一种图像处理方法及装置、电子设备和存储介质与流程
1.本公开涉及计算机技术领域,尤其涉及一种图像处理方法及装置、电子设备和存储介质。
背景技术:
2.图形处理器(graphics processing unit,gpu)作为硬件加速器在高性能计算领域得到广泛的应用。特别是近几年,gpu广泛应用在人工智能(ai)领域,特别是深度学习领域。深度学习的训练和推理过程中所要处理的海量数据由gpu来加速处理。
3.图像的特征可以表征为矩阵的形式,矩阵中的每一个值表征图像中相应位置的像素点,通过对矩阵进行矩阵乘累加操作,可以实现对矩阵的卷积。然而,相关技术中,卷积操作的效率有待提高。
技术实现要素:
4.本公开提出了一种图像处理技术方案。
5.根据本公开的一方面,提供了一种图像处理方法,包括:
6.提取目标图像中的图像特征;
7.在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核;
8.利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征;
9.将所述多个子卷积特征进行特征融合处理,得到卷积特征,所述卷积特征用于表征对所述图像特征的提取结果。
10.在一种可能的实现方式中,所述利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,包括:
11.确定各子卷积核在存储空间中的索引位置;
12.根据所述索引位置,读取各子卷积核中的数据,并行地将读取到的各数据与所述图像特征进行卷积处理,得到多个子卷积特征。
13.在一种可能的实现方式中,在所述将卷积核划分为多个子卷积核后,所述方法还包括:
14.根据所述图像特征和各子卷积核确定用于进行矩阵乘运算的第一矩阵和第二矩阵,所述第一矩阵和第二矩阵的通道k维度的尺寸为所述图像特征的通道数乘以所述子卷积核的数量;
15.在所述k维度上,将所述第一矩阵和第二矩阵划分为多个特征块。
16.在一种可能的实现方式中,所述利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,包括:
17.在图形处理器的多个线程块内并行地进行矩阵乘处理,得到第一处理结果,其中,每个所述线程块内进行至少一个矩阵乘处理;
18.所述将所述多个子卷积特征进行特征融合处理,得到卷积特征,包括:
19.在所述图形处理器的共享内存中,将单个所述线程块内的各矩阵乘处理得到的第一处理结果进行特征融合,得到各线程块内的第二处理结果,并将所述第二处理结果写入全局存储空间中;
20.将所述全局存储空间中的各第二处理结果进行特征融合,得到卷积特征。
21.在一种可能的实现方式中,在所述提取目标图像中的图像特征后,所述方法还包括:
22.确定单个线程束warp中能够处理的特征块的多种第一尺寸,并基于所述第一尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第一尺寸的最大值根据寄存器容量确定,所述第一尺寸的最小值为矩阵乘加运算指令计算的最小矩阵单元的尺寸,所述多种第一尺寸的值为所述最小值的倍数。
23.在一种可能的实现方式中,在所述提取目标图像中的图像特征后,所述方法还包括:
24.确定单个线程块tb中能够处理的特征块的多种第二尺寸,并基于所述第二尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第二尺寸的最小值为单个线程束warp能够处理的特征块的第一尺寸,所述第二尺寸为所述第一尺寸的倍数,所述第二尺寸的最大值根据共享内存的容量和tb内线程数上限确定。
25.在一种可能的实现方式中,在所述提取目标图像中的图像特征后,所述方法还包括:
26.确定单个线程块中的特征块在通道k维度上划分的分组的第三尺寸,以及所述分组的数量;
27.基于所述分组的数量确定要进行融合处理的第一处理结果的数量;
28.基于所述第三尺寸和所述第一处理结果的数量生成图形处理器核函数,所述图形处理器核函数还用于对单个线程块中的各分组的各第一处理结果进行融合处理。
29.根据本公开的一方面,提供了一种图像处理装置,包括:
30.提取单元,用于提取目标图像中的图像特征;
31.划分单元,用于在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核;
32.处理单元,用于利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征;
33.融合单元,用于将所述多个子卷积特征进行特征融合处理,得到卷积特征,所述卷积特征用于表征对所述图像特征的提取结果。
34.在一种可能的实现方式中,所述处理单元,用于确定各子卷积核在存储空间中的索引位置;根据所述索引位置,读取各子卷积核中的数据,并行地将读取到的各数据与所述图像特征进行卷积处理,得到多个子卷积特征。
35.在一种可能的实现方式中,所述装置还包括:
36.展开单元,用于根据所述图像特征和各子卷积核确定用于进行矩阵乘运算的第一矩阵和第二矩阵,所述第一矩阵和第二矩阵的通道k维度的尺寸为所述图像特征的通道数乘以所述子卷积核的数量;
37.矩阵划分单元,用于在所述k维度上,将所述第一矩阵和第二矩阵划分为多个特征块。
38.在一种可能的实现方式中,所述处理单元,用于在图形处理器的多个线程块内并行地进行矩阵乘处理,得到第一处理结果,其中,每个所述线程块内进行至少一个矩阵乘处理;
39.所述融合单元,用于在所述图形处理器的共享内存中,将单个所述线程块内的各矩阵乘处理得到的第一处理结果进行特征融合,得到各线程块内的第二处理结果,并将所述第二处理结果写入全局存储空间中;将所述全局存储空间中的各第二处理结果进行特征融合,得到卷积特征。
40.在一种可能的实现方式中,所述装置还包括:
41.第一尺寸确定单元,用于确定单个线程束warp中能够处理的特征块的多种第一尺寸,并基于所述第一尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第一尺寸的最大值根据寄存器容量确定,所述第一尺寸的最小值为矩阵乘加运算指令计算的最小矩阵单元的尺寸,所述多种第一尺寸的值为所述最小值的倍数。
42.在一种可能的实现方式中,所述装置还包括:
43.第二尺寸确定单元,用于确定单个线程块tb中能够处理的特征块的多种第二尺寸,并基于所述第二尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第二尺寸的最小值为单个线程束warp能够处理的特征块的第一尺寸,所述第二尺寸为所述第一尺寸的倍数,所述第二尺寸的最大值根据共享内存的容量和tb内线程数上限确定。
44.在一种可能的实现方式中,所述装置还包括:
45.第三尺寸确定单元,用于确定单个线程块中的特征块在通道k维度上划分的分组的第三尺寸,以及所述分组的数量;基于所述分组的数量确定要进行融合处理的第一处理结果的数量;基于所述第三尺寸和所述第一处理结果的数量生成图形处理器核函数,所述图形处理器核函数还用于对单个线程块中的各分组的各第一处理结果进行融合处理。
46.根据本公开的一方面,提供了一种电子设备,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为调用所述存储器存储的指令,以执行上述方法。
47.根据本公开的一方面,提供了一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述方法。
48.在本公开实施例中,通过在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核,利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,将所述多个子卷积特征进行特征融合处理,得到卷积特征。由此,通过在通道维度上对卷积核进行第一层拆分,在长和宽的维度上进行第二层拆分,通过两层的拆分,能够尽可能多地对卷积核进行切分,多个子卷积核并行地分别对所述图像特征进行卷积处理,该并行过程可以由多个计算单元并行地执行,充分利用gpu中的处理资源,提高了卷积操作的效率。
49.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本公开。根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
附图说明
50.此处的附图被并入说明书中并构成本说明书的一部分,这些附图示出了符合本公开的实施例,并与说明书一起用于说明本公开的技术方案。
51.图1示出根据本公开实施例的特征图尺寸的示意图。
52.图2示出根据本公开实施例的矩阵乘运算的卷积过程的示意图。
53.图3示出根据本公开实施例的图像处理方法的流程图。
54.图4示出根据本公开实施例的图像处理过程的示意图。
55.图5示出根据本公开实施例的一种图像处理装置的框图。
56.图6示出根据本公开实施例的一种电子设备的框图。
57.图7示出根据本公开实施例的一种电子设备的框图。
具体实施方式
58.以下将参考附图详细说明本公开的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
59.在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。
60.本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中术语“至少一种”表示多种中的任意一种或多种中的至少两种的任意组合,例如,包括a、b、c中的至少一种,可以表示包括从a、b和c构成的集合中选择的任意一个或多个元素。
61.另外,为了更好地说明本公开,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本公开同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本公开的主旨。
62.如背景技术所述,相关技术中的卷积操作的效率有待提高,为了提高卷积操作的效率,可以基于张量计算单元(tensor core)进行卷积操作。tensor core是一种矩阵乘累加的计算单元,其在一个周期可以完成多次的乘加操作,可以达到非常高的计算性能。针对a100型号的gpu,tensor core的int8精度的计算性能甚至可以达到624tops。芯片算力的增加主要是为了加速卷积/矩阵乘法一类的高频计算密集型算子,但是也带来了如何高效利用算力的困难,即如何高效地在tensor core上实现卷积算子。
63.典型的卷积神经网络(cnn)由输入层(input)、卷积层(conv)、激活函数(relu)、全连接层(fc)等组成。其中,原始的图像数据经过网络,逐渐抽取出其底层特征,最后形成高级语义特征。
64.卷积操作就是图像的特征图(feature map)与卷积核(filter kernel)进行乘加运算,抽取出图像信息的过程。卷积操作是神经网络中最耗时的运算,深度学习模型的大部分时间开销都在卷积算子上,卷积算子的性能对程序性能有着重要影响。
65.根据特征图(feature map)的尺寸大小,可以将卷积类型分为大图少通道类型和小图多通道类型,如图1所示。其中特征图的三个尺寸“长
×
宽
×
通道”标注于特征图的上方,如224
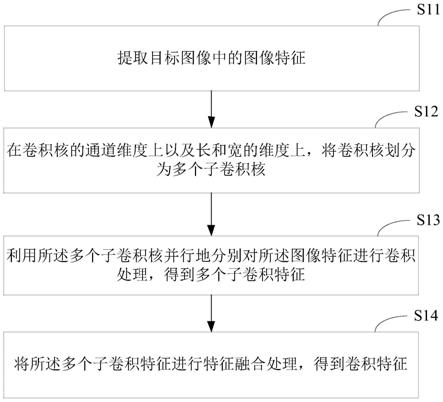
×
224
×
3、56
×
56
×
64等。卷积核尺寸“长
×
宽”标注于卷积核的下方,如7x7、1x1
