一种基于深度学习的购物平台商品垃圾评论的识别方法
1.本发明涉及一种基于深度学习的购物平台商品垃圾评论的识别方法。
背景技术:
2.随着互联网技术的逐渐成熟,网络购物应运而生,它的出现给越来越多的人带来便捷,满足了用户不用出门,就能轻松进行购物。与传统的线下商城相比,网站及各种网上购物 app 都会针对用户群体开放评论功能,人们在购物之后会习惯性的将用户体验以评论的形式发表出来。随着在线评论的数据量不断增长,它对网购用户做出购买决策起着至关重要的作用,这些在线评论可以作为其他消费者购买的参考依据,也有助于商家更好的搜集信息 。但是由于网络的开放性以及用户的言论自由,一些用户或者枪手因为某些利益,对一些商品发表垃圾评论,故意叫好或贬低某些商品 ,这些评论信息往往会对其他的用户造成误导,不仅不利于商城系统的维护与完善,也对信息资源造成了极大的浪费。
3.对于商家而言,有效识别垃圾评论,可以提升商家对于商品质量信息反馈的掌握程度,同时也给商家完善商品缺陷、优化销售方式及设置合理价格提供参考依据。对于消费者而言,由于当前在线购物平台评论数量的剧增,给消费者判别垃圾评论提取有效信息带来了极大的不便,而缺乏一个便捷、通用的评论筛选标准,也是当前消费者在进行评论信息获取和使用过程中遇到的一大难题 。为了维护消费者和商家的共同利益,解决在线购物平台平台的信誉损失问题,同时营造出一个积极健康的网络购物环境,需要对在线购物平台的垃圾评论识别问题展开相关研究工作。
4.因此,对商品的垃圾评论进行识别是十分有意义的,不仅仅具有丰富的理论价值,而且具有重要的实践意义,同时也是十分迫切和必要的。
5.有学者在研究中率先提出垃圾评论(opinion spam),在给出的垃圾评论定义中,将其分成了三大类别:
①
不真实的评论(untruthfulopinions);
②
仅针对品牌的评论(opinionsonbrands);
③
不包含任何情感的评论(non
‑
opinions)。垃圾评论识别研究主要包括以评论内容为中心(主要研究评论文本本身的特征)和以评论者为中心(主要研究评论者、评论团体的特征)进行垃圾评论识别的两种研究思路。
6.现有针对垃圾评论的识别方法中,主要的识别对象涉及垃圾评论者和垃圾评论内容的文本。深度神经网络模型正在渐渐应用于文本分类任务,但是在很多方面仍然有待研究,首先,由于短文本具有稀疏性、实时性、和不规则形的特点,基于深度学习的短文本分析算法难度较大;其次大多基于深度学习的文本分析算法应用场景都是英文,由于中文的复杂性,不是所有方法都适用于中文文本分析;最后由于虚假评论具有很强的迷惑性和隐蔽性,需要更有效的深度学习算法来挖掘其语义信息。需要对现有的深度学习算法进行改进,以挖掘以评论文本为典型代表的短文本中的语义信息并进行向量表示。针对上述问题,本文拟提出一种基于深度学习的商品垃圾评论识别模型。
技术实现要素:
7.本发明的目的是为了解决现有的商品垃圾评论的文本存在的稀疏性、隐蔽性等特点,导致的现有的基于深度学习的文本分析算法存在识别效果差的问题,而提出一种基于深度学习的购物平台商品垃圾评论的识别方法。
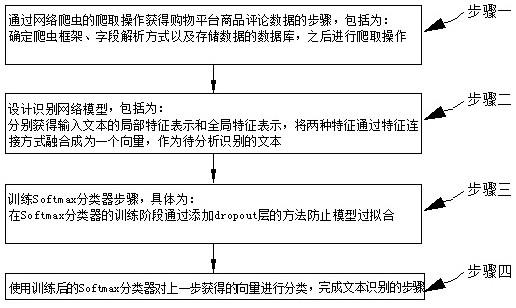
8.本发明内容为:一种基于深度学习的购物平台商品垃圾评论的识别方法,所述方法通过以下步骤实现:步骤一、通过网络爬虫的爬取操作获得购物平台商品评论数据的步骤,具体为:确定爬虫框架、字段解析方式以及存储数据的数据库,之后进行爬取操作;步骤二、设计识别网络模型,具体为:分别获得输入文本的局部特征表示和全局特征表示,将两种特征通过特征连接方式融合成为一个向量,作为待分析识别的文本;步骤三、训练softmax分类器步骤,具体为:在softmax分类器的训练阶段通过添加dropout层的方法防止模型过拟合;步骤四、使用训练后的softmax分类器对上一步获得的向量进行分类,完成文本识别的步骤。
