基于多关键字覆盖的路网Top-k路径查询方法
基于多关键字覆盖的路网top
‑
k路径查询方法
技术领域
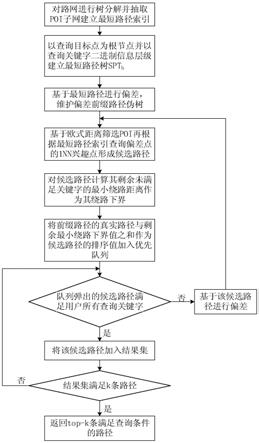
1.本发明属于多模式交通下k近邻查询处理技术领域,具体涉及一种路 网中多关键字覆盖的top
‑
k路径查询方法,基于收缩的poi子路网和快速 最短路径查询的层次标签索引(hierarchical 2
‑
hop,h2h),构建具有查询 关键字二进制信息的部分最短路径树(partial shortest path tree withbinary keywords,spt
b
),并且利用路径偏差技术以及启发式最小绕路距离 下界的方法来实现路网中多关键字覆盖的top
‑
k路径查询方法。
背景技术:
2.随着社会的发展,科技的进步,全球定位系统(global positioningsystem,gps)变得越来越受欢迎,受益于地图服务和移动终端的普及和发 展,游客在规划旅游路线时不仅将路径长度作为考量,同时会综合考虑其他 方面的因素。其中,路径长度、路径开销和路径所覆盖兴趣点是游客普遍 关注的三个最优路径选择因素。现有的方法要不是只能够求得单条近似路 径或者指定关键字访问序列的k条路径,又或者是路径代价极高的近似解 路径,还有的方法只适合单个关键字poi的路网,所以这些方法并不适用。 为了既要保证路径代价低且查询效率高的top
‑
k条多关键字覆盖路径,仍 需要进一步优化查询方法。
技术实现要素:
3.为了解决无向路网中满足用户多关键字访问请求的多条路径规划查询 问题,本发明提出了基于多关键字覆盖的路网top
‑
k路径查询方法;
4.包括以下步骤:
5.s1:基于关键字信息对无向路网的多个节点进行树分解得到poi子图, 所述poi子图上所有节点均含有关键字信息,且节点之间距离与原始路网 一致;建立poi子图上两点之间最短路径索引h2h,采用dijkstra算法建 立以查询目标点为根节点的带有关键字信息的最短路径树spt
b
;
6.s2:基于上述最短路径树,以起点至目标查询点最短路径为基本路径 进行偏差,维护当前偏差路径的全部前缀路径,采用偏差方法计算以每一 个前缀路径结尾节点为偏差点的最近邻1nn poi,基于该最近邻1nn poi建 立其与目标查询点之间剩余最短路径,前缀路径链接至剩余最短路径形成 候选路径,存储该候选路径上所有节点的关键字信息;
7.s3:基于候选路径计算其满足剩余每一类关键字的最小绕路距离下界 值,所述下界值为选取每一类关键字绕路距离最小值组成poi候选集合, 选取该候选集中最大值作为剩余路径的最小绕路距离;前缀路径链接至最 近邻1nn poi路径的路网距离与该最小绕路距离之和作为完整候选路径加 入最小优先队列中排序,不断筛出同时满足查询关键字及最短距离两个参 数指标的最佳路径。
8.本发明采用路径偏差法并利用启发式绕路下界扩展,主要分为三部分, 预计算、find1nn和complb;以最短路径为基准进行不断地偏差找到局部 最优的poi,并对剩下未满足的每个关键字求其最小绕路距离,选其最大的 候选值作为最小绕路下界,同时在偏差的
过程中利用剪枝策略并且不断对 路径进行距离修正,找到top
‑
k条满足用户指定关键字集合的路径则结束 查询。该偏差扩展的关键字覆盖最优路径规划算法能为用户提供k条(poi 序列不同)出行代价最优的路径规划方案。
附图说明
9.为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说 明。
10.图1为本发明提供的路网中多关键字覆盖的top
‑
k路径查询方法的流 程图;
11.图2为实施例中的含有关键字信息无向路网poi子网;
12.图3为实施例中求剩余路径未满足关键字的启发式最小绕路下界三角 形绕路准则;
13.图4为候选路径组成示意图;
具体实施方式
14.为了使本发明的目的、技术方案及优点更加的清楚明白,以下结合附图 及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体 实施例仅以解释本发明,并不限定本发明。
