一种数据导入方法、装置、设备及介质与流程
1.本发明涉及大数据技术领域,尤其是涉及一种数据导入方法、装置、设备及介质。
背景技术:
2.数据导入是指将数据从一个数据仓库导入到另一个数据仓库的过程。hive和hbase是两种不同类型的数据仓库,其中,hvie主要用于离线计算(如数据聚合、数据分析等),而数据查询速度减慢,难以满足在线查询的需求;hbase支持对数据快速地在线查询。如此,将hive中存储的数据导入到hbase中后,用户能够通过hbase的应用程序接口api,实现对数据快速地在线查询。
3.业界提供了一种基于mapreduce框架(一种软件开发框架,简称mr)开发的hive
‑
hbase做映射表的数据导入方案中。具体地,根据规范创建合适的映射表,然后基于该映射表,将数据从hive导入到hbase中。
4.由于hive中存储的数据的文件格式为sequencefile格式,hbase中存储的数据的文件格式为hfile格式,即hive和hbase中存储的数据的文件格式不同,导致数据仅能够一条一条地从hive通过hbase的api导入到hbase中,然后再将新导入的数据的文件格式转换为hfile格式。当需要从hive向hbase中导入数据量较大的数据时,不仅数据导入的效率低,而且还会长时间占用hbase的api,进而降低hbase在线查询的响应速度。
技术实现要素:
5.本技术的目的在于提供一种数据导入方法、装置、设备及介质,能够提高数据导入的效率,并且不影响hbase的响应速度。
6.第一方面,本技术提供了一种数据导入方法,包括:获取配置信息,所述配置信息包括第一数据仓库的路径和第二数据仓库的路径;
7.根据所述第一数据仓库的路径,从所述第一数据仓库中获取第一数据;
8.将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式,得到第二数据;
9.根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中。
10.作为一种可能的实现方式,所述第一数据仓库为hive,所述第二数据仓库为hbase;所述配置信息还包括:所述第一数据仓库的列名映射、待导入数据的列名;所述方法还包括:
11.根据所述第一数据仓库的列名映射,为所述第一数据库仓库的每一列分配列名;
12.所述根据所述第一数据仓库的路径,从所述第一数据仓库中获取第一数据,包括:
13.根据所述第一数据仓库的路径,从所述第一数据仓库中的每一列的列名中查找与所述待导入数据的列名相对应的目标列名;
14.获取所述目标列名对应的第一数据。
15.作为一种可能的实现方式,所述配置信息还包括:时间字段;
16.所述获取所述目标列名对应的第一数据,包括:
17.根据时间字段,对所述目标列名中的数据进行筛选,从所述目标列名中获取所述时间字段对应的第一数据。
18.作为一种可能的实现方式,所述配置信息还包括:第二数据仓库中的表名和所述表名所对应的表的主键;
19.所述根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中,包括:
20.根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中所述表名所对应的表的主键中。
21.作为一种可能的实现方式,所述配置信息还包括:资源队列名;
22.所述将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式,包括:
23.根据所述资源队列名,请求计算资源;
24.利用所述计算资源,将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式。
25.第二方面,本技术提供了一种数据导入装置,包括:
26.获取单元,用于获取配置信息,所述配置信息包括第一数据仓库的路径和第二数据仓库的路径;
27.读取单元,用于根据所述第一数据仓库的路径,从所述第一数据仓库中获取第一数据;
28.转换单元,用于将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式,得到第二数据;
29.导入单元,用于根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中。
30.作为一种可能的实现方式,所述第一数据仓库为hive,所述第二数据仓库为hbase;所述配置信息还包括:所述第一数据仓库的列名映射、待导入数据的列名;所述装置还包括:映射单元;
31.映射单元,用于根据所述第一数据仓库的列名映射,为所述第一数据库仓库的每一列分配列名;
32.读取单元,具体用于根据所述第一数据仓库的路径,从所述第一数据仓库中的每一列的列名中查找与所述待导入数据的列名相对应的目标列名;获取所述目标列名对应的第一数据。
33.作为一种可能的实现方式,所述配置信息还包括:时间字段;
34.所述读取单元,具体用于根据时间字段,对所述目标列名中的数据进行筛选,从所述目标列名中获取所述时间字段对应的第一数据。
