一种处理特征和标记同时缺失的多标记分类方法
1.本发明涉及机器学习技术领域,更具体地说,涉及一种处理特征和标记同时缺失的多标 记分类方法。
背景技术:
2.传统的机器学习任务中,一个对象对应一个语义,一个典型的例子是判断西瓜是否是“好 瓜”,对于“西瓜”来说,它只有“是好瓜”和“不是好瓜”两种选择。然而,在实际应用中, 并不仅仅是“是好瓜”与“不是好瓜”之分。例如,电影“狮子王”同时属于“歌舞”、“动 画”和“剧情”等三个电影类型;又如一个街舞作品可能同时包含“嘻哈舞”、“锁舞”和“霹 雳舞”等三个舞种;再如一篇介绍机器学习的文章,可能被标注“线性模型”、“支持向量机
”ꢀ
等词条,即一个对象不再具有单一的语义,由此引出多标记学习的研究。
3.作为当前机器学习领域的一个研究热点,多标记学习受到广泛关注,并已在现实生活中 得到了广泛应用,例如文档分类、图像标注、视频标注等。多标记学习的主要任务就是根据 训练数据,学习一个高效的分类模型,为未见示例预测一个或多个可能的类别标记。近年来, 针对多标记学习问题,研究人员提出了多种学习方法,现有方法大致可以分为两类:“问题转 换”方法和“算法适应”方法。“问题转换”方法的主要思想是改造多标记数据,将多标记学 习问题转换为已有的更成熟的学习问题,然后利用已有的算法去解决问题,如br(转换为二 类分类问题)、clr(转换为标记排序问题)、random k
‑
label sets(转换为多类分类问题)等。
ꢀ“
算法适应”方法则是改造现有算法,使其能够直接处理多标记数据,如基于k近邻算法改 造的ml
‑
knn,基于决策树算法改造的ml
‑
dt,基于支持向量机改造的rank
‑
svm等。随着 对多标记学习的深入研究,越来越多的问题被发掘出来,例如,标记缺失问题,多视角多标 记学习,偏多标记学习等。其中,标记缺失是一个热门的研究方向。
4.在之前的多标记学习中,研究者们通常假设所参与训练的标记信息是完整的,并且标记 之间不是相互独立的,而是相互依赖的。然而,在实际应用中,标记大多是不完整的,这可 能有以下三个方面的原因:人工标记费时费力且成本高、人工标注者知识限制、收集数据的 机器故障等。为解决这类问题,研究者们提出许多算法,现有算法大致可分为两类:一类是
ꢀ“
两步走”策略,即先恢复含有缺失值的标记矩阵,然后利用恢复后的矩阵进行训练。例如, mcwl将多个视角特征信息整合为一个矩阵,并通过矩阵补全的方式补全标记矩阵中的缺失 值,然后利用图结构思想以及核目标依赖技巧融合多个视角的相似图信息,以此来辅助分类 器的学习。这种方法依赖恢复之后的标记矩阵,存在误差传播现象。另一类是将缺失标记矩 阵恢复与模型分类整合在同一框架中,二者同时训练。由于标记之间相互依赖,因此在构建 分类模型时,研究者通常会利用标记相关性辅助分类器的学习。例如,lrml利用拉普拉斯 流形正则技术以及低秩映射去恢复标记矩阵中的缺失值,隐式地利用了标记相关性,分析了 判别子空间中的高维数据。然而,由于标记存在缺失项,所以对于标记相关性的利用就变得 不那么准确,从而降低模型性能,影响多标记分类任务。
5.目前,在多标记学习中,大多数处理标记缺失问题算法的一个首要前提是特征信
息完整, 而标记信息不完整。然而,在实际应用中,这种假设可能并不成立。因为在收集数据过程中, 当数据受到损坏或者某些信息被忽略或者收集数据的机器故障时,会造成收集到的数据不完 整,即收集到的特征信息不完整,此时很难收集到完整的标记集,从而导致标记缺失,即特 征缺失引起标记缺失。例如,在医疗诊断领域,患者可视为一个对象,特征空间由其体格检 查结果组成,有些病人可能会选择性地做一些检查,从而忽略其他特征,但被忽略的特征恰 好又是判断某种疾病的关键特征,这时忽略了的特征就变成及时治疗疾病的关键因素。在分 布式物联网设备上检测恶意事件时,从保护物联网设备的安全产品(代理服务器等)中得到 的安全遥测数据可能非常不完整。客户可以手动更改设备上的隐私配置,从而限制与安全供 应商共享的遥测数据的覆盖范围。同时,人工分析人员只能识别具有相对完整和典型配置文 件的恶意事件,因为将恶意事件错误地标记为良性事件可能会增加误报率,并使学习到的事 件检测器无法捕捉潜在的恶意活动。在这种情况下,多标记学习的有效解决方案对于在医疗 诊断领域、物联网安全等现实应用中就变得至关重要。
