,并以i<i>表示序列中第i个表情。将对应时间序列记为t,将t<i>记为第i个表情出现的时间。将t与i信息输入lstm预测模型,通过lstm预测模型输出最终分类结果(1:neutral、2:serious、3:panic、4:curious、5:surprise、6:happiness、7:despise),记为f
a
,其中f
a
(t)为出现在t时刻的图片的分类结果。
[0108]
在上述实施例的基础上,本发明一可选实施例中,步骤s3还包括步骤s3c1至步骤s3c3:
[0109]
s3c1、基于终端轻量化神经网络模型,构建物体检测模型。
[0110]
具体地,图像序列中包含有整个人物的图像信息。因此,直接对其进行手势识别计算量较大。在本实施例中,通过构建物体检测模型,来从图像序列中识别并提取手部图像。进而提高识别速度和正确率。在本实施例中,终端轻量化模型为mnasnet模型。物体检测模型为ssd模型。在其它实施例中,终端轻量化模型和物体检测模型还可以是其它现有的模型,本发明对此不做具体限定。
[0111]
在上述实施例的基础上,本发明一可选实施例中,步骤s3c1包括步骤s3c11。
[0112]
s3c11、构建以mnasnet模型为主干网络的ssd模型。如图4所示,其中,主干网络依次包括:1层卷积核为3x3的conv,1层卷积核为3x3的speconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,4层卷积核为3x3的mbconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,1层卷积核为3x3的mbconv,1层pooling或者1层fc。
[0113]
具体地,将现有的ssd模型的主杆网络从vgg16卷积主干网络替换为mnasnet,能够减少目标检测过程中的计算量,大大提高目标检测的速度,具有很好的实际意义。
[0114]
s3c2、通过物体检测模型,提取图像序列中的手部图像,并根据图像序列的时间生成手部图像序列。
[0115]
在上述实施例的基础上,本发明一可选实施例中,步骤s3c2包括步骤s3c21至步骤s3c23。
[0116]
s3c21、如图4所示,将图像序列逐帧输入主干网络,以使主干网络逐层对图像进行卷积。
[0117]
s3c22、提取卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100的五个中间层进行回归分析,以获得手部图像的区域s3c23、根据区域从图像中提取手部图像。
[0118]
在本实施例中,发明人选择在mnasnet中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100五个中间层作为ssd框架下的候选区,再在这些候选区中按照ssd的经典方式对候选区进行回归分析,得到最后的定位结果。
[0119]
s3c3、根据手部图像序列,通过图像分类模型进行分类,以获得手势序列。
[0120]
由于mnasnet的结构相比于vgg16较为简单,不足以完成定位的同时完成分类的任务,故为了实现对手势的分类,再分割出最终框选出的最终区域,并最后将分割出的图像进行预处理,将其处理为适合vgg16网络输入尺度的图像,输入至vgg16网络进行运算,由vgg16完成最后对手部姿态的分类。相比于传统经典的vgg16网络为主干的ssd框架,替换候选区采集主干网络为mnanet网络结构,并在最后只对最后框选区使用vgg16进行分类的网络更为轻巧,量级更小,运算速度也相应的更加快速。两模型针对的参数组数对比如下所示。
[0121]
具体地,通过将图像序列的每一帧输入基于mnanet的ssd网络,通过mnanet进行卷积等操作,提取mnanet在卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100五个中间层作为手部所在区域的候选区,对这五个候选区通过经典ssd的分析方式对这五个中间层进行回归分析。将这个五个区域中其中置信度最高的区域所标识的手部区域作为手部所在的候选区域,将该候选区域的手部位置映射到原图上,将原图上的对应位置区域扣取出来送入vgg16进行手部姿态类别的分类,得到最终结果。
[0122]
在本实施例中,图像分类模型为vgg16分类模型。在其它实施例中,图像分类模型可以是其它分类/识别模型,本发明对此不做具体限定。
[0123]
s4、根据各个安全系数,生成相应的安全报警等级。
[0124]