35.作为一种可能的实现方式,所述配置信息还包括:第二数据仓库中的表名和所述表名所对应的表的主键;
36.所述导入单元,具体用于根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中所述表名所对应的表的主键中。
37.作为一种可能的实现方式,所述配置信息还包括:资源队列名;
38.所述转换单元,具体用于根据所述资源队列名,请求计算资源;利用所述计算资源,将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式。
39.第三方面,本技术提供一种电子设备,所述电子设备包括处理器和存储器;
40.所述处理器用于执行所述存储器中存储的指令,以使得所述电子设备执行上述第一方面中任意一项所述的方法。
41.第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行上述第一方面中任意一项所述的方法。
42.相对于现有技术,本技术上述技术方案的优点在于:
43.本技术提供了一种数据导入方法,该方法包括获取配置信息,该配置信息包括第一数据仓库的路径和第二数据仓库的路径;先根据第一数据仓库的路径,从第一数据仓库中获取第一数据;将第一数据的文件格式转换为第二数据仓库存储的数据的文件格式,得到第二数据;该第二数据的文件格式与第二数据仓库中存储的数控的文件格式相同,进而根据第二数据仓库的路径,将第二数据直接导入到第二数据仓库中。上述将第一数据转换为第二数据的过程中支持批量处理,并且由于不是在hbase侧对数据的文件格式进行转换,并不影响hbase在线查询的响应速度。如此,该方法不仅能够提高数据导入的效率,并且不影响hbase的响应速度。
附图说明
44.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
45.图1为本技术实施例提供的一种数据导入方法的流程图;
46.图2为本技术实施例提供的一种数据导入方法的流程图;
47.图3为本技术实施例提供的一种数据导入装置的示意图;
48.图4为本技术实施例提供的一种电子设备的示意图。
具体实施方式
49.为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
50.下面先对本技术所涉及的技术术语进行介绍。
51.数据导入是指将数据从一个数据仓库导入到另一个数据仓库的过程。例如将hive中存储的数据导入到hbase中,从而通过hbase能够实现对数据快速地在线查询。
52.然而,将hive中存储的数据导入到hbase中时,由于hbase本身的限制以及hive和hbase中存储的数据的文件格式不同,导致数据仅能够一条一条地从hive通过hbase的api导入到hbase中,然后再将新导入的数据的文件格式转换为hfile格式。该方案无法适应数
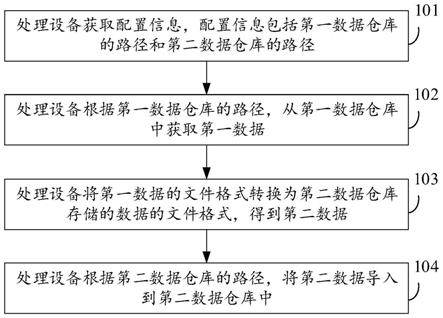
据量较大的数据的情况,并且数据导入过程中,会降低hbase在线查询的响应速度。
53.有鉴于此,本技术实施例提供了一种数据导入方法。该方法可以由处理设备执行,处理设备获取配置信息,配置信息包括第一数据仓库(例如hive)的路径和第二数据仓库(例如hbase)的路径;然后处理设备根据第一数据仓库的路径,从第一数据仓库中获取第一数据;接着处理设备将第一数据的文件格式(sequencefile格式)转换为第二数据仓库存储的数据的文件格式(hfile格式),得到第二数据;最后处理设备根据第二数据仓库的路径,将第二数据导入到第二数据仓库中。
54.一方面,该方法将第一数据的文件格式由sequencefile格式转换为hfile格式,得到第二数据,该第二数据的文件格式为hfile格式,由此可以直接将该第二数据导入到hbase中,无需通过hbase的api进行数据导入;进一步的,由于不通过hbase的api进行数据导入,故不会长时间占用该api,不会影响hbase在线查询的响应速度。
55.另一方面,由于将第一数据转换为第二数据的过程不再hbase侧,故可以实现批量对第一数据的文件格式进行转换,得到hfile格式的第二数据,然后直接将第二数据导入到hbase,提高数据导入的效率。
56.本技术实施例提供的数据导入方法可以应用于标签数据的数据导入的场景,例如将hive中存储的用户标签数据导入到hbase中,以便用户通过hbase快速地在线查询用户标签数据。
57.为了使得本技术的技术方案更加清楚、易于理解,下面结合说明书附图,对本技术实施例提供的数据导入方法进行介绍。
58.如图1所示,该图示出了一种本技术实施例提供的数据导入方案的流程图,该数据导入方法可以由处理设备执行,该方法包括:
59.s101:处理设备获取配置信息,配置信息包括第一数据仓库的路径和第二数据仓库的路径。
60.其中,第一数据仓库可以是hive,第一数据仓库的路径可以是指向hive的分布式文件系统(hadoop distributed file system,hdfs);第二数据仓库可以是hbase,第二数据仓库的路径可以是指向hbase的hdfs。
