一种基于值函数的参数化深度强化学习算法
1.本发明属于深度强化学习技术领域,具体涉及基于值函数的参数化深度强化学习算法。
背景技术:
2.近几年来,深度强化学习为复杂序贯决策问题提供了新的解决方案,其中之一是为电脑游戏设计ai(artificial intelligence)智能体(agent)。基于深度强化学习算法,alphago和alphazero在围棋领域中击败了各路世界冠军[1]。此外,游戏ai在atari游戏[2]、robot soccer足球游戏[3]、torcs赛车模拟游戏中[4]均取得近乎甚至超越人类的表现。
[0003]
传统的深度强化学习算法要求动作空间为离散或者连续之一:其中离散动作空间下的深度强化学习算法包含dqn[3]、double dqn[5]和a3c[6]等;连续动作空间下的深度强化学习算法包含dpg[7]、ddpg[4]等。智能体在进行决策时,需要从有限的离散动作集中选择某个离散动作,或者从连续动作区间中选取特定的连续参数。
[0004]
然而,对于现实生活中的具体任务,动作空间往往具有更复杂的参数化结构,即离散连续混合动作空间。智能体获取到环境状态信息后,需要先从离散动作空间[k]中选取一个高层级离散动作k,接着需要从动作k对应的连续动作空间中选定低层级连续动作x
k
。
[0005]
若要利用传统深度强化学习处理离散连续动作混合动作空间,常见的做法为:
[0006]
(1)将连续动作离散化:即将连续动作空间近似为离散动作子集,并利用离散深度强化学习算法进行训练。但是该方式在近似过程中粗粒度会导致连续动作选择范围缩小,细粒度会导致近似后离散动作空间过于庞大;
[0007]
(2)将离散动作连续化:即将离散动作集[k]放松至连读动作空间,并利用连续深度强化学习算法进行训练[8]。但是该方式会增大动作空间复杂度,使得算法难以收敛。
技术实现要素:
[0008]
本发明的目的在于提供一种无需改变动作类型即可直接作用于离散连续混合动作空间,从而实现更快的收敛速度和更好的收敛效果的基于值函数的参数化强化学习算法。
[0009]
本发明提供的基于值函数的参数化强化学习算法,是将强化学习中的状态动作值函数(q值)分解为状态值函数(v值)和优势函数(a值)之和,其中v值用于估计各离散动作下的期望累计奖励,而a值用于估计各连续动作带来的累计奖励偏差。通过构建单个神经网络,即可同时输出最优离散动作和连续动作选择。本发明提出的算法同时解决了q值过估计问题,在动作决策时离散动作v值仅取决于其对应的连续动作,在神经网络训练过程中连续动作更新仅与其对应的离散动作有关。从仿真实验结果可以得出,相比于其余参数化强化学习算法,本发明提出的算法实现了更快的收敛速度和更好的收敛效果。
[0010]
本发明提供的基于值函数的参数化强化学习算法,具体步骤如下。
[0011]
(一)首先,对参数化动作空间进行数学建模,具体包括:
[0012]
参数化动作空间包含离散动作集和相应的连续动作集其中k表示离散动作个数,m
k
表示离散动作k下的连续动作维度。因此,参数化动作空间可以定义为:
[0013][0014]
参数化动作空间下的马尔可夫决策过程定义为pamdp(partially observable markov decision process)[9]。对于pamdp模型process)[9]。对于pamdp模型为状态空间,为参数化动作空间,p(s
′
|s,k,x
k
)为状态转移概率函数,r(s,k,x
k
,s
′
)为奖励函数,γ∈[0,1]为奖励折扣因子。则状态值函数可以定义为q(s,a)=q(s,k,x
k
),策略完成状态空间和动作空间的映射。定义k
t
为t时刻选定的离散动作,为相应额连续动作,则参数化动作空间下的贝尔曼方程为:
[0015][0016]
为了得到最优q值,需要对各离散动作k∈[k]求解得出最优连续动作选择:
[0017][0018]
然后比较各离散动作下的q值,并得到最大q值然而,由于神经网络为非凸函数,求取最优连续动作十分困难。
[0019]
(二)其次,构建神经网络结构,具体包括:
[0020]
本发明构建的神经网络结构,如图1所示,由输入层、隐含层和三部分输出层构成。神经网络将状态动作值函数q值q(s,k,x
k
)分解为状态值函数v值v(s,k)和优势函数a值a(s,k,x
k
)之和:
[0021]
q(s,k,x
k
;θ)=v(s,k;θ)+a(s,k,x
k
;θ),
[0022]
其中,v值v(s,k)代表离散动作k下的期望累计奖励,a值a(s,k,x
k
