一种基于互信息相似度的零样本动作识别方法及系统
1.本发明涉及计算机视觉技术领域,具体涉及一种基于互信息相似度的零样本动作识别方法及系统。
背景技术:
2.随着深度学习在骨架动作识别上面的应用越来越广泛,大规模的骨架动作识别的标注问题凸显出来。现实中难以构建出包含所有动作类的数据集用于训练,基于这种情况,零样本的学习方法被用于学习训练中并不涉及到的不可见类。利用一些语义上的信息,例如动作名称、属性和描述作为可见类和不可见类联系的桥梁。与图像数据相比,视频数据集的采集和标注尤为困难,因此,在骨架动作视频数据集上进行零样本动作识别是很有意义的现实问题。
3.深度学习系统在动作识别领域面对给定的训练集和标签类已经取得了非常好的效果,但是对于测试集中的不可见类却无能为力。为了缓解这个问题,研究人员提出了零样本的动作识别方法。在零样本的视频分类领域,通用方法是先利用预训练好的网络从视频帧中提取视觉特征。
4.现阶段大多数的零样本动作识别方法是从零样本的图像识别方法上扩展而来。在训练阶段,它们通过在训练集的可见类上训练神经网络,构造投影函数来建立视觉特征和语义特征之间的联系。在测试阶段,测试集动作序列的视觉特征与所有不可见类的语义向量之间的相似性要么在投影的公共空间中计算,要么通过学习到的度量方法计算。然而,由于序列数据本身的复杂性,这些自适应方法面临以下两个问题。
5.首先,在提取视觉特征时,视频领域一般采取3d卷积网络对rgb视频数据进行提取操作,而骨架数据一般使用图卷积的方式进行。这些特征提取器提取的特征会进一步的保留时序信息,在处理特征时,时序信息很大程度上会被平均池化或者最大池化而消失。作为一个序列数据,这种池化操作仅保留了全局的统计信息,对于局部的时序信息上的损失是无法接受的。在零样本领域,这种时序信息上的遗漏将会带来更加严重的后果,因为语义向量上的判别更加需要时序上的动态信息,就如不同的动作可能只在局部部分有所不同,,如何获取时序上的判别信息是零样本骨架动作识别领域的一个重要的技术问题。
6.其次,在可见类上构建投影或者学习距离度量来捕捉视觉特征和语义特征之间的相关性将很难泛化到具有不同分布的不可见类上。一个可能的原因是,这种方法试图在有限的可见类的投影或度量给定数据下,从一个空间重构到另一个空间,而两类特征空间之间的分布鸿沟将无法简单跨越。实际上,相对于映射的视觉特征与其对应的语义向量之间的绝对距离,更感兴趣的是语义向量对同一类和不同类的视觉特征的相对关系。
技术实现要素:
7.本发明提供了一种基于互信息相似度的零样本动作识别方法及系统,解决了以上所述的骨架动作识别提取难度大的技术问题。
8.本发明为解决上述技术问题提供了一种基于互信息相似度的零样本动作识别方法,包括以下步骤:
9.s1,在零样本的动作分类任务中使用视频特征提取模块进行骨架动作特征提取;
10.s2,利用语义特征提取模块对动作标签的语义信息进行特征化处理;
11.s3,构建出语义特征和视频特征之间的非线性映射,同时设计出随帧数递增而互信息递增的互信息判别网络,以增强互信息对两类特征的判别能力。
12.可选地,所述s1具体包括:利用预训练好的3d图神经网络从人体骨架动作视频中提取特征向量,将骨架动作视频表示成动作特征向量x=[x1,
…
,x
n
],x
i
∈r
d
×
t
,其中t为向量长度,d为帧特征的维数。
[0013]
可选地,所述s2具体包括:用预训练好的词向量模型将视频动作的标签转化为相对应的语义向量,词性越接近的标签在距离度量上越短,并将各类标签表示成标签语义特征向量y=[y1,
…
,y
n
],y
i
∈r
c
其中c为标签语义特征向量的维数。
[0014]
可选地,所述s3具体包括:整个骨架视频动作类别分为可见类和不可见类;
[0015]
在训练阶段,仅用可见类的骨架动作视频以及相对应的标签进行模型的训练,在测试阶段,对选定的不可见类进行骨架动作的分类,以达到动作识别的零样本要求。
[0016]
可选地,在训练阶段,通过导入动作特征向量x以及对应的标签语义特征向量y到互信息估计网络t中,通过最大化x和y两者之间的互信息同时调整x在时序维度上与y的互信息的递增关系,从而构建出一个优秀的互信息判别网络t,为后续测试阶段做好模型上的准备。
[0017]
