一种基于集群架构的分布式可扩展模拟计算方法
1.本发明涉及脉冲神经网络领域,具体涉及一种基于集群架构的分布式可扩展模拟计算方法。
背景技术:
2.以数学模型实现的神经元为基本元素,以依靠突触在神经元间传输信息的脉冲数据为信息媒介,所组成的脉冲神经网络(spiking neural network,snn)因其类似生物神经元活动特性而具有生物合理性,被称为继深度人工神经网络(artificial neural network,ann)后的下一代人工神经网络。与生物神经元活动过程相同,snn中的神经元彼此以神经突触相连,神经元间突触以权值大小来表示连接关系的强弱,脉冲以神经突触为桥梁在神经元间进行信息传递。在每个生物周期内,某些神经元因为上一周期其膜电位超过了自身阈值电位而发放脉冲,再由神经突触传递至其他神经元,接收到脉冲信息的神经元会依靠自身动力学方程更新神经元状态,进而决定发放脉冲与否,本周期所产生的脉冲又会在下一周期作用于接收到脉冲信息的神经元。上述过程即为snn的模拟仿真过程。决定snn模拟仿真效率的关键部分,即是snn网络中神经元的模拟计算过程。在大规模snn网络模拟仿真中,神经元数量庞大,snn网络模拟仿真耗时也会随之大幅增加,而减少模拟仿真耗时的关键就在于如何提升单位时间内进行模拟计算过程的神经元的数量。
3.现有的实现方案需要特定芯片硬件支持,不具备普适性,不利于推广发展,且在缺少相关特定硬件支持的情况下,无法实现脉冲神经网络的快速模拟仿真。
技术实现要素:
4.本发明的目的是提供一种基于集群架构的分布式可扩展模拟计算方法,用于实现脉冲神经网络计算机集群中大规模snn网络的接近生物神经元的周期的快速实时模拟仿真。
5.为了实现上述任务,本发明采用以下技术方案:
6.一种基于集群架构的分布式可扩展模拟计算方法,包括以下步骤:
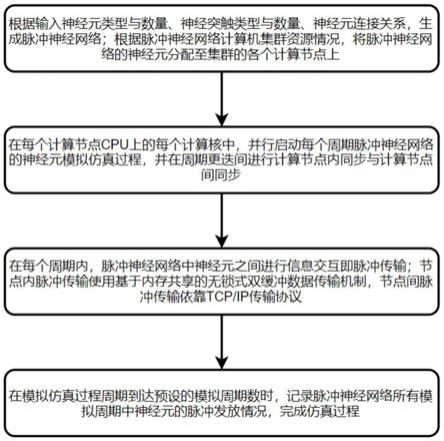
7.根据神经元类型与数量、神经突触类型与数量、神经元连接关系,生成脉冲神经网络;根据脉冲神经网络计算机集群资源情况,将脉冲神经网络的神经元分配至集群的各个计算节点上;
8.在每个计算节点cpu上的每个计算核中,并行启动每个周期脉冲神经网络的神经元模拟仿真过程,并在周期更迭间进行计算节点内同步与计算节点间同步;
9.在每个周期内,脉冲神经网络中神经元之间进行信息交互即脉冲传输;节点内脉冲传输使用基于内存共享的无锁式双缓冲数据传输机制,节点间脉冲传输依靠tcp/ip传输协议;
10.在模拟仿真过程周期到达预设的模拟周期数时,记录脉冲神经网络所有模拟周期中神经元的脉冲发放情况,完成仿真过程。
11.进一步地,所述将脉冲神经网络的神经元分配至集群的各个计算节点上,包括:
12.在开始每周期的神经元活动过程模拟前,集群内的计算节点根据自身节点编号获取对应神经元节点的配置信息与突触连接信息,随后各计算节点在内存中创建相应数量神经元的神经元组,所有计算节点的神经元统一全局编号,而神经元之间的连接关系即突触与突触权值则载入内存中,供以cpu读取与使用;随后,本计算节点的神经元根据该计算节点的多cpu的核数量进一步划分每个计算核需要负责的神经元。
13.进一步地,每个计算节点根据分配到该计算节点内的任务创建主进程,用于创建多个线程作为神经元模拟仿真过程中的各类任务的执行者,包括计算线程组、路由线程组与网络线程组并进行线程与计算核的绑定。
14.进一步地,所述计算线程组用于负责执行模拟仿真神经元的逻辑运算与状态更新的过程;计算线程组中的各个计算线程首先接收路由线程组转发的内部脉冲数据以及网络线程组转发的外部脉冲数据,针对各脉冲获取需要外部电流的神经元编号,添加权值到神经元的外部电流,随后每个计算线程内所有神经元的动力学方程,更新本计算线程所负责的所有神经元状态,获取本周期神经元发放的脉冲,放入路由线程缓冲区;
