一种基于深度学习的驾驶员疲劳驾驶实时检测方法及系统
1.本发明涉及计算机视觉与深度学习领域,具体涉及一种基于深度学习的驾驶员疲劳驾驶实时检测方法及系统。
背景技术:
2.随着汽车的广泛普及,驾驶安全问题越来越受到重视。疲劳驾驶是引发交通事故的常见原因之一,但在行车过程中,驾驶员往往无法评估自己的疲劳状态,因而,使用外部设备实时检测驾驶员的疲劳状态,对异常状态进行提醒,能够有效预防交通事故的发生,降低交通安全隐患。
3.按照数据的测量方式,疲劳驾驶检测方法可分为三大类:基于汽车行驶状态的方法、基于驾驶员生理特征的方法,以及基于计算机视觉的方法。
4.基于汽车行驶状态的方法利用疲劳驾驶时出现驾驶员反应变慢、控制操作变差等异常驾驶行为,需要测量车速、方向盘操作、车道偏移等多种车辆行驶信息。但汽车行驶信息的测量需要大量的专业设备,成本较高,目前只有一些汽车的高端车型使用,且该方法受车型、驾驶习惯等因素的影响较大,不具有通用性。
5.基于驾驶员生理特征的方法通过测量驾驶员的脑电、心电和肌电等信号,来判断驾驶员的疲劳状态。由于可直接对生理特征进行测量,该方法可靠性与准确度相对更高,但测量设备需要与驾驶员进行接触,安装方式复杂,可能干扰到驾驶员的正常操作,目前仍停留在实验阶段。
6.基于计算机视觉的方法设备相对简单,通常使用神经网络提取驾驶员的面部特征,进而识别驾驶员的疲劳状态。但在实际应用中,高精度的深度神经网络参数多、运算慢,无法满足疲劳驾驶检测的实时性要求;另一方面深度神经网络高度依赖训练数据集,针对疲劳驾驶检测的数据集仍较少。
技术实现要素:
7.为了解决上述技术问题,本发明提供一种基于深度学习的驾驶员疲劳驾驶实时检测方法及系统。
8.本发明技术解决方案为:一种基于深度学习的驾驶员疲劳驾驶实时检测方法,包括:
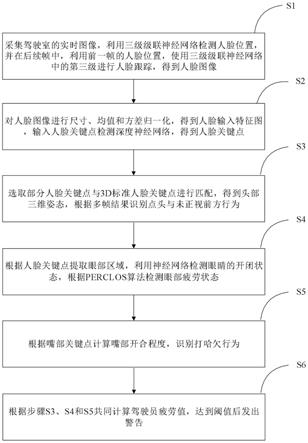
9.步骤s1:采集驾驶室的实时图像,利用三级级联神经网络检测人脸位置,并在后续帧中,利用前一帧的人脸位置,使用所述三级级联神经网络中的第三级进行人脸跟踪,得到人脸图像;
10.步骤s2:对所述人脸图像进行尺寸、均值和方差归一化,得到人脸输入特征图,输入人脸关键点检测深度神经网络,得到人脸关键点;
11.步骤s3:选取部分所述人脸关键点与3d标准人脸关键点进行匹配,得到头部三维姿态,根据多帧结果识别点头与未正视前方行为;
12.步骤s4:根据所述人脸关键点提取眼部区域,利用神经网络检测眼睛的开闭状态,根据perclos算法检测眼部疲劳状态;
13.步骤s5:根据嘴部关键点计算嘴部开合程度,识别打哈欠行为;
14.步骤s6:根据步骤s3、s4和s5共同计算驾驶员疲劳值,达到阈值后发出警告。
15.本发明与现有技术相比,具有以下优点:
16.本发明使用人脸关键点检测,能够识别出丰富的人脸特征信息,在此基础上分别检测头部、眼部和嘴部的不同行为特征,对多种疲劳行为进行检测,提高了方法的可靠性与实用性。同时,本发明在人脸检测和关键点检测两个运算量较大的步骤上进行优化,人脸检测中,利用前一帧图像的人脸位置信息,直接使用级联神经网络的最后一级进行人脸跟踪,避免了人脸位置的重复提取;关键点检测使用轻量级模块构建深度神经网络,使用小尺寸人脸降低计算量,极大提升了模型的计算速度。通过上述的优化,能够有效防止行为特征的丢失,提高疲劳驾驶行为检测的准确度。
附图说明
17.图1为本发明实施例中一种基于深度学习的驾驶员疲劳驾驶实时检测方法的流程图;