在上述实施例的基础上,本发明一可选实施例中,步骤s4包括步骤s41至步骤s43。
[0125]
s41、根据各个安全系数,计算目标区域中小于预设的安全系数阈值的人数、安全系数的第一平均值和相邻场景的安全系数第二平均值。
[0126]
s42、将人数、第一平均值和第二平均值,按照时间顺序排列成时序特征。
[0127]
s43、根据时序特征,通过预测模型进行预测,以获得安全报警等级。
[0128]
具体地,首先计算场景中每个个体的特征向量。该特征向量计算方式为步骤s3中,计算得到的身体姿态、面部表情序列和手势序列。然后对这些特征向量进行回归分析计算出个体的安全系数。再将个体的安全系数与身体姿态、面部表情序列、手势序列的特征向量合并即得到各个个体的特征向量。
[0129]
其中,安全系数的计算方法为:先获取一些处于危险状态的个体图片,人工对这些图片进行指标评判,打上1
‑
10分的安全系数,在将这些场景送入步骤s3中的各个模型进行计算获得每个场景的三个特征向量v1、v2、v3,将三个特征向量与最终场景结果与人工打分结果合并生成一个样本。根据这些样本进行线性回归分析,根据生成的回归函数对要打分的场景进行计算,即将新场景的特征向量v1,v2,v3输入函数中计算得到安全系数
[0130]
将目标区域中所有人物的特征向量计算出来之后。根据这些特征向量计算小于安全系数阈值的人数、平均阈值、邻近场景阈值等特征,并将其按采集时间排列为时序特征,最终送入lstm进行安全等级评定,并根据评级结果以及具体使用场景实行相应级别的报警。其中,临近场景阈值为目标区域旁边的区域的安全系数阈值。
[0131]
本发明实施例,通过从过个角度的监控视频中提取出各个人物的较为适合分析的一个角度的图像序列,然后分别分析目标区域内的各个人物的身体姿态、面部表情序列和手势序列,根据这些信息,通过回归分析计算得到每个人的安全系数,然后根据这些安全系数生成相应等级的警报。不需要安排人员实时盯着监控,并且能够及时的发现警情,具有很好的实际意义。
[0132]
实施例二、本发明实施例提供一种安全监控装置,其包含:
[0133]
视频模块1,用于接收目标区域的不同角度的多个监控视频。
[0134]
图像模块2,用于根据多个监控视频,分别获取目标区域中的各个人物的图像序列。
[0135]
系数模块3,用于根据图像序列,获取各个人物的身体姿态、面部表情序列和手势序列,并进行回归分析,以获得各个人物的安全系数。
[0136]
等级模块4,用于根据各个安全系数,生成相应的安全报警等级。
[0137]
可选地,图像模块2具体包括:
[0138]
骨架单元,用于根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
[0139]
区域单元,用于根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
[0140]
图像单元,用于图像区域,从多个监控视频中,分别提取各个人物的图像序列。
[0141]
可选地,系数模块3包括:
[0142]
人体模型模块5,用于根据图像序列,获取关节点数据,并建立人体骨骼模型。其中,关节点数据包括头部、颈部关节、躯干关节、右肩关节、右肘关节、右腕关节、左肩关节、左肘关节、左腕关节、右踝关节、左膝关节、左踝关节、左髋关节、左膝关节和左踝关节。
[0143]
人体坐标模块6,用于根据人体骨骼模型,以躯干关节为原点,躯干关节指向颈部关节为z轴,左肩关节指向右肩关节为x轴,人体朝向方向为y轴建立人体动态坐标系。
[0144]
人体参数模块7,用于根据人体动态坐标系,将各个关节的坐标根据身高进行归一化处理后,计算身体参数。其中,参数包括身高、头到x轴的第一距离、右脚到x轴的第二距离、左脚到x轴的第三距离、身体倾斜角度、脚部角速度、肩部中心角速度和矩信息。
[0145]
人体姿态模块8,用于根据身体参数,通过svm模型进行分类,以获得图像序列中人物的身体姿态。
[0146]
可选地,系数模块3还包括:
[0147]
区域模块9,用于通过人脸检测模型,获得图像序列中的人脸区域。
[0148]
表情模块10,用于通过表情识别模型,获得人脸区域中的表情信息。
[0149]
初始模块11,用于根据图像序列的时间顺序和表情信息,生成初始表情序列。
[0150]
最终模块12,用于根据初始表情序列,通过预测模型进行校正,以获得面部表情序列。
[0151]
可选地,人脸检测模型为yolov3人脸识别模型。表情识别模型为vgg16表情分类模型。
[0152]
