一种异常数据智能筛选方法
1.本发明涉及数据治理、深度学习领域领域,特别涉及一种异常数据智能筛选方法。
背景技术:
2.近年来,我国已将“数字经济”列入国家发展战略,大数据、人工智能、区块链等数字技术被广泛应用于智慧城市、公共事务管理等社会治理领域,加速了社会治理的数字化转型进程。
3.在数字化转型过程中,“数据治理”是最关键的环节之一。“数据治理”关注的是数据规划、数据获取、数据质量、数据共享、数据标注等数据管理的整个生命周期,是各个领域“智能决策”应用的关键支撑。
4.在“数据治理”中,保证数据质量、确保数据的准确性是非常重要的基础工作。在这基础工作中,关注异常数据是关键点,对异常数据的处理是确保数据质量和数据准确性的前提。所以,如何从数据集中筛选出异常数据成为必然。
技术实现要素:
5.本发明所要解决的技术问题是提供一种,以解决现有技术中导致的上述多项缺陷。
6.为实现上述目的,本发明提供以下的技术方案:一种异常数据智能筛选方法,包括如下步骤:
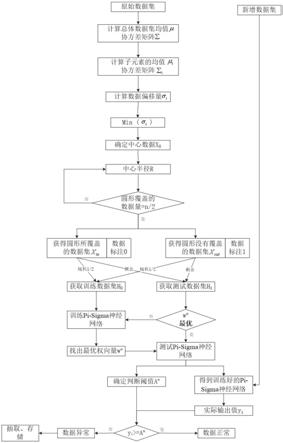
7.步骤1)寻找数据集的中心数据,通过计算子元素与总体数据集之间的数据偏移量,寻找出偏移量最小的数据,即中心数据;
8.步骤2)设置中心半径,以中心数据为圆心,寻找到一个合适的半径,使该圆所覆盖的数据数量为总体数据集的数据数量的一半;
9.步骤3)数据标注,把圆所覆盖的数据,添加标注为0,表示数据正常;把圆没有覆盖的数据,添加标注为1,表示数据异常;
10.步骤4)获取平衡数据集,从标注为0的数据集中随机抽取一半的数据,归入训练集,再从标注为1的数据集中随机抽取一半的数据,归入训练集,由此得到最终的训练数据集;把标注为0的数据集和标注为1的数据集剩下的各一半的数据归入测试集,由此得到测试数据集;
11.步骤5)训练模型,采用pi
‑
sigma高阶神经网络来训练模型,寻找到最优权向量及判断阈值;
12.步骤6)判断异常数据结论,针对待判断的数据,输入训练好的 pi
‑
sigma神经网络中,计算出实际输出值,当实际输出值大于等于判断阈值时,判断该数据正常,无需做处理;当实际输出值小于判断阈值时,判断该数据异常。
13.优选的,其特征在于,将数据处理对象,定义为数据集x, x=(x1,x2,
…
,x
i
,
…
,x
n
),其中,n为数据集x包含的数据个数,x
i
为数据集x中的第i个数据,x
i
为c
×
d的多维数据,
当x
i
为一个数值时,c=d=1;
14.设x的所有数据元素样本均值为μ,协方差矩阵为∑,x
i
的数据样本均值为μ
i
,协方差矩阵为∑
i
(μ,∑,μ
i
,∑
i
均可通过计算得出实际值)。
15.优选的,所述步骤1)中,下面通过计算子元素x
i
与总体数据集x 的偏移量,寻找出偏移量最小的数据,即寻找x的中心数据,x
i
与x 的偏移量定义如下:
16.σ
i
=(μ
i
‑
μ)'(∑
i
)
‑1(μ
i
‑
μ)
17.然后寻找偏移量最小的数据,记为x0:
18.x0={x
i
|min(σ
i
),i=1,2,
…
,n}
19.x0即为x的中心数据,x0的数据元素个数为1个或者多个。
20.优选的,所述步骤2)中,以x0的数据元素为圆心(当x0的数据元素个数为多个时,随机选取其中一个作为圆心),设置初始半径 r0,计算1个或者多个圆(对应x0的数据元素个数)覆盖的数据数量:(1)当覆盖的数据数量大于[n/2](取整),缩小r0的值,进行寻找;(2)当覆盖的数据数量小于[n/2],扩大r0的值,进行寻找;(3) 当覆盖的数据数量为[n/2],确定出中心半径r=r0,停止寻找。把圆所覆盖的所有数据集,记为:x
in
;把圆没有覆盖的所有数据集,记为:x
out
。
[0021]
优选的,所述步骤3)中,把x
in
里的数据元素,添加标注为0,表示数据正常;把x
out
里的数据元素,添加标注为1,表示数据异常;标注原则:把距x的中心数据较近的数据标注为0,其它较远的数据标注为1。
[0022]
优选的,所述步骤4)中,设训练数据集和测试数据集分别记为h0和h1,从x
in
中随机抽取一半的数据,归入h0,再从x
out
中随机抽取一半的数据,归入h0,由此得到训练数据集h0;把x
in
和x
out
剩下的各一半的数据归入h1,由此得到测试数据集h1;
[0023]
h0=(x
0,1
,x
0,2
,
…
,x
0,j
…
,x
0,[n/2]
),
[0024]
其中,x
0,j
=(x
0,j,1
,x
0,j,2
,