15.路由线程组负责执行用于神经元之间信息传递的脉冲数据的流向处理任务,决定脉冲数据的流向,处理脉冲信息通信任务;各个路由线程需要平均地获取由计算线程组、网络线程组存放至路由线程组缓冲区的脉冲数据,根据缓冲区数据长度和路由线程数进行均分,若均分后存在剩余数据则将其交予最后一个路由线程;随后,各个路由线程根据获取到的脉冲数据确定脉冲数据流向本计算节点内或是流向外部计算节点;
16.所述网络线程组包括发送线程和接收线程,用于处理每个模拟仿真周期节点间的脉冲信息传输任务以及所有节点的周期同步任务;其中,发送线程负责发送经路由线程处理后的脉冲数据至其他计算节点,期间发送线程需要通过同步信号包控制计算节点间的周期一致;接收线程负责接收计算节点外部脉冲数据,并转存至路由线程组以供后续处理。
17.进一步地,在周期更迭间进行计算节点内同步,包括:
18.计算节点内同步机制即线程之间同步机制,其依靠由主进程创建的所有线程可共享的全局变量实现:所有线程均可无条件获取全局变量,但是全局变量值的变化需要依靠原子操作函数;当存在两个线程同时对同一全局变量进行写入时,会产生冲突现象,原子操作函数使得在某个时间点上的某个全局变量有且仅有一个线程能够对其进行写入修改,其他线程会暂时阻塞等待完成。
19.进一步地,在周期更迭间进行计算节点间同步,包括:
20.在进入周期模拟过程前,设置一个主计算节点,其余计算节点作为从计算节点,每个计算节点都要维护一个flag变量;随后,主计算节点释放开始信号包,开始其运行任务,从计算节点则在收到开始信号包后进入运行任务;
21.当计算节点任务结束后,每个计算节点都会进入while循环等待接收其余节点的结束信号包,该信号包附带发送者的节点编号信息;根据计算节点编号信息,各计算节点将flag对应位置1,直至flag=预设值表明三个节点本周期任务已完成,可以将flag值清零,等待主计算节点开始信号包,开始下一周期。
22.进一步地,所述无锁式双缓冲数据传输机制,包括:
23.数据发送过程为:在t0周期,dbuffer_sw值为0,计算线程组在进行神经元计算更
新过程后将本周期产生的脉冲数据临时存于w.outbuf0中,等待计算更新过程结束后,位于w.outbuf0的脉冲数据将一并拷贝至routebuf0内;随后在t1周期,dbuffer_sw值为1,路由线程组开始读取routebuf0中上一周期的脉冲数据并进行脉冲数据分流;流往节点内的脉冲存至workerbuf,发向w.inbuf1,流往节点外的脉冲存至networkbuf,发向n.inbuf0;最后在t2周期,dbuffer_sw值为0,网络线程组中的发送线程开始读取n.inbuf0,拷贝socket发送缓冲区进行转发任务;
24.其中:当前周期为t0周期,下一周期为t1周期;dbuffer_sw为所有双缓冲区编号,取值范围为0或1;w.outbuf0表示本周期t0计算线程组的脉冲数据发送缓冲区;routebuf0表示t1周期路由线程组计算线程组的脉冲数据读取处理缓冲区;workerbuf为t1周期路由线程组临时存放内部脉冲数据缓冲区;w.inbuf1为t1周期接收由workerbuf而来脉冲数据的计算线程组的数据读取缓冲区;networkbuf为t1周期路由线程组临时存放外部脉冲数据缓冲区;
25.n.inbuf0为t1周期接收由networkbuf而来脉冲数据的网络线程组的数据发送缓冲区。
26.进一步地,所述无锁式双缓冲数据传输机制,还包括:
27.数据接收过程为:在t0周期,dbuffer_sw值为0,网络线程组中的接收线程会拷贝socket接收缓冲区中外部节点发往本节点的脉冲数据至n.inbuf0,发向outnetbuf0;随后在t1周期,dbuffer_sw值为1,路由线程组开始读取outnetbuf0中上一周期的脉冲数据并进行脉冲数据筛选;流往节点内的脉冲存至workerbuf,发向w.inbuf1,其余脉冲数据进行丢弃,最后在t2周期,dbuffer_sw值为0,计算线程组在神经元计算更新过程中,读取w.inbuf1中的脉冲数据,判断脉冲数据是否对本线程神经元有影响,并将此影响作用至神经元的状态更新过程。
28.与现有技术相比,本发明具有以下技术特点:
29.1.本发明据分布式并行计算原理,使用分布式多线程技术将脉冲神经网络的神经元整体分散到各个线程中,多线程并行模拟仿真,使得脉冲神经网络计算机具备生物实时模拟性能,实现脉冲神经网络的快速实时模拟仿真。
30.2.本发明通过脉冲神经网络计算机集群,以及基于集群架构的分布式可扩展模拟计算方法,可以在缺少相关特定硬件支持的情况下合理利用已有计算资源实现脉冲神经网络的快速模拟仿真的目的,降低使用门槛,利于推广发展。
附图说明
31.图1为本发明方法的流程示意图;
32.图2为单cpu轮询与多core轮询示意图;
33.图3为计算线程任务流程图;
34.图4为路由线程任务流程图;
35.图5为发送线程任务流程图;
36.图6为接收线程任务流程图;
37.图7为计算节点内线程周期同步机制;
38.图8为计算节点间线程周期同步机制;
39.图9为线程间数据流向示意图;
具体实施方式
40.本发明应用于脉冲神经网络计算机上,提供一种多cpu节点集群下高并行度的扩展性良好的模拟计算方法,使得脉冲神经网络计算机具备生物实时模拟性能,实现脉冲神经网络的快速实时模拟仿真。
41.参见附图1,本发明的一种基于集群架构的分布式可扩展模拟计算方法,包括以下步骤:
42.步骤1,根据输入神经元类型与数量、神经突触类型与数量、神经元连接关系,生成脉冲神经网络;根据当前脉冲神经网络计算机集群资源情况,将脉冲神经网络的神经元分配至集群的各个计算节点上。
43.在每个生物神经元周期内,cpu需要轮询每个神经元,检测神经元是否收到脉冲信息,并据此通过计算更新各个神经元的状态,获得下一个周期神经元的脉冲的发放情况。当脉冲神经网络规模较大,网络中包含的神经元数量较大时,在cpu对单个神经元进行状态更新过程所需时间固定的情况下,每个周期内cpu轮询神经元所需时间也就越长。
44.如图2所示,多core独立并行轮询神经元相比单cpu串行轮询神经元,既合理充分利用了多核cpu的计算资源,又有效节省轮询时间。因此,本方法根据分布式并行原理,将脉冲神经网络中的神经元自适应分配到每个计算节点的每个计算核内,每个计算核用于平均分配本cpu上的神经元,分别轮询,通过计算更新进行神经元的状态。具体自适应分配方法如下:在开始每周期的神经元活动过程模拟前,集群内的计算节点需要根据自身节点编号获取对应神经元节点的配置信息与突触连接信息,随后各计算节点在内存中创建相应数量神经元的神经元组,所有计算节点的神经元统一全局编号,而神经元之间的连接关系即突触与突触权值则载入内存中,供以cpu读取与使用;随后,本计算节点的神经元根据该计算节点的多cpu的核数量进一步划分每个计算核需要负责的神经元。
45.步骤2,在每个计算节点cpu上的每个计算核中,并行启动每个周期脉冲神经网络的神经元模拟仿真过程,并在周期更迭间进行计算节点内同步与计算节点间同步。
46.在单计算节点内,本方案根据分配到本计算节点内的任务首先创建主进程(master process),它并不处理具体的计算及脉冲信息通信任务,而是只负责创建多个线程作为神经元模拟仿真过程中的各类任务的执行者,如计算线程组、路由线程组与网络线程组并进行线程与计算核的绑定。
