基于SAX解析Excel文件至多表并提高数据精度的方法与流程
本发明涉及数据处理技术领域,具体的说是一种基于SAX解析Excel文件至多表并提高数据精度的方法。
背景技术
对于excel文件解析导入数据库表,传统的方式存在以下几个问题:
(1)传统DOM解析方式一个几M的excel文件,解析的结果将会占用几百M的内存,导致JVM内存溢出;
(2)每一个excel文件仅能有一个表头信息,当一个excel文件中存在多个表头信息时,必须将该excel拆分为多个不同表头的excel(一个表头对应一个excel 数据文件),逐个导入;
(3)excel表头与数据表的映射关系必须完全匹配,不能按照指定的需求,进行部分匹配;
(4)SAX解析数据会丢失精度和时间格式无法正常转换。
对于上述的四点问题,设计研发一种基于SAX解析Excel文件至多表并提高数据精度的方法,以通过将解析excel的传统方式转化为SAX方式进行解析,并通过配置多个不同的excel表头与数据表的映射关系,和重写SAX抽象类,成功解决上述四点问题,使得excel文件的导入变得高效便捷。
技术实现要素:
本发明针对目前技术发展的需求和不足之处,提供一种基于SAX解析Excel文件至多表并提高数据精度的方法,旨在将excel文件通过SAX解析方式导入多个数据库表中,同时解决数据会丢失精度问题、时间格式无法正常转换问题和传统DOM解析方式带来的问题。
本发明的一种基于SAX解析Excel文件至多表并提高数据精度的方法,解决上述技术问题采用的技术方案如下:
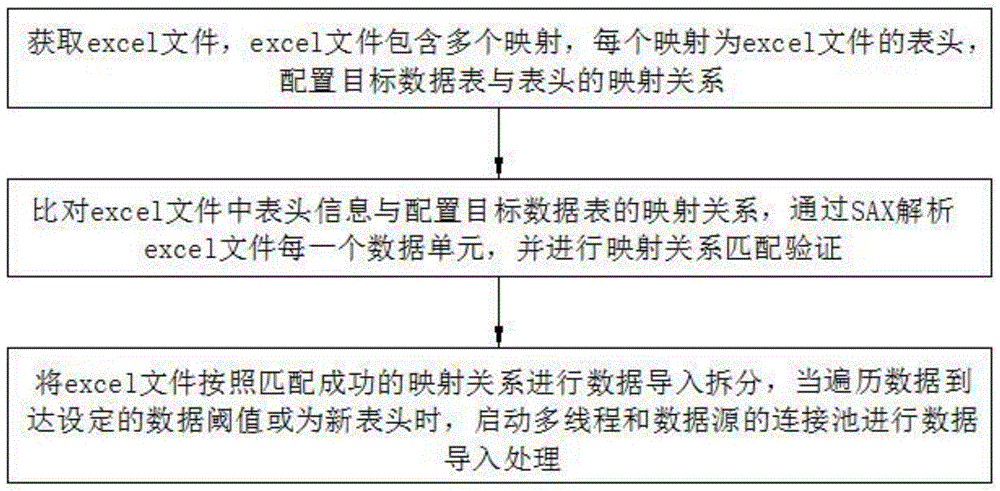
一种基于SAX解析Excel文件至多表并提高数据精度的方法,首先获取excel文件,excel文件包含多个映射,每个映射为excel文件的表头,配置目标数据表与表头的映射关系;然后比对excel文件中表头信息与配置目标数据表的映射关系,通过 SAX解析excel文件每一个数据单元,并进行映射关系匹配验证,最后将excel文件按照匹配成功的映射关系进行数据导入拆分,当遍历数据到达设定的数据阈值或为新表头时,启动多线程和数据源的连接池进行数据导入处理。
可选的,获取的excel文件包括03版本和07版本两种。
进一步可选的,针对03版本的excel文件,需要编写实现HSSFListener接口的抽象类XLSReader,实现processRecord方法,用于读取行列,且针对每种单元格数据类型根据record.getSid()进行处理。
进一步可选的,针对07版本的excel文件,需要编写继承DefaultHandler的抽象类XLSXReader,重写startElement和endElement,用于读取行列。
优选的,读取行列的过程中,将数字中日期类型的默认转为yyyy-MM-dd HH:mm:ss:SSS格式进行统一处理。
可选的,比对excel文件中表头信息与配置目标数据表的映射关系之前,需要根据部署机器的线程数、内存和EXCEL行数据大小,设置数据阈值。
可选的,比对excel文件中表头信息与配置目标数据表的映射关系,通过SAX解析excel文件每一个数据单元,并进行映射关系匹配验证,具体为:
采用SAX方式遍历excel文件的每行并与映射关系进行匹配,确认该excel文件中匹配的映射关系的相关信息,统计满足映射的表头个数,并记录满足匹配成功的映射的sheet页和行列信息。
进一步可选的,一个映射关系包括多个表头与数据列的映射。
本发明的一种基于SAX解析Excel文件至多表并提高数据精度的方法,与现有技术相比具有的有益效果是:
(1)本发明旨在将excel文件通过SAX解析方式导入多个数据库表中,同时解决数据会丢失精度问题、时间格式无法正常转换问题和传统DOM解析方式带来的问题;
(2)本发明采用SAX方式解析excel文件,并配置excel表头与数据表的多个映射关系,重写SAX抽象类,来提高excel文件导入的灵活性、效率和准确性;另外,还通过抽象类XLSXReader和XLSReader数据处理提高数据精度和日期数据处理能力。
附图说明
附图1是本发明的方法流程图。
具体实施方式
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
实施例一:
本实施例提出一种基于SAX解析Excel文件至多表并提高数据精度的方法,包括:
首先,获取excel文件,excel文件包含多个映射,每个映射为excel文件的表头,配置目标数据表与表头的映射关系。
根据部署机器的线程数、内存和EXCEL行数据大小,设置数据阈值。
然后,比对excel文件中表头信息与配置目标数据表的映射关系,通过SAX解析 excel文件每一个数据单元,并进行映射关系匹配验证,具体为:
采用SAX方式遍历excel文件的每行并与映射关系进行匹配,确认该excel文件中匹配的映射关系的相关信息,一个映射关系包括多个表头与数据列的映射;统计满足映射的表头个数,并记录满足匹配成功的映射的sheet页和行列信息。
最后,将excel文件按照匹配成功的映射关系进行数据导入拆分,当遍历数据到达设定的数据阈值或为新表头时,启动多线程和数据源的连接池进行数据导入处理。
本实施例中,获取的excel文件为03版本,此时,需要编写实现HSSFListener 接口的抽象类XLSReader,实现processRecord方法,用于读取行列,且针对每种单元格数据类型根据record.getSid()进行处理。读取行列的过程中,将数字中日期类型的默认转为yyyy-MM-dd HH:mm:ss:SSS格式进行统一处理,尤其是个性化的m/d/yy、 yy、/yy、/m、m/、/d、d/、/年、年/、/月、月/、/日、日/等。
编写抽象类XLSReader的具体实现代码如下:
实施例二:
本实施例提出一种基于SAX解析Excel文件至多表并提高数据精度的方法,包括:
首先,获取excel文件,excel文件包含多个映射,每个映射为excel文件的表头,配置目标数据表与表头的映射关系。
根据部署机器的线程数、内存和EXCEL行数据大小,设置数据阈值。
然后,比对excel文件中表头信息与配置目标数据表的映射关系,通过SAX解析 excel文件每一个数据单元,并进行映射关系匹配验证,具体为:
采用SAX方式遍历excel文件的每行并与映射关系进行匹配,确认该excel文件中匹配的映射关系的相关信息,一个映射关系包括多个表头与数据列的映射;统计满足映射的表头个数,并记录满足匹配成功的映射的sheet页和行列信息。
最后,将excel文件按照匹配成功的映射关系进行数据导入拆分,当遍历数据到达设定的数据阈值或为新表头时,启动多线程和数据源的连接池进行数据导入处理。
本实施例中,获取的excel文件为07版本,此时,需要需要编写继承 DefaultHandler的抽象类XLSXReader,重写startElement和endElement,用于读取行列。读取行列的过程中,将数字中日期类型的默认转为yyyy-MM-dd HH:mm:ss:SSS 格式进行统一处理,尤其是个性化的m/d/yy、yy、/yy、/m、m/、/d、d/、/年、年/、 /月、月/、/日、日/等。
编写抽象类XLSXReader的具体实现代码如下:
- 还没有人留言评论。精彩留言会获得点赞!