一种联合注意力机制的3D人体姿态识别双分支网络模型
一种联合注意力机制的3d人体姿态识别双分支网络模型
技术领域
1.本技术涉及计算机视觉领域,尤其涉及一种联合注意力机制的3d人体姿态识别双分支网络模型。
背景技术:
2.人体姿态识别作为计算机视觉的一个基础性研究领域,在行为识别、人机交互和智能安防等领域起着非常重要的作用。人体姿态识别的目标是从视觉信息(rgb图像或视频)中定位出人体的关节点,比如,手腕,手肘,肩膀,膝盖等,然后将这些关节点解析为人体姿态。
3.传统的姿态识别方法依赖人工提取特征并容易受环境和背景的影响,所提取到的特征在关节定位上准确率和精度过低。随着深度学习的发展以及算力的提升,卷积神经网络,尤其是残差神经网络在计算机视觉领域获得了广泛应用。借助残差神经网络,模型可以自动高效地学习图像深层语义信息,人体姿态识别任务取得了极大的发展。
4.人类视觉注意力系统通过选择性感知场景中的重要区域,抑制不重要的刺激,使得人类可以高效感知复杂视觉信息的关键部分,为目标检测、行为识别、场景分类等任务提供便利。近年来,注意力机制在多项视觉任务中得到了广泛应用并取得了巨大成功,比如图像分类、目标检测、图像分割、视频理解等。研究人员借助注意力机制来改善模型的专注能力,使得模型可以尽量地关注与任务相关的重要信息,忽略相关性差甚至不相关的干扰信息。
5.目前的人体姿态识别算法按照维度主要分为两大类,一种是只在2d图像空间内进行关节检测和定位的2d人体姿态识别,另一种是在2d图像空间基础上添加了深度信息的3d人体姿态识别。2d人体姿态识别由于深度信息的缺乏在很多应用场景上存在一定的局限性。虽然注意力机制在多项视觉任务中得到广泛研究,但是在姿态识别中,尤其是3d人体姿态识别任务上,联合注意力机制的研究工作比较缺乏。姿态识别任务的关键是提升模型对于人体关节位置的定位和识别能力,考虑到注意力机制可以提升模型的专注度,如何联合注意力机制来降低模型对人体关节的定位误差是需要深入研究的问题。
技术实现要素:
6.发明目的:为解决现有技术存在的问题,弥补注意力机制在姿态识别任务中的研究与应用比较缺乏的现状,提高模型对人体关节的专注能力,从而极大地降低模型在人体姿态识别上的关节定位误差。本发明提供了一种联合注意力机制的3d人体姿态识别双分支网络模型。
7.技术方案:一种联合注意力机制的3d人体姿态识别双分支网络模型,其特征在于,包括以下步骤:
8.步骤一:初始阶段:接收输入的rgb图像,经过人体检测网络hdn(human detectionnetwork)进行人体检测,再通过姿态识别网络进行数据增强操作,生成单人人体
图像;
9.步骤二:骨干网阶段:
10.(2
‑
1)利用残差网络模块对单人人体图像进行关节特征提取,得到关节特征分布f(x);
11.(2
‑
2)利用注意力模块学对单人人体图像进行注意力分布提取。注意力模块输出的注意力分布需要映射到[0,1]区间,因此最终的注意力分布a(x)为:
[0012]
a(x)=σ(a(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中,σ为sigmoid函数。
[0013]
(2
‑
3)最终骨干网阶段输出的特征图h(x)描述如下:
[0014][0015]
其中,f(x)为关节特征分布,a(x)为注意力分布,表示按位乘法。
[0016]
步骤三:姿态识别阶段:
[0017]
(3
‑
1)姿态识别网络根节点模块:利用姿态识别网络根节点模块检测出人体关节的盆骨根节点r=(x
r
,y
r
,z
r
),其中,x
r
,y
r
分别是盆骨根节点的2d图像坐标,z
r
是盆骨关节点的深度信息即盆骨根节点到相机的距离。
[0018]
首先,根据相机小孔成像的原理,采用可以对人体关节点检测定位的相机距离感知模型来获取根节点的深度信息。在现实空间(real space)和图像空间(image space)分别以人体盆骨为坐标轴原点,分别建立起x轴和y轴直角空间坐标系。其中,d表示人体在真实空间中盆骨到相机孔的距离,单位是毫米(mm);f表示相机的焦距,焦距以像素为单位,在x轴和y轴上即宽和高两个方向上每个像素代表的实际距离(以毫米为单位)不同,分别记为x1,y1;l表示人物的身体长度。
[0019]