47.如图3所示,计算线程组(worker threads)主要负责执行模拟仿真神经元的逻辑运算与状态更新的过程。各个计算线程首先接收路由线程组转发的内部脉冲数据以及网络线程组转发的外部脉冲数据,针对各脉冲获取需要外部电流的神经元编号,添加权值到上述神经元的外部电流,随后每个计算线程内所有神经元的动力学方程,更新本计算线程所负责的所有神经元状态,获取本周期神经元发放的脉冲,放入路由线程缓冲区。
48.如图4所示,路由线程组(router threads)主要负责执行用于神经元之间信息传递的脉冲数据的流向处理任务。决定脉冲数据的流向,处理脉冲信息通信任务。各个路由线程需要平均地获取由计算线程组、网络线程组存放至路由线程组缓冲区的脉冲数据,即根据缓冲区数据长度和路由线程数进行均分,若均分后存在剩余数据则将其交予最后一个路
由线程。随后,各个路由线程根据获取到的脉冲数据确定脉冲数据后续,即脉冲数据流向本计算节点内或是流向外部计算节点。
49.如图5、6所示,网络线程组(network threads)包括发送线程(send thread)和接收线程(recv thread),主要负责处理每个模拟仿真周期节点间的脉冲信息传输任务以及所有节点的周期同步任务。发送线程负责发送经路由线程处理后的脉冲数据至其他计算节点,期间发送线程需要通过同步信号包控制节点间的周期一致;接收线程负责接收节点外部脉冲数据,并转存至路由线程组以供后续处理。
50.计算节点内同步机制即线程之间同步机制,其依靠由主进程创建的所有线程可共享的全局变量实现:所有线程均可无条件获取全局变量,但是全局变量值的变化需要依靠原子操作函数。当存在两个线程同时对同一全局变量进行写入时,会产生冲突现象,原子操作函数能够保证在某个时间点上的某个全局变量有且仅有一个线程能够对其进行写入修改,其他线程会暂时阻塞等待完成。线程间同步机制实现过程如图7所示:
51.首先,在进入周期模拟过程前,本方法初始化同步机制所需全局变量。coresign用于统计每个周期已完成任务的线程数,初始值为0,corenum用于记录本模拟仿真过程使用的线程数,syntime用于记录当前周期值,初始值为0;syntime用于记录模拟神经元活动过程的总周期数,synt用于记录上一周期值,初始值为
‑
1。
52.其次,在共计1000个周期的神经元模拟过程中,每周期多线程同步过程如下,以三线程同步过程为例,:设当前周期值为t,则coresign值为0,corenum值为3,syntime值为t,syntime值为固定1000,synt值为t
‑
1。各线程进入运行阶段,在完成本周期任务后,每个线程调用原子操作函数获取coresign值,将其加1。然后,主线程进入while循环等待,不断检测比较coresign与corenum是否相等,当满足coresign=corenum时,本周期所有任务都已完成,主线程将synt加1,将coresign置0。
53.随后,主线程与其他从线程会进入while循环等待,不断检测比较synt与syntime是否相等,当满足synt=syntime时,所有线程同步完成,主线程对syntime+1。
54.最后所有线程会继续进入下一周期重复上述过程,直至syntime=syntime时模拟过程结束;多线程同步过程与三线程同步过程相同。
55.多计算节点间同步机制依靠多计算节点全连接的基于tcp/ip协议的通信网络实现,多计算节点同步过程如下,以三节点同步过程为例,具体过程如图8所示:
56.首先,在进入周期模拟过程前,本方法需要设置node0为主计算节点(master),其余计算节点node1和node2设置为从计算节点(slaver),每个计算节点都要维护一个flag变量,初始值设置为0x000。随后,master释放开始信号包,开始其运行任务,slaver则在收到开始信号包后进入运行任务。