可选地,在测试阶段,将不可见类的骨架动作特征分别与不可见类所有的标签语义向量y导入到训练好的互信息判别网络t中,选择计算结果中互信息最大的那一个标签类作为该骨架动作的预测标签。
[0018]
可选地,所述互信息判别网络的具体构造方法步骤如下:
[0019]
(1)设置超参数:n为每个骨架动作视频的采样帧数;a为总体互信息损失和时序互信息损失之间的比例参数;
[0020]
(2)对输入骨架序列采样n帧,送入预训练的3d图神经网络中获得对应的视觉特征向量[f1,f2,
…
,f
n
],然后对前k帧的视觉特征使用max
‑
pooling从而获取第k步的视觉特征表示x
k
,即:
[0021]
x
k
=maxpool([f1,f2,
…
,f
k
])
[0022]
(4)进行正负样本的采样,对于每个视觉特征向量的前k步表示x
k
均对应一个标签语义特征向量y,这一组视觉特征和语义特征配对构成正样本(x
k
,y),然后从另一个不对应的骨架动作序列里进行前k步的视觉特征提取与y构成负样本
[0023]
(5)将正负采样的样本对导入互信息判别网络进行对比学习,利用jensen
‑
shannon散度估计去最大化互信息,得到一个互信息的估计分数c
k
,通过对c
k
的优化使得正样本对互信息越大而负样本对互信息越来越小,从而训练得到互信息判别网络t,即:
[0024][0025]
其中,x和均采样自视觉特征分布v中,而y采样自语义特征分布l中,f
sp
表示
soft
‑
plus函数,f
sp
(z)=log(1+e
z
)。
[0026]
可选地,步骤(5)之后还包括:
[0027]
(6)对于分段互信息递增损失,模型因为是进行了k步的视觉特征分段,通过最大化互信息的计算得到n个互信息估计分数c=[c1,c2,
…
,c
n
],时序递增部分的局部互信息损失函数定义为:
[0028][0029]
通过优化该损失,为互信息判别网络增加互信息递增的条件限制;
[0030]
(7)最终损失函数融合了全局的互信息估计分数和时序递增部分的互信息分数,以超参数a融合在一起,即:
[0031]
l=l
g
+αl
l
[0032]
全局互信息损失函数定义为l
g
=
‑
c
n
,l为最终损失函数。
[0033]
本发明还提供了一种用于基于互信息相似度的零样本动作识别方法的系统,包括视频特征提取模块、语义特征提取模块及基于互信息的特征相似度计算模块;
[0034]
所述视频特征提取模块用于在零样本的动作分类任务中对骨架动作特征进行提取;
[0035]
所述语义特征提取模块用于对动作标签的语义信息进行特征化处理;
[0036]
所述特征相似度计算模块用于构建出语义特征和视频特征之间的非线性映射,同时设计出随帧数递增而互信息递增的判别网络,以增强互信息对两类特征的判别能力。
[0037]
有益效果:本发明提供了一种基于互信息相似度的零样本动作识别方法及系统,包括以下步骤:s1,在零样本的动作分类任务中使用视频特征提取模块进行骨架动作特征提取;s2,利用语义特征提取模块对动作标签的语义信息进行特征化处理;s3,构建出语义特征和视频特征之间的非线性映射,同时设计出随帧数递增而互信息递增的互信息判别网络,以增强互信息对两类特征的判别能力。通过最大化视觉特征和语义特征之间的互信息来捕捉两者分布之间的非线性统计相关性,进而提高对不可见类的泛化效果;保证了互信息在时序上的递增单调约束,从而使得时序信息融合进了互信息的判别网络之中,提升了网络的判别效果;与其他零样本的骨架动作识别方法相比具有更好的性能。
[0038]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。本发明的具体实施方式由以下实施例及其附图详细给出。
附图说明
[0039]
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0040]
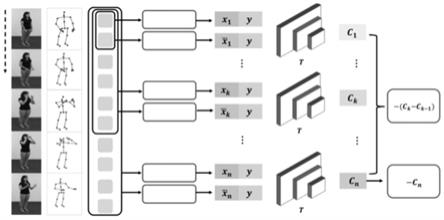
图1为本发明基于互信息相似度的零样本动作识别方法及系统的原理框架图;
[0041]
图2为本发明基于互信息相似度的零样本动作识别方法及系统的时序上的动作示例和互信息判别分数的示意图;
[0042]
图3为本发明基于互信息相似度的零样本动作识别方法及系统的训练和测试阶段
示意图。
具体实施方式
