一种对不同图像分辨率鲁棒的人脸表情识别方法
1.本发明属于图像识别领域,设计一种人脸表情识别方法。
背景技术:
2.人脸表情识别是人脸识别技术的重要组成部分,近年来,在人机交互、自动驾驶、精准营销、课堂教学等领域得到了广泛应用,成为学术界和工业界的研究热点。根据特征提取方法的不同,人脸表情识别技术大致可以分为两种方法:手工特征提取方法和基于深度学习的特征提取方法。
3.常用的手工特征提取方法有gabor小波、局部二值模式(local binary pattern,lbp)
1.、局部定向模式(local directional pattern,ldp)
2.等。传统的人脸特征提取方法虽然取得了一定的效果,但其缺点是容易受到环境因素的干扰,而基于深度学习的表情识别方法可以自动提取面部特征,提高了表情识别的准确率。
4.然而目前的方法输入图片大小大多为224
×
224或某一个固定大小。然而,在现实世界中,根据人脸与摄像头的距离不同,拍摄到的人脸图像的分辨率是不同的,因此,在实际应用中要求系统能够处理不同分辨率的输入图像。
技术实现要素:
5.本发明的目的是提供一种对不同图像分辨率鲁棒的人脸表情识别方法。本发明采用的技术方案是:
6.一种对不同图像分辨率鲁棒的人脸表情识别方法,其特征在于,包括下列步骤:
7.s1、对待识别的含有人脸的图片进行人脸检测,提取出人脸区域保存为人脸图像;
8.s2、将人脸图像缩放到h
×
w个像素大小,然后输入到基于多尺度的深浅层特征融合网络中,进行特征提取,得到特征向量,方法如下:
9.s21、采用双线性插值法对人脸图像进行缩放,得到尺寸为c
×
h
×
w的人脸图像
10.s22、将f输入到ghostnet主干网络中,经过卷积操作得到深层特征图
11.s23、然后采用双线性插值法将人脸图像缩放为再将f1输入到浅层网络中,得到浅层特征图
12.s24、将f
s1
和f
d1
在通道维度上级联,生成深浅层特征融合后的特征图
13.s25、采用基于两步法的通道注意力模块,对级联后的特征图f
sd1
中的通道信息进行编码,得到通道注意力图mc,并将其与级联特征图f
sd1
逐元素相乘,得到加权特征图
14.s26、按照s22~s25的步骤,将f
w1
输入到后续ghostnet主干网络中进行卷积操作,
得到深层特征图然后将人脸图像f缩放为并输入到浅层网络中,得到浅层特征图再将f
s2
和f
d2
级联,得到深浅层特征融合后的特征图f
sd2
;最后通过通道注意力模块对f
sd2
进行加权得到特征图
15.s27、按照s26的步骤,得到再将f
w3
输入到后续ghostnet主干网络中进行特征提取;
16.s3、将提取出的特征向量输入到softmax层中进行分类。
17.所述步骤s25具体为:
18.s251、通过平均池化和最大池化来聚合特征图f
sd1
的空间信息,得到两个输出特征图和
19.s252、将f
avg1
和f
max1
输入到无填充的3
×
3卷积层中,得到两个特征图和
20.s253、将f
avg2
和f
max2
输入到一个1
×
1卷积层后,将两个输出特征图逐元素相加得到合并后的特征图
21.s254、采用sigmoid函数对f
merge
进行激活,得到通道注意力图mc;具体计算过程如下所示:
22.s255、将特征图f
sd1
与mc逐元素相乘,得到加权特征图f
w1
。
23.本发明的优势在于:
24.1.设计了一个多尺度特征提取模块,充分提取图像中不同尺度的特征,提高了不同分辨率下图像的识别精度。
25.2.提出了一种深浅层特征融合模块,充分提取图像的浅层特征,减少信息丢失,提高了特征提取能力。
26.3.设计了一种基于两步法的通道注意力模块,与现有的基于一步法的通道注意力模块相比,该模块具有更强的通道权重学习能力。
附图说明
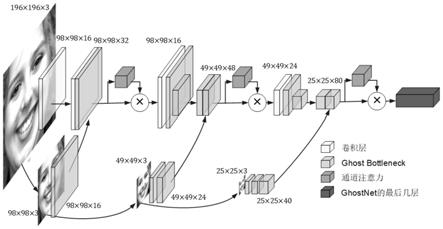
27.图1为基于多尺度的深浅层特征融合网络整体结构图。
28.图2为多尺度特征提取模块结构示意图。
29.图3为基于两步法的通道注意力模块结构示意图。
30.图4为预处理后的人脸表情图片。
具体实施方式
31.为使本发明的技术方案以及优点更加详细清楚,下面将结合附图对本发明中的技术作进一步阐述。具体实施方式有以下步骤:
32.(1)人脸检测与预处理
33.首先通过dlib库进行人脸检测,裁剪出通过摄像头采集到的图像中的脸部区域并缩放到h
×
w个像素大小,然后将图像的三个通道合并,保存为灰度图,再将图像广播到三通道。其中,采用双线性插值法对脸部区域进行缩放,得到人脸图像缩放后的图片中像素点(x,y)处的像素值计算公式如下:
[0034][0035]
其中pij(i,j∈{1,2})表示像素点(x
i
,y
j
)处的像素值。
[0036]
(2)网络整体结构
[0037]
本发明提出了一种基于多尺度的深浅层特征融合网络。该网络致力于充分提取原始图像中不同尺度的浅层特征,并将其与深层特征融合,然后通过通道注意力模块给级联后的特征图的不同通道添加不同的权重,进一步增强特征提取能力。
[0038]
网络的上半部分是基于最新的轻量化网络ghostnet的主干网络。首先将人脸图像输入到主干网络中,经过一系列卷积操作得到深层特征图(式中的除法采用进一法,即若无法整除,则结果取整数部分加1,下同)。网络的下半部分有三个分支,分别将原图缩放到三个不同的尺寸,然后输入到三个分支网络中,得到三个不同尺寸的浅层特征图将f