可选地,表情信息包括x类。其中,x类包括neutral、serious、panic、curious、surprise、happiness、despise。
[0153]
可选地,初始模块11包括:
[0154]
时间单元,用于图像序列中各帧的时间信息,生成时间序列t。
[0155]
初始单元,用于根据时间序列,对表情信息进行排序,以获得初始表情序列i。
[0156]
可选地,预测模型为lstm模型。lstm模型的输入长度为n,单位长度的特征包括x类。
[0157]
可选地,最终模块12包括:
[0158]
输入单元,用于根据初始表情序列,分割成长度为n的输入序列。
[0159]
输出单元,用于将输入序列输入至预测模型,以获得长度为n的输出序列。
[0160]
最终单元,用于根据输出序列,获得面部表情序列。
[0161]
可选地,输入长度n为11帧。
[0162]
可选地,系数模块3还包括:
[0163]
模型模块13,用于基于终端轻量化神经网络模型,构建物体检测模型。
[0164]
检测模块14,用于通过物体检测模型,提取图像序列中的手部图像,并根据图像序列的时间生成手部图像序列。
[0165]
分类模块15,用于根据手部图像序列,通过图像分类模型进行分类,以获得手势序列。
[0166]
可选地,终端轻量化模型为mnasnet模型。物体检测模型为ssd模型。
[0167]
可选地,模型模块13具体用于:
[0168]
构建以mnasnet模型为主干网络的ssd模型。其中,主干网络依次包括:1层卷积核为3x3的conv,1层卷积核为3x3的speconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,4层卷积核为3x3的mbconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,1层卷积核为3x3的mbconv,1层pooling或者1层fc。
[0169]
可选地,检测模块14包括:
[0170]
卷积单元,用于将图像序列逐帧输入主干网络,以使主干网络逐层对图像进行卷积。
[0171]
分析单元,用于提取卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100的五个中间层进行回归分析,以获得手部图像的区域
[0172]
提取单元,用于根据区域从图像中提取手部图像。
[0173]
可选地,等级模块4包括:
[0174]
阈值单元,用于根据各个安全系数,计算目标区域中小于预设的安全系数阈值的人数、安全系数的第一平均值和相邻场景的安全系数第二平均值。
[0175]
时序单元,用于将人数、第一平均值和第二平均值,按照时间顺序排列成时序特征。
[0176]
等级单元,用于根据时序特征,通过预测模型进行预测,以获得安全报警等级。
[0177]
实施例三、本发明实施例提供一种安全监控设备,其包括处理器、存储器,以及存储在存储器内的计算机程序。计算机程序能够被处理器执行,以实现如第一方面所说的安全监控方法。
[0178]
实施例四、本发明实施例提供一种计算机可读存储介质,计算机可读存储介质包括存储的计算机程序,其中,在计算机程序运行时控制计算机可读存储介质所在设备执行如第一方面所说的安全监控方法。
[0179]
实施例五、本实施例的表情识别方法,其实现原理和产生的技术效果和实施例一相同,本实施例为简要描述。本实施例未提及之处,可参考实施例一。
[0180]
请参阅图8,本发明实施例提供一种智能监控的表情识别方法,其可以由智能监控的表情识别设备或者安全监控设备来执行。特别地,由表情识别设备或者安全监控设备内的一个或多个处理器来执行,以至少实现步骤s3b0至步骤s3b4。
[0181]
s3b0、获取图像序列。其中,图像序列包含有目标人物。
[0182]
s3b1、通过人脸检测模型,获得图像序列中的人脸区域。
[0183]
s3b2、通过表情识别模型,获得人脸区域中的表情信息。
[0184]
s3b3、根据图像序列的时间顺序和表情信息,生成初始表情序列。
[0185]
s3b4、根据初始表情序列,通过预测模型进行校正,以获得面部表情序列。
[0186]
可选地,人脸检测模型为yolov3人脸识别模型。表情识别模型为vgg16表情分类模型。
[0187]
可选地,表情信息包括x类。其中,x类包括neutral、serious、panic、curious、surprise、happiness、despise。
[0188]
可选地,步骤s3b3具体包括:
[0189]