[0043]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。在下列段落中参照附图以举例方式更具体地描述本发明。根据下面说明和权利要求书,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
[0044]
需要说明的是,当组件被称为“固定于”另一个组件,它可以直接在另一个组件上或者也可以存在居中的组件。当一个组件被认为是“连接”另一个组件,它可以是直接连接到另一个组件或者可能同时存在居中组件。当一个组件被认为是“设置于”另一个组件,它可以是直接设置在另一个组件上或者可能同时存在居中组件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
[0045]
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
[0046]
如图1至图3所示,本发明提供了一种基于互信息相似度的零样本动作识别方法,包括以下步骤:
[0047]
s1,在零样本的动作分类任务中使用视频特征提取模块进行骨架动作特征提取;
[0048]
s2,利用语义特征提取模块对动作标签的语义信息进行特征化处理;
[0049]
s3,构建出语义特征和视频特征之间的非线性映射,同时设计出随帧数递增而互信息递增的互信息判别网络,以增强互信息对两类特征的判别能力。
[0050]
在零样本的骨架动作识别领域设计了一个累积互信息最大化的模块,利用互信息作为视觉特征和语义特征之间相似性的度量,从而构建两者的非线性统计关系。同时构建了一个时序互信息递增模块,保留了视觉特征的时序信息,进一步增强互信息判别网络的判别效果,提高了测试阶段对不可见类的分类准确率。该发明利用神经网络作来估计互信息,通过对比学习的方式,让相同类之间的互信息越来越大,不同类之间的互信息越来越小。互信息的估计网络通过最大化训练集内的可见类视觉特征向量和对应的语义向量来完成,在测试阶段,每一个输入的不可见类的视觉特征将会和所有的不可见类的语义向量计算互信息,选择互信息最大的语义向量标签作为分类结果。
[0051]
如图3所示,本发明基于互信息的零样本骨架动作识别模型存在训练和测试两个阶段。训练时的数据集中的类称为可见类,用于训练原始模型,测试时的类称为不可见类,用于测试准确率。可见类和不可见类不存在交集。整个模型分为三个部分:视觉特征提取部分、语义特征提取部分和相似度度量部分。相似度度量部分作为本发明的核心,旨在利用互信息的判别方法,衡量前两个部分获得的视觉特征和语义特征之间的距离。而互信息的相似度度量部分又分为两个模块,分别为整体互信息计算模块和局部互信息计算模块。
[0052]
视觉特征提取网络:
[0053]
采用论文“engfei zhang,cuiling lan,wenjun zeng,junliang xing,jianru xue,and nanningzheng.semantics
‑
guided neural networks for efficient skeleton
‑
based human action recognition.in proceedings of the ieee/cvf conference on computer vision and pattern recognition,pages 1112
–
1121,2020”里的sgn作为视觉特征提取的骨干网络。sgn把骨架序列作为输入,然后利用一个空间上的图卷积网络来整合节点信息,即3d节点坐标和节点运动的光流信息,两类信息被映射到同一维度后直接相加。为了进一步将语义信息集成到输入数据中,sgn利用节点层面的图卷积模块吸收节点类型信息并对节点依赖关系进行建模。最后一个帧层面的卷积模块用于将帧序号的信息也融入帧的信息中。以这种方式,sgn捕获到了同一时间内的空间和时序上的语义信息。以sgn为骨干网络提取到的视觉特征一共n帧记为其中f
i
为第i帧的特征,d是f
i
的维度,n是帧数。
[0054]
语义特征提取网络:
[0055]
本发明使用论文“matteo pagliardini,prakhar gupta,and martin jaggi.unsupervised learning of sentence embeddings using compositional n