18.图2为本发明实施例中基于深度可分离卷积的轻量级卷积模块的结构示意图;
19.图3为本发明实施例中人脸关键点检测深度神经网络的得到人脸关键点的示意图;
20.图4为本发明实施例中一种基于深度学习的驾驶员疲劳驾驶实时检测方法中步骤s3:选取部分人脸关键点与3d标准人脸关键点进行匹配,得到头部三维姿态,根据多帧结果识别点头与未正视前方行为的流程图;
21.图5为本发明实施例中一种基于深度学习的驾驶员疲劳驾驶实时检测方法中步骤s4:根据人脸关键点提取眼部区域,利用神经网络检测眼睛的开闭状态,根据perclos算法检测眼部疲劳状态的流程图;
22.图6为本发明实施例中一种基于深度学习的驾驶员疲劳驾驶实时检测系统的结构框图。
具体实施方式
23.本发明提供了一种基于深度学习的驾驶员疲劳驾驶实时检测方法,通过人脸关键点检测,能够识别出丰富的人脸特征信息,在此基础上分别检测头部、眼部和嘴部的不同行为特征,对多种疲劳行为进行检测,提高了可靠性与实用性。
24.为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
25.实施例一
26.如图1所示,本发明实施例提供的一种基于深度学习的驾驶员疲劳驾驶实时检测方法,包括下述步骤:
27.步骤s1:采集驾驶室的实时图像,利用三级级联神经网络检测人脸位置,并在后续帧中,利用前一帧的人脸位置,使用三级级联神经网络中的第三级进行人脸跟踪,得到人脸
图像;
28.步骤s2:对人脸图像进行尺寸、均值和方差归一化,得到人脸输入特征图,输入人脸关键点检测深度神经网络,得到人脸关键点;
29.步骤s3:选取部分人脸关键点与3d标准人脸关键点进行匹配,得到头部三维姿态,根据多帧结果识别点头与未正视前方行为;
30.步骤s4:根据人脸关键点提取眼部区域,利用神经网络检测眼睛的开闭状态,根据perclos算法检测眼部疲劳状态;
31.步骤s5:根据嘴部关键点计算嘴部开合程度,识别打哈欠行为;
32.步骤s6:根据步骤s3、s4和s5共同计算驾驶员疲劳值,达到阈值后发出警告。
33.在一个实施例中,上述步骤s1:采集驾驶室的实时图像,利用三级级联神经网络检测人脸位置,并在后续帧中,利用前一帧的人脸位置,使用三级级联神经网络中的第三级进行人脸跟踪,得到人脸图像,具体包括:
34.采集驾驶室的实时图像,要检测人脸在图像中的位置,采用三级级联神经网络(mtcnn)进行人脸检测,并使用其第三级神经网络进行人脸跟踪。其中,三级级联神经网络包括:
35.第一级网络p
‑
net在多个尺寸的图像上生成人脸候选框。使用p
‑
net对可能存在人脸的区域进行筛选与回归,并利用非极大值抑制剔除重叠人脸候选框;
36.第二级网络r
‑
net对上述人脸候选框进一步筛选与回归,排除非人脸候选框,同样使用非极大值抑制剔除重叠人脸候选框;
37.第三级网络o
‑
net对r
‑
net输出的人脸候选框进行更加精细地筛选,最终回归输出人脸位置与图像。
38.由于三级级联神经网络的运算集中在第一级网络p
‑
net的多尺寸图像金字塔的候选框生成过程,在已经识别出前一帧人脸位置的情况下,可直接使用前一帧的人脸候选框,并利用第三级网络o
‑
net对当前帧的人脸候选框进行回归,实现人脸的快速跟踪。
39.在得到人脸图像后,需要对其中的关键点进行检测。由于后续疲劳驾驶状态的识别依赖于关键点,因而需要保证该步骤具有较高的精度,保证人脸各部分特征不容易丢失;同时为了减少模型的计算量,本发明采用了人脸关键点检测深度神经网络。