)代表x
k
带来的期望累计奖励和v(s,k)的偏差,θ代表神经网络的参数。
[0023]
为了确保求取最优连续动作有确切解,同时确保带来最大a值的连续动作为最优,需要限制a值a(s,k,x
k
)为连续动作x
k
的二次函数,即:
[0024][0025]
其中x
k
(s;θ)为神经网络的预测连续动作,x
′
k
为真实连续动作,p(s;θ)为依赖于环境状态s的对称正定方阵,计算式为:
[0026]
p(s;θ)=l(s;θ)l(s;θ)
t
,
[0027]
其中,l(s;θ)为下三角矩阵,其元素为神经网络输出值的重新排列,且对角线元素指数化。由乔列斯基(cholesky)分解[10]可知,一个对称正定方阵可以表示为主对角元素均为正数的下三角矩阵和它的转置的乘积。因此,通过构造下三角矩阵l(s;θ),可以保证p(s;θ)为对称正定方阵,从而也确保a值a(s,k,x
k
)恒小于等于0,且当a(s,k,x
k
)=0时,此刻的连续动作x
k
为最优动作。
[0028]
(三)最后,设计算法流程,具体包括:
[0029]
首先,初始化策略网络q(s,k,x
k
;θ)和目标网络q
′
(s,k,x
k
;θ
′
),其中目标网络的参
数θ
′
与策略网络的参数θ保持一致。同时初始化经验回放池(replay buffer)d,以存储状态转移信息。
[0030]
为了鼓励智能体(即车载设备)充分探索动作空间以寻找最优动作,离散动作和连续动作的选择分别依照∈
‑
贪婪策略和ou过程。对于离散动作k,智能体将以∈的概率在离散动作空间[k]中随机选取,以1
‑
∈的概率选取v值最高的离散动作,即:
[0031][0032]
对于连续动作x
k
,将利用ou过程添加序贯相关的噪声,即:
[0033][0034]
其中,表示均值回归速率,μ表示均值,σ表示波动率,w
t
表示维纳过程。
[0035]
在t时刻,智能体观测到环境状态s
t
,依照神经网络输出分别得到离散动作k
t
和连续动作并执行联合动作此时环境状态转变为s
t+1
并反馈给智能体相应奖励r
t
。智能体将环境转变存储至经验回放池d中。在神经网络参数更新过程中,智能体从经验回放池d中随机采样出批量训练数据目标值y
i
均设为单步奖励r
i
与目标网络q
′
(s,k,x
k
;θ
′
)输出得到的最大v值之和,即:
[0036]
y
i
=r
i
+γmax
k∈[k]
v
′
(s
i+1
,k;θ
′
),
[0037]
其中,γ为奖励折扣因子。为了使策略网络q(s,k,x
k
;θ)的估计q值逼近目标值y
i
,损失函数l
t
设置为目标值y
i
与策略网络输出q值的均方差,即:
[0038][0039]
通过梯度下降法对策略网络参数进行更新,以最小化损失函数l
t
,即:
[0040][0041]
其中,α为学习率。最后对目标网络参数进行软更新(soft update),即:
[0042]
θ
′←
τθ+(1
‑
τ)θ
′
,
[0043]
其中,τ为软更新率。智能体以上述方式进行迭代训练直至收敛。
[0044]
本发明提出的基于值函数的参数化深度强化学习算法,在platform游戏平台可以实现更快的收敛速度和更好的收敛效果。相比于其余参数化强化学习算法,本发明提出的算法主要有以下三大优点:
[0045]
(1)单个网络同时输出离散动作v值和连续动作选择,无需构造额外网络;
[0046]
(2)离散动作v值仅取决于其对应的连续动作,不受其余连续动作的影响;
[0047]
(3)连续动作更新仅与其对应的离散动作有关,不受其余离散动作干扰。
附图说明:
[0048]
图1为本发明的神经网络结构。
[0049]
图2为platform游戏平台截图。
[0050]
图3为本发明方法与其他算法的训练结果对比图。
[0051]
图4为本发明方法与其他算法的测试结果对比图。
具体实施方式
[0052]
设实施例的参数
[0053]
仿真环境:python;
[0054]
游戏平台:如图2所示;
[0055]
训练批量大小:128;
[0056]
学习率:0.0001;
[0057]
目标网络更新率:0.01。
[0058]
基于值函数的参数化深度强化学习算法,具体步骤为:
[0059]
步骤1:初始化策略网络q(s,k,x
k
;θ)和目标网络q
′
(s,k,x
k
;θ
′
),其中θ
′←
θ。初始化经验回放池
[0060]
步骤2:观测当前环境状态s
t
,依照∈
‑
贪婪策略选择离散动作k
t
,依照ou过程选择相应连续动作并执行离散连续混合动作
