神经网络机器翻译模型训练方法、机器翻译方法和装置
1.本发明涉及机器翻译技术领域,尤其涉及一种神经网络机器翻译模型训练方法、机器翻译方法和装置。
背景技术:
2.在5g的快节奏生活下,人们往往会使用一则视频和一段简短的文字来记录自己的生活。我们以抖音(tiktok)为例,应用数据公司sensortower的最新数据显示,tiktok全球下载量突破20亿人次。这不仅表示喜爱视频的人之多,同样也足以显示(短)视频全球化这一趋势。所以将视频信息作为机器翻译中文本的辅助信息,将在一定程度上顺应大时代的发展。具体来说,这个任务需要在理解源语言以生成适当的目标语言的同时,还需要从视频中学习到丰富而复杂的视觉信息。这不仅是具有较高学术研究价值的新兴多媒体研究领域,还存在一定的潜在实际应用场景,例如,在像tiktok以及微博等类似的社交媒体平台中翻译带有视频内容的帖子。
3.现有的大部分视频引导的机器翻译都是使用循环神经网络(recurrent neural network,rnn)作为其主要架构,在序列到序列范式下捕获时间依赖性。为了更好地利用视觉辅助信息,现有技术在整体视频特征上使用了注意力网络,来探索视频内部的潜在特征,然后再将两种模态的信息拼接喂入解码器中。与单独解码视频特征和源语言句子特征不同的是,有的研究人员利用注意机制对视觉特征和文本特征进行融合,使之在喂入解码器中时,是一个融合特征向量。此外,也有利用视频中的帧信息进一步提取视觉上的特征,例如通过非重叠帧来获取其图像模态和运动模态,或通过关键帧来加深对其外观特征和动作特征的理解,以此来生成更加有效的视频特征表示。
4.进一步地,目前流行的解决视频引导的机器翻译问题的方法已经深入到对局部语义理解的层面,通常会分别学习视频和源语言句子内容的表示形式,然后获得不同形式之间的交互作用或对齐方式。但是,现有方法集中于充分利用视频作为辅助材料,但忽略源语言和目标语言之间的语义一致性和可还原性。另外,视觉概念有助于改善不同语言的对齐和翻译,也很少被考虑。
技术实现要素:
5.本发明的目的在于提供一种神经网络机器翻译模型训练方法,能够提升机器翻译的精度。
6.本发明的目的还在于提供一种机器翻译方法,能够提升机器翻译的精度。
7.本发明的目的还在于提供一种机器翻译装置,能够提升机器翻译的精度。
8.为实现上述目的,本发明提供一种神经网络机器翻译模型的训练方法,包括如下步骤:
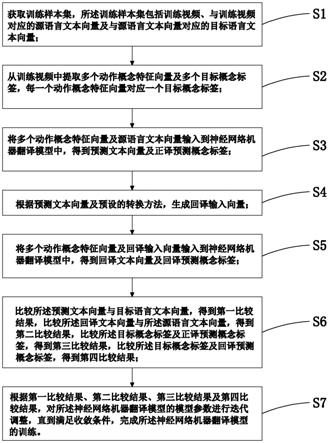
9.步骤s1、获取训练样本集,所述训练样本集包括训练视频、与训练视频对应的源语言文本向量及与源语言文本向量对应的目标语言文本向量;
10.步骤s2、从训练视频中提取多个动作概念特征向量及多个目标概念标签,每一个动作概念特征向量对应一个目标概念标签;
11.步骤s3、将多个动作概念特征向量及源语言文本向量输入到神经网络机器翻译模型中,得到预测文本向量及正译预测概念标签;
12.步骤s4、根据预测文本向量及预设的转换方法,生成回译输入向量;
13.步骤s5、将多个动作概念特征向量及回译输入向量输入到神经网络机器翻译模型中,得到回译文本向量及回译预测概念标签;
14.步骤s6、比较所述预测文本向量与目标语言文本向量,得到第一比较结果,比较所述回译文本向量与所述源语言文本向量,得到第二比较结果,比较所述目标概念标签及正译预测概念标签,得到第三比较结果,比较所述目标概念标签及回译预测概念标签,得到第四比较结果;
15.步骤s7、根据第一比较结果、第二比较结果、第三比较结果及第四比较结果,对所述神经网络机器翻译模型的模型参数进行迭代调整,直到满足收敛条件,完成所述神经网络机器翻译模型的训练。
16.具体地,所述步骤s2具体包括:
17.获取训练视频中的多个关键帧;
18.依据所述多个关键帧将所述训练视频拆分成多个动作片段,每一个动作片段均包括一关键帧及该关键帧之后的n个连续帧,n为正整数;