61.在一些示例中,处理设备可以向用户提供用户图形界面,用户可以在用户图形界面上输入配置信息。例如,用户可以在用户图形界面配置第一数据仓库的路径和第二数据仓库的路径。如此,处理设备可以获取配置信息。
62.在另一些示例中,用户还可以在用户图形界面配置第一数据仓库的列名映射和待导入数据的列名。其中,列名映射用于给第一数据仓库中每一个命名。举例说明,第一数据仓库包括3列,列名映射可以为[1
‑2‑
3],然后处理设备可以根据列名映射按照顺序给每一列命名,例如第一列为“1”,第二列为“2”,第三列为“3”。待导入数据的列名可以是“2”,也可以是“1”和“2”等。
[0063]
在另一些示例中,用户还可以在用户图形界面配置时间字段,该时间字段用于对第一数据仓库中的数据进行二次筛选。例如时间字段为[2020.10.10
‑
2021.05.05],则处理设备筛选该时间区间内的数据。
[0064]
在另一些示例中,用户还可以在用户图形界面配置第二数据仓库中表名和表名所对应的主键,第二数据仓库中表名用于指示将第二数据存储的表,表名所对应的主键用于
指示第二数据在表中的存储位置。
[0065]
在另一些示例中,用户还可以在用户图形界面配置资源队列名,资源队列名用于指示处理设备使用的计算资源。在另一些示例中,若用户为配置资源队列名,处理设备使用默认的计算资源。
[0066]
s102:处理设备根据第一数据仓库的路径,从第一数据仓库中获取第一数据。
[0067]
在一些示例中,处理设备根据第一数据仓库的列名映射,为第一数据库仓库的每一列分配列名;然后处理设备根据第一数据仓库的路径,从第一数据仓库中的每一列的列名中查找与待导入数据的列名相对应的目标列名,获取该目标列名对应的第一数据。
[0068]
延续上例,第一数据库包括第一列“1”、第二列“2”和第三列“3”,待导入数据的列名为“2”,则该第二列的列名“2”为目标列名,然后处理设备获取该目标列名下对应的第一数据。
[0069]
在一些示例中,处理设备还可以根据时间字段对目标列名中的数据进行筛选,从目标列名中获取时间字段对应的第一数据。
[0070]
延续上例,时间字段可以是[2020.10.10
‑
2021.05.05],处理设备根据该时间字段,对目标列名中的数据进行筛选,得到该时间区间内的数据,如此获取时间字段对应的第一数据。
[0071]
s103:处理设备将第一数据的文件格式转换为第二数据仓库存储的数据的文件格式,得到第二数据。
[0072]
第一数据的文件格式为sequencefile格式,第二数据的文件格式为hfile格式。
[0073]
在一些实施例中,处理设备读取到第一数据后,可以在处理设备上,而不是在hbase侧对第一数据的文件格式进行转换,从而处理设备可以利用获取到的计算资源,对第一数据的文件格式进行批量转换,得到第二数据。
[0074]
在一些示例中,处理设备根据资源队列名,请求计算资源,然后利用计算资源将第一数据的文件格式转换为第二数据仓库存储的数据的文件格式。
[0075]
举例说明,处理设备能够使用的计算资源包括计算资源1、计算资源2和计算资源3,处理设备可以根据用户设置的资源队列名,在上述3个计算资源中选择一个或者多个计算资源进行文件格式的转换。在一些情况中,若用户未配置资源队列的情况下,处理设备可以选择默认的计算资源进行文件格式的转换,例如默认的计算资源为计算资源1。
[0076]
s104:处理设备根据第二数据仓库的路径,将第二数据导入到第二数据仓库中。
[0077]
在一些示例中,处理设备可以根据第二数据仓库的路径,将第二数据导入到第二数据仓库中表名所对应的表的主键中。
[0078]
举例说明,处理设备先根据第二仓库的路径,确定hbase的hdfs,然后在该hdfs中创建表名以及表名中的主键,再将第二数据导入到主键中。
[0079]
基于上述内容描述,本技术实施例提供了一种数据导入方法。该方法将第一数据的文件格式由sequencefile格式转换为hfile格式,得到第二数据,该第二数据的文件格式为hfile格式,由此可以直接将该第二数据导入到hbase中,无需通过hbase的api进行数据导入;进一步的,由于不通过hbase的api进行数据导入,故不会长时间占用该api,不会影响hbase在线查询的响应速度。并且由于将第一数据转换为第二数据的过程不再hbase侧,故可以实现批量对第一数据的文件格式进行转换,得到hfile格式的第二数据,然后直接将第
二数据导入到hbase,提高数据导入的效率。
[0080]
为了便于理解,下面以第一数据仓库中存储的数据为用户标签数据为例,介绍本技术实施例提供的数据导入方法。
[0081]
参见图2,该图示出了一种本技术实施例提供的数据导入方法的流程图。
[0082]
该方法包括:
[0083]
s201:通过shell脚本设置入参值。
[0084]
在一些示例中,入参值包括:hive的路径(hive的hdfs)、hbase的路径(hbase的hdfs)、hive的列名映射、待导入数据的列名、hbase的表名和该表名的主键、资源队列名、时间字段、其他字段等。
[0085]
