一种基于异构图transformer的单文档文本摘要系统
1.本发明属于自然语言处理领域,涉及一种基于异构图transformer的单文档文本摘要系统。
背景技术:
2.文本摘要是自然语言处理的核心技术之一,是目前解决信息过剩问题的一种辅助手段,能够帮助人类更加快速、准确、全面地从自然语言文本获取关键信息,在工业和商业方面都具有重要的实用意义。文本摘要技术涉及到语言理解、文本分类、摘要生成等复杂技术,因而面临着诸多挑战。
3.抽取式文本摘要认为文档的主题思想可通过文章中一句或几句话来代替。传统的抽取式文本摘要技术往往采用基于统计和规则的方法来得到摘要,通过计算文本中句子的相似性对句子进行排序,然后在抽取文本摘要。优点是不需要进行复杂计算,通用性较强,句子的语法错误较少,缺点是准确率较低,,比如lexrank和textrank。2014年,kagebackm等人首次使用深度学习方法完成抽取式文本摘要任务,该方法通过计算不同句子间语义表示的相似度,并采用次模函数优化选择合适的句子作为摘要。cheng和lapata等人于2016年提出一种基于seq2seq的通用自动摘要框架,采用层次文档编码器和注意力机制抽取文本摘要句。同年,cao等人针对查询式摘要任务,提出了一种融合査询信息的注意力机制。2017年,lip等人提出了一种基于等比序列的编码解码器模型drgn,采用神经变异推理对复发性潜伏期变量进行后验推理。在不同语言的数据集上证实,该方法表现出良好的性能。2018年,bennani等人提出了一种使用句子嵌入的简单无监督关键短语抽取模型,在单文本中采用嵌入排序抽取关键短语,该模型在f1得分上有了进一步提高。2019年,bouscarratl等人提出基于句子嵌入的高效抽取式摘要模型,该模型通过利用向量空间的语义信息进行信息抽取。2020年wang等人根据图注意力模型提出hsg模型,该方法构建提取文档摘要异构图网络来建模句子之间的关系,而无需预先训练语言模型。随着图模型的广泛应用,图模型如何和文本摘要任务相联系,最近的工作已经做了初步的探索。
4.当前技术问题为:
5.(1)当前基于图模型的文本摘要,存在融合周围结点的语义不足的问题。
6.(2)文本摘要对位置信息比较敏感,但当前存在图模型中位置信息不足的问题。
技术实现要素:
7.有鉴于此,本发明的目的在于提供一种基于异构图transformer的单文档文本摘要系统。
8.为达到上述目的,本发明提供如下技术方案:
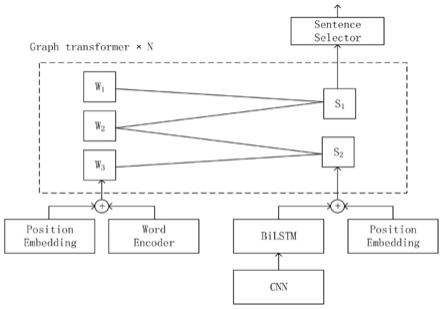
9.一种基于异构图transformer的单文档文本摘要系统,包括三部分:编码层、图更新层和句子选择层;
10.先通过编码层对句子和词语进行编码,然后,异构图层通过hgt模型来更新句子结
点和词语结点的间的语义表示,最后,句子选择层通过句子结点的语义表示来抽取摘要。
11.可选的,所述编码层:使用hsg模型中编码层,用表示词语结点语义表示矩阵,表示句子结点的语义表示矩阵;先对句子中包含的词语语义表示,使用不同大小卷积核cnn捕获其中临近词的语义得到融合周围结点语义表示矩阵,通过池化层得到句子的语义表示c
j
,使用bilstm得到句子的语义表示b
j
,将bilstm和cnn得到的结果拼接,得到句子最终的语义表示s
j
=[c
j
;b
j
];直接使用glove训练的300维词嵌入作为词语结点的语义表示。
[0012]
可选的,所述hgt模型包括注意力信息、传递信息和信息融合;
[0013]
1)注意力信息:
[0014]
在hgt更新结点的语义表示的过程中,为了避免结果过拟合,使用多头注意力机制来计算源结点和更新结点间的注意力权重,计算公式为:
[0015][0016]
公式中att
‑
head
i
(s,e,t)表示多头注意力机制中第i个更新头,其中s为源结点,t为更新结点,e为对应的边的特征;根据不同的边的关系来计算源结点和目标结点间的相关性;多头注意力中的第i头的计算公式,计算公式为:
[0017][0018]
其中,k
i
(s)表示源结点的线性变换,q