6.众所周知,低秩矩阵分解技术在矩阵恢复方面扮演着至关重要的角色,因此吸引许多学 者利用该技术去恢复数据中的缺失值。例如,ledm利用低秩矩阵分解技术和hsic(独立性 准则:检验特征空间与标记空间之间的依赖性,值越大,依赖性越强)联合学习一个特征和 标记的嵌入空间,然后在学习嵌入空间以及标记相关性的同时去恢复标记矩阵中的缺失值。 但ledm并没有考虑到特征缺失对标记的影响。此外,实际上,在标记空间中,通常有一些 标记仅出现在很少的实例中,导致很难利用一个线性结构来描述标记之间的相关性,亦即破 坏了这种标记空间的低秩性,这些标记统称为尾标记。尾标记的存在导致利用低秩矩阵分解 技术恢复标记空间缺失值时变得不那么准确,而ledm显然没有考虑到尾标记的问题。相对 于ledm,多视角多标记学习方法imvwl考虑到了特征缺失对标记缺失的影响,该方法仅 对特征空间采用非负矩阵分解技术,因此无需考虑尾标记问题,并在异构的不完整视图中寻 找共享子空间,从而捕获交叉视图之间的关系,并在该子空间中建立一个鲁棒的弱标记分类 器,使其能够在统一的学习框架中学习标记相关性和鉴别信息。但该方法针对的是多视角多 标记学习问题,不能直接应用在单视角多标记学习问题中。尽管矩阵分解技术在恢复缺失值 方面扮演着重要的角色,但现有的处理特征和标记同时缺失的多标记学习方法,并没有直接 对特征空间以及标记空间同时使用矩阵分解技术去恢复缺失值,也并没有单独考虑尾标记破 坏标记空间低秩特性的问题。
7.处理数据中的缺失值,有助于我们更好的发现一些易忽略的数据。因此,提出有效的学 习方法,处理数据集中的缺失值,并构建有效的多标记分类模型,具有重要的研究意义。
8.经检索,中国专利申请号zl202010870298.7,申请日为2020年8月26日,发明名称为 一种存在部分缺失和未知类别标记的多标记分类方法,该申请案将部分缺失类别标记和未知 类别标记的问题融合在一个框架中,利用高斯距离函数,计算样本相似度矩阵,再将相似度 矩阵分解,得到完整类别标记矩阵的近似解,约束近似解的部分结果与已观测的标记结果一 致,同时构建从样本特征到完整标记的分类模型,建模已知标记和新发现未知标记之间的关 联性,约束相关性较强的具有相似的分类模型系数,并不断优化完整标记矩阵的结果,进而 学习得到准确的分类模型。但该申请案处理的是部分缺失和未知类别标记
的多标记学习问题, 并没有考虑到特征缺失的影响,同时该申请仅对样本相似度矩阵进行分解从而得到完整类别 标记矩阵的近似解。
技术实现要素:
9.1.发明要解决的技术问题
10.鉴于现有技术中,传统的多标记学习方法在处理标记缺失问题时,忽略了特征缺失引起 标记缺失的问题,从而造成数据不完整(特征缺失以及标记缺失),进一步影响决策函数的分 类性能。本发明提供了一种处理特征和标记同时缺失的多标记分类方法,本发明提出有效的 学习方法,在恢复数据集中缺失特征以及缺失标记的同时,构建有效的多标记分类模型,使 多标记分类更加准确。
11.2.技术方案
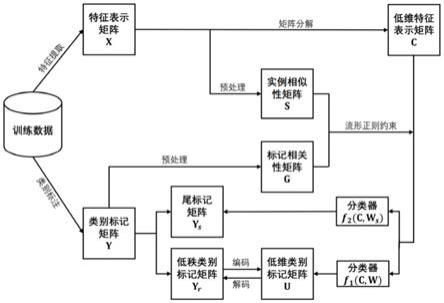
12.为达到上述目的,本发明提供的技术方案为:
13.本发明的一种处理特征和标记同时缺失的多标记分类方法,其步骤为:
14.s1、对训练数据进行特征提取,获得特征表示矩阵x;并对训练数据进行类别标记,获得 类别标记矩阵y,矩阵x和y中均存在缺失值;
15.s2、将特征表示矩阵x分解为低维特征表示矩阵c和低维特征表示空间与原始特征表示空 间相关联的系数矩阵d;同时将类别标记矩阵y分解为低秩类别标记矩阵y
r
与尾标记矩阵y
s
; 对y
r
进行分解,得到低维类别标记矩阵u;初始化尾标记矩阵y
s
;利用上述矩阵恢复训练数据 中的缺失值;