19.从每一个动作片段中提取一个动作概念特征向量及目标概念标签。
20.具体地,所述步骤s3具体包括:
21.对所述源语言文本向量及动作概念特征向量进行文本编码处理,得到概念引导的源语言文本向量;
22.解码所述概念引导的源语言文本向量,得到预测文本向量;
23.对所述源语言文本向量及动作概念特征向量进行概念编码处理,得到源文本引导的动作概念向量;
24.解码所述源文本引导的动作概念向量,得到正译预测概念标签。
25.具体地,所述步骤s4具体包括:
26.利用贪婪搜索或束搜索将所述预测文本向量转换为回译输入向量。
27.具体地,所述步骤s5具体包括:
28.对所述回译输入向量及动作概念特征向量进行文本编码处理,得到概念引导的回译输入向量;
29.解码所述概念引导的回译输入向量,得到回译文本向量;
30.对所述回译输入向量及动作概念特征向量进行概念编码处理,得到回译文本引导的动作概念向量;
31.解码所述回译文本引导的动作概念向量,得到回译预测概念标签。
32.具体地,所述步骤s6中:
33.所述第一比较结果用第一损失函数表示,所述第二比较结果用第二损失函数表示,所述第三比较结果用第三损失函数表示,所述第四比较结果用第四损失函数表示;
34.所述步骤s7包括:
35.依据第一权重融合所述第一损失函数及第二损失函数,得到文本损失函数;
36.依据第二权重融合所述文本损失函数、第三损失函数及第四损失函数,得到目标损失函数;
37.所述收敛条件为对所述神经网络机器翻译模型的模型参数进行迭代调整,使得所述目标损失函数最小。
38.具体地,n等于31。
39.本发明还一种机器翻译方法,包括如下步骤:
40.步骤s10、获取待翻译的文本及其对应的视频;
41.步骤s20、将待翻译的文本及其对应的视频输入神经网络机器翻译模型,得到所述待翻译的文本对应的翻译文本,所述神经网络机器翻译模型通过如权利要求1至7任一项所述的方法训练得到;
42.步骤s30、显示翻译文本。
43.本发明还提供一种机器翻译装置,包括:
44.获取模块,用于获取待翻译的文本及其对应的视频;
45.翻译模块,用于通过神经网络机器翻译模型获得所述待翻译的文本对应的翻译文本,所述神经网络机器翻译模型通过如权利要求1至7任一项所述的方法训练得到的;
46.显示模块,用于显示所述翻译文本。
47.本发明的有益效果:本发明提供一种神经网络机器翻译模型的训练方法,包括如下步骤:获取训练样本集,所述训练样本集包括训练视频、与训练视频对应的源语言文本向量及与源语言文本向量对应的目标语言文本向量;从训练视频中提取多个动作概念特征向量及多个目标概念标签,每一个动作概念特征向量对应一个目标概念标签;将多个动作概念特征向量及源语言文本向量输入到神经网络机器翻译模型中,得到预测文本向量及正译预测概念标签;根据预测文本向量及预设的转换方法,生成回译输入向量;将多个动作概念特征向量及回译输入向量输入到神经网络机器翻译模型中,得到回译文本向量及回译预测概念标签;比较所述预测文本向量与目标语言文本向量,得到第一比较结果,比较所述回译文本向量与所述源语言文本向量,得到第二比较结果,比较所述目标概念标签及正译预测概念标签,得到第三比较结果,比较所述目标概念标签及回译预测概念标签,得到第四比较结果;根据第一比较结果、第二比较结果、第三比较结果及第四比较结果,对所述神经网络机器翻译模型的模型参数进行迭代调整,直到满足收敛条件,完成所述神经网络机器翻译模型的训练,通过句子回译机制与概念回译机制进行模型训练,能够提升机器翻译的精度。
附图说明
48.为了能更进一步了解本发明的特征以及技术内容,请参阅以下有关本发明的详细说明与附图,然而附图仅提供参考与说明用,并非用来对本发明加以限制。
49.附图中,
50.图1为本发明的神经网络机器翻译模型的训练方法的流程图;