等。
66.大图少通道类型:这种类型的卷积一般存在于神经网络的开始阶段,它的特点是特征图的长和宽较大(即大图),比如224,但是通道数目比较小(即多通道),比如3。这种卷积类型属于访存密集型运算,tensor core的计算能力对于这种类型得不到充分的发挥。
67.小图多通道类型:这种类型的卷积存在于神经网络的中间和末尾阶段,它的特点是特征图的长和宽较小(即小图),比如56/28/14等,但是通道数目比较大(即多通道),比如64/128/256等。这种卷积类型属于计算密集型运算,很适合发挥tensor core的计算能力。
68.目前tensorcore上采用的卷积算法主要是隐式矩阵乘算法。矩阵乘法的计算形式可以表述为两个尺寸为m
×
k的矩阵a和k
×
n的矩阵b相乘,a中每一行的第k个元素都与b中对应列的第k个元素对应相乘,得到m
×
n的矩阵c的过程。
69.gpu的编程模型往往包含三层:线程网(grid)、线程块(thread block,tb)和线程(thread);其中,线程块是任务分配的基本单元,足够多的线程块能保证gpu的硬件计算单元得到充分的发挥。在本公开实施例中,矩阵乘法利用分块技术,将整个大的矩阵乘任务划分成多个小矩阵的乘法任务,然后将每一块小任务分配给不同的线程块来执行。例如,矩阵乘运算会对矩阵c(m
×
n维度)进行任务划分,每一个线程块计算mtile
×
ntile的小矩阵块,其中,mtile为m维度特征块的尺寸,ntile为n维度特征块的尺寸。例如,当m=n=1024时,在m和n维度可以按照mtile=ntile=128进行分块,这样一共产生(1024/128)x(1024/128)=64个特征块。对于t4型号的gpu来说,至少需要40个线程块才能用上全部的gpu计算单元sm(streaming multiprocessor)。
70.然而,把小图多通道的卷积类型转换成矩阵乘后,矩阵乘的尺寸如图2所示,矩阵a的m维度和矩阵b的n维度尺寸很小,而累加的k维度的尺寸却很大。例如,m=n=256时,m和n维度如果依然使用mtile=ntile=128进行分块,这样只能划分出4个线程块,大部分gpu的sm处于空闲状态,导致卷积操作的效率有待提高。
71.在本公开实施例中,通过在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核,利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,将所述多个子卷积特征进行特征融合处理,得到卷积特征。由此,通过在通道维度上对卷积核进行第一层拆分,在长和宽的维度上进行第二层拆分,通过两层的拆分,能够尽可能多地对卷积核进行切分,多个子卷积核并行地分别对所述图像特征进行卷积处理,该并行过程可以由多个计算单元并行地执行,充分利用gpu中的处理资源,提高了卷积操作的效率。
72.在一种可能的实现方式中,所述图像处理方法可以由终端设备或服务器等电子设备执行,终端设备可以为用户设备(user equipment,ue)、移动设备、用户终端、终端、蜂窝电话、无绳电话、个人数字助理(personal digital assistant,pda)、手持设备、计算设备、车载设备、可穿戴设备等,所述方法可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。
73.为便于描述,本说明书一个或多个实施例中,图像处理方法的执行主体可以是图形处理器(graphics processing unit,gpu),后文以执行主体为图形处理器为例,对该方法的实施方式进行介绍。可以理解,该方法的执行主体为gpu只是一种示例性的说明,并不应理解为对该方法的限定。
74.图3示出根据本公开实施例的图像处理方法的流程图,如图3所示,所述图像处理方法包括:
75.在步骤s11中,提取目标图像中的图像特征。
76.图像在计算机技术中的表达可以是一个个像素值组成的矩阵,那么对图像的分析可以是对表征图像像素值的矩阵进行分析。
77.这里的图像特征可以用来表征图像的像素值,该图像特征可以是图像的像素值组成的矩阵,或者也可以是经多次卷积操作后得到的图像特征,本公开对此不做限定。
78.在步骤s12中,在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核。
79.卷积核的具体表现形式可以是一个矩阵,该矩阵中的元素为卷积时的权重,通过该权重,可以通过卷积操作提取想要的图像特征,抑制其它图像特征。
80.这里对卷积核的划分,具体可以是将卷积核的每一个权重划分为一个子卷积核,或者也可以将不止一个权重划分为一个子卷积核,本公开对子卷积核的划分尺寸不做限定。
81.对卷积核的拆分可以从两个层面进行拆分,第一层拆分是在通道维度上对卷积核进行拆分,而第二层拆分是在长和宽的维度上进行拆分,通过两层的拆分,能够尽可能多地对卷积核进行切分。
82.在步骤s13中,利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征。
83.利用子卷积核进行卷积处理的过程,即对图像特征进行卷积处理的过程,具体过程此处不做赘述。
84.在步骤s14中,将所述多个子卷积特征进行特征融合处理,得到卷积特征,所述卷积特征用于表征对所述图像特征的提取结果。
85.由于多个子卷积核分别对图像特征进行的卷积处理,得到的多个子卷积特征是分开的,因此,可以通过特征融合处理将多个子卷积特征融合在一起。该特征融合处理的过程可以是将多个子卷积特征进行累加,或者可以是对各子卷积特征乘以一定的权重后进行累加,对于具体进行特征融合的过程,此处不做赘述。