15.路由查找问题的关键是找到从起始位置到目的地的top
‑
k条最短路径, 或者根据某些标准找到最合适的路径。其中一个热门的话题是兴趣点 (points of interests,pois)的路径规划,就是给定一个出发点和目的 地,还有一组需要被满足的关键词,规划出一条能覆盖所有查询关键词的 路线,使得总距离花费代价最小。在以往的相关研究中,认为poi仅包含 一种关键词;然而,在现实生活中一个poi可能会提供多种关键词来标明 其包含多种服务,例如大型购物中心,可能同时提供超市,餐厅,自动取 款机等关键词服务。考虑到这一特性的路径规划称为多关键词覆盖的路径 查询(multi
‑
keywords
‑
cover optimal route query,mor),这是针对pois 提供的服务类别提出的一类问题。
16.现有的多关键字覆盖的top
‑
k路径查询方法有ksp(无环k条最短路径)、 kosr(k条指定多关键字序列最短路径)、ig
‑
tree(具有关键字文件信息的g 树索引框架近似路径查询)和在poi子网中的mrrp(多关键字请求的近似路 径查询),但是在实际应用中,路网上具有关键字信息的地理坐标点是占比 不大的,故可以利用图收缩的方法通过树分解结构抽取poi子网避免掉不 访问的非poi点来保证子网与原始路网在相同点对的最短路径距离上具有 一致性本发明提供的一种路网中多关键字覆盖的top
‑
k路径查询方法,利 用基于收缩的poi子路网和快速最短路径查询的层次标签索引 (hierarchical 2
‑
hop,h2h),构建具有查询关键字二进制信息的部分最短 路径树(partial shortest path tree with binary keywords,spt
b
),并且 利用路径偏差技术以及启发式最小绕路距离下界的方法来实现路网中多关 键字覆盖的top
‑
k路径查询方法。参考图1,该方法包括如下步骤:
17.s1:基于关键字信息对无向路网的多个节点进行树分解得到poi子图, 所述poi子图上所有节点均含有关键字信息,且节点之间距离与原始路网 一致;建立poi子图上两点之间最短路径索引h2h,采用dijkstra算法建 立以查询目标点为根节点的带有关键字信息的最短路径树spt
b
;
18.s 101:基于节点度数从小到大的顺序将无向路网树分解,将无向路网 上不含查
询关键字的非poi节点先分解掉,包括删减或者增添对应边;当 删除该非poi点使得无向路网中两节点距离增大,则删除该点增添两节点 之间连边,增添后的连边与剩余未分解的poi节点和边形成poi子图,建 立poi子图的最短路径索引;
19.s 102:根据查询条件,以查询目标点为根节点,每个节点存储其到根 节点最短路径上的查询关键字二进制的或运算结果,利用dijkstra算法自 顶向下建立部分最短路径树,若在扩展的过程中包含查询关键字的所有节 点均被访问过,则提前结束算法并存贮最短路径树。
20.s2:基于上述最短路径树,以起点至目标查询点最短路径为基本路径 进行偏差,维护当前偏差路径的全部前缀路径,计算以每一个前缀路径结 尾节点为偏差点的最近邻1nn poi,基于该最近邻1nn poi建立其与目标查 询点之间剩余最短路径,前缀路径链接至剩余最短路径形成候选路径,存 储该候选路径上所有节点的关键字信息;
21.s201:在读取节点关键字信息时建立关键字倒排索引,记录每种关键字 能被提供的poi;
22.s202:以起点至目标查询点最短路径为基线进行偏差,维护所有前缀路 径,并标记前缀路径的最后一个节点为偏差点;
23.s203:基于步骤s201关键字倒排文件索引得到只包含查询关键字的全 部poi,计算偏差点到每个poi的欧式距离,从小到大排列筛选前20%的poi 作为候选poi,利用h2h索引计算候选poi到偏差点的真实路网距离,返回 距离偏差点的最近邻1nn poi,偏差点至1nn poi段为偏差路径,前缀路径
ꢀ‑
1nn poi偏差路径
‑
1nn poi至目标点剩余最短路径三段形成候选路径,并 记录该候选路径所包含的查询关键字信息。