40.在一个实施例中,上述步骤s2中人脸关键点检测深度神经网络,具体包括:
41.基于深度可分离卷积的轻量级卷积模块以及损失函数如公式(1)所示:
[0042][0043]
其中,b为样本数,为第k个头部姿态角,为第n个人脸关键点的预测值与真实值之间的差值。
[0044]
如图2所示的基于深度可分离卷积的轻量级卷积模块的结构示意图。本发明实施例中的人脸关键点检测深度神经网络由多层轻量级卷积模块构成,逐层提取图像的深层特征。单个轻量级卷积模块可分为三个步骤:
[0045]
(1)使用轻量级卷积进行特征提取。首先使用1
×
1卷积核对输入人脸特征图进行通道扩展,将通道扩展后的特征图进行各通道分离,并使用单通道3
×
3卷积核逐通道提取空间尺度特征,即通道分离卷积,再使用1
×
1卷积核提取通道尺度特征。该方法将普通卷积
操作分离为空间尺度卷积和通道尺度卷积,使用极少的参数量完成了特征提取,同时通道扩展操作弥补了通道分离卷积的特征提取能力;
[0046]
(2)特征通道权重分配。使用轻量级卷积提取特征后,将特征进行空间尺度的全局平均池化,并使用两层1
×
1卷积对平均后的特征压缩再展开,以获取各通道的权重系数,将权重系数与池化前的特征对应通道相乘,输出权重分配后的特征图。由于可分离卷积无法考虑各通道之间的关系,因而使用权重分配的方法,使模型能够学习不同通道的重要程度;
[0047]
(3)残差连接结构。考虑到深度网络的复杂性,模块使用了残差连接结构,将输入特征图与处理后的特征图求和作为输出,保证在多层模块堆叠后,整体网络训练时便于梯度传播。该方法要求输入与输出特征图维度相等,本算法在维度不相等时,使用1
×
1卷积层或池化层改变输入特征图的维度,使其与输出维度相等。
[0048]
本发明实施例中的人脸关键点检测深度神经网络输入的人脸图像尺寸为112
×
112像素,输出68个关键点的回归坐标。根据后续步骤的需要,模型使用视频数据集进行训练,使其对闭眼、张嘴等动作的局部关键点检测鲁棒性更强。
[0049]
同时,由于驾驶场景经常出现大角度头部偏转,本发明实施例通过损失函数引入了的头部姿态角的权重,保证网络训练时,在大角度姿态下的人脸关键点的检测准确率。
[0050]
图3展示本发明提出的人脸关键点检测深度神经网络的检测结果,可以看出采用的多层轻量级卷积模块并未减小其识别的准确度,对人脸姿态、人脸表情以及光照等因素的影响具有较强的鲁棒性。
[0051]
如图4所示,在一个实施例中,上述步骤s3:选取部分人脸关键点与3d标准人脸关键点进行匹配,得到头部三维姿态,根据多帧结果识别点头与未正视前方行为,具体包括:
[0052]
步骤s31:根据公式(2),将预先设定的3d标准人脸关键点投影到图像平面上;
[0053][0054]
其中,s
2d
是3d标准人脸关键点在图像平面上的2d坐标(x,y),s是3d标准人脸关键点3d坐标(x,y,z),f是缩放因子,p是单位投影矩阵,是3
×
3旋转矩阵,t
3d
是平移向量;
[0055]
将公式(2)展开,得到公式(3):
[0056][0057]
根据步骤s2中得到的实际2d关键点s
2dt
,通过公式(4)最小化s
2d
和s
2dt
之间的距离来估计公式(3)的参数f、旋转矩阵和平移向量t
3d
:
[0058][0059]
步骤s32:将旋转矩阵转换为三个欧拉姿态角,设定俯仰角阈值检测点头,姿态角偏离中心区域视为视线偏移,通过计算点头次数与视线偏移时间,识别点头与未正视前方行为。