‑
gram features.naacl
‑
hlt,2018.及bhavan jasani and afshaan mazagonwalla.skeleton based zero shot action recognition in joint pose
‑
language semantic space.arxiv preprint arxiv:1911.11344,2019”里提到的sent2vec作为语义特征提取器,输入的是骨架动作视频的类的标签,例如“standing up from sitting position”和“wear on glasses”。sent2vec对类似长短语的特征提取效果比word2vec等提取器效果更好。sent2vec将可见类和不可见类所有的标签转化为了700维的语义嵌入向量,这些向量作为本发明的外部语言知识库先存储起来。与一般的独热编码相比,这些经过sent2vec编码的语义向量具有更深层的语义信息,标签越接近则向量之间距离越短,否则距离越大。每个骨架序列的标签语义向量表示为y。
[0056]
互信息估计网络:
[0057]
如图1所示,本发明的基于互信息进行零样本骨架动作识别方法核心在于互信息估计网络,整个网络包含两个模块,一个是全局互信息计算模块,另一个是局部互信息计算模块。通过视觉特征提取网络和语义特征提取网络后,得到了对应的视觉特征向量x和语义向量y,在训练阶段,模型通过最大化两者之间的互信息来学习一个相似度的估计网络,从而获取两者间分布的距离:
[0058][0059]
其中d
kl
代表kl散度,x和y代表对视觉特征和语义特征两者分布的采样,p代表概率。然而在高维空间中很难直接计算两者的互信息,因此利用jensen
‑
shannon散度(jsd)“参考论文sebastian nowozin,botond cseke,and ryota tomioka.fgan:training generative neural samplers using variational divergence minimization.advances in neural information processing systems 29(nips 2016),pages 271
–
279,2016及r hjelm devon,fedorov alex,lavoie
‑
marchildon samuel,grewal karan,bachman phil,trischler adam,and bengio yoshua.learning deep representations by mutual information estimation and maximization.iclr,2019”利用神经网络t对互信息进行近
似。近似网络t将视觉特征x和y作为输入,输出为两者的相似性度量分数。在训练时通过最大化下述公式表示的jsd估计器来获取该近似网络:
[0060][0061]
其中,jsd估计网络利用了对比学习的方式,(x,y)作为正样本表示对应的视觉特征和语义特征,则表示负样本,输入的为同一个语义向量y和选取的另一个不对应的视觉特征其中,x和均采样自视觉特征分布v中,而y采样自语义特征分布l中,f
sp
表示soft
‑
plus函数,f
sp
(z)=log(1+e
z
)。
[0062]
全局互信息损失:
[0063]
提取出的视觉特征x=[f1,
…
,f
n
]∈r
d
×
t
,对时序维度直接进行最大值池化操作,得到x
n
=maxpool([f1,
…
,f
n
]),构建正样本对(x
n
,y),其中y为对应的语义向量。然后进行负采样,对另一个视觉特征的时序维度进行maxpool得到构建负样本将正负样本对输入互信息估计网络t中,得到对应的互信息估计分数c
n
。最终的全局互信息损失函数定义为l
g
=
‑
c
n
,通过训练过程不断优化损失,从而最大化视觉特征和对应语义特征之间的互信息,最终训练出一个优秀的互信息判别网络。
[0064]
局部互信息损失:
[0065]
对于视觉特征x=[f1,
…
,f
n
]∈r
d
×
t