9.优选地,步骤一所述的爬取操作包括:设计针对在线购物平台评论数据的爬虫流程,形成数据采集方案;根据所得到的数据研究基础,制定在线购物平台评论数据预处理及文本表示方案;利用中文分词、停用词过滤、关键词提取操作把爬取到的评论数据进行初步处理,利用特征选择及向量模型等操作对数据进行文本表示;其中,评论数据预处理包括文本分词、去除停用词、词义消歧、统计处理;且对中文文本进行分类之前,还要先进行分词处理,英文文本单词与单词之间则有空格进行分割,无需进行分词。
10.优选地,步骤二所述的将两种特征通过特征连接方式融合成为一个向量,作为待分析识别的文本的过程,具体为:将局部特征表示和全局特征表示输入到网络的全连接层,对二者进行融合,全连接层的输出为一个融合了全局特征和局部特征的向量,这个向量即为待进行分析识别的文本。
11.优选地,步骤三所述的训练softmax分类器步骤是采用长短期记忆网络或门控循环单元网络进行文本处理,在处理当前的单词的同时将包含这个单词的信息通过权重传递给即将处理下一个单词的神经元,使得中间层不断对自己更新,以保留之前单词的历史信息。
12.本发明的有益效果为:本发明是将深度学习的算法应用到购物平台中商品垃圾评论文本的识别,结合卷积神经网络和循环神经网络的特点,本发明设计了基于并联方式的混合神经网络识别模型,可以一边处理当前的单词,一边将包含这个单词的信息通过权重传递给即将处理下一个单词的神经元,使得中间层不断对自己更新,以保留之前单词的历史信息,从而让整个文
本的上下文信息都被利用,文本之间的关联得到挖掘。
13.本发明用于分析网购平台中的商品评论文本,识别出其中的商品垃圾评论。通过准确率(accuracy)、精确率(precision)、召回率(recall)和 f1 值(f1
‑
score)四个指标验证了本发明方法的可行性,本发明能够同时提取出文本的全局信息和局部信息,对文本信息的利用更充分,提高文本处理性能,并提高了模型的识别正确率。
附图说明
14.图1为本发明的流程图。
具体实施方式
15.具体实施方式一:本实施方式的一种基于深度学习的购物平台商品垃圾评论的识别方法,如图1所示,所述方法通过以下步骤实现:步骤一、通过网络爬虫的爬取操作获得购物平台商品评论数据的步骤,具体为:确定爬虫框架、字段解析方式以及存储数据的数据库,之后进行爬取操作;步骤二、设计识别网络模型,具体为:分别获得输入文本的局部特征表示和全局特征表示,将两种特征通过特征连接方式融合成为一个向量,作为待分析识别的文本以用于对其进行识别分类;步骤三、训练softmax分类器步骤,具体为:在softmax分类器的训练阶段通过添加dropout层的方法防止模型过拟合的情况;步骤四、使用训练后的softmax分类器对上一步获得的向量进行分类,完成文本识别的步骤。
16.本发明设计了基于并联方式的混合神经网络识别模型,并通过准确率(accuracy)、精确率(precision)、召回率(recall)和 f1 值(f1
‑
score)四个指标验证了本发明方法的可行性,本发明能够同时提取出文本的全局信息和局部信息,对文本信息的利用更充分,提高文本处理性能。
17.其中,四个指标的具体含义是:(1)准确率是评判模型整体的识别能力,即判断正确输出为虚假评论和真实评论的百分比;(2)精确率反应的是被模型分类为虚假评论中的虚假评论比例;(3)召回率反应的是被模型分类的正确样本占总样本的百分比;(4)f1 值为综合表达精确率和召回率的值,通常认为其是精确率和召回率的加权平均值。