86.那么,针对矩阵乘卷积方式而言,对于小图多通道的卷积类型,虽然矩阵a的m维度和矩阵b的n维度尺寸很小,且累加的k维度的尺寸却很大。然而,由于将卷积核划分为了多个子卷积核,可以在卷积核的维度上进一步分块,来提高并行执行的效率。
87.例如,当对3
×
3的卷积核、通道为1024的图像特征进行卷积操作时,第一层对通道划分为8份,那么通道维度的特征块尺寸为1024/8=256;第二层对3x3卷积核划分为9份,那么子卷积核的尺寸为3
×
3/9=1;这两层划分后的可以产生的特征块的数量为8x9=72份。72份特征块并行进行运算,充分利用gpu中的处理资源,提高了卷积效率。
88.在本公开实施例中,通过在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核,利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,将所述多个子卷积特征进行特征融合处理,得到卷积特征。由此,通过在通道维度上对卷积核进行第一层拆分,在长和宽的维度上进行第二层拆分,通过两层的拆分,能够尽可能多地对卷积核进行切分,多个子卷积核并行地分别对所述图像特征进
行卷积处理,该并行过程可以由多个计算单元并行地执行,充分利用gpu中的处理资源,提高了卷积操作的效率。
89.在一种可能的实现方式中,所述利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,包括:确定各子卷积核在存储空间中的索引位置;根据所述索引位置,读取各子卷积核中的数据,并行地将读取到的各数据与所述图像特征进行卷积处理,得到多个子卷积特征。
90.数据在存储空间中存储时会有一个索引值,用来表征数据在存储空间中的存储位置,在本实现方式中,会预先记录子卷积核的索引值,该索引值具体可是卷积核在存储空间中的起始值和终止值。然后直接依据索引值来读取存储空间中的值来跟图像特征进行卷积计算,而无需将卷积核展开为矩阵再进行卷积计算,能够节省内存资源。
91.在一种可能的实现方式中,在所述将卷积核划分为多个子卷积核后,所述方法还包括:根据所述图像特征和各子卷积核确定用于进行矩阵乘运算的第一矩阵和第二矩阵,所述第一矩阵和第二矩阵的通道k维度的尺寸为所述图像特征的通道数乘以所述子卷积核的数量;在所述k维度上,将所述第一矩阵和第二矩阵划分为多个特征块。
92.如前文所述,矩阵乘法的计算形式可以表述为两个尺寸为m
×
k的矩阵a和k
×
n的矩阵b相乘,a中每一行的第k个元素都与b中对应列的第k个元素对应相乘,得到m
×
n的矩阵c的过程。
93.在显示的矩阵乘卷积中,可以先利用卷积核将m
×
n的矩阵转化为两个m
×
k的矩阵a和k
×
n的矩阵b,具体可以通过im2col算法来实现,此次不做赘述。而针对一个卷积核而言,在一个子卷积核为卷积核中的一个值的情况下,可以利用每一个子卷积核分别将m
×
n的矩阵(表征图像特征)转换为矩阵a和矩阵b,然后得到的这多个矩阵a可以在k维度上累加作为第一矩阵,得到的这多个矩阵b可以在k维度上累加作为第二矩阵。那么,显然,第一矩阵和第二矩阵的通道k维度的尺寸为所述图像特征的通道数乘以所述子卷积核的数量。
94.例如,卷积核的尺寸为3
×
3,每个子卷积核的尺寸为1,那么便有9个子卷积核,在图像特征的矩阵的通道数为1024的情况下,第一矩阵和第二矩阵k维度总的尺寸即为9
×
1024=9216。
95.然后,在k维度上,将第一矩阵和第二矩阵划分为多个特征块,当然,也还可以在矩阵的行列(m和n)维度进行划分,此次不做赘述。具体划分特征块尺寸的实现方式,可参见本公开提供的多种可能的实现方式,此次不做赘述。
96.在本公开实施例中,基于划分的子卷积核,将第一矩阵和第二矩阵在k维度上的尺寸实现了倍增,那么,在所述k维度上,将所述第一矩阵和第二矩阵划分为多个特征块时,可以划分得到更多的特征块,由此,可以并行地分别对各所述特征块进行矩阵乘运算,得到多个子卷积特征,由于特征块的数量增多,因此,在进行卷积操作时可并行处理的特征块也进一步增多,进一步提高了卷积计算的效率。
97.在一种可能的实现方式中,所述利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征,包括:在图形处理器的多个线程块内并行地进行矩阵乘处理,得到第一处理结果,其中,每个所述线程块内进行至少一个矩阵乘处理;所述将所述多个子卷积特征进行特征融合处理,得到卷积特征,包括:在所述图形处理器的共享内存中,将单个所述线程块内的各矩阵乘处理得到的第一处理结果进行特征融合,得到各线
程块内的第二处理结果,并将所述第二处理结果写入全局存储空间中;将所述全局存储空间中的各第二处理结果进行特征融合,得到卷积特征。
98.在图形处理器中,线程块tb加载在计算单元sm上运行,线程块tb可以并行地执行运算操作,因此,可以由图形处理器的多个tb并行地进行运算操作,每个线程块内进行至少一个运算操作,这样tb中即可得到多个第一处理结果。
99.单个tb中的特征块在通道k维度上进一步可以划分为一组或多组,即每一个tb中可以对一组或多组特征块进行计算,tb中计算的特征块的组数是2的指数幂,例如可以是1、2、4等等。那么tb对一组或多组特征块进行计算后,会得到一组或多组第一处理结果,第一处理结果会位于共享内存(shared memory,smem)中,然后通过smem将同一tb中的第一处理结果进行特征融合,得到各tb内的第二处理结果。
100.虽然共享内存的大小有限,但是其具备较高的读写速度和带宽,因此,考虑到对单个tb内的第一处理结果进行特征融合所需的运算量并不大,因此,通过smem对tb内部的第一运算结果进行特征融合,能够提高对第一运算结果进行融合的效率。
101.在将第一处理结果融合为第二处理结果后,第二处理结果的数量往往较多,因此,可以通过开辟额外的全局存储空间(global memory,即gmem)进行特征融合,如图4所示,多个第二处理结果(s1‑