…
,x
0,j,d
,
…
,x
0,j,d
),d为x
0,j
的数据维度,与x
i
一致,o
0,j
为x
0,j
对应的数据标注值;
[0025]
h1=(x
1,1
,x
1,2
,
…
,x
1,j
…
,x
1,n
‑
[n/2]
),
[0026]
其中,x
1,j
=(x
1,j,1
,x
1,j,2
,
…
,x
1,j,d
,
…
,x
1,j,d
),d为x
1,j
的数据维度,与x
i
一致,o
1,j
为x
1,j
对应的数据标注值。
[0027]
优选的,所述步骤5)中,pi
‑
sigma神经网络由一个输入层、一个隐含层和一个输出层组成,假设输入层、隐含层和输出层的神经元个数分别为n、k和1;输入样本x
m
=(x
m,1
,x
m,2
,
…
,x
m,n
‑1,x
m,n
)
t
,其中x
m,n
=
‑
1 是对应的阀值,相应的实际输出为y,理想输出为o,w
i,k
为第i个输入点与第k个求和层结点间的权值,w
k
=(w
1,k
,w
2,k
,
…
,w
i,k
,
…
,w
n
‑
1,k
,w
n,k
)为输入层各结点与求和层k结点的权值向量,其中w
nk
=1,则求和层的h
k
为:
[0028][0029]
设激活函数为f(x),这里取f(x)为sigmoid函数(1/1+e
‑
x
),则对于样本集(y
j
,o
j
),网络实际输出为:
[0030][0031]
网络误差函数取为传统的平方误差函数:
[0032][0033]
使用梯度算法来训练pi
‑
sigma神经网络,目的就是寻找到权值向量w
*
,使e(w)达到最小,
[0034]
即
[0035]
在使用训练数据集h0进行模型训练时:
[0036]
输入层的神经元个数为:n=d+1,即x
m
=(x
0,j
,
‑
1)
t
;
[0037]
样本集(y
j
,o
j
)对应的理想输出o
j
为:o
j
=o
0,j
,j=[n/2];
[0038]
训练以前,对数据集h0进行归一化处理;
[0039]
通过数据集h0训练pi
‑
sigma神经网络,找出最优权值向量w
*
;
[0040]
在使用测试数据集h1进行模型测试时:
[0041]
输入层、隐含层、输出层的神经元个数保持不变,权值向量为w
*
;
[0042]
样本集(y
j
,o
j
)对应的理想输出o
j
为:o
j
=o
1,j
,j=n
‑
[n/2]。
[0043]
优选的,所述步骤6)中,针对任何一个数据x
i
,输入训练好的 pi
‑
sigma神经网络,对应的实际输出值为y
i
;
[0044]
当y
i
>=a
*
时,判断该数据x
i
正常,判断结束;
[0045]
当y
i
<a
*
时,判断该数据x
i
异常,把该数据自动提取处理,存储在计算机系统中,为下一步的“数据治理”做准备。
[0046]
采用以上技术方案的有益效果是:该方法较之于传统的异常数据判别方法,是集判断、抽取、存储为一体的方法,计算简便,直观明了,数据标注原则明确,训练数据集和测试数据集的数据平衡性好,模型具有良好的非线性处理能力,判断结论明确。
附图说明
[0047]
图1为本发明一种异常数据智能筛选方法的流程图;
[0048]
图2是pi
‑
sigma神经网络函数图;
[0049]
图3是误差变化示意图。
具体实施方式
[0050]
下面详细说明本发明的优选实施方式。
[0051]
一种异常数据智能筛选方法,首先,通过计算子元素与总体数据集之间的数据偏移量,寻找出偏移量最小的数据,即中心数据;其次,以中心数据为圆心,寻找到一个合适的半径,使该圆所覆盖的数据数量为总体数据集的数据数量的一半;第三,把圆所覆盖的数据,添加标注为0(表示数据正常);把圆没有覆盖的数据,添加标注为1(表示数据异常);第四,从标注为0的数据集中随机抽取一半的数据,归入训练集,再从标注为1的数据集中随机抽取一半的数据,归入训练集,由此得到最终的训练数据集;把标注为0的数据集和标注为1的数据集剩下的各一半的数据归入测试集,由此得到测试数据集;第五,采用一种pi
‑
sigma高阶神经网络来训练模型,利用训练数据集和测试数据集寻找到最优权向量及判断阈值;第六,针对待判断的数据,输入训练好的pi
‑
sigma神经网络中,计算出实际输出值,当实际
输出值大于等于判断阈值时,判断该数据正常,无需做处理,当实际输出值小于判断阈值时,判断该数据异常;最后,把判断为异常的数据,通过计算机系统自动提取并存储起来,为下一步“数据治理”做准备。
[0052]
