燃料乙醇发酵过程工业知识图谱构建方法与流程
1.本发明属于工业生物发酵过程智能制造领域,涉及在工业生物发酵过程中,一种燃料乙醇发酵过程工业知识图谱构建方法,以便对关键变量的控制并提高燃料乙醇生产的质量和效率。
背景技术:
2.随着全球工业化的快速发展和社会经济的迅猛增长,传统能源煤矿、石油等化石燃料逐渐短缺,相伴而生的环境污染问题也不可忽视。燃料乙醇作为绿色、可再生的生物燃料,正在取代一次燃料的地位。燃料乙醇是体积分数在99.5%以上的无水乙醇,主要通过以生物质为原料经生物发酵作用等途径获得,它不添加变性剂,可作为燃料使用,是一种可再生资源,也是一种清洁的高辛烷值燃料,其燃烧性能和传统燃料相似。
3.燃料乙醇的美好前景决定了其在工业燃料生产领域的重要地位,其生产质量和效率也因此成为各方关注的焦点。燃料乙醇发酵制法的生产过程复杂,它涉及到拌料液化、酒母和发酵过程中大量需监测的变量以及多种物理和化学反应,其机理复杂,各变量的反应及数据采集工作不同程度地有所滞后,是一种具有多变量、纯滞后、非线性和强耦合的复杂被控对象。要保证燃料乙醇的高质高效生产,出罐乙醇体积比是一个关键指标,如果能够找到影响该关键指标的重要变量,通过连锁反应,即可在一定程度上从根源对整个燃料乙醇生产过程进行监测和控制。此策略的思路是根据燃料乙醇生产过程中的过程变量建立出罐乙醇体积比的软测量模型,先由模型筛选重要变量,再按照不同生产阶段的时间顺序,在可能对这些重要变量产生决定性影响的变量中继续筛选,直到在处于生产过程较早阶段且相对容易控制的液化环节中找到最可能影响后续过程的重要变量,最终将重要变量及其之间的影响关系以工业知识图谱的形式展现。燃料乙醇生产工厂的操作人员可以由知识图谱查看关键变量,对变量监控和机理分析有一定帮助。
4.xgboost(extreme gradient boosting)树形模型是数据驱动的开源框架,在shap(shapley additive explanations)方法的特征选择指导下可以有效构建软测量模型并得到对出罐乙醇体积比影响最大的变量。以这些变量为根基,用基于评分的因果关系发现算法fges(fast greedy equivalence search)追根溯源,在燃料乙醇生产的各个阶段中找到其他决定性变量。根据上述信息,可以构建燃料乙醇发酵过程关键指标的工业知识图谱。
技术实现要素:
5.本发明的目的是针对燃料乙醇发酵过程构建一个包含各阶段重要变量的工业知识图谱,为工厂操作人员提供关键变量及其相互影响关系的参考,提高燃料乙醇生产的质量和效率,同时也对生产机理有一定启发和验证作用。
6.基于上述目的,本发明提供一种燃料乙醇发酵过程工业知识图谱构建方法,包含以下三个阶段:获取燃料乙醇生产过程历史数据,构建并优化预测模型;提取出罐乙醇体积比和各生产阶段中重要变量的因果关系及其对应权重值;绘制能准确表示此关系的工业知
识图谱,用于对关键变量的控制并提高燃料乙醇生产的质量和效率。
7.针对构建并优化预测模型阶段,本发明建立一个燃料乙醇生产过程中出罐乙醇体积比的软测量模型,具体步骤如下:
8.(1)获取燃料乙醇生产过程中液化过程、酒母过程和发酵过程的生产历史数据;
9.(2)构建基于xgboost框架的预测模型并训练;xgboost模型的目标函数如下:
[0010][0011]
其中,l为损失函数,t为迭代轮数,ω(f
t
)为正则项,constant为常数项,f
t
(x
i
)表示一个新的子模型,即回归树。经过泰勒展开近似并省去每次迭代过程中的常数损失函数后,目标函数可化简为:
[0012][0013]
其中分别代表上一轮迭代中损失函数的一阶偏导数和二阶偏导数。
[0014]
(3)使用网格搜索方法,调整步骤(2)中预测模型的参数,确定最佳参数并重新训练模型;
[0015]
(4)利用shap方法分析步骤(3)所得模型各特征的重要性,以此为标准,得到筛选后的特征;单个特征的shap重要性计算公式为:
[0016][0017]
其中s为模型中使用的特征的子集,j为该特征的编号,x1,
…
,x
p
为特征的向量,p为特征的数量,为s的权重,val(s)为s的预测值;