24.由于在连续的偏差过程中,存在对无效节点的相同偏差,为了减少无 效偏差带来的候选路径过多问题。在不断的偏差过程中,如果前后偏差得 到的1nn poi是同一个结点且两者所包含的查询关键字相同,则根据 domination关系,剪枝掉具有相同poi序列的偏差路径。即,在连续的偏 差过程中,若两条前缀路径p1和p2,它们的1nn poi结果相同,其偏差路 径分别是d1和d2,经过偏差后(前缀路径+偏差路径)两者所包含的关键 字种类是一致的。此时,存在disr(p1+d1)小于dist(p2+d2),则有支配关 系:路径(p1+d1)支配了路径(p2+d2),后者被剪枝掉。通过支配关系剪枝 能够减少无效偏差带来的多余候选路径数量并且进一步缩小搜索解空间, 提高算法查询效率
25.为了避免了路网扩展搜索空间过大以及过大成本的候选路径,利用最 短路径偏差过程计算最近邻poi生成候选路径并计算剩余关键字的启发式 最小绕路距离下界lowerbound来评估候选路径的优劣,将路径查询问题转 化为poi之间的查找匹配问题,在不脱离路网的情况下提供了快速查询解 决方案。所以在查询过程中通过如下步骤来计算候选路径的最小绕路距离 下界:
26.s3:基于候选路径计算其满足剩余每一类关键字的最小绕路距离下界 值,所述下界值为选取每一类关键字绕路距离最小值组成poi候选集合, 选取该候选集中最大值作为剩余路径的最小绕路距离;前缀路径链接至最 近邻1nn poi路径的路网距离与该最小绕路距离之和作为完整候选路径加 入最小优先队列中排序。
27.s301:基于关键字信息,以基本路径维护前缀路径的每一个偏差点所 找到的最近邻1nn poi为起点,查询目标点为终点,利用h2h索引分别计 算剩余包含剩余每一类关键字
poi到起点和终点的最短路网距离之和,得 到每一类关键字的两段值最小的poi候选集合,并在候选集中选取poi两 段值最大的作为剩余路径的最小绕路距离,并以此为启发式下界值,计算 模型如下:
28.lb(o
max
,p
u,t
)=max{min{d
n
(o
i
,n
i
)}|o
i
∈o
′
,kw
j
∈q
′
kw
}
29.其中,lb为剩余路径最小绕路距离,p
u,t
为兴趣点u到查询点t剩余最短 路径,o
i
表示所有包含剩余关键字的poi集合,
30.n
i
为以兴趣点到终点剩余最短路径上所有节点,d
n
为绕路距离, o
′
为包含所有查询关键字的poi集合, kw
j
为关键字信息,q
′
kw
为包含所有查询关键字的集合;min{d
n
(o
i
,n
i
)} 为每一类关键字的最近绕路poi距离,o
max
为求得剩余路径绕路下界的两 段值最大的poi。
31.s302:链接前缀路径、偏差点至1nn poi点的偏差路径、1nn poi点为 始到目标查询点的最短路径三段路径形成完整候选路径。参考图4所示,s
ꢀ→
v为前缀路径,v为偏差点,1nnpoi为以v进行偏差的最近邻poi,链接 前缀路径(s
→
v)+偏差路径(v
→
1nnpoi)+剩余最短路径(1nnpoi
→
t) 形成完整候选路径。
32.考虑到查询效率和路径成本问题,在维护候选路径的过程中,为了保 证安全可靠的删减无效候选路径,提出了相同节点的路径支配关系剪枝策 略以及提前满足关键字的可行路径upperbound策略,并提出了反向路径poi 贪心原则进一步缩短路径成本,重新计算前缀路径链接偏差路径的真实路 网距离,并以该真实路网距离和剩余路径的最小绕路距离之和为排序值加 入到最小优先队列中。
33.s303:若队列为空,中止程序;若得到的路径结果集合小于k值,则 继续从队列中弹出排序值最小的完整候选路径,如果该路径的关键字二进 制信息与查询关键字信息完全符合,则将其加入到结果集合中;否则,继 续对其进行偏差计算,生成新的候选路径加入到队列中直到路径结果集合 大小等于k。
34.结合图2中的poi子网,建立关键字倒排索引以及最短路径快速查询索 引,给定查询query=(s=v1,t=v9,q
kw
=<kw1,kw2,kw3>,k=2)为 例.以最短路径<v1,v4,v5,,v9>,cost=9为基线路径进行偏差,先构建前 缀路径pt树。