i
(t)表示更新结点线性变换后的向量,表示可训练的注意力权重,μ<τ(s),φ(e),τ(t)>根据不同注意力头和不同结点对设置的可训练参数,d表示更新结点线性变换后的维度;
[0019]
2)传递信息:
[0020]
更新信息从源结点传递到更新结点,为了计算更新结点的注意力,需要根据边的类型e=(s,t)对更新结点进行语义抽取;计算公式为:
[0021][0022]
对τ(s)类型的源结点在第l
‑
1时刻的语义表示向量h
(l
‑
1)
[s]进行线性变换后的向量;
[0023]
3)信息融合:
[0024]
根据不同的结点对,使用对应结点对计算出的注意力信息attention
hgt
(s,e,t)作为权重乘以语义抽取的结果message
hgt
(s,e,t)后求和,得到更新结点的更新向量计算公式为:
[0025][0026]
这个向量是更新结点t根据不同边特征的源结点更新后得到的特征向量;最后一步是对更新结点进行残差连接,以防止出现梯度消失;先对τ(t)类型的更新结点的更新信息使用激活函数,在进行线性变换a
‑
linear
τ(t)
,最后和τ(t)在l
‑
1时刻的更新结点的语义表示进行残差连接,计算公式为:
[0027][0028]
得到更新后的句子结点的语义表示向量。
[0029]
可选的,所述hgt模型改进为,由于在图模型更新过程中结点的语义表示中缺少位置信息,故在更新过程中在结点的语义表示中加上位置编码;分别在源结点和更新结点的输入的语义表示中加入可训练的位置编码分别为p
s
和p
t
;计算公式为:
[0030][0031]
可选的,所述句子选择层为:模型需要从异构图更新后的句子节点中抽取出摘要,使用交叉熵作为损失函数。
[0032]
本发明的有益效果在于:
[0033]
(1)本发明在图更新层,采用hgt方法来更新结点间的语义,可以融合更深层次的语义,进而可以提高模型对摘要抽取的准确率。
[0034]
(2)在图更新层加入可训练的位置编码,可以在图模型中加入文本的顺序信息,该方法可以进一步提高模型训练过程的收敛速度。
[0035]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0036]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0037]
图1为基于异构图transformer的单文档文本摘要模型框架图;
[0038]
图2为图更新层中句子结点的更新方式图;
[0039]
图3为图更新层中词语结点的更新方式图。
具体实施方式
[0040]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0041]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0042]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描
述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0043]
本发明采用一种基于异构图transformer的单文档文本摘要模型,主要包括三部分:文本编码层、图更新层、句子选择层。先通过编码层对句子和词语进行编码,然后,异构图层通过hgt来更新句子结点和词语结点的间的语义表示,最后,句子选择层通过句子结点的语义表示来抽取摘要。
[0044]
1.编码层:使用hsg模型中编码层,用表示词语结点语义表示矩阵,表示句子结点的语义表示矩阵。先对句子中包含的词语语义表示,使用不同大小卷积核cnn捕获其中临近词的语义得到融合周围结点语义表示矩阵,通过池化层得到句子的语义表示c
j
,进一步使用bilstm得到句子的语义表示b
j
,将bilstm和cnn得到的结果拼接,得到句子最终的语义表示s
j
=[c
j
;b
j
]。直接使用glove训练的300维词嵌入作为词语结点的语义表示。
[0045]
2.hgt模型:其包括三个步奏:注意力信息、传递信息、信息融合。
