基于数据样本增强的深度学习模型去偏方法和装置
1.本发明属于深度学习领域,具体涉及基于数据样本增强的深度学习模型去偏方法和装置
背景技术:
2.深度学习模型拥有强大的学习样本数据集内在函数规律和分析抽象化特征的能力,近年来在很多领域辅助人们做出决策并给很多复杂的识别以及分类问题提供了解决方案。深度学习在生物信息学、图形图像识别、语音识别、无人驾驶汽车、艺术创作、情感识别、自然语言处理、银行、监狱、生涯评估和刑事司法判决等领域都起到了很好的效果。并且随着相关科研工作人员的不断努力,深度学习模型的效率不断提高,应用范围也更加广泛,对人们现在的日常生活产生了更为重要的影响。
3.深度学习模型在刑事司法、信贷、金融预测等领域的广泛应用使得相关领域的工作效率大大提升、发展速度大大增加,但如果其分析结果存在偏见,将给相关领域和相关个人及群体带来强大的负面影响,因此深度学习模型的一个研究重点就在于在保证深度学习模型的性能的同时提高模型的公平性,避免产生相关危害。深度学习模型产生偏见的原因是,在一般的深度学习当中,模型通过学习过去的经验来指导未来的任务,即将预测结果和过去的经验尽量的相符合,但是数据集的不完善性可能会导致模型训练过程中不断接受数据集中的偏见,最终导致过去经验的偏见通过训练在模型中不断积累,并导致训练完毕的模型受到如年龄、性别等敏感属性的影响导致预测结果发生变化。例如,来自uci机器学习知识库的心脏病数据集包含了不同年龄段患者的14个处理过的特征,数据的稀少性导致偶然时间发生的比重大大增加。当医疗领域使用这个数据集训练模型用来预测一个患者未来是否可能会得心脏病时发现年龄对预测结果的影响过大,从而导致了年龄这一敏感属性引发的偏见对患者的治疗过程产生了不好的影响。现有专利中的去偏方法主要针对图像和语言数据集,鉴于深度学习模型的偏见会引发上述的问题,并且相关领域缺少针对用于表格数据集模型的去偏方法,研究一种基于对模型再训练的无偏模型训练方法,缓解模型的偏见程度具有极其重要的理论与实践意义。
技术实现要素:
4.本发明公开了一种基于数据样本增强的深度学习模型去偏方法,该方法能够有效去除社会偏见。
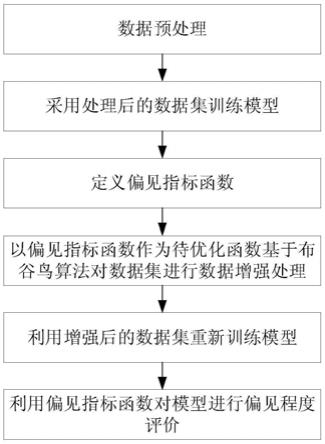
5.一种基于数据样本增强的深度学习模型去偏方法,包括:
6.s1:获得数据集,利用one
‑
hot编码,筛选数据集中敏感属性数据集作为样本集,所述样本集基于敏感属性分为特权样本集和非特权样本集;
7.s3:通过多个偏见指标构建偏见指标函数,对偏见指标函数进行训练,将样本集输入至偏见指标函数得到偏见值,采用布谷鸟搜索方法迭代样本集,并将迭代样本集输入至偏见指标函数,直至偏见值满足偏见阈值,或迭代次数满足迭代阈值则停止迭代,得到增强
样本集,完成偏见指标函数的训练,获得最终偏见指标函数;
8.s2:构建预测收入模型,所述预测模型包括多个特征提取器和两个分类器,所述特征提取其包括多个线性层和relu激活函数,所述分类器包括多个全连接层;
9.s3:利用强化样本集训练收入预测模型,训练时,收入预测损失loss_m1,和去社会偏见损失loss_m2组成的总损失loss为最终损失,其中,去社会偏见损失loss_m2为:
10.loss_m2=
‑
∑h(x)
·
log(y
n
)+(
‑
∑h(x)
·
log(h(x
′
))
11.其中,h()为收入预测模型,x为特权样本集,x
′
为非特权样本集,y
n
为敏感属性;
12.s4:每训练一阶段,将收入预测模型输出的收入预测结果和强化样本集通过最终偏见指标函数进行测算,当最终偏见指标函数计算结果满足偏见阈值,则获得最终收入预测模型;
13.s5:应用时,将待测样本输入至最终收入预测模型中,经计算得到收入预测结果。
14.本发明利用布谷鸟搜索方法实现训练样本增强,通过增强后的样本对收入预测模型进行再训练,实现深度学习模型的去偏方法,以缓解模型的偏见程度,提升模型分类的公平性。
15.所述数据集为adult数据集,所述adult数据集包括14种类别属性,其中,4个敏感属性,adult数据集用14个特征来对每个个体进行描述,用来预测一个人的收入是否超过收入阈值,
