一种代码相似度检测方法及装置与流程
本技术涉及信息,尤其涉及一种代码相似度检测方法及装置。
背景技术:
1、软件开发人员为了提高效率,在软件开发过程中,存在代码的复制和粘贴(即代码克隆龙)以实现相同的功能,尽管在某种程度上有助于代码开发,但却不利于维护。
2、克隆代码在提高生产效率的同时,也带来了巨大的安全隐患。比如原始程序存在的错误甚至漏洞修复后,在其它冗余代码中进行了修复,可能会产生比原始漏洞还要严重的安全风险。因此,需要进行代码克隆检测。代码克隆检测可应用于多个领域多个场景中。比如在代码抄袭检测场景,可检测目标代码是否与受版权保护的已有代码相似,在恶意软件分析场景,可检测目标恶意代码是否与已知的相似,从而判断目标代码是否为恶意软件,在已知漏洞匹配场景中,检测目标代码是否与已知的漏洞代码相似,从而判断目标代码中是否存在已知漏洞。
3、在实际应用中,需要快速的在海量代码中发掘出相似代码,比如在软件版权场景,需要判断整个工程内部乃至不同工程间是否被抄袭,因此,亟需一种需要具有海量代码的检测能力的代码相似度检测方法。
技术实现思路
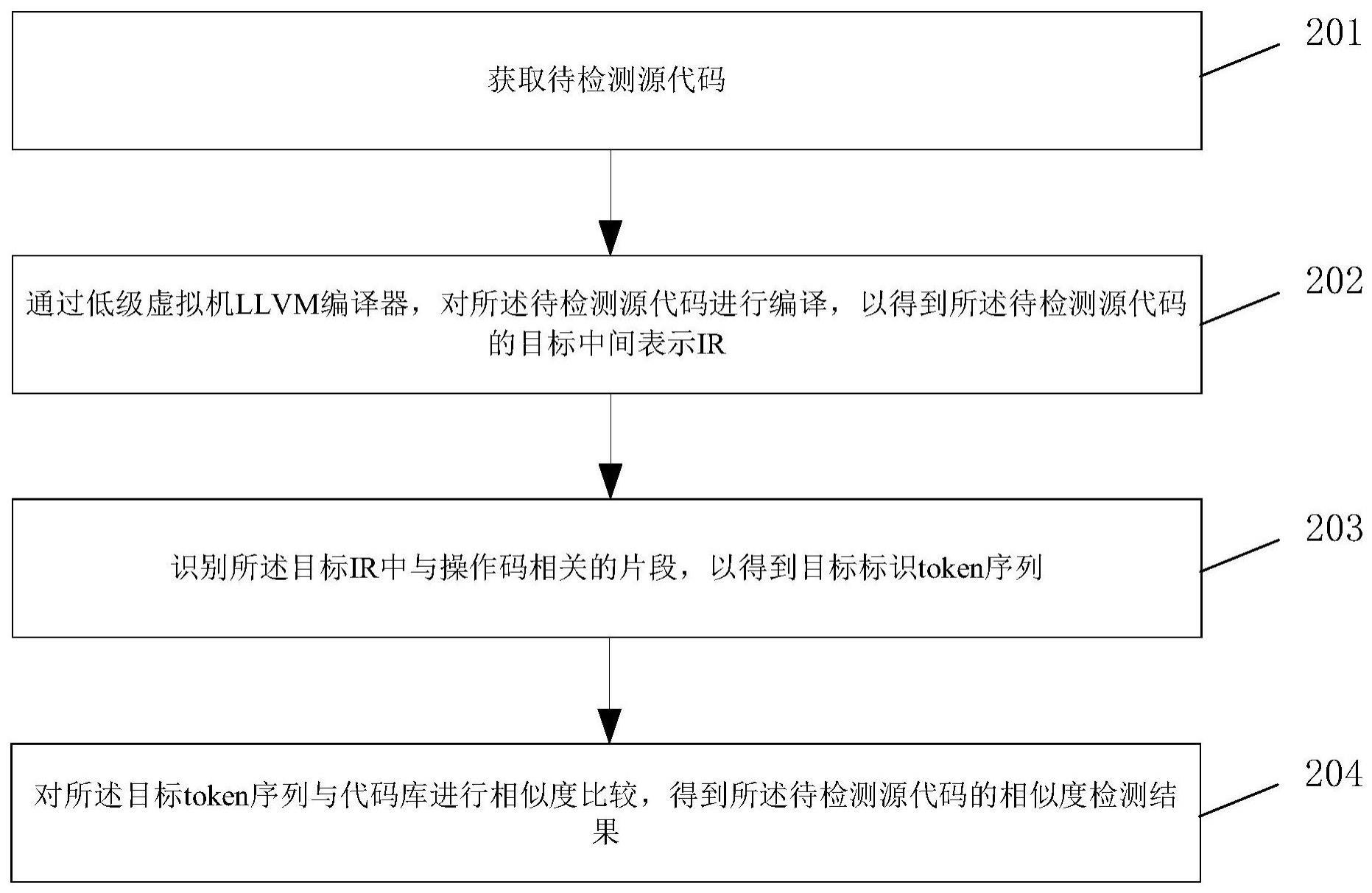
1、第一方面,本技术提供了一种代码相似度检测方法,所述方法包括:
2、获取待检测源代码;通过低级虚拟机llvm编译器,对所述待检测源代码进行编译,以得到所述待检测源代码的目标中间表示ir;识别所述目标ir中与操作码相关的片段,以得到目标标识token序列;对所述目标token序列与代码库进行相似度比较,得到所述待检测源代码的相似度检测结果。
3、本技术实施例提供了一种代码相似度检测方法,所述方法包括:获取待检测源代码;通过低级虚拟机llvm编译器,对所述待检测源代码进行编译,以得到所述待检测源代码的目标中间表示ir;识别所述目标ir中与操作码相关的片段,以得到目标标识token序列;对所述目标token序列与代码库进行相似度比较,得到所述待检测源代码的相似度检测结果。
4、其中,不同平台、不同cpu架构、不同编译器版本、不同编译选项等产生的二进制往往存在很大差异,会对相似度的比较产生较大影响,llvm编译器编译得到的ir语言可以充分屏蔽后端差异,可以很好的解决此问题。
5、其中,通过llvm编译器编译后的目标ir可以充分保留源代码的语义信息,而且不受空格、注释等无效代码的影响,可以保证较高的相似度识别准确率。且提取操作码、被调函数等信息作为特征向量,在不需要基于复杂的语义提取的前提下,利用llvm编译器的优化能力可挖掘更深层次的克隆代码对,进而实现海量代码的检测能力。
6、在一种可能的实现中,在所述通过低级虚拟机llvm编译器,对所述待检测源代码进行编译之前,所述方法还包括:
7、对所述待检测源代码中的无效代码片段进行剔除,所述无效代码片段为所述待检测源代码中对运算结果无影响的代码片段。
8、具体的,可以利用编译器的优化技术,挖掘深层次的优化,比如无用代码消除(即对无效代码片段进行剔除),其中无效代码片段也可以称之为无用代码(dead-code),无效代码片段可以指计算结果永远不会使用的语句。