[0046]
1)注意力信息:
[0047]
在hgt更新结点的语义表示的过程中,为了避免结果过拟合,使用多头注意力机制来计算源结点和更新结点间的注意力权重,计算公式为:
[0048][0049]
公式中att
‑
head
i
(s,e,t)表示多头注意力机制中第i个更新头,其中s为源结点,在图1中表示w表示源结点,在图2中s表示源结点,t为更新结点,在图1中表示s表示更新结点,在图2中w表示更新结点,e为对应的边的特征。由于是异构图,所以结点对之间可能有不同的边的关系。图3为图更新层中词语结点的更新方式图。因此,需要根据不同的边的关系来计算源结点和目标结点间的相关性。因此,多头注意力中的第i头的计算公式,计算公式为:
[0050][0051]
其中,k
i
(s)表示源结点的线性变换,q
i
(t)表示更新结点线性变换后的向量,表示可训练的注意力权重,μ<τ(s),φ(e),τ(t)>根据不同注意力头和不同结点对设置的可训练参数,d表示更新结点线性变换后的维度。
[0052]
2)传递信息:
[0053]
更新信息从源结点传递到更新结点,为了计算更新结点的注意力,需要根据边的类型e=(s,t)对更新结点进行语义抽取。计算公式为:
[0054][0055]
对τ(s)类型的源结点在第l
‑
1时刻的语义表示向量h
(l
‑
1)
[s]进行线性
变换后的向量。
[0056]
3)信息融合:
[0057]
根据不同的结点对,使用对应结点对计算出的注意力信息attention
hgt
(s,e,t)作为权重乘以语义抽取的结果message
hgt
(s,e,t)后求和,得到更新结点的更新向量计算公式为:
[0058][0059]
这个向量是更新结点t根据不同边特征的源结点更新后得到的特征向量。最后一步是对更新结点进行残差连接,以防止出现梯度消失。先对τ(t)类型的更新结点的更新信息使用激活函数,在进行线性变换a
‑
linear
τ(t)
,最后和τ(t)在l
‑
1时刻的更新结点的语义表示进行残差连接,计算公式为:
[0060][0061]
得到更新后的句子结点的语义表示向量。
[0062]
3.位置编码:进一步改进模型,由于在图模型更新过程中结点的语义表示中缺少位置信息,故在更新过程中在结点的语义表示中加上位置编码。分别在源结点和更新结点的输入的语义表示中加入可训练的位置编码分别为p
s
和p
t
。因此,计算公式为:
[0063][0064]
4.句子选择层:模型需要从异构图更新后的句子节点中抽取出摘要,本文使用交叉熵作为损失函数。trigram blocking是paulus等人在2017年提出的,trigram blocking是简单和高效的抽取方式,从更新后的结点表示中抽取得分最高的三个句子编号。句子的得分是根据更新层输出的句子语义表示进行计算所得。
[0065]
实施例:
[0066]
本发明根据现有的单文档文本摘要模型以及相关语言模型改进而来。本发明的实施过程如下:
[0067]
1、对文本进行图构建和使用编码层对输入的文本进行编码,分别生成句子的语义表示s,词语结点的语义表示w。
[0068]
2、通过初始句子结点的语义表示s0=s和词语结点的语义表示w1=w0=w得到第一个时刻的句子语义表示,计算公式如下:
[0069]
s1=hgt(w0,s0)
[0070]
然后表示第t层的更新方式计算公式如下;
[0071]
w
t
=hgt(s
i
‑1,w
i
‑1)
[0072]
s
t
=hgt(w
i
‑1,s
i
‑1)
[0073]
3、将第三层s3作为句子结点的语义表示输入句子选择层中,进行摘要抽取。
[0074]
4、通过评价指标rouge
‑
1、rouge
‑
2和rouge
‑
l对文本的预测结果进行评估。
[0075]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明
的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1