16.利用one_hot编码对敏感属性进行扩充且均处理为二分类序列,并能够根据需求扩充需求敏感属性的数量,而减少样本集中的剩余敏感属性的数量。
17.通过one
‑
hot编码对将敏感属性处理为二分类序列增加了数据处理速度,提高了效率,增强需求敏感属性数量而减弱剩余敏感属性的数量,能够增加收入预测模型的预测准确性和分类公平性,偏见指标函数判断准确性。
18.所述的偏见指标函数f(d)为:
[0019][0020]
其中,d为样本集,x为特权样本集,x
′
为非特权样本集,y为预测结果,p[
·
]为条件概率。
[0021]
所述的布谷鸟搜索方法为:
[0022][0023][0024]
x
t+1
为输出样本集,x
t
为输入样本集,α为步长缩放因子,levy(β)为莱维随机路径,,r为∈服从均匀分布的随机数,heaviside(
·
)是赫维赛德函数,p
α
为用于平衡局部和全局随机游走的切换参数,x
j
和x
j
为随机选择的样本集。
[0025]
将样本集输入至预测收入模型得到预测收入结果,将预测收入结果和样本集输入至最终偏见指标函数得到偏见值,通过偏见值得到预测收入模型的偏见程度。
[0026]
所述的收入预测损失loss_m1为:
[0027]
loss_m1=
‑
[y
m
·
log(p)+(1
‑
y
m
)
·
log(1
‑
p)]
[0028]
y
m
为类别属性,p为预测结果超过收入阈值的概率。
[0029]
一种基于数据样本增强的深度学习模型去偏装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机存储器中采用权利要求1
‑
7所述的基于数据样本增强的深度学习模型去偏方法构建收入预测模型;
[0030]
所述算机处理器执行所述计算机程序时实现以下步骤:
[0031]
将待测样本输入至收入预测模型中,经计算得到收入预测结果。
[0032]
与现有技术相比,本发明的有益效果为:
[0033]
本发明利用改进的布谷鸟搜索方法,训练后的偏见指标函数结合作用,实现样本集增强,通过增强后的样本集对收入预测模型进行再训练,实现深度学习模型的去偏,以缓解模型的偏见程度,提升模型分类的公平性能够。
附图说明
[0034]
图1为本发明具体实施方式提供的基于数据样本增强的深度学习模型去偏方法的框图;
[0035]
图2为本发明具体实施方式提供的偏见指标函数的流程图;
[0036]
图3为本发明具体实施方式提供的基于数据样本增强的深度学习模型去偏方法的流程图。
具体实施方式
[0037]
下为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
[0038]
为了解决由于深度学习模型存在偏见问题导致的分类结果不准确的问题。本实施例提供了一种基于数据样本增强的深度学习模型去偏方法,如图1所示,流程图如图3所示,该基于数据样本增强的深度学习模型去偏方法包括以下步骤:
[0039]
(1)深度学习模型偏见的定义。
[0040]
针对分类任务,将把分类模型在做出决策时,受到无关但敏感特征的影响,并且其决策可能会会依赖于这种错误的特征关联的现象定义为模型的偏见行为。
[0041]
(2)数据集准备及预处理。
[0042]
(2.1)采用adult数据集作为源域数据集:
[0043]
本实施例选择带有敏感特征的数据集作为初始样本集,将其中一个偏见标签b作为偏见特征,例如性别特征。本发明采用adult数据集作为面向迁移学习的去偏方法的目标域数据集。adult数据集是uci数据库中的人口普查数据集,是由barry becker从1994年的人口普查数据库中进行的预测任务是确定一个人的年收入是否超过50k。adult数据集包含48842个人员的样本信息,每个个体的样本属性包括现有年龄、工作类别、教育程度等,样本属性中还包括敏感属性,例如,属性10为性别。adult数据集用14个特征来对每个个体进行描述,从而预测一个人的年收入是否超过50k。