s
n
)在gmem上进行特征融合,最终得到卷积特征s。在gmem上对第二处理结果进行特征融合,由于gmem的存储空间较大,因此其输出效率不会随着特征块数量的增大而降低,能够保证对第二处理结果的输出效率。
102.在本公开实施例中,在图形处理器的多个线程块内并行地进行卷积处理,在进行特征融合时,可以先在图形处理器的共享内存中,将单个所述线程块内的各矩阵乘处理得到的第一处理结果进行特征融合,得到各线程块内的第二处理结果,并将所述第二处理结果写入全局存储空间中;然后将全局存储空间中的各第二处理结果进行特征融合,得到卷积特征。由此,由于共享内存具备较高的读写速度和带宽,因此通过共享内存对tb内部的第一运算结果进行特征融合,能够提高对第一运算结果进行融合的效率。其次,由于全局存储空间的存储空间较大,因此,通过全局存储空间对线程块之间的第二处理结果进行特征融合,其计算效率不会随着特征块数量的增大而降低,能够保证对第二处理结果的输出效率。从而进一步地提高了卷积任务的并行性,更好地利用了gpu的硬件资源。
103.在图形处理器中,通过图形处理器核函数kernel来进行特征尺寸切分和卷积核尺寸切分,而由于特征图的尺寸众多,因此,特征块划分尺寸固定的kernel并不能适用于全部的卷积尺寸类型上,在本公开实施例中,尽可能地遍历每一种可能的特征块尺寸来生成卷积kernel,一个卷积kernel对应一种特征块尺寸,由此,可以基于图像特征的尺寸,选择合适的kernel来进行分块,得到多个特征库。
104.在本公开实施例中,可以确定tb,线程束warp及k维度的多种可能的特征块尺寸,最终生成对应的多种kernel,方便后期根据图像特征的尺寸来选择合适的kernel。下面对三个维度分别进行详细的说明。
105.在一种可能的实现方式中,在所述提取目标图像中的图像特征后,所述方法还包括:确定单个线程束warp中能够处理的特征块的多种第一尺寸,并基于所述第一尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第一尺寸的最大值根据寄存器容量确定,所述第一尺寸的最小值为矩阵乘加运算指令计算的最小矩阵单元的尺寸,所述多种
第一尺寸的值为所述最小值的倍数。
106.在gpu中,会通过下发的矩阵乘加运算(matrix multiply and accumulate,mma)指令来进行卷积运算,示例性的,一个mma指令所处理的最小矩阵单元在m
×
n维度是16
×
8,在k维度是8。
107.在单个warp中,其能够处理的最小矩阵单元的尺寸即为mma指令能够处理的最小矩阵单元的尺寸,而由于指令的运算是以2的指数幂的形式累加,因此单个warp所能够处理的特征块的尺寸即为最小矩阵单元的尺寸再乘以2的指数幂,n可以为8、16、32、64,m可以为16、32、64、128,那么得到的m
×
n的值具体如表1所示。
108.而考虑到寄存器容量的限制,特征块的尺寸也不能无限的增大,其最大值可以根据寄存器容量来确定,由于寄存器容量的限制,寄存器中无法存储128x64的warp特征块,因此,特征块的第一尺寸的最大值为128
×
32或64
×
64,具体如表1所示。
109.m\n81632641616x816x1616x3216x643232x832x1632x3232x646464x864x1664x3264x64128128x8128x16128x32\
110.表1 warp级的特征块尺寸
111.在本公开实施例中,可以在warp维度将所有的特征块的第一尺寸进行遍历,进而基于第一尺寸生成图形处理器核函数kernel,这样得到的kernel可以适用于对各种尺寸的图像特征进行切分,得到的kernel的普适性较高。
112.在一种可能的实现方式中,在所述提取目标图像中的图像特征后,所述方法还包括:确定单个线程块tb中能够处理的特征块的多种第二尺寸,并基于所述第二尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第二尺寸的最小值为单个线程束warp能够处理的特征块的第一尺寸,所述第二尺寸为所述第一尺寸的倍数,所述第二尺寸的最大值根据共享内存的容量和tb内线程数上限确定。
113.一个tb中会包含一个或多个warp,那么,第二尺寸的最小值即为单个线程束warp能够处理的特征块的第一尺寸,第二尺寸也可以是第一尺寸的倍数,该倍数为2的指数幂,即2、4。表3中的m
tb
和n
tb
的具体值为第一尺寸的倍数。
114.在一些gpu中,一个tb往往最多可以有1024个线程,即16个warp,然而,在gpu中,线程数量为128
‑
512个时运算效率较高,因此,往往不会运行16个warp,因此,为了保证gpu运算效率,一个tb中最多运行8个warp,即m
tb
×
n
tb
的最大值为2
×
4或者4
×
2,如
115.表2所示。
116.m
tb
\n
tb
12411x11x21x422x12x22x444x14x2\
117.表2 tb级的特征块尺寸。表中的数字表示相应warp级特征块尺寸的倍数
118.在本公开实施例中,可以在tb维度将所有的特征块的第二尺寸进行遍历,进而基于第二尺寸生成图形处理器核函数kernel,这样得到的kernel可以适用于对各种尺寸的图
像特征进行切分,得到的kernel的普适性较高。
119.在一种可能的实现方式中,在所述提取目标图像中的图像特征后,所述方法还包括:确定单个线程块中的特征块在通道k维度上划分的分组的第三尺寸,以及所述分组的数量;基于所述分组的数量确定要进行融合处理的第一处理结果的数量;基于所述第三尺寸和所述第一处理结果的数量生成图形处理器核函数,所述图形处理器核函数还用于对单个线程块中的各分组的各第一处理结果进行融合处理。