51.图2为本发明的神经网络机器翻译模型训练方法中的神经网络机器翻译模型的基本架构图;
52.图3为本发明的神经网络机器翻译模型训练方法中的神经网络机器翻译模型的详
细架构图;
53.图4为本发明的机器翻译方法的流程图;
54.图5为本发明的机器翻译装置的示意图。
具体实施方式
55.为更进一步阐述本发明所采取的技术手段及其效果,以下结合本发明的优选实施例及其附图进行详细描述。
56.请参阅图1至图5,本发明提供一种神经网络机器翻译模型的训练方法,包括如下步骤:
57.步骤s1、获取训练样本集,所述训练样本集包括训练视频、与训练视频对应的源语言文本向量及与源语言文本向量对应的目标语言文本向量;
58.具体地,所述步骤s1包括:
59.获取样本集,所述样本集包括源语言文本、与源语言文本对应的训练视频、及与源语言文本对应的目标语言文本;
60.通过嵌入算法将源语言文本及目标语言文本转换为向量;
61.接着在转换得到的向量中加入位置编码,得到源语言文本对应的源语言文本向量以及目标语言文本对应的目标语言文本向量;
62.进而得到包括训练视频、源语言文本向量及目标语言文本向量的训练样本集。
63.步骤s2、从训练视频中提取多个动作概念特征向量及多个目标概念标签,每一个动作概念特征向量对应一个目标概念标签。
64.具体地,所述步骤s2包括:获取训练视频中的多个关键帧;
65.依据所述多个关键帧将所述训练视频拆分成多个动作片段,每一个动作片段均包括一关键帧及该关键帧之后的n个连续帧,n为正整数;
66.从每一个动作片段中提取一个动作概念特征向量及目标概念标签。
67.举例来说,在本发明的一些实施例中,首先获取训练视频中的k个关键帧,然后,对于每一个关键帧,我们将随后的32帧(包括关键帧)重新编码为新的动作片段,得到k个动作片段,接着通过动作检测器从k个动作片段中获得k个动作概念特征向量和k个目标概念标签,它们被表示为v={a1,a2,
…
,a
k
}和l={l1,l2,
…
,l
k
},其中,v表示动作概念特征向量的集合,a1,a2,
…
,a
k
表示动作概念特征向量,l表示目标概念标签的集合,l1,l2,
…
,l
k
表示目标概念标签,k为正整数。
68.步骤s3、将多个动作概念特征向量及源语言文本向量输入到神经网络机器翻译模型中,得到预测文本向量及正译预测概念标签;
69.具体地,所述步骤s3具体包括:
70.对所述源语言文本向量及动作概念特征向量进行文本编码处理,得到概念引导的源语言文本向量;
71.解码所述概念引导的源语言文本向量,得到预测文本向量;
72.对所述源语言文本向量及动作概念特征向量进行概念编码处理,得到源文本引导的动作概念向量;
73.解码所述源文本引导的动作概念向量,得到正译预测概念标签。
74.具体地,在本发明的一些实施例中,所述神经网络机器翻译模型与动作检测器1相连,所述神经网络机器翻译模型包括:视频处理模块2、文本编码模块3、解码模块4、第一生成模块5及第二生成模块6;
75.其中,动作检测器1与视频处理模块2相连,视频处理模块2与第二生成模块6相连,文本编码模块3与所述视频处理模块2相连,解码模块4与文本编码模块3相连,第一生成模块5与解码模块4相连。
76.进一步地,如图3所示,在本发明的一些实施例中,所述视频处理模块2进一步包括多个级联的视频处理子层,每一视频编码子层均包括依次连接的多头注意力网络、残差&归一化层、全连接前馈网络及残差&归一化层;所述文本编码模块3包括多个级联的文本编码子层,每一文本编码子层均包括依次连接自注意力网络、残差&归一化层、多头注意力网络、残差&归一化层、全连接前馈网络及残差&归一化层;所述解码模块4包括多个级联的解码子层,每一解码子层均包括依次连接的自注意力网络、残差&归一化层、多头注意力网络、残差&归一化层、全连接前馈网络及残差&归一化层;所述第一生成模块5包括:依次连接线性层及softmax变换层;所述第二生成模块6包括:依次连接线性层及softmax变换层。
