一种基于多维度视差先验的双目图片超分辨率重建方法与流程
1.本发明属于图像处理技术领域,具体涉及一种基于多维度视差先验的双目图片超分辨率重建方法。
背景技术:
2.近年来,随着光学成像技术的发展,双目摄像头在我们的日常生活中越来越普及。比如,几乎所有的智能手机都配备了双目摄像头以获得更好的图像质量,自动驾驶的汽车也使用双目摄像头来捕捉场景图像的深度图。此外,双目摄像机在计算机辅助手术中也受到了重视。因此,随着双目成像器件的发展,对高分辨率立体图像的要求越来越高,发展双目超分辨率技术迫在眉睫。
3.得益于深度学习的蓬勃发展,基于单张图像的超分辨率算法在最近取得显著的进步,它致力于从一张低分辨率图像中恢复出对应的高分辨率的图像。通过模型训练,基于单张图像的超分辨率算法方法可以从外部训练数据和内部图像特征信息中获取可行信息,来达到恢复高清细节的目的。不同于单张图像的超分技术,双目超分辨率算法的输入是两张不同视角的低分辨率图像,它致力于恢复出某一视角的高分辨率图像。由于两张不同视角的低分辨率图像存在比较大的视差信息,直接运用现成的单张超分辨率算法分别恢复不同视角的图像是不可行的,它忽略了其它视点的亚像素偏移信息所带来的交叉视图信息的优点,最终导致性能下降。
4.因此,最近的双目超分辨率方法致力于利用视差先验信息,同时利用现有的单张图像的超分辨率算法来挖掘内部图像特定信息。具体来说,jeon 等人在文献“d. s. jeon, s. baek, i. choi, and m. h. kim, enhancing the spatial resolution of stereo images using a parallax prior, in cvpr 2018, pp. 1721
–
1730”中提出了 stereosr网络,它首先论证了视差先验在立体视觉中的重要性,并提出通过联合训练两个级联子网络来学习视差先验。基于stereosr, wang等人在文献“l. wang, y. wang, z. liang, z. lin, j. yang, w. an, and y. guo, learning parallax attention for stereo image super
‑
resolution, in cvpr 2019, pp. 12 250
–
12 259”提出了一种新的用于立体图像超分辨网络的视差注意网络passrnet,它引入了一种具有全局感受野的视差注意机制来处理立体图像间的视差信息。此外,ying等人在文献“x. ying, y. wang, l. wang, w. sheng, w. an, and y. guo, a stereo attention module for stereo image super
‑
resolution, in ieee signal process. lett. 2020, vol. 27, pp. 496
–
500”提出了一种通用的立体注意模块(sam)来利用交叉视角和视角内信息,它可以嵌入到任意单张超分辨网络中进行双目图像超分。然而,stereosr仅水平地移动右图像64个像素以模拟先前的粗略视差。同时,passrnet和sam只考虑了对两个原始视点的视差关注,而忽略了两个特征之间的多维信息。
5.因此,最近的双目超分辨率方法致力于利用视差先验信息,同时利用现有的单张图像的超分辨率算法来挖掘内部图像特定信息。
技术实现要素:
6.本发明的目的是为了解决重建双目图片超分辨率的问题,提出了一种基于多维度视差先验的双目图片超分辨率重建方法。
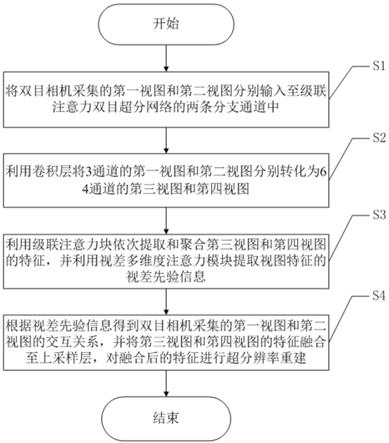