[0018]
(5)根据步骤(4)的特征筛选结果,重新构建、训练模型并再次确定最优参数。查看各特征的重要性。
[0019]
本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述生产历史数据,针对液化过程,包含ph、干物、粘度、dp4+、dp3、dp2、葡萄糖、果糖、琥珀酸、乳酸、甘油、乙酸、乙醇、色谱还原糖、色谱总糖、de、gi和si等变量数据;针对酒母过程,包含ph、干物、酵母数、出芽率、死亡率、dp4+、dp3、dp2、葡萄糖、果糖、琥珀酸、乳酸、甘油、乙酸、乙醇、色谱还原糖、色谱总糖、乙醇/甘油和乙醇体积比等变量数据;针对发酵过程,包含发酵8小时、24小时和40小时共三组变量,每组变量包含dp4+、dp3、dp2、葡萄糖、果糖、琥珀酸、乳酸、甘油、乙酸、乙醇、色谱还原糖、色谱总糖、乙醇/甘油和乙醇体积比等变量数据;另有出罐乙醇体积比数据。
[0020]
进一步地,本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述构建基于xgboost框架的预测模型并训练,将生产历史数据中除出罐乙醇体积比外的变量作为自变量,出罐乙醇体积比作为因变量。参数参考常用值和经验值进行选择,暂不对自变量做筛选。
[0021]
更进一步地,本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述调整参数使用网格搜索方法,给模型的各个参数在一定范围内设置可能的预选值,在此范围内将各参数组合成参数组,分别训练,多次模拟建模,从而在其中选定最优者。
[0022]
更进一步地,本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述利用shap方法筛选特征,分析特征对预测结果产生的影响,通过计算在预测中每个特征的贡献来确定该特征的重要程度。按特征重要性顺序,每次保留一定数量的特征,舍弃其余特征,多次建模,选定最优者后完成特征筛选。
[0023]
更进一步地,本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述重新构建、训练模型并再次确定最优参数,将利用shap方法筛选后的特征作为模型自变量,再次使用网格搜索方法调整参数。建模完成后用shap方法查看特征重要程度,删除其中属于发酵过程的组变量(8h、24h和40h)中的同名重复特征。记录其余特征和对应的重要性数值。
[0024]
针对提取出罐乙醇体积比和各生产阶段中重要变量的因果关系及其对应权重值阶段,本发明考虑燃料乙醇生产过程的发生顺序,提出提取变量因果关系及其对应权重值的方法,具体步骤如下:
[0025]
(1)提取液化过程、酒母过程和发酵过程中的变量和出罐乙醇体积比之间的影响作用;
[0026]
(2)分别提取针对酒母过程和发酵过程、液化过程和发酵过程、液化过程和酒母过程中的变量之间的因果信息和对应权重值。
[0027]
进一步地,本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述提各生产阶段的变量与出罐乙醇体积比之间的影响作用,使用利用shap方法筛选出的特征作为影响出罐乙醇体积比的重要指标,由此确定因果信息,权重值即基于shap方法记录好的重要性数值。
[0028]
更进一步地,本发明所述燃料乙醇发酵过程工业知识图谱构建方法中,所述分别提取不同生产阶段间变量的因果关系和对应权重值,使用基于评分的因果关系发现算法fges和sem bic评分准则分析因果关系,并考虑约束条件:变量之间的因果关系必须按时间顺序定向,同一生产阶段的变量不能互为因果。具体步骤如下:
[0029]
①
针对酒母过程和发酵过程,分析前者中的全部变量和利用shap方法筛选出的特征中属于后者阶段的变量,得到酒母过程中的重要指标及其对应的因果信息和多次迭代后得到的权重值;
[0030]
②
针对液化过程和发酵过程,分析前者中的全部变量和利用shap方法筛选出的特征中属于后者的阶段变量,得到液化过程中影响发酵过程的重要指标及其对应的因果信息和多次迭代后得到的权重值;