35.如图3所示,根据用户给定查询关键字建立具有关键字二进制信息的部 分最短路径树,其距离步骤如下:
36.将包含查询关键字的倒排索引poi划定节点范围c,利用dijkstra算法 扩展最短路径,以目标节点t作为根节点进行扩展,层级记录访问节点的 关键字二进制信息,下层信息为上层信息的二进制或运算结果。若范围c 内的节点全部被标记访问过了,则停止扩展,保留部分最短路径树如图3 所示。之后,对每一个偏差点进行1nn poi查询,偏差点v1为例,最短路径 <v1,v4,v5,v9>为基础偏差路径,维护pt0集合 c0={c(v1),c(v4),c(v5),c(v9)},其查询关键字倒排索引为pck(kw1)= {v2,v3,v7},pck(kw2)={v3,v6,v8},pck(kw3)={v5,v7},先利用经纬度计 算欧式空间距离,筛选得到poi范围<v2,v3,v5>,再计算真实路网距离得到 1nn poi为v2,这时得到前缀路径p1=<v1,v2>,cost1=5,当前关键字信 息为kw1,继续下一次由偏差点v4进行偏差根据上述同样的步骤找到1nn poi 点同样为v2,得到前缀路径p2=<v1,v4,v2>,cost2=4+2=6>5当前 关键字信息为kw1.此时根据domination关系剪枝掉路径p2,继续以p1为标 准,直到下一个不被支配的前缀路径替换p1,本文所述的剪
枝原则为包含 相同关键字信息的两条路径,距离大的路径将被距离小的路径替换。
37.接下来,利用三角形准则求得剩余未满足关键字路径的下界,以前缀路 径p=<v1,v4,v5>,剩余关键字q
kw
=<kw1,kw2>为例计算最小绕路下 界,由部分最短路径树可知1nn poi(v5)点到t点的最短路径节点,根据 最短路径和poi分别到起始点的最短路径构成的三角形,关键字倒排索引 pck(kw1)={v2,v3,v7},调用complb计算 d
d
(v2,sp(v5,t))=10,d
d
(v3,sp(v5,t))=13,d
d
(v7,sp(v5,t))=7 故得到关键字kw1的最小绕路距离为lb1(v7,sp(v5,t))=7, 接着,pck(kw2)={v5,v6,v8},同上计算得到如下值: d
d
(v5,sp(v5,t))=2,d
d
(v6,sp(v5,t))=7,d
d
(v8,sp(v5,t))=2 其得到关键字kw2的最小绕路距离为lb2(v5,sp(v5,t))=2 max(lb1,lb2)=lb1=7|o
max
=v7最终得到剩余路径的最小绕路下界为 7,此时,cost+lb=7+7=14,将其放入队列中。
38.给定查询query=(s=v1,t=v9,q
kw
=<kw1,kw2,kw3>,k=3), 每个步骤在优先队列中的候选路径偏差过程如下表所示:
[0039][0040]
在step1中先将<s=v1>加入队列中,从基础路径(s到t的最短路 径)构建pt树维护前缀路径,在step2里,依次从每个偏差点调用findnn 找到最近邻1nn poi生成候选路径,根据剪枝原则可知(<s,v2>,5+ 6,001)被(<s,v4,v2>,6+6,001)支配,此时,发现候选路径 (<s,v4,v5,v7>,9+6,101),需要根据反向重复poi收缩原则生成新的候选 路径(<s,v7>,8+6,101),并加入到队列中,在step3中,检查所有候选路 径,重复偏差操作,直到一条满足所有用户关键字的可行路径产生,step5 将(<s,v7,v8,t>,14,111),其cost=14加入到结果集合中,接着在step6 中发现两个相同poi序列的候选路径(<s,v2,v6,v5>)和(<s,v2,v
′6,v5> ),,则根据poi序列唯一原则剪枝掉后者,保留前者,最终在step7中,获 得结果集{<s,v2,v6,v5,t>),(<s,v7,v8,t>),(<s,v2,v3,v6,v5,t>}。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1