[0044]
(2.2)数据集预处理:
[0045]
adult数据集拥有14个特征属性,为了保证模型可以充分提取数据的特征的同时
减弱除性别外其它敏感特征的影响,对数据的'workclass','education','marital
‑
status','occupation','relationship','race','native
‑
country','sex'属性进行one
‑
hot编码扩充,获取对应的类别标签序列,使得均为二分类。并对其他属性进行保留,以此达到突出目标属性,减弱其它属性对敏感属性的影响的目的,本发明中,将会着重使用one
‑
hot编码扩充之后的数据集,本实例中记作。
[0046]
(3)定义偏见指标函数:
[0047]
本发明中采用偏见指标来评判模型及样本的偏见程度,根据相关领域常用的3个偏见指标函数设计一个新的偏见指标函数f(d),其中以数据集d作为函数的自变量。f(d)具有在不同数据集均有使用价值的优点,克服了现有评价指标对不同数据集具有功能不通用问题的缺陷,即单独使用某一偏见指标针对多个不同数据集的衡量结果可能不具有评判性。现有的常用偏见指标如下:
[0048]
(3.1)disparate impact(差异影响)
[0049]
该定义在从数学上代表不同影响的法理概念。这要求两组的正例预测率之间有较高的比率。这确保了各组中积极预测的比率是相似的。例如,如果一个积极的预测代表收入较高,该条件要求接受的申请人的比率在不同群体中是相近的。其数学计算公式如下:
[0050][0051]
其中s表示受保护的属性(如性别),s=1为特权组,s≠1为非特权组。表示预测为正,注意到,如果代表接受(例如,对一份工作),那么条件要求不同组的接受率是相近的。该指标的值越高,代表不同群体的比率越相似,ε为阈值。
[0052]
(3.2)demographic parity(人口统计平等)
[0053]
人口统计平等的衡量方法类似于差异影响方法,但该方法采用的是差异而不是比率。这种方法通常也被称为统计奇偶性。其数学计算公式如下:
[0054][0055]
该度量值越低,表明接受率越相似。
[0056]
(3.3)equal opportunity(机会平等)
[0057]
机会平等要求真正例率(tprs)在不同组之间是相似的(意味着一个个体有一个积极的结果大概率对应一个积极的预测)。这种方法类似于均等赔率,但只关注真正例率。其数学计算公式如下:
[0058][0059]
当一个预测器满足下式则认为是满足机会均等的:
[0060]
p{h(x
i
)=1|y
i
=1,x
i
∈s}=p{h(x
j
)=1|y
j
=1,x
j
∈x\s}
ꢀꢀꢀ
(4)
[0061]
设x代表一组个体,s代表群组。对于一个个体x
i
∈x,让它成为要预测的真实结果(或标号)。一个预测因子可以用一个映射h:x
→
y从总体x到结果y的集合来表示,这样h(x
i
)就是个体x
i
的预测结果。i和j表示两个个体。
[0062]
(3.4)定义偏见函数f(d)
[0063]
将以上3个偏见指标进行改进融合,合成统计概率偏见函数f(d),具体表达式为:
[0064][0065]
当f(d)越小说明数据的公平性越好,本发明将用f(d)作为衡量数据集偏见程度指标。
[0066]
若用f衡量模型的偏见指标,则将公式中的y改为
[0067][0068]
即用模型的预测值作为分类进行公平性分析。
[0069]
(4)对样本进行偏见程度检测:
[0070]
将扩充后的数据集d的样本特征、敏感属性及其d的标签输入到偏见指标函数内,利用偏见指标函数,根据偏见程度公式对数据集d进行偏见程度分析,对每个偏见指标函数的偏见值进行记录。根据这些偏见值可以得到数据集d的偏见程度。
[0071]
(5)有偏见模型的训练:
[0072]
本实施例中,构建的有深度学习模型包括特征提取器和分类器两部分,其中特征提取器采用3个线性层,激活函数采用relu函数,分类器采用2个全连接层构成的网络。利用原始数据集的训练集训练深度学习模型,并用测试集对深度学习模型进行测试优化,使深度学习模型达到预设的识别准确率。记模型为m。