s3b31、图像序列中各帧的时间信息,生成时间序列t。
[0190]
s3b32根据时间序列,对表情信息进行排序,以获得初始表情序列i。
[0191]
可选地,预测模型为lstm模型。lstm模型的输入长度为n,单位长度的特征包括x类。
[0192]
可选地,步骤s3b4具体包括:
[0193]
s3b41、根据初始表情序列,分割成长度为n的输入序列。
[0194]
s3b42、将输入序列输入至预测模型,以获得长度为n的输出序列。
[0195]
s3b43、根据输出序列,获得面部表情序列。
[0196]
可选地,输入长度n为11帧。
[0197]
可选地,步骤s3b0具体包括步骤s1和s2:
[0198]
s1、接收目标区域的不同角度的多个监控视频。
[0199]
s2、根据多个监控视频,分别获取目标区域中的各个人物的图像序列。
[0200]
可选地,步骤s2具体包括:
[0201]
s21、根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
[0202]
s22、根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
[0203]
s23、根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
[0204]
在步骤s3b4之后还包括:
[0205]
s3、根据面部表情序列进行回归分析,以获得各个人物的安全系数。
[0206]
s4、根据各个安全系数,生成相应的安全报警等级。
[0207]
在上述实施例的基础上,本发明一可选实施例中,步骤s4包括步骤s41至步骤s43。
[0208]
s41、根据各个安全系数,计算目标区域中小于预设的安全系数阈值的人数、安全系数的第一平均值和相邻场景的安全系数第二平均值。
[0209]
s42、将人数、第一平均值和第二平均值,按照时间顺序排列成时序特征。
[0210]
s43、根据时序特征,通过预测模型进行预测,以获得安全报警等级。
[0211]
具体的实施方法请参照实施例一。在本实施例中为了节省计算量,提高识别速度,省略了关于身体姿态和手势序列的部分。在其它实施例中,也可以只省略身体姿态和手势序列中的一个。
[0212]
实施例六、请参阅图9,本发明实施例提供一种智能监控的表情识别装置,其包含:
[0213]
序列模块0,用于获取图像序列。其中,图像序列中包含有人的图像。
[0214]
区域模块9,用于通过人脸检测模型,获得图像序列中的人脸区域。
[0215]
表情模块10,用于通过表情识别模型,获得人脸区域中的表情信息。
[0216]
初始模块11,用于根据图像序列的时间顺序和表情信息,生成初始表情序列。
[0217]
最终模块12,用于根据初始表情序列,通过预测模型进行校正,以获得面部表情序列。
[0218]
可选地,人脸检测模型为yolov3人脸识别模型。表情识别模型为vgg16表情分类模型。
[0219]
可选地,表情信息包括x类。其中,x类包括neutral、serious、panic、curious、surprise、happiness、despise。
[0220]
可选地,初始模块11,具体包括:
[0221]
时间单元,用于根据图像序列中各帧的时间信息,生成时间序列t。
[0222]
初始单元,用于根据时间序列,对表情信息进行排序,以获得初始表情序列i。
[0223]
可选地,预测模型为lstm模型。lstm模型的输入长度为n,单位长度的特征包括x类。
[0224]
可选地,最终模块12,具体包括:
[0225]
输入单元,用于根据初始表情序列,分割成长度为n的输入序列。
[0226]
输出单元,用于将输入序列输入至预测模型,以获得长度为n的输出序列。
[0227]
最终单元,用于根据输出序列,获得面部表情序列。
[0228]
可选地,输入长度n为11帧。
[0229]
可选地,序列模块0包括实施例一中的视频模块和图像模块,其包括:
[0230]
接收单元,用于接收目标区域的不同角度的多个监控视频。
[0231]
骨架单元,用于根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
[0232]
区域单元,用于根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
[0233]
图像单元,用于根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
[0234]