[0061]
步骤3:观测下一环境状态s
t+1
并获得单步奖励r
t
;
[0062]
步骤4:将环境转变储存至经验回放池d,再从经验回放池d中随机采样批量训练数据
[0063]
步骤5:设置目标值y
i
=r
i
+γv
′
(s
i
,k
i
),更新q网络参数更新目标网络参数θ
′←
τθ+(1
‑
τ)θ
′
。
[0064]
仿真结果:
[0065]
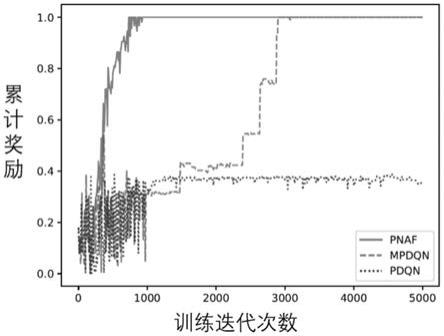
如图3所示,本发明方法与其他算法的训练结果对比图,随着迭代次数的不断增加,三种算法得到的累计奖励不断增大,而本发明提出的算法相比于另外两种比较算法,收敛速度最快且收敛效果最好。
[0066]
如图4所示,本发明方法与其他算法的测试结果对比图,去除了∈
‑
贪婪策略和ou噪声干扰。本发明提出的算法在800次迭代左右即可收敛至最优策略并稳定于此。
[0067]
参考文献
[0068]
[1]silver d,huang a,maddison c j,et al.mastering the game of go with deep neural networks and tree search[j].nature,2016,529(7587):484
‑
489.
[0069]
[2]mnih v,kavukcuoglu k,silver d,et al.human
‑
level control through deep reinforcement learning[j].nature,2015,518(7540):529
‑
533.
[0070]
[3]hausknecht m,stone p.deep reinforcement learning in parameterized action space[j].arxiv preprint arxiv:1511.04143,2015.
[0071]
[4]lillicrap t p,hunt j,pritzel a,et al.continuous control with deep reinforcement learning[j].arxiv preprint arxiv:1509.02971,2015.
[0072]
[5]van hasselt h,guez a,silver d.deep reinforcement learning with doubleq
‑
learning[c]//proceedings of the aaai conference on artificial intelligence.2016,30(1).
[0073]
[6]mnih v,badia a p,mirza m,et al.asynchronous methods for deep reinforcement learning[c]//international conference on machine learning.pmlr,2016:1928
‑
1937.
[0074]
[7]silver d,lever g,heess n,et al.deterministic policy gradient algorithms[c]//international conference on machine learning.pmlr,2014:387
‑
395.
[0075]
[8]hausknecht m,stone p.deep reinforcement learning in parameterized action space[j].arxiv preprint arxiv:1511.04143,2015.
[0076]
[9]monahan g e.state of the art—a survey of partially observable markov decision processes:theory,models,and algorithms[j].management science,1982,28(1):1
‑
16.
[0077]
[10]higham n j.cholesky factorization[j].wiley interdisciplinary reviews:computational statistics,2009,1(2):251
‑
254.。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1