[0031]
③
针对液化过程和酒母过程,分析前者中的全部变量和利用shap方法筛选出的特征中属于后者的变量及步骤
①
得到的酒母过程的重要指标,得到液化过程中影响酒母过程的重要指标及其对应的因果信息和多次迭代后得到的权重值。
[0032]
针对绘制能准确表示因果关系的工业知识图谱阶段,本发明构建一个工业知识图谱。使用networkx开源软件包,将前述步骤所得的因果信息和对应权重值以工业知识图谱的形式展现,具体步骤如下:
[0033]
(1)将因果信息所涉及的变量作为工业知识图谱的节点,按出罐乙醇体积比、发酵过程变量、酒母过程变量和液化过程变量的顺序由中心向外排列,形成多层圆环形结构,同一生产阶段的变量节点位于同一层内;
[0034]
(2)根据变量间的因果关系和对应的权重值,用有向线段连接各个节点,并将对应
的权重值标注在有向线段上。若权重值为利用shap方法得到的重要性数值,则需在有向线段上额外注明;
[0035]
(3)调整节点大小、位置、颜色和形状等属性,使图谱结构的节点名称显示完整、连线清晰、层次分明。
附图说明
[0036]
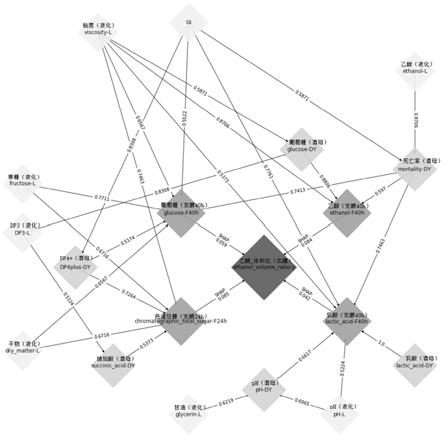
图1是一个燃料乙醇发酵过程中重要指标工业知识图谱(l:液化阶段;dy:酒母阶段;f:发酵阶段)。
具体实施方式
[0037]
下面进一步说明本发明所述技术方案。
[0038]
针对构建并优化预测模型阶段,步骤(1)获取燃料乙醇生产过程中液化过程、酒母过程和发酵过程的生产历史数据。针对液化过程,包含ph、干物、粘度、dp4+、dp3、dp2、葡萄糖、果糖、琥珀酸、乳酸、甘油、乙酸、乙醇、色谱还原糖、色谱总糖、de、gi和si等变量数据;针对酒母过程,包含ph、干物、酵母数、出芽率、死亡率、dp4+、dp3、dp2、葡萄糖、果糖、琥珀酸、乳酸、甘油、乙酸、乙醇、色谱还原糖、色谱总糖、乙醇/甘油和乙醇体积比等变量数据;针对发酵过程,包含发酵8小时、24小时和40小时共三组变量,每组变量包含dp4+、dp3、dp2、葡萄糖、果糖、琥珀酸、乳酸、甘油、乙酸、乙醇、色谱还原糖、色谱总糖、乙醇/甘油和乙醇体积比等变量数据;另有出罐乙醇体积比作为因变量,其余全部特征作为自变量。自变量共79个,因变量1个,数据样本647个。
[0039]
步骤(2)构建基于xgboost框架的预测模型并训练。参数参考常用值和经验值进行选择。部分重要参数设置如下:booster=’gbtree’、colsample_bytree=0.7、subsample=0.7、eval_metric=’rmse’、gamma=0.1、importance_type=’gain’、learning_rate=0.1、max_depth=5、min_child_weight=1、objective=’reg:squarederror’。xgboost模型的目标函数如下:
[0040][0041]
其中,l为损失函数,t为迭代轮数,ω(ft)为正则项,constant为常数项,f
t
(x
i
)表示一个新的子模型,即回归树。经过泰勒展开近似并省去每次迭代过程中的常数损失函数后,目标函数可化简为:
[0042][0043]
其中分别代表上一轮迭代中损失函数的一阶偏导数和二阶偏导数。
[0044]
步骤(3)用网格搜索方法调整模型参数。给每个待调整参数在一定范围内设置预选值,先粗略调整再精细调整。调整后的重要参数如下:colsample_bytree=0.6、subsample=0.7、gamma=0.1、learning_rate=0.01、max_depth=4、min_child_weight=7。
[0045]
步骤(4)利用shap方法分析步骤(3)所得模型各特征的重要性,以此为标准,得到
筛选后的特征共8个:色谱总糖(发酵24h)、乙醇(发酵40h)、乙醇(发酵24h)、色谱总糖(发酵40h)、葡萄糖(发酵40h)、乳酸(发酵40h)、乙醇_体积比(发酵40h)、乙醇(发酵8h)。
[0046]