9、其中,无效代码片段由于在代码中没有实质性作用,例如,空格、注释等片段,在进行代码的相似性比较时将这部分代码进行剔除,可以提高代码相似性检测的精确率。
10、在一种可能的实现中,在所述通过低级虚拟机llvm编译器,对所述待检测源代码进行编译之前,所述方法还包括:对所述待检测源代码中位于循环体内的循环不变量(loopinvariant)进行剔除并移动至所述循环体外。
11、其中,循环不变量(loop invariant)可以指不会随着每轮循环改变的表达式,优化程序只在循环体外计算一次并在循环过程中使用。编译器的优化程序能找出循环不变量并使用“代码移动(code motion)”将其移除循环体。
12、以循环不变量提取为例,res=3即为循环不变量,其中,优化前的代码为:
13、int loop(int num)
14、{int i=0;int res;
15、for(i=0;i<num;i++){res=3;}return res;}
16、优化后的代码为:
17、int loop1(int num)
18、{int i=0;int res=3;for(i=0;i<num;i++){}return res;}。
19、在一种可能的实现中,可以识别所述目标ir中包含的操作码,以得到目标token序列,其中所述目标token序列包括所述操作码。例如,对构建后生成的ir文件(.bc)可以以函数为单位解析ir指令,提取相关的语义信息(针对于普通的ir指令,可以提取操作码)。
20、在一种可能的实现中,可以识别所述目标ir中包含指针操作的指令,以得到目标token序列,其中所述目标token序列包括所述指针操作的指令中包含的操作码以及所述指针操作所指向的对象。例如,对构建后生成的ir文件(.bc)可以以函数为单位解析ir指令,提取相关的语义信息(针对于指针类型操作,可以提取操作码和指针指向的类型)。
21、在一种可能的实现中,可以识别所述目标ir中的调用指令,以得到目标token序列,其中所述目标token序列包括所述调用指令中调用的函数。例如,对构建后生成的ir文件(.bc)可以以函数为单位解析ir指令,提取相关的语义信息(针对于调用指令,可以提取调用的函数名)。
22、在一种可能的实现中,所述代码库包括多个文档,每个所述文档对应一个token序列,每个所述token序列为根据一个候选代码得到的,且每个所述文档包括对应的token序列的最小哈希签名;
23、所述对所述目标token序列与代码库进行相似度比较,包括:
24、通过最小哈希minhash算法,确定所述目标token序列的目标最小哈希签名;
25、对所述目标最小哈希签名与每个所述文档包括的最小哈希签名进行相似度比较。
26、其中,代码库可以包括由多个token序列组成的文档,其可以是key-value结构,其中key是文档的名字,value为文档的minhash签名值,本技术可以利用redis内存数据库结合涉及的key-value存储结构,做到高效快速的数据处理能力。
27、在一种可能的实现中,所述对所述目标最小哈希签名与每个所述文档包括的最小哈希签名进行相似度比较,包括:
28、通过局部敏感hash(lsh)算法,对所述目标最小哈希签名与每个所述文档包括的最小哈希签名进行相似度比较。