57.然后,当计算节点任务结束后,每个计算节点都会进入while循环等待接收其余节点的结束信号包,该信号包附带发送者的节点编号信息。根据计算节点编号信息,各计算节点将flag对应位置1,直至flag=0x111表明三个节点本周期任务已完成,可以将flag值清零,等待master开始信号包,开始下一周期;多节点同步过程与三节点同步过程相同。
58.步骤3,在每个周期内,脉冲神经网络中神经元之间进行信息交互即脉冲传输;节点内脉冲传输使用基于内存共享的无锁式双缓冲数据传输机制,节点间脉冲传输依靠tcp/ip可靠传输协议。
59.线程间数据传输依靠全局缓冲区实现。缓冲区的多线程并发读写需要使用互斥锁加以控制,但是过多的锁的使用会消耗过多的cpu资源,影响模拟仿真过程效率,于是,本方案用双缓冲机制进行数据传输,在某个周期内双缓冲的一个缓冲区用于本周期脉冲数据写入,另一个缓冲区用于保存上一周期的写入脉冲数据,二者互不干扰,保证数据传输不会过多占用cpu资源。无锁式双缓冲数据传输机制实现过程如图9所示:
60.记各参数含义如下:当前周期为t0周期,下一周期为t1周期;
61.dbuffer_sw为所有双缓冲区编号,取值范围为0或1,用于标记t0周期所有线程使用的缓冲区;w.outbuf0表示本周期t0计算线程组的脉冲数据发送缓冲区;routebuf0表示t1周期路由线程组计算线程组的脉冲数据读取处理缓冲区;workerbuf为t1周期路由线程组临时存放内部脉冲数据缓冲区;w.inbuf1为t1周期接收由workerbuf而来脉冲数据的计算线程组的数据读取缓冲区;
62.networkbuf为t1周期路由线程组临时存放外部脉冲数据缓冲区;n.inbuf0为t1周期接收由networkbuf而来脉冲数据的网络线程组的数据发送缓冲区。
63.数据发送过程为:在t0周期,dbuffer_sw值为0,计算线程组在进行神经元计算更新过程后将本周期产生的脉冲数据临时存于w.outbuf0中,等待计算更新过程结束后,位于w.outbuf0的脉冲数据将一并拷贝至routebuf0内。随后在t1周期,dbuffer_sw值为1,故1
‑
dbuffer_sw=0,路由线程组开始读取routebuf0中上一周期的脉冲数据并进行脉冲数据分流。流往节点内的脉冲存至workerbuf,发向w.inbuf1。流往节点外的脉冲存至networkbuf,发向n.inbuf0。最后在t2周期,dbuffer_sw值为0,网络线程组中的发送线程开始读取n.inbuf0,拷贝socket发送缓冲区进行转发任务。
64.数据接收过程为:在t0周期,dbuffer_sw值为0,网络线程组中的接收线程会拷贝socket接收缓冲区中外部节点发往本节点的脉冲数据至n.inbuf0,发向outnetbuf0。随后在t1周期,dbuffer_sw值为1,故1
‑
dbuffer_sw=0,路由线程组开始读取outnetbuf0中上一周期的脉冲数据并进行脉冲数据筛选。流往节点内的脉冲存至workerbuf,发向w.inbuf1,其余脉冲数据进行丢弃。最后在t2周期,dbuffer_sw值为0,计算线程组在神经元计算更新过程中,会读取w.inbuf1中的脉冲数据,判断脉冲数据是否对本线程神经元有影响,并将此影响作用至神经元的状态更新过程。
65.针对单个周期来说,计算线程组、路由线程组以及网络线程组的脉冲写入与读取过程均互不干扰,同时整个数据传输过程实现了无锁化,提高了模拟仿真运行效率。
66.步骤4,在模拟仿真过程周期到达预设的模拟周期数时,记录脉冲神经网络所有模拟周期中神经元的脉冲发放情况,即统计模拟仿真过程中每个周期内所有产生的脉冲数据。
67.以上实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1