,为了融合时序信息并进一步增强互信息近似网络的判别性,本专利提出了一个时序互信息递增的限定条件,并构建出了一个局部互信息的损失函数作为最终损失的补充。对于一个n帧的视觉特征x,我们考虑其前缀子序列x
k
=[f1,
…
,f
k
],k∈(1,n)。对每个前缀子序列进行maxpool后得到:
[0066]
x
k
=maxpool([f1,...,f
k
])
[0067]
同样的,对x
k
构建正负样本对(x
k
,y)和然后将正负样本送入互信息估计网络中获取互信息估计分数c
k
,c
k
表示前k帧的视觉特征向量与语义向量之间的互信息估计量。至此,我们获得了时序互信息列表c=[c1,c2,...,c
n
],为了充分利用骨架数据在时序部分的结构化信息,我们的目的在于增强互信息估计网络效用,使得随着帧数的增加,视觉特征和语义特征的互信息能够越来越大。局部互信息损失函数定义为l
l
:
[0068][0069]
最终结合全局互信息损失函数和局部互信息损失函数的损失函数定义为l:
[0070]
l=l
g
+αl
l
[0071]
α为控制整体互信息和局部互信息的比例超参数。
[0072]
在测试阶段,将测试集内不可见类的视觉特征x和所有的不可见类的语义特征y构建样本对(x,y),送入已经训练好的互信息近似网络t中,获取计算出的互信息,最后从中选择互信息最大的那个标签类作为预测标签。
[0073]
可选的方案,在三个数据集上评估本发明方法的性能:ntu60数据集(参考论文liu junfa,guang yisheng,and rojas juan.gast
‑
net:graph attention spatio
‑
temporal convolutional networks for 3d human pose estimation in video.2020),ntu120数据
集(参考论文bishay mina,zoumpourlis georgios,and patras ioannis.tarn:temporal attentive relation network for few
‑
shot and zero
‑
shot action recognition.bmvc,2019)和gast60数据集(参考论文kaat alaerts,evelien nackaerts,pieter meyns,stephan pswinnen,and nicole wenderoth.action and emotion recognition from point light displays:an investigation of gender differences.plos one,6(6):e20989,2011)。ntu60由微软的体感捕捉摄像机在室内进行拍摄获取,整个数据集包含56880个骨架序列数据,一共60个类,且由40个志愿者完成。每个人的骨架数据由25个节点表示,同时每个骨架视频的表演人数最多不超过两个。ntu120是在ntu60上做出的扩展,一共包含114480个骨架序列,120个类,且由106名不同的志愿者参与创造。gast60是在ntu60视频数据的基础上利用视频重建的三维姿态所合成的三维骨架数据集,重建方法为图注意力卷积神经网络(gast
‑
net(参考论文liu junfa,guang yisheng,and rojas juan.gast
‑
net:graph attention spatio
‑
temporal convolutional networks for 3d human pose estimation in video.2020)).在这个数据集中,每个人包含17个节点。gast60作为一个基准数据集,主要用于测试本专利方法在不同环境下的鲁棒性和泛化性。
[0074]
可见类和不可见类的分割:由于类与类之间存在着相似度的差异,不同的分割方式会对最终分类结果产生较大影响。因此我们对三个数据集采取了不同的分割方式。ntu60包含60个类,采取与论文“bhavan jasani and afshaan mazagonwalla.skeleton based zero shot action recognition in joint pose
‑