可选地,序列模块0包括实施例一中的视频模块和图像模块,其包括:
[0235]
视频模块,用于接收目标区域的不同角度的多个监控视频。
[0236]
图像模块,用于根据多个监控视频,分别获取目标区域中的各个人物的图像序列。
[0237]
可选地,图像模块包括:
[0238]
骨架单元,用于根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
[0239]
区域单元,用于根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
[0240]
图像单元,用于根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
[0241]
表情识别装置还包括:
[0242]
系数模块3,用于根据面部表情序列进行回归分析,以获得各个人物的安全系数。
[0243]
等级模块4,用于根据各个安全系数,生成相应的安全报警等级。
[0244]
在上述实施例的基础上,本发明一可选实施例中,等级模块4包括。
[0245]
阈值单元,用于根据各个安全系数,计算目标区域中小于预设的安全系数阈值的人数、安全系数的第一平均值和相邻场景的安全系数第二平均值。
[0246]
时序单元,用于将人数、第一平均值和第二平均值,按照时间顺序排列成时序特征。
[0247]
等级单元,用于根据时序特征,通过预测模型进行预测,以获得安全报警等级。
[0248]
实施例七、本发明实施例提供一种智能监控的表情识别设备,其包括处理器、存储器,以及存储在存储器内的计算机程序。计算机程序能够被处理器执行,以实现如实施例五所说的智能监控的表情识别方法。
[0249]
实施例八、本发明实施例提供计算机可读存储介质包括存储的计算机程序,其中,在计算机程序运行时控制计算机可读存储介质所在设备执行如实施例五所说的智能监控的表情识别方法。
[0250]
实施例九、本实施例的手势识别方法,其实现原理和产生的技术效果和实施例一相同,本实施例为简要描述。本实施例未提及之处,可参考实施例一。
[0251]
请参阅图10,本发明实施例提供了一种智能监控的手势识别方法,其可以由智能监控的手势识别设备或者安全监控设备来执行。特别地,由手势识别设备或者安全监控设备内的一个或多个处理器来执行,以至少实现步骤s3c0至步骤s3c3。
[0252]
s3c0、获取图像序列。其中,图像序列包含有目标人物。
[0253]
s3c1、基于终端轻量化神经网络模型,构建物体检测模型。
[0254]
s3c2、通过物体检测模型,提取图像序列中的手部图像,并根据图像序列的时间生成手部图像序列。
[0255]
s3c3、根据手部图像序列,通过图像分类模型进行分类,以获得手势序列。
[0256]
可选地,终端轻量化模型为mnasnet模型。物体检测模型为ssd模型。
[0257]
可选地,步骤s3c1具体包括:
[0258]
s3c11、构建以mnasnet模型为主干网络的ssd模型。其中,主干网络依次包括:1层卷积核为3x3的conv,1层卷积核为3x3的speconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,4层卷积核为3x3的mbconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,1层卷积核为3x3的mbconv,1层pooling或者1层fc。
[0259]
可选地,步骤s3c2具体包括:
[0260]
s3c21、将图像序列逐帧输入主干网络,以使主干网络逐层对图像进行卷积。
[0261]
s3c22、提取卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100的五个中间层进行回归分析,以获得手部图像的区域s3c23、根据区域从图像中提取手部图像。
[0262]
可选地,步骤s3c0具体包括步骤s1和s2:
[0263]
s1、接收目标区域的不同角度的多个监控视频。
[0264]
s2、根据多个监控视频,分别获取目标区域中的各个人物的图像序列。
[0265]
可选地,步骤s2具体包括:
[0266]
s21、根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
[0267]
s22、根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
[0268]