把“数据治理”中的一种类型的数据处理对象,定义为数据集x,x=(x1,x2,
…
,x
i
,
…
,x
n
),其中,n为数据集x包含的数据个数,x
i
为数据集x中的第i个数据,x
i
为c
×
d的多维数据,当x
i
为一个数值时, c=d=1。
[0053]
设x的所有数据元素样本均值为μ,协方差矩阵为∑,x
i
的数据样本均值为μ
i
,协方差矩阵为∑
i
(μ,∑,μ
i
,∑
i
均可通过计算得出实际值)。
[0054]
寻找中心数据:
[0055]
下面通过计算子元素x
i
与总体数据集x的偏移量,寻找出偏移量最小的数据,即寻找x的中心数据,x
i
与x的偏移量定义如下:
[0056]
σ
i
=(μ
i
‑
μ)'(∑
i
)
‑1(μ
i
‑
μ)
[0057]
然后寻找偏移量最小的数据,记为x0:
[0058]
x0={x
i
|min(σ
i
),i=1,2,
…
,n}
[0059]
x0即为x的中心数据,x0的数据元素个数为1个或者多个。
[0060]
设置中心半径:
[0061]
以x0的数据元素为圆心(当x0的数据元素个数为多个时,随机选取其中一个作为圆心),设置初始半径r0,计算1个或者多个圆(对应 x0的数据元素个数)覆盖的数据数量:(1)当覆盖的数据数量大于[n/2] (取整),缩小r0的值,进行寻找;(2)当覆盖的数据数量小于[n/2],扩大r0的值,进行寻找;(3)当覆盖的数据数量为[n/2],确定出中心半径r=r0,停止寻找。把圆所覆盖的所有数据集,记为:x
in
;把圆没有覆盖的所有数据集,记为:x
out
;
[0062]
数据标注:
[0063]
把x
in
里的数据元素,添加标注为0(表示数据正常);把x
out
里的数据元素,添加标注为1(表示数据异常)。标注原则:把距x的中心数据较近的数据标注为0,其它较远的数据标注为1。
[0064]
获取平衡数据集:
[0065]
设训练数据集和测试数据集分别记为h0和h1。从x
in
中随机抽取一半的数据,归入h0,再从x
out
中随机抽取一半的数据,归入h0,由此得到训练数据集h0;把x
in
和x
out
剩下的各一半的数据归入h1,由此得到测试数据集h1。
[0066]
h0=(x
0,1
,x
0,2
,
…
,x
0,j
…
,x
0,[n/2]
),其中,x
0,j
=(x
0,j,1
,x
0,j,2
,
…
,x
0,j,d
,
…
,x
0,j,d
),d为x
0,j
的数据维度,与x
i
一致,o
0,j
为x
0,j
对应的数据标注值;
[0067]
h1=(x
1,1
,x
1,2
,
…
,x
1,j
…
,x
1,n
‑
[n/2]
),其中, x
1,j
=(x
1,j,1
,x
1,j,2
,
…
,x
1,j,d
,
…
,x
1,j,d
),d为x
1,j
的数据维度,与x
i
一致,o
1,j
为 x
1,j
对应的数据标注值。
[0068]
用这种方式获取训练数据集和测试数据集,是为了加强两个数据集的数据平衡性,减少因数据不平衡性导致的模型不准确性。
[0069]
训练模型:
[0070]
本专利采用一种高阶神经网络pi
‑
sigma神经网络来作为训练模型。针对传统的神经网络结构,只包含一种求和神经元(∑),这种结构效率低下,面对非线性问题时束手无策,而现实生活中到处存在着非线性问题;而pi
‑
sigma高阶神经网络结构中包含求积神经
元(π)的前馈神经网络,包含了多项式乘积的特点,很好地提高了网络效率,增强了非线性能力,还有效地克服了“维数灾难”问题。因此,利用 pi
‑
sigma神经网络来训练模型。
[0071]
pi
‑
sigma神经网络由一个输入层、一个隐含层(求和层)和一个输出层(求积层)组成,假设输入层、隐含层和输出层的神经元个数分别为n、k和1(如图2)。输入样本x
m
=(x
m,1
,x
m,2
,
…
,x
m,n
‑1,x
m,n
)
t
,其中x
m,n
=
‑
1是对应的阀值,相应的实际输出为y,理想输出为o,w
i,k
为第i个输入点与第k个求和层结点间的权值, w
k
=(w
1,k
,w
2,k
,
…
,w
i,k
,
…
,w
n
‑
1,k
,w
n,k
)为输入层各结点与求和层k结点的权值向量,其中w
nk
=1,则求和层的h
k
为:
[0072][0073]
设激活函数为f(x),这里取f(x)为sigmoid函数(1/1+e
‑
x
),则对于样本集(y
j
,o
j
),网络实际输出为:
[0074][0075]