16.s3、利用矩阵补全技术初步恢复特征表示矩阵x,得到实例相似性矩阵s;利用标记相关 性重新构建缺失标记,初步恢复类别标记矩阵y,得到标记相关性矩阵g;并计算矩阵s和矩阵 g的拉普拉斯矩阵;
17.s4、分别构建低维特征表示矩阵c映射到低秩类别标记矩阵y
r
以及低维特征表示矩阵c映 射到尾标记矩阵y
s
的线性模型,作为分类器;
18.s5、利用流形正则技术约束相关特征以及相关类别标记的相似性;
19.s6、利用步骤s5中优化目标获得的结果更新特征表示矩阵x以及类别标记矩阵y,补全 缺失特征和缺失标记;
20.s7、给定一个测试实例m,利用一个低维映射矩阵p,将mp带入上述学习得到的最终分 类模型,从而输出测试实例的分类结果。
21.3.有益效果
22.与已有的相关技术相比,本发明提供的技术方案具有如下显著效果:
23.(1)鉴于现有技术中,很少同时处理特征缺失与标记缺失两个方面的问题,且现有的关 于不完整数据的算法要么不能直接应用到多标记学习中,要么不能起到分类作用。本发明将 缺失特征以及缺失标记共同恢复与分类融合在统一框架中,并利用实例相似性以及标记相关 性来辅助训练模型。
24.(2)鉴于现有技术中,利用矩阵分解技术恢复缺失值时,没有同时考虑到特征空间与标 记空间。本发明利用矩阵分解技术同时恢复特征空间与标记空间的缺失值,并在低维空间中 学习多标记模型,降低了模型的复杂度,缓解了多标记学习中出现不完整数据引发的性能下 降问题,同时考虑到了尾标记破坏矩阵分解中低秩假设的问题,本发明对尾标记
进行处理, 利用尾标记与低秩类别标记共同构建分类模型,从而提升分类性能,更好的进行多标记学习 任务。
附图说明
25.图1为本发明方法的框架图。
具体实施方式
26.为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。
27.实施例1
28.结合图1,本实施例的一种处理特征和标记同时缺失的多标记分类方法,包含模型构建 与训练,和标记预测两个阶段,具体步骤如下:
29.(1)模型构建与训练:
30.s1、对训练数据进行特征提取,获得特征表示矩阵x;并对训练数据进行类别标记,获得 类别标记矩阵y,矩阵x和y中均存在缺失值。具体为:
31.假定训练数据中含有缺失值的特征表示矩阵为一个实数矩阵其中,n表示实例 个数,d表示特征个数,表示实数域,用ω表示观察到的特征表示矩阵x中的元素的索引集合。 y∈{0,1}
n
×
q
是特征表示矩阵x对应的含有缺失值的类别标记矩阵,q表示类别标记个数,其中, y
ij
表示类别标记矩阵y中的第i行第j列的元素,y
ij
=1表示第i个实例被标注为第j个类别标记, y
ij
=0表示第i个实例没有被标注为第j个类别标记,或第i个实例的第j个类别标记没有被观测 到(即缺失),其中i=1,2,
…
,n,j=1,2,
…
,q。
32.s2、将特征表示矩阵x分解为低维特征表示矩阵c和低维特征表示空间与原始特征表示空 间相关联的系数矩阵d;同时将类别标记矩阵y分解为低秩类别标记矩阵y
r
与尾标记矩阵y
s
; 对y
r
进行分解,得到低维类别标记矩阵u;初始化尾标记矩阵y
s
;利用上述矩阵恢复训练数据 中的缺失值。具体为:
33.将训练数据的特征表示矩阵x进行分解,即x=cd,其中,为低维特征表示矩阵,表示低维特征表示空间与原始特征表示空间相关联的系数矩阵。将训练数据的类别 标记矩阵y分为一个低秩类别标记矩阵y
r
与一个尾标记矩阵y
s
,即y=y
r
+y
s
,对低秩类别标 记矩阵y
r
进行分解,即y
r
=uv,其中为低维类别标记矩阵,表示低维类别 标记空间与原始类别标记空间相关联的系数矩阵。由于尾标记仅出现在个别实例中,因此设 定为稀疏的,并将y
s
初始化为0,0表示大小为n
×
q的矩阵且其中元素取值均为0。 通过矩阵分解技术以及考虑到尾标记的存在,从而恢复训练数据中的缺失值,得到以下最小 化目标公式:
[0034][0035]
式(1)中,c、d、u、v、y
s
为待求解模型参数,λ1、λ2和λ4均为非负权重系数,取值域为 {10
‑5,10
‑4,