s23、根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
[0269]
在步骤s3c3之后还包括:
[0270]
s3、根据手势序列进行回归分析,以获得各个人物的安全系数。
[0271]
s4、根据各个安全系数,生成相应的安全报警等级。
[0272]
在上述实施例的基础上,本发明一可选实施例中,步骤s4包括步骤s41至步骤s43。
[0273]
s41、根据各个安全系数,计算目标区域中小于预设的安全系数阈值的人数、安全系数的第一平均值和相邻场景的安全系数第二平均值。
[0274]
s42、将人数、第一平均值和第二平均值,按照时间顺序排列成时序特征。
[0275]
s43、根据时序特征,通过预测模型进行预测,以获得安全报警等级。
[0276]
具体的实施方法请参照实施例一。在本实施例中为了节省计算量,提高识别速度,省略了关于身体姿态和面部表情序列的部分。在其它实施例中,也可以只省略身体姿态和面部表情序列中的一个。
[0277]
实施例十、请参阅图11,本发明实施例提供一种智能监控的手势识别装置,其包含:
[0278]
序列模块0,用于获取图像序列。其中,图像序列包含有目标人物。
[0279]
模型模块13,用于基于终端轻量化神经网络模型,构建物体检测模型。
[0280]
检测模块14,用于通过物体检测模型,提取图像序列中的手部图像,并根据图像序列的时间生成手部图像序列。
[0281]
分类模块15,用于根据手部图像序列,通过图像分类模型进行分类,以获得手势序列。
[0282]
可选地,终端轻量化模型为mnasnet模型。物体检测模型为ssd模型。
[0283]
可选地,模型模块13具体用于:
[0284]
构建以mnasnet模型为主干网络的ssd模型。其中,主干网络依次包括:1层卷积核为3x3的conv,1层卷积核为3x3的speconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,4层卷积核为3x3的mbconv,2层卷积核为3x3的mbconv,3层卷积核为5x5的mbconv,1层卷积核为3x3的mbconv,1层pooling或者1层fc。
[0285]
可选地,检测模块14,包括:
[0286]
卷积单元,用于将图像序列逐帧输入主干网络,以使主干网络逐层对图像进行卷积。
[0287]
分析单元,用于提取卷积过程中的尺度为112
×
112
×
16、56
×
56
×
24、28
×
28
×
40、14
×
14
×
112、7
×7×
100的五个中间层进行回归分析,以获得手部图像的区域
[0288]
提取单元,用于根据区域从图像中提取手部图像。
[0289]
可选地,序列模块0包括实施例一中的视频模块和图像模块,其包括:
[0290]
接收单元,用于接收目标区域的不同角度的多个监控视频。
[0291]
骨架单元,用于根据多个监控视频,通过openpose模型获取目标区域中的各个人物的不同角度的骨架信息。
[0292]
区域单元,用于根据骨架信息,获取各个人物所在的图像区域。其中,图像区域为各个人物的骨架面积最大的图像所在的区域。
[0293]
图像单元,用于根据图像区域,从多个监控视频中,分别提取各个人物的图像序列。
[0294]
手势识别装置还包括:
[0295]
系数模块3,用于根据手势序列进行回归分析,以获得各个人物的安全系数。
[0296]
等级模块4,用于根据各个安全系数,生成相应的安全报警等级。
[0297]
在上述实施例的基础上,本发明一可选实施例中,等级模块4包括。
[0298]
阈值单元,用于根据各个安全系数,计算目标区域中小于预设的安全系数阈值的人数、安全系数的第一平均值和相邻场景的安全系数第二平均值。
[0299]
时序单元,用于将人数、第一平均值和第二平均值,按照时间顺序排列成时序特征。
[0300]
等级单元,用于根据时序特征,通过预测模型进行预测,以获得安全报警等级。
[0301]
实施例十一、本发明实施例提供一种智能监控的手势识别设备,其包括处理器、存储器,以及存储在存储器内的计算机程序。计算机程序能够被处理器执行,以实现如实施例九所说的手势识别方法。
[0302]
实施例十二、本发明实施例提供一种计算机可读存储介质,计算机可读存储介质包括存储的计算机程序,其中,在计算机程序运行时控制计算机可读存储介质所在设备执行如实施例九所说的智能监控的手势识别方法。
[0303]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1