以用户标签数据为例,用户标签数据是一种分级标签数据,例如第一级标签数据可以是用户的id,第二级标签数据可以是用户的昵称、年龄,第三级标签数据可以是用户的地区,第四级标签数据可以是用户的喜好、活跃度等。
[0086]
在一些示例中,可以以第四级标签数据的名称作为hive的列名映射。举例说明,第四级标签数据的名称为“f1”,则hive中第一例的列名可以是“f1”,以此类推。
[0087]
s202:根据入参值连接hdfs。
[0088]
在一些示例中,处理设备可以根据上述入参值的部分或者全部,设置hdfs的信息,例如namespace连接信息、高可用(high available,ha)信息、kerberos信息、文件输入输出格式(例如输入格式为sequencefile格式,输出格式为hfile格式)、任务名称、清空输出路径、设置目录权限信息等。
[0089]
其中,任务名称可以是本次作业的名称,为了保证每次作业输出的文件格式正确,每次作业前应当先清空输出路径,设置目标权限信息可以进一步保证数据文件的安全。
[0090]
s203:根据入参值,确定hdfs中待读取的数据。
[0091]
根据上述入参值的部分或者全部,确定待读取的数据。
[0092]
s204:读取hdfs中的数据。
[0093]
s205:对读取到的数据进一步筛选处理。
[0094]
在一些实例中,可以根据时间字段对读取到的数据进一步筛选处理。在另一些实施例中,还可以根据其他字段对读取到的数据进一步筛选处理。本技术对此不进行限定。
[0095]
s206:对数据的文件格式进行转换,得到hfile格式的文件。
[0096]
s207:输出hfile格式的文件。
[0097]
s208:将hfile格式的文件加载到hbase中。
[0098]
本实施例中,以mr为框架实现分布式程序设计,以shell作为传参入口,针对大数据量级的hive数据的进行处理,直接生成符合hbase底层要求的hfile格式的文件,并将hfile文件加载到hbase中。进一步的,本实施例中采用sheel脚本的方式,可以灵活的控制入参值,并完成一些复杂操作等。
[0099]
本技术实施例还提供了一种数据导入装置,如图3所示,该数据导入装置包括:
[0100]
获取单元301,用于获取配置信息,所述配置信息包括第一数据仓库的路径和第二数据仓库的路径;
[0101]
读取单元302,用于根据所述第一数据仓库的路径,从所述第一数据仓库中获取第一数据;
[0102]
转换单元303,用于将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式,得到第二数据;
[0103]
导入单元304,用于根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中。
[0104]
作为一种可能的实现方式,所述第一数据仓库为hive,所述第二数据仓库为hbase;所述配置信息还包括:所述第一数据仓库的列名映射、待导入数据的列名;所述装置还包括:映射单元;
[0105]
映射单元,用于根据所述第一数据仓库的列名映射,为所述第一数据库仓库的每一列分配列名;
[0106]
读取单元,具体用于根据所述第一数据仓库的路径,从所述第一数据仓库中的每一列的列名中查找与所述待导入数据的列名相对应的目标列名;获取所述目标列名对应的第一数据。
[0107]
作为一种可能的实现方式,所述配置信息还包括:时间字段;
[0108]
所述读取单元,具体用于根据时间字段,对所述目标列名中的数据进行筛选,从所述目标列名中获取所述时间字段对应的第一数据。
[0109]
作为一种可能的实现方式,所述配置信息还包括:第二数据仓库中的表名和所述表名所对应的表的主键;
[0110]
所述导入单元,具体用于根据所述第二数据仓库的路径,将所述第二数据导入到所述第二数据仓库中所述表名所对应的表的主键中。
[0111]
作为一种可能的实现方式,所述配置信息还包括:资源队列名;
[0112]
所述转换单元,具体用于根据所述资源队列名,请求计算资源;利用所述计算资源,将所述第一数据的文件格式转换为所述第二数据仓库存储的数据的文件格式。
[0113]
本技术实施例还提供一种电子设备,如图4所示,该所述电子设备包括处理器401和存储器402;
[0114]
所述处理器401用于执行所述存储器402中存储的指令,以使得所述电子设备执行上述实施例中任意一项所述的方法。
[0115]
本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行上述实施例中任意一项所述的方法。
[0116]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元及模块可以是或者也可以不是物理上分开的。另外,还可以根据实际的需要选择其中的部分或者全部单元和模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0117]
以上所述仅是本技术的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1