网络误差函数取为传统的平方误差函数:
[0076][0077]
使用梯度算法来训练pi
‑
sigma神经网络,目的就是寻找到权值向量w*,使e(w)达到最小,即
[0078][0079]
在使用训练数据集h0进行模型训练时:
[0080]
输入层的神经元个数为:n=d+1,即x
m
=(x
0,j
,
‑
1)
t
;
[0081]
样本集(y
j
,o
j
)对应的理想输出o
j
为:o
j
=o
0,j
,j=[n/2];
[0082]
训练以前,对数据集h0进行归一化处理;
[0083]
通过数据集h0训练pi
‑
sigma神经网络,找出最优权值向量w
*
。
[0084]
在使用测试数据集h1进行模型测试时:
[0085]
输入层、隐含层、输出层的神经元个数保持不变,权值向量为w
*
;
[0086]
样本集(y
j
,o
j
)对应的理想输出o
j
为:o
j
=o
1,j
,j=n
‑
[n/2];
[0087]
训练以前,对数据集h1进行归一化处理;
[0088]
通过数据集h1测试pi
‑
sigma神经网络,确定模型效果及判断阈值 a
*
(选取的判断阈值,要确保判断结论的准确率最高)。
[0089]
判断、抽取、存储异常数据:
[0090]
针对任何一个数据x
i
,输入训练好的pi
‑
sigma神经网络,对应的实际输出值为y
i
。
[0091]
当y
i
>=a
*
时,判断该数据x
i
正常,判断结束;
[0092]
当y
i
<a
*
时,判断该数据x
i
异常,把该数据自动提取处理,存储在计算机系统中,为下一步的“数据治理”做准备。
[0093]
实施例
[0094]
这里以某专业某班级学生的成绩分数为例:
[0095]
假设该班12名同学的各科成绩如表1。
[0111][0112]
把标注为0的x3,x8,x9列入数据集h1,再把标注为1的x1, x6,x
11
列入数据集h1,最终形成数据集h1[0113]
表3 数据集h1[0114][0115]
训练pi
‑
sigma高阶神经网络模型:
[0116]
在训练pi
‑
sigma高阶神经网络前,先确认几个参数:
[0117]
隐含层节点数为:3,最大训练次数为:100000,学习率为:0.01,目标误差为:1.50001,输入层与隐含层的初始权值在0
‑
1之间随机选取。在数据输入前,把h0和h1中的成绩进行归一化处理。
[0118]
h0数据输入后,得到训练的误差变化如图3所示:
[0119]
当迭代次数得到24904时,满足误差要求。此时得到最优权向量
[0120][0121]
然后保持w
*
不变,把h1数据输入后,得出实际输出值:
[0122]
表4 测试实际输出值与判断阈值选取表
[0123][0124]
从表4可以看出,当判断阈值取a
*
=0.5011时,判断结果准确率最高(5/6≈83.33%,x3,x6,x8,x9,x
11
判断正确,x1判断错误)。
[0125]
判断异常数据结论:
[0126]
另外列出三个数据:x
13
=[95,65,74,86,90];x
14
=[101,180, 89,64,140];x
15
=[0,100,100,99,100],把这三个数据分别输入训练好的pi
‑
sigma模型中,各自的输出值为:y
13
=0.5011; y
14
=0.5001;y
15
=0.5010。
[0127]
因为y
13
>=a
*
,所有x
13
数据正常;
[0128]
(分数的取值范围正常情况下为0
‑
100之间,所以x
13
的判断结论正确)
[0129]
因为y
14
<a
*
,所有x
14
数据异常,把该数据自动提取处理,存储在计算机系统中,为下一步的“数据治理”做准备。
[0130]
(分数的取值范围正常情况下为0
‑
100之间,而x
14
的出现了101、180、140等数据,所以x
14
的判断结论正确)
[0131]
因为y
15
<a
*
,所有x
15
数据异常,把该数据自动提取处理,存储在计算机系统中,为下一步的“数据治理”做准备。
[0132]
(从x
15
的成绩可以看出,后面四门课程的成绩为满分或接近满分,应该是优等生,但出现了一门0分,可以推测该学生的成绩异常,所以x
15
的判断结论正确)
[0133]
以上所述的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员
来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1