29、其中,minhash算法可以把token的比较转化成签名的比较,具有准确高效的优点,而minhash lsh算法可以解决海量数据的比较问题。本技术实施例通过llvm把源码转化成ir语言,保留了源码语义信息,同时结合minhashlsh算法,实现海量代码的检测能力。
30、在一种可能的实现中,所述相似度检测结果包括至少一个候选代码,每个候选代码对应的token序列与所述目标token序列之间的相似度高于阈值;
31、所述方法还包括:
32、呈现目标信息,所述目标信息用于指示所述至少一个候选代码中每个候选代码与所述待检测代码之间的差异信息。
33、在一种可能的实现中,所述待检测源代码包括代码的编译指令,且所述编译指令为clang编译命令。
34、第二方面,本技术提供了一种代码相似度检测装置,所述装置包括:
35、获取模块,用于获取待检测源代码;
36、编译模块,用于通过低级虚拟机llvm编译器,对所述待检测源代码进行编译,以得到所述待检测源代码的目标中间表示ir;
37、识别模块,用于识别所述目标ir中与操作码相关的片段,以得到目标标识token序列;
38、相似度检测模块,用于对所述目标token序列与代码库进行相似度比较,得到所述待检测源代码的相似度检测结果。
39、其中,不同平台、不同cpu架构、不同编译器版本、不同编译选项等产生的二进制往往存在很大差异,会对相似度的比较产生较大影响,llvm编译器编译得到的ir语言可以充分屏蔽后端差异,可以很好的解决此问题。
40、其中,通过llvm编译器编译后的目标ir可以充分保留源代码的语义信息,而且不受空格、注释等无效代码的影响,可以保证较高的相似度识别准确率。且提取操作码、被调函数等信息作为特征向量,在不需要基于复杂的语义提取的前提下,利用llvm编译器的优化能力可挖掘更深层次的克隆代码对,进而实现海量代码的检测能力。
41、在一种可能的实现中,所述装置还包括:
42、代码优化模块,用于在所述通过低级虚拟机llvm编译器,对所述待检测源代码进行编译之前,对所述待检测源代码中的无效代码片段进行剔除,所述无效代码片段为所述待检测源代码中对运算结果无影响的代码片段。
43、在一种可能的实现中,所述装置还包括:
44、代码优化模块,用于在所述通过低级虚拟机llvm编译器,对所述待检测源代码进行编译之前,对所述待检测源代码中位于循环体内的循环不变量(loop invariant)进行剔除并移动至所述循环体外。
45、在一种可能的实现中,所述识别模块,具体用于:
46、识别所述目标ir中包含的操作码,以得到目标token序列,其中所述目标token序列包括所述操作码;和/或,
47、识别所述目标ir中包含指针操作的指令,以得到目标token序列,其中所述目标token序列包括所述指针操作的指令中包含的操作码以及所述指针操作所指向的对象;和/或,
48、识别所述目标ir中的调用指令,以得到目标token序列,其中所述目标token序列包括所述调用指令中调用的函数。
49、在一种可能的实现中,所述代码库包括多个文档,每个所述文档对应一个token序列,每个所述token序列为根据一个候选代码得到的,且每个所述文档包括对应的token序列的最小哈希签名;