120.如前文所述,在单个warp中,其能够处理的最小矩阵单元的尺寸即为mma指令能够处理的最小矩阵单元的尺寸,示例性的,一个mma指令所处理的最小矩阵单元在m
×
n维度是16
×
8,在k维度是8。那么,单个tb中多种可能的k维度的尺寸包括k8、k16、k32、k64等。而tb是由多个warp组成的,把这些warp分成多个分组s,不同的组会在k维度的尺寸上进一步切分,切分的尺寸可以是s8、s16、s32等。
121.例如,1个tb中有8个warp,在tb内在k维度上的尺寸为k128,如果把这8个warp分成2组(每组4个warp),那么,单个组处理的特征块在k维度尺寸即为s64。
122.单个tb中分组的数量即为k维度特征块的尺寸除以单个组的k维度尺寸,例如,针对表3中的第二行1
×
,其分组数为1;第二行2
×
,其分组数为2;第三行4
×
,其分组数为4。以k32_s16为例,s16表示分组的尺寸为16,k32表示特征块k维度的尺寸是32,因此,分组数即为2。
123.k/s816321
×
k8_s8k16_s16k32_s322
×
k16_s8k32_s16k64_s324
×
k32_s8k64_s16k128_s32
124.表3 k维度的特征块尺寸及分组尺寸。
125.由于一个分组会对应一个第一处理结果,因此,分组的数量即可作为第一处理结果的数量,然后基于第一处理结果的数量和第三尺寸即可生成图形处理核函数。
126.在本公开实施例中,可以在特征块的k维度上对分组的第三尺寸进行遍历,进而基于第三尺寸和特征块的尺寸,确定要进行融合处理的第一处理结果的多种数量,基于第三尺寸和第一处理结果的数量生成图形处理器核函数kernel,这样得到的kernel可以适用于对各种尺寸的分组的第一结果进行融合处理,得到的kernel的普适性较高。
127.请参阅图4,为本公开实施例的图像处理方法的一个应用场景示意图,在该应用场景中,包含多个gpu计算单元:sm1、sm2
……
smn,每一个sm中的tb内对1个特征块进行矩阵乘运算,1个特征块分为2组进行并行处理,分组后得到的第一处理结果在图4中依次标识为s1_0,s1_1,s2_0,s2_1,
……
sn_0,sn_1,第一处理结果位于smem上,在smem上进行tb内规约(特征融合处理),得到第二处理结果,第二处理结果在图4中依次标识为s1,s2,
……
sn。得到的第二处理结果会写入gmem中,然后在gmem上进行tb间规约(特征融合处理)处理,得到卷积结果s。
128.可以理解,本公开提及的上述各个方法实施例,在不违背原理逻辑的情况下,均可以彼此相互结合形成结合后的实施例,限于篇幅,本公开不再赘述。本领域技术人员可以理解,在具体实施方式的上述方法中,各步骤的具体执行顺序应当以其功能和可能的内在逻辑确定。
129.此外,本公开还提供了图像处理装置、电子设备、计算机可读存储介质、程序,上述均可用来实现本公开提供的任一种图像处理方法,相应技术方案和描述和参见方法部分的相应记载,不再赘述。
130.图5示出根据本公开实施例的图像处理装置的框图,如图5所示,所述装置50包括:
131.提取单元51,用于提取目标图像中的图像特征;
132.划分单元52,用于在卷积核的通道维度上以及长和宽的维度上,将卷积核划分为多个子卷积核;
133.处理单元53,用于利用所述多个子卷积核并行地分别对所述图像特征进行卷积处理,得到多个子卷积特征;
134.融合单元54,用于将所述多个子卷积特征进行特征融合处理,得到卷积特征,所述卷积特征用于表征对所述图像特征的提取结果。
135.在一种可能的实现方式中,所述处理单元,用于确定各子卷积核在存储空间中的索引位置;根据所述索引位置,读取各子卷积核中的数据,并行地将读取到的各数据与所述图像特征进行卷积处理,得到多个子卷积特征。
136.在一种可能的实现方式中,所述装置还包括:
137.展开单元,用于根据所述图像特征和各子卷积核确定用于进行矩阵乘运算的第一矩阵和第二矩阵,所述第一矩阵和第二矩阵的通道k维度的尺寸为所述图像特征的通道数乘以所述子卷积核的数量;
138.矩阵划分单元,用于在所述k维度上,将所述第一矩阵和第二矩阵划分为多个特征块。
139.在一种可能的实现方式中,所述处理单元,用于在图形处理器的多个线程块内并行地进行矩阵乘处理,得到第一处理结果,其中,每个所述线程块内进行至少一个矩阵乘处理;
140.所述融合单元,用于在所述图形处理器的共享内存中,将单个所述线程块内的各矩阵乘处理得到的第一处理结果进行特征融合,得到各线程块内的第二处理结果,并将所述第二处理结果写入全局存储空间中;将所述全局存储空间中的各第二处理结果进行特征融合,得到卷积特征。
141.在一种可能的实现方式中,所述装置还包括:
142.第一尺寸确定单元,用于确定单个线程束warp中能够处理的特征块的多种第一尺寸,并基于所述第一尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第一尺寸的最大值根据寄存器容量确定,所述第一尺寸的最小值为矩阵乘加运算指令计算的最小矩阵单元的尺寸,所述多种第一尺寸的值为所述最小值的倍数。
143.在一种可能的实现方式中,所述装置还包括:
144.第二尺寸确定单元,用于确定单个线程块tb中能够处理的特征块的多种第二尺寸,并基于所述第二尺寸生成用于进行特征块划分的图形处理器核函数;其中,所述第二尺寸的最小值为单个线程束warp能够处理的特征块的第一尺寸,所述第二尺寸为所述第一尺寸的倍数,所述第二尺寸的最大值根据共享内存的容量和tb内线程数上限确定。
145.在一种可能的实现方式中,所述装置还包括:
146.第三尺寸确定单元,用于确定单个线程块中的特征块在通道k维度上划分的分组