language semantic space.arxiv preprint arxiv:1911.11344,2019”相同的分割方式分为55个可见类用于训练和5个不可见类用于测试。为了更好的探究本专利方法的效用和泛化性能,我们按不同难度的分割方法来选取这5个不可见类。1、最近分割方式,选择的5个不可见类的语义向量与55个可见类的语义向量之间的平均距离最短。2、最远分割方式,与最近分割方式相反,选取的的不可见类与可见类之间的距离最远。3、随机分割方式,随机选择5个不可见类,为了保证实验的普遍性,我们一共取了5组随机分割实验,最终结果取平均值。在ntu60和gast60数据集上,也同样采取了5组随机分割实验取平均值的方式。其中,ntu120的不可见类个数为10%,即12个,gast60的不可见类个数与ntu60相同,为5个。
[0075]
采取和论文“pengfei zhang,cuiling lan,wenjun zeng,junliang xing,jianru xue,and nanning zheng.semantics
‑
guided neural networks for efficient skeleton
‑
based human action recognition.in proceedings of the ieee/cvf conference on computer vision and pattern recognition,pages 1112
–
1121,2020”相同的数据预处理方法,然后利用sgn作为视觉特征提取器。如果在骨架视频的一帧中同时出现了两个人,那么该帧会被分割为独立的两帧,每帧包含一个人。对于骨架序列的所有帧,我们均分为20个片段,然后在每个片段里随机取一帧提取出来。因此,在数据预处理之后,sgn的输入为20帧的骨架序列,每一帧包含25个3d的骨架节点坐标。sgn的预训练设置和上述论文相同,但预训练数据集为选定的可见类。
[0076]
对于互信息近似网络t,为了计算视觉特征和语义特征的相似度,输入t中的是视觉和语义特征的拼接张量。负样本的构造是通过对同一个批次的视觉特征进行向后移位构成,再与语义向量构成负样本对。整个网络t由三层的全连接层构成,并利用softplus激活
函数。最终输出一个标量表示对该批次数据的平均相似度分数。对于局互信息的计算,我们采样的选取前k帧的数据,然后对其时序维度进行max
‑
pooling操作,遵循局部互信息的损失,当且仅当第k+1帧的互信息小于第k帧的互信息,我们才将其差值加入损失函数中。超参数α设置为1。更多的参数设置请见表1。
[0077]
表1 训练时的超参数设置
[0078]
数据集ntu60ntu120gast60预训练sgn训练轮次8010080120学习率1e
‑
51e
‑
41e
‑
51e
‑
3权重衰减1e
‑
41e
‑
301e
‑5[0079]
本专利在ntu60、ntu120和gast60上跟当前最先进的零样本骨架动作识别方法作比较。分别为devise(论文andrea frome,s.gregory corrado,jonathon shlens,samy bengio,jeffrey dean,marc’aurelio ranzato,and tomas mikolov.devise:a deep visual
‑
semantic embedding model.nips,pages 2121
–
2129,2013)和relationnet(论文flood sung,yongxin yang,li zhang,tao xiang,philip hs torr,and timothy m hospedales.learning to compare:relation network for few
‑
shot learning.in proceedings of the ieee conference on computer vision and pattern recognition,pages 1199
–
1208,2018)。总体结果见表2和表3.所有的方法使用相同的类分割方法、视觉特征提取和语义特征提取均分别使用sgn和sent2vec。
[0080]
表2 ntu60数据集集下不同分割方法下的top1和top3分类准确率