…
,102,103}。使用低维特征表示矩阵c和低维特征表示空间与原始特征表 示空间相关联的系数矩阵d的乘积,可以恢复特征表示矩阵x中的缺失值,使用低维类别标记 矩阵u与低维类别标记空间与原始类别标记空间相关联的系数矩阵v的乘积以及尾标记矩阵 y
s
,可以恢复类别标记矩阵y中的缺失值,然后分别使用f范数来最小化误差值,使用l1‑ꢀ
norm来表示y
s
的稀疏约束。
[0036]
s3、将训练数据的特征表示矩阵x利用矩阵补全技术初步恢复,得到一个实例相似性矩阵 s;将训练数据的类别标记矩阵y利用标记相关性重新构建缺失标记从而初步恢复,进一步得 到一个标记相关性矩阵g;并利用这两个矩阵以及步骤s2得到的低维类别矩阵计算拉普拉斯 矩阵。具体为:
[0037]
利用矩阵补全技术初步恢复特征表示矩阵x中的缺失值,本实施例采用natal(g.y.lyu, s.h.feng and y.d.li,“noisy label tolerance:a new perspective of partial multi
‑
label learning,
”ꢀ
information sciences,vol.543,pp.454
‑
466,2020.)中用到的特征补全方法,对特征表示矩阵 x进行特征补全,从而引入一个缺失特征表示矩阵来初步补全特征表示矩阵x中的 缺失值。设定为实例相似性矩阵,其中任意第i行第j列元素s
ij
,可以通过对恢复之后 的特征表示矩阵利用公式(2)计算heat
‑
kernel function(热核函数)得到,表明相似的两个实例 应该共享相似的特征。其中,x
i
表示第i个实例,x
j
表示第j个实例,n
k
(x
i
)表示实例x
i
的第k个 最近邻居,设置k=50,σ=1。
[0038][0039]
为实例相似性矩阵s的拉普拉斯矩阵,l0=diag(sum(s))
‑
s,其中,sum(s) 表示分别对s的每一行元素进行相加,返回的一个列向量,diag(sum(s))返回一个维度和 sum(s)的行数一样的方阵,并且对角线元素和sum(s)一一对应,其余元素值均为0。
[0040]
利用标记相关性重新构建缺失标记从而初步恢复类别标记矩阵y中的缺失值,本实施例采 用lsml(j.huang,f.qin,x.zheng,et al.“improving multi
‑
label classification with missinglabels by learning label
‑
specific features,”.information sciences,vol.492,pp.124
‑
146,2019.) 中利用标记相关性重新构建缺失标记来初步恢复类别标记矩阵y中的缺失值。设定为标记相关性矩阵,其中任意第i行第j列元素g
ij
,可以通过对恢复之后的低维类别标记矩阵 利用公式(3)计算余弦相似度得到,表明标记之间不是独立存在的,而是相互依赖的。其中, y
i
与y
j
分别表示第i个标记与第j个标记,<y
i
,y
j
>表示向量y
i
与向量y
j
的点积,返回的是向 量y
i
与向量y
j
中对应元素乘积之和,||y
i
||与||y
j
||分别表示向量y
i
与向量y
j
的模,分别返回 的是向量y
i
与向量y
j
的长度。
[0041][0042]
为标记相关性矩阵g的拉普拉斯矩阵,l1=diag(sum(g))
‑
g,其中,sum(g) 表示分别对g的每一行元素相加,返回的一个列向量,diag(sum(g))返回一个维度和sum(g) 的行数一样的方阵,并且对角线元素和sum(g)一一对应,其余元素值为0。
[0043]
s4、分别构建低维特征表示矩阵c映射到低秩类别标记矩阵y
r
以及低维特征表示矩阵c映 射到尾标记矩阵y
s
的线性模型,作为分类器。具体为:
[0044]
使用线性回归模型作为分类器,在低维空间中构建分类模型。基于低维特征表示矩阵c, 分别学习到低维类别标记矩阵u以及到尾标记矩阵y
s
的线性分类模型,即f1(c,w)=