s1
和f
d1
在通道维度上级联,生成深浅层特征融合后的特征图然后采用基于两步法的通道注意力模块,对级联后的特征图f
sd1
中的通道信息进行编码,得到通道注意力图mc,并将其与级联特征图f
sd1
逐元素相乘,得到加权特征图再将f
w1
输入到后续ghostnet主干网络中进行卷积操作,得到深层特征图然后将f
s2
和f
d2
级联,得到深浅层特征融合后的特征图f
sd2
。最后通过通道注意力模块对f
sd2
进行加权得到特征图通过类似的方式,得到再将f
w3
输入到后续ghostnet主干网络中进行特征提取和分类。
[0039]
这种结构的优点在于可以缓解卷积层数增加时梯度消失的问题。这主要借鉴了resnet中残差模块的思想,即特征图x被输入到几个卷积层中,生成特征图f(x),然后将x与f(x)相加作为新的特征图h(x)。这里的x即对应于所提出网络中的浅层特征图f
s1
,f
s2
和f
s3
,f(x)对应于深层特征图f
d1
,f
d2
和f
d3
,h(x)对应于深浅层特征融合后的特征图f
sd1
,f
sd2
和f
sd3
,不同之处是所提出的方法将深浅层特征图在通道维度上堆叠而不是简单地相加,保留了更多信息。
[0040]
(3)多尺度特征提取
[0041]
多尺度特征提取被广泛应用于目标检测领域,以获取不同大小的感受野,从而检测图像中不同大小的物体。也有研究人员将其用于分类领域。现有的方法大都采用不同大小的卷积核提取不同尺度的特征,然后将提取出的特征相加或堆叠。但对于计算而言,使用较大的空间滤波器(如5
×
5或7
×
7)进行卷积意味着较高的计算成本。例如,使用5
×
5的卷积核的计算量是3
×
3卷积核计算量的25/9=2.78倍。
[0042]
为了解决这一问题,本发明提出了一种新的多尺度特征提取方法。现有的方法采用3
×
3的卷积核提取出较小的感受野中的特征,5
×
5的卷积核提取出较大的感受野中的特征,然后再将两个不同尺度的特征堆叠,实现多尺度特征融合。本发明所提出的多尺度特征提取方法,包含两个分支,其中左分支同样采用3
×
3的卷积核提取较小感受野中的特征,右分支先将输入缩放到较小的尺度,这样使用3
×
3的卷积核也能获得较大的感受野。因而可以大大减少参数量,加快训练速度。
[0043]
(4)通道注意力模块
[0044]
为了计算通道注意力,需要将每个通道内部的全局空间信息压缩到一个通道描述符中。迄今为止,为了汇总空间信息,通常采用平均池化或最大池化一次性地将每个通道上的所有空间特征编码为一个全局特征,即将特征图的尺寸从c
×
h
×
w直接压缩到c
×1×
1(c表示特征图的通道数,h表示高,w表示宽)。经典的挤压激励模块(squeeze
‑
and
‑
excitation block,se block)和卷积块注意力模块(convolutional block attention module,cbam)都是采用这种方式。然而,这种暴力的编码方式会损失较多的信息,从而使学习到的注意力不准确。为了解决这个问题,本发明提出一种分两步汇总空间信息的方法,可以更加精细地编码空间特征,从而使学习到的通道注意力更加具有代表性。具体方法为:
[0045]
首先通过平均池化和最大池化来聚合特征图f
sd1
的空间信息,得到两个输出特征图和即先将输入特征图缩放到c
×3×
3而不是c
×1×
1,因此保留的空间信息是原来的9倍,以便于进一步学习空间特征。然后将f
avg1
和f
max1
输入到无填充的3
×
3卷积层中,得到两个特征图和以进一步聚合空间信息。再将f
avg2
和f
max2
输入到一个1
×
1卷积层后,将两个输出特征图逐元素相加得到合并后的特征图为减少参数量,3
×
3卷积层和1
×
1卷积层对每个特征图是共享的。最后采用sigmoid函数对合并后的特征图进行激活,就得到了通道注意力。总之,通道注意力的计算过程为:
[0046]
mc=σ(k1×1*(k3×3*avgpool(f
sd1
))+k1×1*(k3×3*maxpool(f
sd1
)))
[0047]
其中,k
n
×
n
表示n
×
n大小的卷积核;σ表示激活函数。
[0048]
最后,需要将输入特征图f
sd1
与得到的通道注意力mc逐元素相乘,就得到了加了权重的特征图f
w1
。
[0049]
(5)分类
[0050]
将神经网络提取到的二维特征展平为一维特征向量,再将特征向量的长度映射为n(n一般为6,表示分类为愤怒,厌恶,恐惧,幸福,悲伤和惊讶6种表情,若增加一种中性表情则n为7),最后将提取出的特征向量输入到softmax层中进行分类。计算过程为:
[0051][0052]
其中,z
j
是长度为n输入特征向量,f(zj)为预测为某一类的概率值。
[0053]
本发明其他未详述之处均为本领域技术人员的常识性技术。
[0054]
综上所述,本发明针对输入图像分辨率变化的问题,提出了一种更加鲁棒的人脸表情识别方法。本领域的相关技术人员可依照本思路对其中的参数或结构做出些许的改动,进而进一步提高人脸表情识别的准确率,但任何依据本发明的技术实质对以上实施案例进行的简单修改与等效变换等,均仍属于本发明的技术范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1