7.本发明的技术方案是:一种基于多维度视差先验的双目图片超分辨率重建方法包括以下步骤:s1:将双目相机采集的第一视图和第二视图分别输入至级联注意力双目超分网络的两条分支通道中;其中,级联注意力双目超分网络包括两条对称的分支通道,其分支通道均包括依次连接的卷积层、级联注意力块和上采样层,还包括插入至级联注意力块的视差多维度注意力模块;s2:利用卷积层将3通道的第一视图和第二视图分别转化为64通道的第三视图和第四视图;s3:利用级联注意力块依次提取和聚合第三视图和第四视图的特征,并利用视差多维度注意力模块提取视图特征的视差先验信息;s4:根据视图特征的视差先验信息得到双目相机采集的第一视图和第二视图的交互关系,并将第三视图和第四视图的特征融合至上采样层,利用上采样层对融合后的第三视图和第四视图的特征进行超分辨率重建,得到超分辨率图片。
8.进一步地,步骤s1中,级联注意力双目超分网络采用自注意力机制;其中,视觉多维度注意力模块用于输入两个视图,并提取两个视图的视差先验信息;级联注意力块包括残差网络和视觉多维度自注意力模块;视觉多维度自注意力模块用于输入单一视图,并提取单一视图的视差先验信息。
9.进一步地,步骤s3包括以下子步骤:s31:利用级联注意力块依次提取和聚合第三视图的特征和第四视图的特征;s32:将第三视图的特征和第四视图的特征均依次输入至视差多维度注意力模块中的残差块和卷积层,得到视图特征;s33:基于视图特征,根据第三视图的特征函数,计算从第四视图到第三视图的第一注意力特征图,并通过第三视图的特征更新函数进行更新,得到第二注意力特征图;s34:基于视图特征,根据第四视图的特征函数,计算从第三视图到第四视图的第三注意力特征图,并通过第四视图的特征函数更新进行更新,得到第四注意力特征图;s35:计算第二注意力特征图和第四注意力特征图在通道维度、高度维度和宽度维度上的视差先验信息。
10.进一步地,步骤s32中,视图特征的表达式为,其中,表示自注意力机制中第三视图的值张量,表示自注意力机制中第三视图的键张量,表示自注意力机制中第三视图的查询张量,表示自注意力机制中第四视图的值张量,表示自注意力机制中第四视图的键张量,表示自注意力机制中第四视图的查询张量,表示自注意力机制中的键张量,表示自注意力机制中的键张量,表示自注意力机制中的查询张量,表示第三视图,表示第四视图;步骤s33中,第三视图的特征函数和第三视图的特征更新函数
的表达式分别为:的表达式分别为:其中,表示归一化指数函数,表示矩阵乘法,表示矩阵转置;步骤s34中,第四视图的特征函数和第四视图的特征更新函数的表达式分别为:的表达式分别为:。
11.进一步地,步骤s35中,计算第二注意力特征图和第四注意力特征图在通道维度、高度维度和宽度维度上的视差先验信息的方法相同,均包括以下子步骤:s351:在通道维度、高度维度和宽度维度上,分别重塑自注意力机制中的查询张量和键张量,得到第一查询张量、第二查询张量和第三查询张量、第一键张量、第二键张量和第三键张量,其中,表示注意力特征图的通道维度,表示注意力特征图的高度维度,表示注意力特征图的宽度维度,表示矩阵尺度;s352:对第一查询张量、第二查询张量和第三查询张量与第一键张量、第二键张量和第三键张量依次进行对应的矩阵相乘和归一化操作,得到第一依赖关系映射、第二依赖关系映射和第三依赖关系映射;s353:在通道维度、高度维度和宽度维度上重塑自注意力机制中的值张量,得到第一值张量、第二值张量和第三值张量,并将第一依赖关系映射、第二依赖关系映射和第三依赖关系映射分别与第一值张量、第二值张量和第三值张量进行对应的矩阵相乘,得到第一注意力机制更新后特征、第二注意力机制更新后特征和第三注意力机制更新后特征;注意力机制更新后的特征具有视差的交互信息。
12.s354:将第一注意力机制更新后特征、第二注意力机制更新后特征和第三注意力机制更新后特征和视差多维度注意力模块中残差块的残差特征在通道维度上进行拼接,并利用卷积层减少第一注意力机制更新后特征、第二注意力机制更新后特征和第三注意力机制更新后特征的通道数,得到视差先验信息的特征表达。
13.进一步地,步骤s352中,依赖关系映射的计算公式为:其中, 表示第一依赖关系映射,表示第二依赖关系映射,表示第三依赖关系映射,表示第一查询张量,表示第二查询张量,表示第三查询张量,表示归一化指数函数,表示矩阵乘法;步骤s353中,注意力机制更新后特征的计算公式为:其中,表示第一值张量,表示第二值张量,表示第三值张量, 表示第一注意力机制更新后特征,表示第二注意力机制更新后特征,表示第三注意力机制更新后特征;步骤s354中,视差先验信息的特征表达的计算公式为:其中,表示自注意力机制中的键张量,表示特征图在通道维度进行拼接,表示卷积操作。
