一种针对互联网直播异常行为的智能检测系统
1.本发明涉及视频及图像处理领域,尤其涉及一种互联网直播异常行为的智能检测系统。
背景技术:
2.目前传统的网络监管机制仍然更多依赖于人工审查,通过各个平台设立的审查部门来人工地判断是否存在违法违规等异常行为信息。通常情况下待审核的对象包括文本、图片、视频和语音等。其中图像内容的人工审查效果是最好的,这是由于图形是人们视觉上最基本的感受,直观地映射了客观自然景象。而文字内容的审查难度会随着文章篇幅的增多而大幅提升,为了对文章内容进行全面地审查,审查员不得不通篇阅读,即使全文绝大多数内容都没有违背审查要求,也可能存在某一句话违背法律法规,向民众传播不良影响。语音内容与文字内容类似,需要通篇播放才能完成审查。而视频内容则是文字、语音类内容与图像内容的折中。和文字、语音类内容相似,其审查难度与视频长度成正相关但对审查员阅读的专注度要求却低于文字类内容,通过快速浏览视频内容,即可完成对视频内容审查是否符合要求的判断。与视频同一机制的还有当下比较热门的网络直播,直播的特点是实时性较强,因此如要人工监管需要长时间的观看直播,这些传统的基于人工审查的网络监管方法虽然对内容是否违规可以做到高置信度的判断,但既耗费了大量人力资源也显得低效。
3.随着深度学习技术的出现与发展,利用深度学习对网络上的不良信息进行筛查成为当前比较热门的趋势,针对文本、图像的各类模型层出不穷,通过对其进行微调修改用于识别异常信息,都有更为良好的效果,同时不依赖人工,极大程度的解放了人力。
4.目前,对于互联网直播异常行为的检测一般是由人工对异常行为进行筛选,然后对异常直播视频及主播进行保存。这种方法在实际应用中存在以下问题:
5.1、需要人工24小时不间断的对互联网直播进行监测,数据量大、时效性及准确性难以保证;
6.2、直播视频的筛选过程,主播异常行为的保存均由人工完成,操作质量难以保证,可能引入主观误差;
7.3、利用人工对互联网直播异常行为进行监测,时间成本和人工成本高,已经不能适应当前复杂的直播状况;
8.因此,利用深度学习对网络上的不良视频内容进行筛查要更具有效率,同时能解放人力资源,使其从事更具有创造性和发展前景的岗位。基于计算机处理以及人工智能等技术有效结合的互联网直播异常行为智能检测系统的开发和研制,具有重要的研究价值和研究意义。
技术实现要素:
9.本发明的目的在于针对现有技术存在的成本高、时效性和准确性差等缺点,提供
一种针对互联网直播异常行为的智能检测系统,具有节约人力成本,稳定性高,操作简单、实时性好的优点。为实现上述目的,本发明设计了一种针对互联网直播异常行为的智能检测系统,能够实时、准确地对互联网直播视频中的异常行为如枪支、穿着暴露、敏感肢体动作等行为进行检测和识别;
10.本发明为实现上述目的所采用的技术方案是:
11.一种针对互联网直播异常行为的智能检测系统,在服务器上设置以下模块:视频采集模块、视频解析模块、异常行为检测模型模块、实时视频异常检测模块,建立用于异常行为判别的网络模型并实际采集网络上的实时视频进行异常行为判定:
12.所述视频采集模块,用于获取互联网直播平台的视频数据;
13.所述视频解析模块,用于将采集的视频流逐帧处理为图像数据,并通过稀疏采样视频帧的方式对视频进行抽帧处理,获取单帧采样图像;
14.所述异常行为检测模型模块,包括建立异常图像样本集,建立异常行为网络模型,利用异常图像样本集数据对异常行为网络模型进行训练,优化网络模型参数及异常判别阈值;
15.所述实时视频异常检测模块,用于存储实时异常行为检测步骤,利用异常行为检测算法调用训练好的异常行为网络模型对互联网直播视频进行实时检测,若超过异常判别阈值则判断直播视频存在异常行为。
16.所述异常图像样本集为对视频解析模块获取的单帧采样图像通过人工判别异常并标记,再按比例分成训练集、验证集和测试集。所述训练集用于训练,验证集用于验证并通过判别概率结果反向传播调整网络参数,所述测试集用于测试。
17.所述异常行为网络模型结构包括:卷积神经网络、全连接层、输出层;
18.所述卷积神经网络,包括若干个resnet152残差块,用于提取预先标记的单帧异常图像的异常特征;
19.所述全连接层,用于对异常图像的异常特征进行降维并输出至输出层;
20.所述输出层,采用softmax分类器,用于根据异常特征计算是否为异常图像的判别概率。
21.所述输出层输出的判别结果包括:异常视频时间time、判别结果result和判别概率probability。
22.所述训练时是将训练集数据分批次输入模型,对当前该批次异常图像给出判别概率。
23.是将异常图像样本集数据输入模型反复迭代,从而优化网络模型参数及异常判别概率阈值。
24.所述稀疏采样视频帧的的间隔为10s。
25.所述实时异常行为检测步骤包括:
26.服务器的视频采集步骤,采集互联网直播平台的视频数据;
27.服务器的视频解析步骤,将采集的视频流逐帧处理为图像数据,并通过稀疏采样进行抽帧处理,获取单帧采样图像;
28.实时视频异常检测步骤,利用异常行为检测算法调用训练好的异常行为resnet152网络模型,提取特征后最后送入全连接层,然后通过softmax函数计算判定概率,
最终输出判别结果,对互联网直播视频进行实时检测,判断直播视频是否存在异常行为。
29.本发明具有以下有益效果及优点:
30.1.本发明采用基于深度学习残差网络的目标检测算法,并进行数据采集,在此基础上进行训练,有效地提高了对直播中异常行为检测的准确率,而采用训练好的模型进行实时跟踪监测,保证了检测系统的实时跟踪监测特性。
31.2.本发明利用晚期特征融合的目标检测算法,把相距一定距离的两帧进行特征抽取,将抽取后的特征在最后一层进行全连接。方法独特,能抽取到远距离相关度信息。