77.步骤s4、根据预测文本向量及预设的转换方法,生成回译输入向量;
78.具体地,所述步骤s4具体包括:
79.利用贪婪搜索或束搜索将所述预测文本向量转换为回译输入向量。
80.步骤s5、将多个动作概念特征向量及回译输入向量输入到神经网络机器翻译模型中,得到回译文本向量及回译预测概念标签。
81.具体地,所述步骤s5具体包括:
82.对所述回译输入向量及动作概念特征向量进行文本编码处理,得到概念引导的回译输入向量;
83.解码所述概念引导的回译输入向量,得到回译文本向量;
84.对所述回译输入向量及动作概念特征向量进行概念编码处理,得到回译文本引导的动作概念向量;
85.解码所述回译文本引导的动作概念向量,得到回译预测概念标签。
86.步骤s6、比较所述预测文本向量与目标语言文本向量,得到第一比较结果,比较所述回译文本向量与所述源语言文本向量,得到第二比较结果,比较所述目标概念标签及正译预测概念标签,得到第三比较结果,比较所述目标概念标签及回译预测概念标签,得到第四比较结果;
87.步骤s7、根据第一比较结果、第二比较结果、第三比较结果及第四比较结果,对所述神经网络机器翻译模型的模型参数进行迭代调整,直到满足收敛条件,完成所述神经网络机器翻译模型的训练。
88.具体地,所述步骤s6中:
89.所述第一比较结果用第一损失函数表示,所述第二比较结果用第二损失函数表示,所述第三比较结果用第三损失函数表示,所述第四比较结果用第四损失函数表示。
90.进一步地,所述步骤s7包括:
91.依据第一权重融合所述第一损失函数及第二损失函数,得到文本损失函数;
92.依据第二权重融合所述文本损失函数、第三损失函数及第四损失函数,得到目标
损失函数;
93.所述收敛条件为对所述神经网络机器翻译模型的模型参数进行迭代调整,使得所述目标损失函数最小。
94.具体地,在本发明的一些实施例中,将源语言文本翻译为预测文本向量的过程如下:
95.首先,通过嵌入算法将源语言文本转换为向量,再在该向量中加入位置编码,并经过多个自注意力网络处理,得到源语言文本过渡向量;
96.具体公式如下:
97.z
s
=sa
y
(pe(s))
98.其中z
s
表示源语言文本过渡向量,s表示源语言文本,pe和sa
y
分别代表位置编码处理和第y个自注意网络处理,y为正整数。
99.接着,通过多个多头注意力网络处理获得概念引导的源语言文本向量,具体公式如下;
[0100][0101][0102]
h
f
表示第f个多头注意力网络输出的权重,其中f∈h,表示概念引导的源语言文本向量,d
k
表示维度常数,softmax表示softmax函数,concat表示concat函数、及w1表示通过所述多个多头注意力网络处理获得概念引导的源语言文本向量时可训练的参数矩阵,f为正整数。
[0103]
最后,使用解码器获取预测文本向量,具体公式表示如下:
[0104][0105]
其中,z
t
表示预测文本向量,decoders表示解码器,至此完成了将源语言文本翻译为预测文本向量的过程,即正译的过程。
[0106]
随后,通过贪婪搜索来生成模拟源语句t
s
,换言之,t
s
即为回译输入向量。
[0107]
接着,将回译输入向量翻译为回译文本向量,具体翻译过程与上述的正译的过程一致,若定义翻译过程为为符号trans,那么将回译输入向量翻译为回译文本向量的过程可以用以下公式表示:
[0108]
s
t
=inference(trans(t
s
))
[0109]
其中inference表示贪婪或束搜索,s
t
为回译文本向量。
[0110]
最终得到如下文本损失函数公式:
[0111]
l
trans
=
‑
logp(t|s,v;θ)
‑
λ1logp(s
t
|t
s
,v;θ)
[0112]
其中p是概率,θ是文本训练参数,λ1是第一权重,l
