一种可端到端训练的同时进行目标检测与显著性排序的方法
1.本发明属于图像检测领域,尤其是涉及一种可端到端训练的同时进行目标检测与显著性排序的方法。
背景技术:
2.图像主体是画面中的主要拍摄目标,主体目标的识别技术对于图像视频内容理解和二次创作具有重要的价值,显著目标排序(salient object ranking,sor)算法通过提取画面的多个主体目标位置(及其重要性排序),为主体相关的下游任务提供帮助。
3.目前该技术已经应用在视频智能剪裁的项目中,同时该技术对于视频切条、剪辑等二创应用具有直接的商业价值,是文娱人工智能创作的重要核心技术。目标检测(object detection)和显著性检测(salient object detection,sod)在学术界通常被作为两类算法研究。
4.siris等人在cvpr20上发表的论文《inferring attention shift ranks of objects for image saliency》,提出的模型包括一个骨干网络,选择性注意模块(sam),空间遮罩模块(smm)和一个用于显著对象排名的分类网络。利用mask
‑
rcnn作为自下而上的主干,以fpn的形式提供对象建议,并从分段分支中提供对象细分。自下而上的smm提取建议对象的低级特征,而自上而下的sam则考虑高级上下文关注特征。
5.上述方案存在以下缺点:这种方法需要通过两个阶段训练:首先训练一个类别无关的mask
‑
rcnn检测器,然后离线提取完特征图、候选框、物体的遮罩后,再开始训练排序模块。不是直接端到端训练,导致最终目标不能进行总体优化。其次,空间信息对于目标的显著性很重要,中心位置或者尺寸更大的物体通常具有更大的显著性,这一点在这个方法里被忽视了。最后,每个对象的最终排序得分是独立预测的,而没有考虑到对象之间特征的相对显著性。
6.显著性目标排序任务相比于常见的图像检测分割任务,其一个重要的特点是对于位置和尺度的敏感性。换句话说,一个人物在画面中的位置和大小,并不影响其是人物的性质(类别),以及人物外形具有的特点(检测与分割),这些信息通常被视为任务的先验知识,是一个绝对信息。而显著性目标排序则不同,同样一个人物在画面的中间还是角落,可能直接会从前景主体变成背景;类似的,大小也对排序任务具有重要的影响,因此对于显著性任务这些信息是相对信息。如何有效的利用画面内物体间的相互信息是解决显著性排序任务的关键,这也是直接应用检测框架所难以解决的。
技术实现要素:
7.为解决现有技术存在的上述问题,本发明提供了一种可端到端训练的同时进行目标检测与显著性排序的方法,可通过单模型解决目标检测和排序,在公开数据集上显著领先于现有的模型结构。
8.一种可端到端训练的同时进行目标检测与显著性排序的方法,包括以下步骤:
9.(1)获取图像样本,对于每张图像样本中出现的主体,根据显著性标注它们的排序,并去除没有显著主体的图像样本;筛选出高质量的显著性排序数据集,并把显著性排序数据集按比例划分为训练集和验证集;
10.(2)建立一个目标检测排序模型,所述的目标检测排序模型包括主干网络、目标检测分支和显著性排序分支;其中,主干网络用于进行特征提取,并将提取的语义特征共享给检测分支和显著性排序分支;
11.所述的检测分支根据语义特征预测目标的类别和位置坐标,所述的显著性排序分支根据语义特征及检测分支的结果进行显著性排序;
12.(3)利用训练集对显著性排序模型进行训练,并利用验证集对正在训练的模型进行验证;
13.(4)使用训练好的目标检测排序模型进行推理,输入一张新的图片,检测出图片中的主体,并且给出每个主体的显著性排序。
14.进一步地,步骤(2)中,所述的主干网络为基于卷积神经网络的特征提取器,包括但不限于resnet和efficientnet。
15.进一步地,所述特征提取器的生成的特征图与坐标图进行链接,从而辅助显著性排序分支的位置感知。
16.进一步地,所述的目标检测分支包含一个分类器和一个回归器,分别用于预测目标的类别和位置坐标。
17.进一步地,所述的显著性排序分支包含排序注意力模块,所述的排序注意力模块包括位置特征嵌入部分和上下文特征交互部分;
18.其中,所述的位置特征嵌入部分通过位置表征引入相对信息,所述的上下文特征交互部分采用多头的注意力编码机制进行画面中物体间的特征交互。
19.进一步地,所述位置特征嵌入部分工作的具体过程为:
20.不同主体的位置坐标构成相对坐标图,先通过稠密连接层形成位置嵌入,之后位置嵌入和语义特征连接后向量化,作为上下文特征交互部分的视觉分词向量。
21.所述上下文特征交互部分工作的具体过程为:
22.采用transformer编码器的结构,将得到的视觉分词向量作为输入,所有正样本分词向量通过多头的注意力机制进行信息交互,得到含有其位置嵌入的视觉分词;每个视觉分词通过注意力结构感知到其他目标的语义和位置信息,从而得到最终的上下文表征,此表征通过全连接层进行目标显著性排序的预测。
23.多头的注意力编码机制进行信息交互时,每一个输入的视觉分词对应于一个正样本roi计算得到的含有其位置嵌入的视觉分词。
24.与现有技术相比,本发明具有以下有益效果:
25.1、本发明的方法首次提出了一个端到端的框架,把显著性排序问题建模成一个多任务学习问题。在这个框架中,显著性排序分支和检测分支可以一起训练,整个模型可以一起优化。另外,得益于这个框架,显著性排序分支可以和不同的检测器相结合,这个模块具有可插拔性。
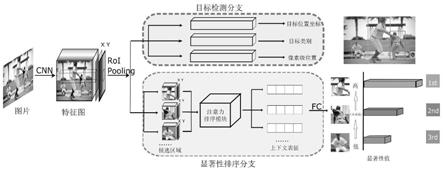
26.2、在排序注意力模块(position
‑