的第三尺寸,以及所述分组的数量;基于所述分组的数量确定要进行融合处理的第一处理结果的数量;基于所述第三尺寸和所述第一处理结果的数量生成图形处理器核函数,所述图形处理器核函数还用于对单个线程块中的各分组的各第一处理结果进行融合处理。
147.在一些实施例中,本公开实施例提供的装置具有的功能或包含的模块可以用于执行上文方法实施例描述的方法,其具体实现可以参照上文方法实施例的描述,为了简洁,这里不再赘述。
148.本公开实施例还提出一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述方法。计算机可读存储介质可以是易失性或非易失性计算机可读存储介质。
149.本公开实施例还提出一种电子设备,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为调用所述存储器存储的指令,以执行上述方法。
150.本公开实施例还提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当所述计算机可读代码在电子设备的处理器中运行时,所述电子设备中的处理器执行上述方法。
151.电子设备可以被提供为终端、服务器或其它形态的设备。
152.图6示出根据本公开实施例的一种电子设备800的框图。例如,电子设备800可以是移动电话,计算机,数字广播终端,消息收发设备,游戏控制台,平板设备,医疗设备,健身设备,个人数字助理等终端。
153.参照图6,电子设备800可以包括以下一个或多个组件:处理组件802,存储器804,电源组件806,多媒体组件808,音频组件810,输入/输出(i/o)的接口812,传感器组件814,以及通信组件816。
154.处理组件802通常控制电子设备800的整体操作,诸如与显示,电话呼叫,数据通信,相机操作和记录操作相关联的操作。处理组件802可以包括一个或多个处理器820来执行指令,以完成上述的方法的全部或部分步骤。此外,处理组件802可以包括一个或多个模块,便于处理组件802和其他组件之间的交互。例如,处理组件802可以包括多媒体模块,以方便多媒体组件808和处理组件802之间的交互。
155.存储器804被配置为存储各种类型的数据以支持在电子设备800的操作。这些数据的示例包括用于在电子设备800上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。存储器804可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(sram),电可擦除可编程只读存储器(eeprom),可擦除可编程只读存储器(eprom),可编程只读存储器(prom),只读存储器(rom),磁存储器,快闪存储器,磁盘或光盘。
156.电源组件806为电子设备800的各种组件提供电力。电源组件806可以包括电源管理系统,一个或多个电源,及其他与为电子设备800生成、管理和分配电力相关联的组件。
157.多媒体组件808包括在所述电子设备800和用户之间的提供一个输出接口的屏幕。在一些实施例中,屏幕可以包括液晶显示器(lcd)和触摸面板(tp)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。在一些实施例中,
多媒体组件808包括一个前置摄像头和/或后置摄像头。当电子设备800处于操作模式,如拍摄模式或视频模式时,前置摄像头和/或后置摄像头可以接收外部的多媒体数据。每个前置摄像头和后置摄像头可以是一个固定的光学透镜系统或具有焦距和光学变焦能力。
158.音频组件810被配置为输出和/或输入音频信号。例如,音频组件810包括一个麦克风(mic),当电子设备800处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器804或经由通信组件816发送。在一些实施例中,音频组件810还包括一个扬声器,用于输出音频信号。
159.i/o接口812为处理组件802和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。
160.传感器组件814包括一个或多个传感器,用于为电子设备800提供各个方面的状态评估。例如,传感器组件814可以检测到电子设备800的打开/关闭状态,组件的相对定位,例如所述组件为电子设备800的显示器和小键盘,传感器组件814还可以检测电子设备800或电子设备800一个组件的位置改变,用户与电子设备800接触的存在或不存在,电子设备800方位或加速/减速和电子设备800的温度变化。传感器组件814可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物体的存在。传感器组件814还可以包括光传感器,如互补金属氧化物半导体(cmos)或电荷耦合装置(ccd)图像传感器,用于在成像应用中使用。在一些实施例中,该传感器组件814还可以包括加速度传感器,陀螺仪传感器,磁传感器,压力传感器或温度传感器。
161.通信组件816被配置为便于电子设备800和其他设备之间有线或无线方式的通信。电子设备800可以接入基于通信标准的无线网络,如无线网络(wifi),第二代移动通信技术(2g)或第三代移动通信技术(3g),或它们的组合。在一个示例性实施例中,通信组件816经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件816还包括近场通信(nfc)模块,以促进短程通信。例如,在nfc模块可基于射频识别(rfid)技术,红外数据协会(irda)技术,超宽带(uwb)技术,蓝牙(bt)技术和其他技术来实现。