32.3.采用resnet预训练残差网络进行视觉特征抽取,内部通过跳跃连接有效缓解了深度神经网络中存在的梯度消失问题,本模型可以拓展到更深层,且泛化性较好。
33.4.本系统操作简单,识别准确率较高,在当今直播盛行的年代,适合大面积推广应用。
附图说明
34.图1为本发明总体流程图;
35.图2为本发明中模型结构图;
36.图3(a)为本发明中resnet 34模型的残差模块结构图;
37.图3(b)是为本发明中resnet152模型的残差模块结构图。
具体实施方式
38.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方法做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但本发明能够以很多不同于在此描述的其他方式来实施,本领域技术人员可以在不违背发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施的限制。
39.除非另有定义,本文所使用的所有技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
40.异常行为图像包括:枪支、穿着暴露等违反法律或社会公德的行为。例如枪支可以通过输入包含枪支的图像为样本图像输入模型结构,提取枪支轮廓作为特征模板,用于训练。针对视频中穿着暴露等行为,采用视觉特征肤色占比进行识别训练。
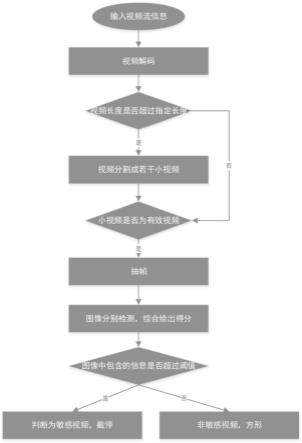
41.所述的智能检测系统内安装有:基于深度学习的异常动作识别模型和训练好的模型权重参数。所述的智能检测系统内安装有:采集异常及正规直播平台视频数据的视频采集程序。所述的智能检测系统内安装有:将视频流处理成图像数据的视频解析程序。所述的智能检测系统内安装有:视频异常行为检测程序。所述的智能检测系统内安装的识别模型是基于深度学习的异常行为识别模型。
42.所述基于深度学习的异常行为识别模型采用卷积神经网络模型和大规模图像数据集预训练模型。
43.所述的智能检测系统内安装的模型权重参数是利用互联网直播平台正规和异常视频流数据对检测模型进行训练获得的。
44.所述智能检测系统内使用的视频采集程序是对互联网平台公开分享的视频流数
据进行搜集。所述智能检测系统内使用的视频解析程序,能够对视频流逐帧处理成图像数据,并且利用稀疏采样方式压缩解析量。所述智能检测系统内使用的视频异常行为检测程序,将视频解析程序处理得到的关键视频帧图像作为输入,使用深度学习神经网络模型进行识别检测,最终的输出是输入视频是否异常。
45.下面结合图1,对本发明所述异常视频的检测流程进行详细描述。
46.本发明采用基于深度学习的视频异常行为检测模型。利用视频采集程序在互联网平台获得公开可使用的直播视频数据集,利用上述异常动作对识别检测模型进行训练,并将训练好的模型权重参数保存在服务器,用于对视频异常行为的检测。
47.首先由视频解析程序对输入的互联网直播平台视频流信息进行解码。在解码阶段,需要判断视频长度是否超过设定长度阈值,如果超过指定长度则将视频分割为多个符合长度的短视频数据,进入下一步。如果视频长度没有超过指定长度,则直接进入下一步。采用稀疏采样视频帧方式对视频进行抽帧处理,得到解码图像。
48.将解码的图像加载到基于深度学习的异常动作识别模型进行视频信息异常情况的检测。
49.下面结合图2,对图1中的异常行为检测算法进行详细描述。
50.视频解析程序对输入的互联网直播平台视频流信息进行解码。在解码阶段,需要判断视频长度是否超过阈值,如果超过指定长度则将视频分割为多个符合长度的短视频数据,进入下一步。
51.如果视频长度没有超过指定长度,则直接进入下一步。
52.采用稀疏采样视频帧方式对视频进行抽帧处理,得到解码图像。
53.将解码的图像加载到基于深度学习的违规动作识别模型进行视频信息违规情况的检测:经过解码处理后的图像数据输入基于大规模图像数据集的预训练模型resnet,抽取出视觉特征。然后在高层对时间维度特征进行晚期融合,将远距离关键帧图像输入两个卷积神经网络提取特征后,再连接到同一个全连接层,有效利用远距离视频帧相关度和视频的全局特征。最后传递给softmax层计算视频含有敏感信息的概率。其中视频时间以10s为间隔单位,判别结果包含正常和非正常两种,判别概率表示是这一结果的概率,当其数值大于0.5时判定视频存在异常行为
54.下面结合图3,对基于卷积神经网络构建的视频异常行为识别模型中的resnet网络残差块结构进行详细描述。
55.图3(a)是resnet34,图3(b)是resnet152,整个结构被称为”building block”,其中图3(b)又被称为”bottleneck design”,目的是为了降低参数的数目。实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1+3x3+1x1,如右图所示。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64+3x3x64x64+1x1x64x256=69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目:3x3x256x256x2=1179648,差了16.94倍。
56.对于常规resnet,可以用于34层或者更少的网络中,对于bottleneck design的resnet通常用于更深的如101这样的网络中,目的是减少计算和参数量。
57.以上说明所描述的实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变换和改进。这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1