14.本发明的有益效果是:(1)本发明提出一个通用的视差多维度注意力模块,充分挖掘了不同视点产生的双目图像的视差信息,很好地捕捉了双目视差信息在特征空间的多维度表示问题。视差多维度注意力模块可以直接集成到不同的单张图片超分辨率网络中进行多阶段的特征融合,以更好地模拟交叉视图信息交互。
15.(2)基于视差多维度注意力模块,本发明还提出多维度自注意力模块,它能够自适应地从单张图像中学习更多有用的内部视点先验信息。
16.(3)基于视差多维度注意力模块和多维度自注意力模块,本发明还提出一个轻量级的级联注意力双目超分网络,它在模型参数和重建效果上达到很好的平衡。
附图说明
17.图1为双目图片超分辨率重建方法的流程图;图2为级联注意力双目超分网络的结构图;图3为视差多维度注意力模块的结构图;图4为视差多维度自注意力模块的结构图;图5为级联注意力块的结构图。
具体实施方式
18.下面结合附图对本发明的实施例作进一步的说明。
19.如图1所示,本发明提供了一种基于多维度视差先验的双目图片超分辨率重建方法,包括以下步骤:
s1:将双目相机采集的第一视图和第二视图分别输入至级联注意力双目超分网络的两条分支通道中;其中,级联注意力双目超分网络包括两条对称的分支通道,其分支通道均包括依次连接的卷积层、级联注意力块和上采样层,还包括插入至级联注意力块的视差多维度注意力模块;s2:利用卷积层将3通道的第一视图和第二视图分别转化为64通道的第三视图和第四视图;s3:利用级联注意力块依次提取和聚合第三视图和第四视图的特征,并利用视差多维度注意力模块提取视图特征的视差先验信息;s4:根据视图特征的视差先验信息得到双目相机采集的第一视图和第二视图的交互关系,并将第三视图和第四视图的特征融合至上采样层,利用上采样层对融合后的第三视图和第四视图的特征进行超分辨率重建,得到超分辨率图片。
20.在本发明实施例中,步骤s1中,级联注意力双目超分网络采用自注意力机制;其中,视觉多维度注意力模块用于输入两个视图,并提取两个视图的视差先验信息;级联注意力块包括残差网络和视觉多维度自注意力模块;视觉多维度自注意力模块用于输入单一视图,并提取单一视图的视差先验信息。
21.如图2所示,级联注意力双目超分网络模型是一个高度对称的结构,拥有两个完全一样的分支,它们相互共享网络参数。其中,每一个分支对应于一个视角低分辨率图像的输入。左边和右边视角的低分辨率图像分别同时输入上面和下面部分的分支网络。输入网络后,首先使用3
×
3卷积网络把3通道的输入图像转化为64通道的特征图。随后,一系列的级联注意力块在主干网络中对特征进一步地提取和聚合。因此,通过两个分支网络,可以获得对应于左视角图像和右视角图像的两个粗糙的特征表达。然后,将多个视差多维度注意力模块插入到主干网络的级联注意力块序列中,以在不同阶段捕捉到左右视图特征的视差先验信息。得益于视觉多维度注意力模块和级联注意力块,帧内视图和帧间交叉视图信息能被网络很好地感知到。一个全局的残差连接把最开始的特征图以相加的方式融合到网络的尾部,这样做可以促进全局信息流动,减轻网络的训练难度。最后,把经过融合后的左右视角特征分别利用上采样模块进行高分辨率重建,就可以得到对用的高分辨率图片。
22.如图3所示,采取自注意力机制来设计视觉多维度注意力模块,这个转化过程可以被认为,给定一个特定的查询(query),基于键(key)来搜索相应的值(value)。由图3可以看出,左右两个视角的特征首先输入到一个残差块,这个残差块参数共享。然后,特征在分别输入到6个1
ꢀ×ꢀ
1卷积层得到6个对应于左右视角的特征。对于左边视图,。由此得到从右到左视图的软注意力特征图,通过就可以得到转化后的特征图。同理,对于右边视图,注意力特征图,。
23.下面主要介绍如何在多维度上计算出视差先验信息的。对于上面的,,(c、h和w分别代表特征图的通道、高度和宽度的维度信息),传