162.在示例性实施例中,电子设备800可以被一个或多个应用专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑器件(pld)、现场可编程门阵列(fpga)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述方法。
163.在示例性实施例中,还提供了一种非易失性计算机可读存储介质,例如包括计算机程序指令的存储器804,上述计算机程序指令可由电子设备800的处理器820执行以完成上述方法。
164.图7示出根据本公开实施例的一种电子设备1900的框图。例如,电子设备1900可以被提供为一服务器。参照图7,电子设备1900包括处理组件1922,其进一步包括一个或多个处理器,以及由存储器1932所代表的存储器资源,用于存储可由处理组件1922的执行的指令,例如应用程序。存储器1932中存储的应用程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理组件1922被配置为执行指令,以执行上述方法。
165.电子设备1900还可以包括一个电源组件1926被配置为执行电子设备1900的电源管理,一个有线或无线网络接口1950被配置为将电子设备1900连接到网络,和一个输入输
出(i/o)接口1958。电子设备1900可以操作基于存储在存储器1932的操作系统,例如微软服务器操作系统(windows server
tm
),苹果公司推出的基于图形用户界面操作系统(mac os x
tm
),多用户多进程的计算机操作系统(unix
tm
),自由和开放原代码的类unix操作系统(linux
tm
),开放原代码的类unix操作系统(freebsd
tm
)或类似。
166.在示例性实施例中,还提供了一种非易失性计算机可读存储介质,例如包括计算机程序指令的存储器1932,上述计算机程序指令可由电子设备1900的处理组件1922执行以完成上述方法。
167.本公开可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本公开的各个方面的计算机可读程序指令。
168.计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是(但不限于)电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd
‑
rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其他自由传播的电磁波、通过波导或其他传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。
169.这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。
170.用于执行本公开操作的计算机程序指令可以是汇编指令、指令集架构(isa)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括面向对象的编程语言—诸如smalltalk、c++等,以及常规的过程式编程语言—诸如“c”语言或类似的编程语言。计算机可读程序指令可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络—包括局域网(lan)或广域网(wan)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。在一些实施例中,通过利用计算机可读程序指令的状态信息来个性化定制电子电路,例如可编程逻辑电路、现场可编程门阵列(fpga)或可编程逻辑阵列(pla),该电子电路可以执行计算机可读程序指令,从而实现本公开的各个方面。
171.这里参照根据本公开实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本公开的各个方面。应当理解,流程图和/或框图的每个方框以及流程图和/
或框图中各方框的组合,都可以由计算机可读程序指令实现。
172.这些计算机可读程序指令可以提供给通用计算机、专用计算机或其它可编程数据处理装置的处理器,从而生产出一种机器,使得这些指令在通过计算机或其它可编程数据处理装置的处理器执行时,产生了实现流程图和/或框图中的一个或多个方框中规定的功能/动作的装置。也可以把这些计算机可读程序指令存储在计算机可读存储介质中,这些指令使得计算机、可编程数据处理装置和/或其他设备以特定方式工作,从而,存储有指令的计算机可读介质则包括一个制造品,其包括实现流程图和/或框图中的一个或多个方框中规定的功能/动作的各个方面的指令。
173.也可以把计算机可读程序指令加载到计算机、其它可编程数据处理装置、或其它设备上,使得在计算机、其它可编程数据处理装置或其它设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机、其它可编程数据处理装置、或其它设备上执行的指令实现流程图和/或框图中的一个或多个方框中规定的功能/动作。
174.附图中的流程图和框图显示了根据本公开的多个实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,所述模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
175.该计算机程序产品可以具体通过硬件、软件或其结合的方式实现。在一个可选实施例中,所述计算机程序产品具体体现为计算机存储介质,在另一个可选实施例中,计算机程序产品具体体现为软件产品,例如软件开发包(software development kit,sdk)等等。
176.以上已经描述了本公开的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1