[0073]
去社会偏见损失loss_m2为:
[0074]
loss_m2=
‑
∑h(x)
·
log(y
n
)+(
‑
∑h(x)
·
log(h(x
′
))
[0075]
其中,h()为收入预测模型,x为特权样本集,x
′
为非特权样本集,y
n
为敏感属性;
[0076]
所述的收入预测损失loss_m1为:
[0077]
loss_m1=
‑
[y
m
·
log(p)+(1
‑
y
m
)
·
log(1
‑
p)]
[0078]
y
m
为类别属性,p为预测结果超过收入阈值的概率。
[0079]
(6)对模型进行偏见程度检测
[0080]
将扩充后的数据集d的测试集输入到模型中,保留模型的偏见值,利用偏见指标函数f(d),对模型进行偏见程度分析,记录函数偏见值,并将偏见值作为模型的偏见程度。
[0081]
(7)生成公平样本,如图2所示,具体步骤如下:
[0082]
本发明以偏见指标函数作为待优化函数,待增强样本作为自变量,利用布谷鸟搜索算法对敏感属性进行更改,根据指标函数生成公平样本,通过多个偏见指标构建偏见指标函数,对偏见指标函数进行训练,将样本集输入至偏见指标函数得到偏见值,采用布谷鸟搜索方法迭代样本集,并将迭代样本集输入至偏见指标函数,直至偏见值满足偏见阈值,或迭代次数满足迭代阈值则停止迭代,得到增强样本集,完成偏见指标函数的训练,获得最终偏见指标函数。
[0083]
布谷鸟搜索(cuckoo search,缩写cs),也叫杜鹃搜索,是由剑桥大学教授和s.戴布于2009年提出的一种新兴启发算法。
[0084]
cs算法是通过模拟某些种属布谷鸟的寄生育雏(brood parasitism),来有效地求
解最优化问题的算法。同时,cs也采用相关的levy飞行搜索机制。研究表明,布谷鸟搜索比其他群体优化算法更有效。以下为布谷鸟搜索的主要公式:
[0085][0086][0087]
其中公式1为搜索过程中模仿萊维飞行进行取值更新,公式2模仿自然界中鸟蛋被发现的情况,利用随机取值法重新更新权重,x
t+1
为输出样本集,x
t
为输入样本集,∈,α为步长缩放因子,levy(β)为莱维随机路径,r为服从均匀分布的随机数,heaviside(
·
)是赫维赛德函数,p
α
为用于平衡局部和全局随机游走的切换参数,x
j
和x
j
为随机选择的样本集。
[0088]
考虑到敏感属性都是bool类型变量,本发明将经典的布谷鸟算法进行了修改,将原本算法中的随机飞行改为了敏感属性的修改,让其在对敏感属性为bool类型的数据集中具有通用性,即敏感属性只有0、1两个取值,因此确定布谷鸟搜索算法的步长为1,方向为正或反,即只能控制敏感属性是否翻转。即满足公式:
[0089][0090][0091]
对原公式进行改进,其中x表示每一个样本敏感属性的取值,[]表示取整,对原结果进行取整后对2取余保证敏感属性的取值为0或1。
[0092]
从训练集中取出待增强样本集合,以偏见指标作为待优化函数,样本集合的敏感属性作为自变量,设置最大迭代次数i
max
,概率pa经过每次根据布谷鸟算法进行迭代后重新使用公平性评价指标f判断其公平性,f越小说明数据集越公平,即当指标f偏见值数值小于最小值则保留当前数据集作为公平数据集d1,并记录当前偏见值作为新的最小值。迭代次数达到i
max
后停止迭代并导出经过增强后的样本d1。
[0093]
(8)对有偏见的模型进行样本增强训练
[0094]
设置最大迭代次数i
max
,利用增强后的样本d1训练有偏见的模型,和原始样本相比增强样本的公平性更强,考虑到数据过拟合、测试集精度降低的问题,在达到限定的最大迭代次数时应该停止训练。
[0095]
(9)检验模型偏见程度
[0096]
将步骤2.2中划分好的测试集输入到模型中,检测模型精确度。利用偏见指标函数f
d
检验模型的偏见程度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1