统的自注意力机制仅仅只计算一个维度的交互信息,导致图像处理任务中的特征挖掘不足。在pmda中,为了解决这一问题,不仅仅挖掘通道维度的信息(h
×
w),空间维度的交互信息也被挖掘(h
×
c,w
×
c)。在图3中,每一个大圆角矩形代表在某一个维度进行自注意力机制的计算。具体地说,给定query、key 和value 张量,三个query张量分别被重塑为三种不同的形状,即、和。为了方便相乘,三个key张量分别被重塑为三种对应的形状、和。这里,相同的下标表示矩阵乘法在对应的三种形状上执行。执行矩阵乘法,q1k1,q2k2,q3k3。然后,沿批处理列对它们应用softmax操作,以生成一组依赖关系映射a1、a2和a3。这可以表述为:。相应地,即、和。接下来,为了将得到的注意力图映射组合成相应的特征,在value值和之间执行矩阵乘法,为此,三个value张量分别被重塑为三种对应的形状和。a和v之间的操作可以表示为。随后,得到的f1、f2和 f3和残差特征value在通道维度进行拼接得到新的向量。最后,用1
×ꢀ
1卷积来减少这些级联特征的通道数,得到最终的输出。这个过程可以表示为。因此,注意力机制的操作是在三个维度空间中进行的w
×
c、 h
×
c和h
×
w这就是为什么这个模块被称为多维的原因。
24.如图4所示,视觉多维度自注意力模块是基视觉多维度注意力模块的改进。视觉多维度注意力模块的输入是左右两个视图的特征,而视觉多维度自注意力模块的输入仅仅就是单一视图的特征。因此视觉多维度自注意力模块能够捕捉到单一视角的多维度先验信息。
25.在本发明实施例中,步骤s3包括以下子步骤:s31:利用级联注意力块依次提取和聚合第三视图的特征和第四视图的特征;s32:将第三视图的特征和第四视图的特征均依次输入至视差多维度注意力模块中的残差块和卷积层,得到视图特征;s33:基于视图特征,根据第三视图的特征函数,计算从第四视图到第三视图的第一注意力特征图,并通过第三视图的特征更新函数进行更新,得到第二注意力特征图;s34:基于视图特征,根据第四视图的特征函数,计算从第三视图到第四视图的第三注意力特征图,并通过第四视图的特征函数更新进行更新,得到第四注意力特征图;s35:计算第二注意力特征图和第四注意力特征图在通道维度、高度维度和宽度维度上的视差先验信息。
26.在本发明实施例中,步骤s32中,视图特征的表达式为,其中,表示自注意力机制中第三视图的值张量,表示自注意力机制中第三视图的键张量,表示自注意力机制中第三视图的查询张量,表示自注意力机制中第四视图的值张量,表示自注意力机制中第四视图的键张量,表示自注意力机制中第四视图的查询张量,表示自注意力机制中的键张量,表
示自注意力机制中的键张量,表示自注意力机制中的查询张量,表示第三视图,表示第四视图;步骤s33中,第三视图的特征函数和第三视图的特征更新函数的表达式分别为:的表达式分别为:其中,表示归一化指数函数,表示矩阵乘法,表示矩阵转置;步骤s34中,第四视图的特征函数和第四视图的特征更新函数的表达式分别为:的表达式分别为:。
27.在本发明实施例中,步骤s35中,计算第二注意力特征图和第四注意力特征图在通道维度、高度维度和宽度维度上的视差先验信息的方法相同,均包括以下子步骤:s351:在通道维度、高度维度和宽度维度上,分别重塑自注意力机制中的查询张量和键张量,得到第一查询张量、第二查询张量和第三查询张量、第一键张量、第二键张量和第三键张量,其中,表示注意力特征图的通道维度,表示注意力特征图的高度维度,表示注意力特征图的宽度维度,表示矩阵尺度;s352:对第一查询张量、第二查询张量和第三查询张量与第一键张量、第二键张量和第三键张量依次进行对应的矩阵相乘和归一化操作,得到第一依赖关系映射、第二依赖关系映射和第三依赖关系映射;s353:在通道维度、高度维度和宽度维度上重塑自注意力机制中的值张量,得到第一值张量、第二值张量和第三值张量,并将第一依赖关系映射、第二依赖关系映射和第三依赖关系映射分别与第一值张量、第二值张量和第三值张量进行对应的矩阵相乘,得到第一注意力机制更新后特征、第二注意力机制更新后特征和第三注意力机制更新后特征;注意力机制更新后的特征具有视差的交互信息。