步骤(5)根据步骤(4)的特征筛选结果,重新构建、训练模型并再次确定最优参数。调整后的重要参数如下:colsample_bytree=0.5、subsample=0.7、gamma=0.14、learning_rate=0.01、max_depth=3、min_child_weight=3。用shap方法查看各个特征的重要性。单个特征的shap重要性计算公式为:
[0047][0048]
其中s为模型中使用的特征的子集,j为该特征的编号,x1,
…
,x
p
为特征的向量,p为特征的数量,为s的权重,val(s)为s的预测值。删除发酵阶段同名特征后,剩余特征和对应的shap重要性为:色谱总糖(发酵24h):0.084641、乙醇(发酵40h):0.083796、葡萄糖(发酵40h):0.059419、乳酸(发酵40h):0.042199。
[0049]
针对提取出罐乙醇体积比和各生产阶段中重要变量的因果关系及其对应权重值阶段,步骤(1)得到直接影响出罐乙醇体积比的重要特征和权重值:色谱总糖(发酵24h):0.084641、乙醇(发酵40h):0.083796、葡萄糖(发酵40h):0.059419、乳酸(发酵40h):0.042199。
[0050]
步骤(2)分别提取针对酒母过程和发酵过程、液化过程和发酵过程、液化过程和酒母过程中的变量之间的因果信息和对应权重值。以针对酒母过程和发酵过程为例,在算法执行前手动排除由发酵变量指向酒母变量的因果关系。fges的数学模型为:
[0051]
maxf(graph,d)s.t.gragh∈ω,graghi=c
[0052]
其中f为sem bic评分函数,graph为将要输出的有向无环图,d为输入数据,ω为结构空间,c为约束条件,这里指的是搜索到的结构应该满足结构是无环的。sem bic评分函数的公式为:
[0053]
bic=ck ln(n)
‑
2ln(l)
[0054]
其中c是惩罚折扣,k是模型参数个数,n是样本容量,l是模型的极大似然函数值。经过fges算法200轮迭代后,排除误判的同一阶段变量之间的因果信息,得到如下因果信息和对应权重值:死亡率(酒母)
→
乙醇(发酵40h):0.5970、死亡率(酒母)
→
乳酸(发酵40h):0.7463、死亡率(酒母)
→
葡萄糖(发酵40h):0.7413、dp4+(酒母)
→
色谱总糖(发酵24h):0.7264、dp4+(酒母)
→
葡萄糖(发酵40h):0.5174、琥珀酸(酒母)
→
色谱总糖(发酵24h):0.5373、葡萄糖(酒母)
→
乙醇(发酵40h):0.8806、ph(酒母)
→
乳酸(发酵40h):0.6617、乳酸(酒母)
→
乳酸(发酵40h):1.0000。其余两部分的因果信息和对应权重值用相同的方法提取。
[0055]
针对绘制能准确表示因果关系的工业知识图谱阶段,步骤(1)生成以因果信息涉及的每个变量名称命名的结点,以出罐乙醇体积比、发酵过程变量、酒母过程变量和液化过程变量的顺序由中心向外排列。
[0056]
步骤(2)用有向线段连接各个节点表示因果关系。色谱总糖(发酵24h)、乙醇(发酵40h)、葡萄糖(发酵40h)和乳酸(发酵40h)4个变量与出罐乙醇体积比之间的权重值额外注明,表示该权重值是基于shap方法的重要性数值。
[0057]
步骤(3)调整节点大小、位置、颜色和形状等属性,将出罐乙醇体积比、发酵过程变
量、酒母过程变量和液化过程变量对应节点的颜色参数依次设为
‘
green’、
‘
limegreen’、
‘
lightgreen’和
‘
linen’。所有节点形状参数设为
‘
d’。
[0058]
本发明采用xgboost框架和shap方法相结合的方式构建出罐乙醇体积比的预测模型并提取重要特征,随后采用fges算法提取重要特征与其他上级变量之间的因果关系,使用networkx开源软件包构建燃料乙醇生产过程重要指标的工业知识图谱。
相关技术
网友询问留言
已有1条留言
-
 0180018... 来自[中国] 2022年11月08日 20:49wow
0180018... 来自[中国] 2022年11月08日 20:49wow
1