[0060]
当点头次数与视线偏移时间超过预设的阈值时,判断为疲劳驾驶行为。
[0061]
如图5所示,在一个实施例中,上述s4:根据人脸关键点提取眼部区域,利用神经网络检测眼睛的开闭状态,根据perclos算法检测眼部疲劳状态,具体包括:
[0062]
步骤s41:构建一个由卷积层与池化层构成的神经网络,根据人脸关键点提取眼部区域,输入神经网络,识别眼睛的开闭状态;
[0063]
首先利用上述步骤得到的人脸关键点,截取眼部区域,构建一个只有卷积层与池化层构成的小型的识别眼睛状态神经网络,用于识别眼睛的开闭状态。
[0064]
步骤s42:根据perclos方法如公式(4)所示,计算闭眼时长;当perclos超过阈值,判断为眼睛疲劳;
[0065][0066]
在一个实施例中,上述步骤s5:根据嘴部关键点计算嘴部开合程度,识别打哈欠行为,具体包括:
[0067]
选取多个上嘴唇关键点以及与之对应的下嘴唇关键点,计算二者之间的平均距离作为纵向距离,将嘴部左右边缘关键点之间的距离作为横向距离,计算嘴部纵横比,设定纵横比阈值,若连续多帧的嘴部纵横比超过阈值时,判断为打哈欠行为。
[0068]
在一个实施例中,上述步骤s6:根据步骤s3、s4和s5共同计算驾驶员疲劳值,达到阈值后发出警告,具体包括:
[0069]
根据点头与未正视前方行为、眼部疲劳状态以及打哈欠行为,根据实际情况,为其设置不同的权值,加权求和后得到最终的疲劳值;当在预设时间段内,疲劳值超出阈值将发出警告。
[0070]
本发明采用人脸关键点检测,能够识别出丰富的人脸特征信息,在此基础上分别检测头部、眼部和嘴部的不同行为特征,对多种疲劳行为进行检测,提高了方法的可靠性与实用性。同时,本发明在人脸检测和关键点检测两个运算量较大的步骤上进行优化,人脸检测中,利用前一帧图像的人脸位置信息,直接使用级联神经网络的最后一级进行人脸跟踪,避免了人脸位置的重复提取;人脸关键点检测使用轻量级模块构建深度神经网络,使用小尺寸人脸降低计算量,极大提升了模型的计算速度。通过上述的优化,能够有效防止行为特征的丢失,提高疲劳驾驶行为检测的准确度。
[0071]
实施例二
[0072]
如图6所示,本发明实施例提供了一种基于深度学习的驾驶员疲劳驾驶实时检测系统,包括下述模块:
[0073]
获取人脸图像模块61,用于采集驾驶室的实时图像,利用三级级联神经网络检测人脸位置,并在后续帧中,利用前一帧的人脸位置,使用三级级联神经网络中的第三级进行人脸跟踪,得到人脸图像;
[0074]
获取人脸关键点模块62,用于对人脸图像进行尺寸、均值和方差归一化,得到人脸输入特征图,输入人脸关键点检测深度神经网络,得到人脸关键点;
[0075]
识别点头与未正视前方模块63,用于选取部分人脸关键点与3d标准人脸关键点进行匹配,得到头部三维姿态,根据多帧结果识别点头与未正视前方行为;
[0076]
检测眼部疲劳状态模块64,用于根据人脸关键点提取眼部区域,利用神经网络检测眼睛的开闭状态,根据perclos算法检测眼部疲劳状态;
[0077]
识别打哈欠模块65,用于根据嘴部关键点计算嘴部开合程度,识别打哈欠行为;
[0078]
计算疲劳值模块66,用于根据识别点头与未正视前方模块、检测眼部疲劳状态模块和识别打哈欠模块共同计算驾驶员疲劳值,达到阈值后发出警告。
[0079]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1