trans
表示文本损失函数,logp(t|s,v;θ)表示第一损失函数,logp(s
t
|t
s
,v;θ)表示第二损失函数。
[0113]
进一步地,本发明中获得正译预测概念标签或回译预测概念标签的公式为:
[0114][0115]
其中ι∈{sl,tl},sl表示源语言,tl表示目标语言,当ι=sl时,ap
ι
表示正译预测
概念标签,表示概念引导的源语言文本向量,当ι=tl时,ap
ι
表示回译预测概念标签,表示概念引导的回译文本向量,mlp表示多层感知网络。
[0116]
进一步地,本发明还包括计算概念损失的步骤,具体公式如下:
[0117][0118]
其中,其中k表示一个视频中概念标签的个数,当j=sl时,l
label
表示第i个概念标签的正译损失,当j=tl时,l
label
表示第i个概念标签的回译损失,i为正整数且i≤k。
[0119]
最后,本发明中目标损失函数的公式为:
[0120][0121]
其中,ξ∈{f,b},f和b表示正译和回译的过程,为目标损失函数,θ
sl
为正译概念模型参数,θ
tl
为回译概念模型参数,为第三损失函数,为第四损失函数,文本损失函数。
[0122]
需要说明的是,本发明还通过采用因子设计预热机制,这意味着将对正向翻译过程进行步骤的预训练,然后再共同学习翻译和回译。
[0123]
请参阅图4,本发明还提供一种机器翻译方法,包括如下步骤:
[0124]
步骤s10、获取待翻译的文本及其对应的视频;
[0125]
步骤s20、将待翻译的文本及其对应的视频输入神经网络机器翻译模型,得到所述待翻译的文本对应的翻译文本,所述神经网络机器翻译模型通过上述的方法训练得到;
[0126]
步骤s30、显示翻译文本。
[0127]
请参阅图5,本发明还通过一种机器翻译装置,包括:
[0128]
获取模块100,用于获取待翻译的文本及其对应的视频;
[0129]
翻译模块200,用于通过神经网络机器翻译模型获得所述待翻译的文本对应的翻译文本,所述神经网络机器翻译模型通过上述的方法训练得到的;
[0130]
显示模块300,用于显示所述翻译文本。
[0131]
从而,本发明首先利用句子级的回译来获得粗粒度的语义,此后,提出了一个概念级回译模块,以探索细粒度的语义一致性和可还原性,最后,提出了一种多范式联合学习方法来提高翻译性能。
[0132]
综上所述,本发明提供一种神经网络机器翻译模型的训练方法,包括如下步骤:获取训练样本集,所述训练样本集包括训练视频、与训练视频对应的源语言文本向量及与源语言文本向量对应的目标语言文本向量;从训练视频中提取多个动作概念特征向量及多个目标概念标签,每一个动作概念特征向量对应一个目标概念标签;将多个动作概念特征向量及源语言文本向量输入到神经网络机器翻译模型中,得到预测文本向量及正译预测概念标签;根据预测文本向量及预设的转换方法,生成回译输入向量;将多个动作概念特征向量及回译输入向量输入到神经网络机器翻译模型中,得到回译文本向量及回译预测概念标签;比较所述预测文本向量与目标语言文本向量,得到第一比较结果,比较所述回译文本向量与所述源语言文本向量,得到第二比较结果,比较所述目标概念标签及正译预测概念标签,得到第三比较结果,比较所述目标概念标签及回译预测概念标签,得到第四比较结果;
根据第一比较结果、第二比较结果、第三比较结果及第四比较结果,对所述神经网络机器翻译模型的模型参数进行迭代调整,直到满足收敛条件,完成所述神经网络机器翻译模型的训练,通过句子回译机制与概念回译机制进行模型训练,能够提升机器翻译的精度。
[0133]
以上所述,对于本领域的普通技术人员来说,可以根据本发明的技术方案和技术构思作出其他各种相应的改变和变形,而所有这些改变和变形都应属于本发明权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1