perserved attention,ppa)的特征提取阶段,我们在roi pooling之前就保留了特征图的坐标信息,在roi pooling之后,每个对象的2d坐
标信息被完整保留,通过后续操作最终得到具有位置信息的物体特征。
27.3、在排序注意力模块中,引入transformer编码器的注意力机制来实现不同物体特征之间的交互,使得它们可以感知到其他物体的特征,进而得到一个基于上下文语义的特征表达。这体现了排序问题的相对性,大大提高了实验效果。
附图说明
28.图1为本发明中目标检测排序模型的结构图;
29.图2为目标检测排序模型中显著性排序分支的结构图。
具体实施方式
30.下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
31.本发明提出了一种可端到端训练的同时进行目标检测与显著性排序的方法,构建了目标检测排序模型,包括主干网络、目标检测分支和显著性排序分支;其中,主干网络用于进行特征提取,并将提取的语义特征共享给检测分支和显著性排序分支;检测分支根据语义特征预测目标的类别和位置坐标,所述的显著性排序分支根据语义特征及检测分支的结果进行显著性排序。通过对模型的端到端训练,在单模型下解决了目标检测与显著性排序问题。
32.如图1所示,系统的输入是需要处理的图片(左侧),输出是图片中的主体目标检测结果(右上),包括包围框的位置坐标和分割的像素级掩膜(mask),以及多个目标的显著性排序(右下)。
33.处理步骤从左到右依次为:1.共享的特征提取网络(主干网络)2.兴趣区域(roi)上的目标检测分支(detection branch)3.兴趣区域(roi)上的显著性排序分支(sor branch)。下面分别详细介绍其中的各部分内容。
34.第一部分是共享的特征提取网络(主干网络),同时为两个roi下游模块提供特征提取,其典型实现是基于卷机神经网络的特征提取器,学术界流行的例如resnet、efficientnet等,常见的主干(backbone)网络都适用,在结构上不具有特殊性。与典型特征提取器不同的是,结果的特征图会与坐标图进行链接,从而辅助sor模块的位置感知。
35.第二部分是目标检测预测分支,如图1上半部分所示,典型的目标检测预测分支包含一个分类器(classifier)和一个回归器(regressor),分别预测目标的类别和位置坐标(x,y,w,h),如果有合适的标注数据,可以同时预测物体的像素级位置(mask)。此部分的预测分支和第一部分的特征提取网络(除去坐标链接)即是典型的目标检测模型,常见的有mask rcnn,centernet等,此预测结构同样不具有特殊性,本方案提出的框架可以适用于各类学术界流行的目标检测模型。
36.第三部分是显著性排序分支,如图1下半部分所示,该模块将第一部分特征提取的特征进一步处理,在多个正样本区域(roi)上进行进一步的显著性特征提取与交互,从而计算出最终的语境表征(contextualized representation),其表征即可通过全连接层(fc)进行目标的排序预测。此部分是本提案的核心,其详细结构图如图2所示。
37.本发明提出的显著性排序分支包含排序注意力模块,排序注意力模块包括位置特
征嵌入部分和上下文特征交互部分其核心是:1.首先通过位置表征引入相对信息2.采用多头的注意力编码机制,进行画面中物体间的特征交互。
38.位置特征嵌入部分:如图2中(b)所示,语义特征和相对坐标图的抽象层次不一,因此相对坐标图先通过卷积为主的稠密连接模块,形成位置嵌入(position embedding),这一步类似于自然语言处理中可学习的位置嵌入,只不过使用卷积的2d形式。之后位置嵌入和语义特征连接(concat)后向量化,作为后续模型的视觉分词向量(visual token)
39.上下文特征交互部分:如图2中(a)所示,此部分采用transformer编码器的结构,将得到的视觉分词向量作为输入,所有正样本分词向量通过多头的注意力机制进行信息交互,其结构与原版attention类似,独特性在于每一个输入的视觉分词对应于一个正样本roi计算得到的含有其位置嵌入的视觉分词。在这一步,每个视觉分词通过注意力结构感知到了其他目标的语义和位置信息,从而得到最终的上下文表征(contextualized representation),此表征通过全连接层即可进行目标显著性排序的预测。
40.目标检测(object detection)和显著性检测(salient object detection,sod)在学术界通常被作为两类算法研究。本发明的方法首次提出了一种可端到端训练的同时目标检测与显著性排序(sor)算法,在多任务学习(multi
‑
task learning)的框架下,单模型解决了前景目标检测和排序,在公开数据集上显著领先于sota。
41.本发明首次提出了可以端到端训练(end
‑
to
‑
end trainable)的显著目标排序sor框架,并证明端到端的模型可显著优于传统的多模型串联结构。同时,在多任务学习的框架下,提出了位置保留的排序注意力模块(position
‑
perserved attention,ppa),解决了典型检测模型中位置和尺度无关性的问题,有效的提升了排序精度。
42.经过测试,在学术公开数据集asr上,本发明的方法的性能显著的高于cvpr 2020的sota方法,同时由于是单模型的简洁结构,在部署和计算上也具有明显的优势。
43.以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1