50、所述相似度检测模块,具体用于:
51、通过最小哈希minhash算法,确定所述目标token序列的目标最小哈希签名;
52、对所述目标最小哈希签名与每个所述文档包括的最小哈希签名进行相似度比较。
53、在一种可能的实现中,所述相似度检测模块,具体用于:
54、通过局部敏感hash(lsh)算法,对所述目标最小哈希签名与每个所述文档包括的最小哈希签名进行相似度比较。
55、在一种可能的实现中,所述相似度检测结果包括至少一个候选代码,每个候选代码对应的token序列与所述目标token序列之间的相似度高于阈值;
56、所述装置还包括:
57、结果呈现模块,用于呈现目标信息,所述目标信息用于指示所述至少一个候选代码中每个候选代码与所述待检测代码之间的差异信息。
58、在一种可能的实现中,所述待检测源代码包括代码的编译指令,且所述编译指令为clang编译命令。
59、第三方面,本技术实施例提供了一种代码相似度检测装置,可以包括存储器、处理器以及总线系统,其中,存储器用于存储程序,处理器用于执行存储器中的程序,以执行如上述第一方面及其任一可选的方法。
60、第四方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面及其任一可选的方法。
61、第五方面,本技术实施例提供了一种计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面及其任一可选的方法。
62、第六方面,本技术提供了一种芯片系统,该芯片系统包括处理器,用于支持代码相似度检测装置实现上述方面中所涉及的功能,例如,发送或处理上述方法中所涉及的数据;或,信息。在一种可能的设计中,所述芯片系统还包括存储器,所述存储器,用于保存代码相似度检测装置必要的程序指令和数据。该芯片系统,可以由芯片构成,也可以包括芯片和其他分立器件。
63、本技术实施例提供了一种代码相似度检测方法,所述方法包括:获取待检测源代码;通过低级虚拟机llvm编译器,对所述待检测源代码进行编译,以得到所述待检测源代码的目标中间表示ir;识别所述目标ir中与操作码相关的片段,以得到目标标识token序列;对所述目标token序列与代码库进行相似度比较,得到所述待检测源代码的相似度检测结果。
64、其中,通过llvm编译器编译后的目标ir可以充分保留源代码的语义信息,而且不受空格、注释等无效代码的影响,可以保证较高的相似度识别准确率。且提取操作码、被调函数等信息作为特征向量,利用llvm编译器的优化能力可挖掘更深层次的克隆代码对。
65、其中,不同平台、不同cpu架构、不同编译器版本、不同编译选项等产生的二进制往往存在很大差异,会对相似度的比较产生较大影响,llvm编译器编译得到的ir语言可以充分屏蔽后端差异,可以很好的解决此问题。
66、其中,minhash算法可以把token的比较转化成签名的比较,具有准确高效的优点,而minhash lsh算法可以解决海量数据的比较问题。本技术实施例通过llvm把源码转化成ir语言,保留了源码语义信息,同时结合minhashlsh算法,实现海量代码的检测能力。
- 还没有人留言评论。精彩留言会获得点赞!