18.具体实施方式二:与具体实施方式一不同的是,本实施方式的一种基于深度学习的购物平台商品垃圾评论的识别方法,步骤一所述的爬取操作包括:基于爬虫系统框架及原理,设计针对在线购物平台评论数据的爬虫流程,形成数据采集方案;根据所得到的数据研究基础,制定在线购物平台评论数据预处理及文本表示方
案;利用中文分词、停用词过滤、关键词提取等操作把爬取到的评论数据进行初步处理,降低数据噪声,提高数据质量,并利用特征选择及向量模型等操作对数据进行文本表示,为后续模型的训练及实验环节做好数据支撑;其中,评论数据预处理包括文本分词、去除停用词(包括标点、数字和一些无意义的词)、词义消歧、统计等处理;且对中文文本进行分类之前,还要先进行分词处理,英文文本单词与单词之间则有空格进行分割,无需进行分词;网络爬虫即数据采集程序,其中,爬虫是一种通过爬取网站信息获取网页中的内容,以便后续研究分析的程序流程。某种意义上来说,网络爬虫就是对所需要访问的网页进行request请求处理和response反馈的操作。当请求访问网站通过时,爬虫程序会根据已写好的爬虫规则进行全覆盖式的爬取内容操作。通过选定研究对象的网站作为目标网站保存到下载列表中,爬虫执行的时候会从url队列中按照顺序依次调用已保存的目标网站的url地址,然后程序会通过本地服务器获取该网页对应的ip地址,爬取地址里面的数据信息。
19.具体实施方式三:与具体实施方式一或二不同的是,本实施方式的一种基于深度学习的购物平台商品垃圾评论的识别方法,步骤二所述的将两种特征通过特征连接方式融合成为一个向量,作为待分析识别的文本的过程,具体为:将局部特征表示和全局特征表示输入到网络的全连接层,对二者进行融合,全连接层的输出为一个融合了全局特征和局部特征的向量,这个向量即为待进行分析识别的文本。
20.具体实施方式四:与具体实施方式三不同的是,本实施方式的一种基于深度学习的购物平台商品垃圾评论的识别方法,步骤三所述的训练softmax分类器步骤是采用长短期记忆网络或门控循环单元网络进行文本处理,在处理当前的单词的同时将包含这个单词的信息通过权重传递给即将处理下一个单词的神经元,使得中间层不断对自己更新,以保留之前单词的历史信息,从而利用长短期记忆网络或门控循环单元网络变体循环神经网络rnn解决rnn 中因一系列 w 的连乘随着时间序列的加长,出现的梯度爆炸或有梯度消失的问题;其中,|w|表示权重矩阵的值,w是隐藏层上一次的值作为这一次的输入的权重,当权重|w|>11,出现梯度爆炸,当|w|<1,出现梯度消失的问题。
21.实施例1:以京东在线购物平台下的手机、电脑、耳机三类商品的评论数据作为研究对象,搭建实验环境,利用本发明的基于深度学习的购物平台商品垃圾评论的识别方法设计的改进识别模型,将处理好的数据输入模型进行训练。设计垃圾评论识别实验,利用不同方法进行对比实验,通过实验结果证明该模型的有效性,同时提出相应的对策建议,为当前垃圾评论的识别问题提供一种切实可行的解决办法。并采用准确率(accuracy)、精确率(precision)、召回率(recall)和 f1 值(f1
‑
score)4个指标来验证了本发明方法的准确性。
22.以上仅为本发明的优选实施方式而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修
改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1