[0081][0082]
表2展示了ntu60数据集下不同分割方式的不可见类测试分类结果。总体上看,最近分割方式的准确率是最高的,相反最远分割方式的准确率最低。在全局互信息和局部互信息融合损失的帮助下,本专利的方法在所有的三个分割方式中均取得了最高的准确率。在与两种基准方法做比较时,我们的方法获得了10%~20%的相对提升。特别的,当分割难度级别提升时,本专利的方法仍然比最好的基准方法表现要优秀(在最细微的分割上相对提高了10%)。这是由于本专利的方法并非直接利用投影而是学习骨架视觉特征空间和语义空间分布之间的非线性统计相关性,从而保留了更多的特征信息。
[0083]
图3定性的展示了本专利在测试过程中的分类结果。我们可视化了最远分割方法中五个不可见类的分类性能,我们的方法能够准确地做出了预测。如图3(a,b,c)所示,拍手和咳嗽的动作非常类似,本专利的方法不仅能做出正确预测,同时对类似的类能够做出何理的分数预测。类似的结论可以在图3的(d,e)中的双人场景中得到。
[0084]
表3 ntu120和gast60是数据集上的分类准确率
[0085][0086][0087]
表3展示了在ntu120数据集下的top1和top5测试集准确率以及gast60数据集下的top1和top3测试集准确率的结果。ntu120中不可见类一共12个(10%),与ntu60相比,虽然数据集变大且不可见类占比增加导致预测难度增加,本专利的方法仍然取得了最高准确率,且与devise相比获得了33.9%的相对准确率的提升。对于gast60数据集,作为由视频数据集人工生成的骨架数据集,gast60中每个人仅包含17个节点,因此在gsat60上的所有结果均比ntu60要低。这种人工生成的骨架节点会产生一定的噪声,从而影响sgn提取的视觉特征和语义特征之间的对应关系。但gast60上的结果显示,通过局部互信息和全局互信息的帮助,本专利的方法仍然比基准方法要优秀,这一步实验也进一步证实了本专利的方法也使用与视频生成的骨架数据集。
[0088]
表4 不同互信息组合的比较
[0089][0090]
表4通过在所有的三个数据集上的消融实验,证明了局部互信息损失的有效性。本专利方法中,局部互信息保证了随着考虑的帧数的增加,视觉特征和语义特征之间的互信息应该呈现递增的趋势,同时不对应的视觉特征和语义特征之间的互信息变得更小。表4中在ntu60数据集上,同时考虑两种互信息的设置使得最近分割和最远分割取得了0.59%~1.2%左右的相对准确率的提升。在gast60上,局部互信息的加入取得了2.6%左右的相对准确率的提升,而在ntu120上的提升为3%左右。通过上述实验,证实了局部互信息对最终分类结果有一定的增益效果。
[0091]
本发明实施例还提供了一种基于互信息相似度的零样本动作识别系统,包括视频特征提取模块、语义特征提取模块及基于互信息的特征相似度计算模块;所述视频特征提取模块用于在零样本的动作分类任务中对骨架动作特征进行提取;所述语义特征提取模块用于对动作标签的语义信息进行特征化处理;所述特征相似度计算模块用于构建出语义特征和视频特征之间的非线性映射,同时设计出随帧数递增而互信息递增的判别网络,以增强互信息对两类特征的判别能力。
[0092]
该系统所用方法及功能模块、系统等涉及到的过程载体和思路,均与前述的于互信息相似度的零样本动作识别方法一致,在此不再赘述。
[0093]
本发明与现有技术相比的有益效果是:(1)本发明提出的基于互信息的零样本骨架动作识别网络通过最大化视觉特征和语义特征之间的互信息来捕捉两者分布之间的非线性统计相关性,进而提高对不可见类的泛化效果(2)本发明提出的时序互信息递增模块保证了互信息在时序上的递增单调约束,从而使得时序信息融合进了互信息的判别网络之中,提升了网络的判别效果(3)在三个基准数据集上的大量实验表明,本发明的基于互信息相似度度量结合时序互信息递增模块的方法,与其他零样本的骨架动作识别方法相比具有更好的性能,表明了该方法在零样本的骨架动作识别任务中的有效性和前景。
[0094]
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0095]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1