cw和 f2(c,w
s
)=cw
s
,并且对权重系数矩阵以及做f范式正则约束,得到更 新的最小化目标公式:
[0045][0046]
式(4)中,w、w
s
、c、d、u、v、y
s
为待求解模型参数,λ1、λ2和λ4均为非负权重系数, 取值域为{10
‑5,10
‑4,
…
,102,103}。
[0047]
s5、利用流形正则技术约束相关特征以及相关类别标记的相似性。具体为:
[0048]
建模实例间的相似性,相似的两个实例,其对应的特征也会相似,反之则不相似;建模 标记间的相关性,相关性较强的两个标记,其对应的欧式距离则越近,反之则远。利用流形 正则技术分别对相似实例以及相关标记进行约束,得到最终优化目标:
[0049][0050]
式(5)中,待求解模型参数为w、w
s
、c、d、u、v、y
s
,λ1、λ2、λ3和λ4均为非负权重 系数,取值域为{10
‑5,10
‑4,
…
,102,103}。为实例相似性矩阵s的拉普拉斯矩 阵,为标记相关性矩阵g的拉普拉斯矩阵。
[0051]
s6、利用步骤s5中优化目标获得的结果更新特征表示矩阵x以及类别标记矩阵y,补全 缺失特征和缺失标记:
[0052]
根据低维特征表示矩阵c、低维特征表示空间与原始特征表示空间相关联的系数矩阵d以 及低维类别标记矩阵u、低维类别标记空间与原始类别标记空间相关联的系数矩阵v和尾标记 矩阵y
s
,同分类模型一起,更新训练数据特征表示矩阵x以及类别标记矩阵y中的结果,从而 补全缺失特征以及缺失标记。具体为:
[0053]
通过求解式(5),得到c、d、u、v、y
s
的最优值,特征表示矩阵x以及类别标记矩阵y中 的缺失值即可通过式(6)恢复。
[0054]
x=cd,y=uv+y
s
ꢀꢀꢀꢀꢀꢀ
(6)
[0055]
(2)标记预测:
[0056]
s7、标记预测。给定一个测试实例m,利用一个低维映射矩阵p,将mp带入上述学习得 到的最终分类模型,从而输出测试实例的分类结果。具体为:
[0057]
本实施例是在低维空间中构建分类模型,利用公式学习 得到一个低维映射矩阵p,其中,表示原始特征表示空间与低维特征表示空间之间的 映射关系。给定一个测试实例m的特征表示x
m
,根据训练阶段得到的w,w
s
,v,p,即可得到测 试实例m的预测值
[0058]
f
p
(x
m
,p,v,w,w
s
)=x
m
pwv+x
m
pw
s
ꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0059]
根据得到的测试实例m的预测值f
p
(x
m
,p,v,w,w
s
)以及设置的阈值τ,计算测试实例m的 最终输出标记向量y
m
∈{0,1}1×
q
,其中
·
为指示函数。根据式(8)的计算结果,当满足括
号中 条件时返回1,表示测试实例m属于第i类;否则返回0,表示测试实例m不属于第i类。
[0060]
y
m
(i)=[f
p
(x
m
,p,v,w,w
s
)>τ],1≤i≤q
ꢀꢀ
(8)
[0061]
本实施例将缺失特征以及缺失标记恢复与分类融合在同一框架中,利用矩阵分解技术, 同时对特征空间以及标记空间进行分解,在低维空间中构建分类器,降低了模型的复杂度, 同时,考虑了尾标记破坏低秩特性的问题,对尾标记做稀疏处理。此外,还利用实例相似性 以及标记相关性来提升模型性能。通过对特征以及标记共同缺失的处理,使其能够在恢复缺 失值的同时进行分类任务,从而使得在数据缺失的情况下,能够提升多标记学习分类模型的 性能。
[0062]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也 只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员 受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结 构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1