可以发现以相机孔为交点的一对相似三角形。根据相似三角形边长成比例的性质,可以得到以下等式:
[0020][0021][0022]
类似的有,
[0023][0024]
最终,可以得到:
[0025][0026]
记a
real
是人物身体在真实空间下的面积,a
img
是人物在图像空间下的面积,观察等式4,可以得到:
[0027][0028]
在获得人物在图像空间下的面积之后,将融合后的特征图通过全局平均池化操作globalaverage pooling(gap)输出一个高度抽象化的语义因子θ。该语义因子用以调节在图像空间的人物检测框的面积,使得这个相机模型拥有更加灵活健壮的人物感知能力。最终距离感知公式如等式8:
[0029][0030]
其次,为了获取人体盆骨根节点的2d图像坐标x
r
,y
r
,首先是对输入的多尺度一致化特征图进行1*1卷积,生成根节点检测的2d热力图。最后,根据热力图进行根节点2d图像坐标提取,并输出得到2d图像坐标x
r
,y
r
。
[0031]
最后,为获取人体盆骨根节点深度信息坐标z
r
,首先是对输入的特征图进行全局平均池化操作gap,通过gap操作获取相机感知模型的语义因子。最后,依照式8进行计算得到盆骨根节点的深度信息,也就是该人物到拍摄相机的实际物理距离,并以此作为深度坐标z
r
。
[0032]
(3
‑
2)姿态识别网络根节点相关姿态模块。从裁剪的单人人体图像中进行根节点相关的3d人体关节检测,接收从骨干网输出的融合后的特征图,并通过1*1卷积生成关节的3d热力图。最后,根据关节的3d热力图进行除了人体盆骨根节点之外的其他各个关节的3d坐标提取,提取到的3d坐标是以根节点为参考的根节点相关关节坐标。
[0033]
进一步,步骤一中,所述人体检测网络hdn采用mask rcnn模型。
[0034]
进一步,步骤一中,所述数据增强为将训练图像沿着垂直轴随机旋转
±
30
°
,水平方向或者垂直方向上进行翻转,对训练图像进行色彩抖动,身体部位同步遮挡。
[0035]
进一步,步骤(2
‑
1)中,所述残差网络模块进行关节特征提取,接收尺寸为256*256的三通道rgb图像,初始卷积层以3*3的卷积核读取输入数据,输出通道数目为64。之后,经过残差网络模块四个特征层的特征提取和转置卷积可以得到最终的关节特征分布。
[0036]
进一步,步骤(3
‑
1)中,所述姿态识别网络根节点模块的盆骨根节点损失函数l
r
采用l1距离损失,如式9所示。其中,r
*
表示是人体盆骨根节点的地表真实标注坐标。
[0037]
l
r
=||r
‑
r
*
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0038]
姿态识别网络根节点相关姿态模块的相关节点损失函数l
rel
如式10所示。其中,表示是人体盆骨根节点相关节点的地表真实标注坐标,i表示第i个关节,n表示除去根节点外其它的人体关节总数。
[0039][0040]
有益效果:本发明直观而有效地解决了在3d人体姿态识别领域学习人体关节注意力分布的问题,弥补注意力机制在姿态识别任务中的研究与应用比较缺乏的现状,提高模型对人体关节的专注能力,从而极大地降低模型在人体姿态识别上的关节定位误差。
[0041]
附图表说明
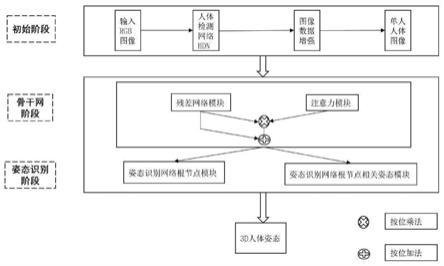
[0042]
图1为本发明的模型概述图;
[0043]
图2为本发明的模型骨干网结构图;
[0044]
图3为本发明涉及到的相机小孔成像模型图。
具体实施方式
[0045]
下面结合附图与具体实施方式对本发明作进一步详细说明:
[0046]
本实例提供一种联合注意力机制的3d人体姿态识别双分支网络模型。该模型通过两个并行分支可以同时学习到人体各个关节的特征信息和注意力分布,然后通过注意力分布来强化模型对于人体关节的专注能力,极大地降低了模型在人体姿态识别上的关节定位误差。
[0047]
该模型的模型概述如图1所示:
[0048]
步骤一:接收输入的rgb图像,经过人体检测网络hdn(human detectionnetwork)进行人体检测,采用mask r
‑
cnn作为实施方案中的人体检测网络hdn,生成单人人体图像;
[0049]
步骤二:对输入姿态识别网络的单人人体图像进行数据增强操作。具体采取的数据增强操作包括训练图像沿着垂直轴随机旋转
±
30
°
,水平方向或者垂直方向上进行翻转,对训练图像进行色彩抖动,身体部位同步遮挡等。
[0050]
步骤三:骨干网模型结构如图2。分支一利用残差网络模块进行特征提取,接收尺寸为256*256的三通道rgb图像,初始卷积层以3*3的卷积核读取输入数据,输出通道数目为64。之后,经过残差网络模块四个特征层的特征提取和转置卷积可以得到最终的人体关节特征图。每个特征层都包含了多层网络,比如卷积层,池化层,batch normalization层,relu激活层等。
[0051]
步骤四:接下来分支二借助注意力模块学习特征的注意力分布。注意力分支采用沙漏式网络结构来提取注意力分布。类似于残差网络模块的四个特征层,该模块经过四次下采样操作将注意力分布图的尺寸采样到8*8,下采样采用的是卷积操作。之后,经过四次上采样操作恢复尺寸,上采样采用的是双线性插值策略,上采样的过程中本文采用按位相加融合的方式融合了同样尺寸的注意力分布。注意力分支输出的关节注意力分布需要映射到[0,1]区间,因此最终的注意力分布a(x)为:
[0052]
a(x)=σ(a(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中,σ为sigmoid函数。
[0053]
借鉴于残差网络中恒等映射,本文在将关节特征分布和注意力分布结合的时候采用了类似的策略。最终骨干网输出的特征图h(x)为加入了注意力分布的特征图,描述如下:
[0054][0055]
其中,f(x)为关节特征分布,a(x)为注意力分布,表示按位乘法。
[0056]
步骤五:利用姿态识别网络根节点模块检测出人体关节的盆骨根节点r=(x
r
,y
r
,z
r
),其中,x
r
,y
r
分别是盆骨根节点的2d图像坐标,z
r
是盆骨关节点的深度信息即盆骨根节点到相机的距离。
[0057]
根据相机小孔成像的原理,采用可以对人体关节点检测定位的相机距离感知模型来获取根节点的深度信息。考虑如图3所示的相机小孔成像原理图。在现实空间(real space)和图像空间(image space)分别以人体盆骨为坐标轴原点,分别建立起x轴和y轴直
pose目的在于从裁剪的单人人体图像中进行根节点相关的3d人体关节检测,接收从骨干网输出的融合后的特征图,并通过1*1卷积生成关节的3d热力图。最后,根据关节的3d热力图进行除了人体盆骨根节点之外的其他各个关节的3d坐标提取,提取到的3d坐标是以根节点为参考的根节点相关关节坐标。
[0073]
步骤七:姿态识别网络根节点模块的盆骨根节点损失函数l
r
采用l1距离损失,如式9所示。其中,r
*
表示是人体盆骨根节点的地表真实标注坐标。
[0074]
l
r
=||r
‑
r
*
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0075]
姿态识别网络根节点相关姿态模块的相关节点损失函数l
rel
如式10所示。其中,表示是人体盆骨根节点相关节点的地表真实标注坐标,i表示第i个关节,n表示除去根节点外其它的人体关节总数。
[0076][0077]
步骤八:在3d人体姿态数据集human3.6m上,实现本发明提出的模型,对人体关节进行识别并对3d关节检测误差进行评估。
[0078]
本实例中,在human3.6m数据集的11个研究对象中,协议一采纳了六个对象用于3d人体姿态识别模型的训练,分别是对象s1,s5,s6,s7,s8和s9,采纳对象s11用于测试,协议一的评价指标采用了普式平均关节位置误差pampjpe。在协议二中,五个研究对象用于3d人体姿态识别模型的训练,分别是对象s1,s5,s6,s7和s8,而对象s9和s11用于模型的测试。在协议二中,评价指标为平均关节位置误差mpjpe。
[0079]
在根节点姿态识别误差评估中,采用协议二,误差下降到了118.3mm,相比之前的方法267.8mm,识别精度有了极大地提升。在根节点相关姿态误差评估中,采用协议一,误差下降到了32.4mm,相比之前方法的82.7mm,识别精度同样有了很大提升。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1