28.s354:将第一注意力机制更新后特征、第二注意力机制更新后特征和第三注
意力机制更新后特征和视差多维度注意力模块中残差块的残差特征在通道维度上进行拼接,并利用卷积层减少第一注意力机制更新后特征、第二注意力机制更新后特征和第三注意力机制更新后特征的通道数,得到视差先验信息的特征表达。
29.在本发明实施例中,步骤s352中,依赖关系映射的计算公式为:其中, 表示第一依赖关系映射,表示第二依赖关系映射,表示第三依赖关系映射,表示第一查询张量,表示第二查询张量,表示第三查询张量,表示归一化指数函数,表示矩阵乘法;步骤s353中,注意力机制更新后特征的计算公式为:其中,表示第一值张量,表示第二值张量,表示第三值张量, 表示第一注意力机制更新后特征,表示第二注意力机制更新后特征,表示第三注意力机制更新后特征;步骤s354中,视差先验信息的特征表达的计算公式为:其中,表示自注意力机制中的键张量,表示特征图在通道维度进行拼接,表示卷积操作。
30.如图5所示,级联注意力块是残差网络和视觉多维度自注意力模块的结合。具体来说,级联注意力块直接将输入的特征图分解为4个子集,分别为x1、x2、x3和x4,每个子集的通道数为原来的四分之一,并使用多个并行但相连的卷积层来处理这些特征映射。最后,将这些子集聚合在一起,用一个1
×ꢀ
1卷积来聚合这些特征。提出的视觉多维度自注意力模块插在这个1
×ꢀ
1卷积层之后,四个子集对应的输出分别为y1、y2、y3和y4。由于残差网络具有较大的感受野,同时保持较小的通道数量,信息传递给smda后就可以用较少的参数获得更详细、更精确的特征表达。
31.下面采用平均绝对误差mean absolute error (mae)来训练网络。在级联注意力双目超分网络中包含10个级联注意力块。峰值信噪比(psnr)和结构相似性(ssim)被用来测试模型的性能,值越大代表恢复出的图像效果越好。表1为级联注意力双目超分网络中不同维度学习的效果。
32.表1
x. gao, y. yang, and x. wang, lightweight image super
‑
resolution with information multi
‑
distillation network, in acm mm, 2019, pp. 2024
–
2032.”,srresnet方法来自论文“c. ledig, l. theis, f. huszar, j. caballero, a. cunningham, a. acosta,a. p. aitken, a. tejani, j. totz, z. wang, and w. shi, photo
‑
realistic single image super
‑
resolution using a generative adversarial network, in cvpr, 2017, pp. 105
–
114.”,rcan方法来自论文“y. zhang, k. li, k. li, l. wang, b. zhong, and y. fu, image super
‑
resolution using very deep residual channel attention networks, in eccv, 2018, pp. 294
–
310”。这三个方法都是专门针对单张超分辨模型的,并且imdn是非常轻量级的模型,srresnet的模型大小适中,rcan是一个参数量巨大的模型,但重建效果也是目前最好的。如果没有这个pmda模块,仅仅只用原始的单张超分模型。结果展示在表2中,可以很容易地发现,在pmda模块的帮助下,单张超分辨模型在双目超分任务上取得巨大的进步。并且,对不同参数量大小的模型都有帮助。这是因为单张超分辨模型不能利用来自另一个视图的交叉视图信息,而pmda可以弥补这一不足。
35.不同模型的定量对比结果列于表3。结果表明,在视差多维度注意力模块的帮助下,本发明提出的级联注意力双目超分网络在三个数据集上几乎都能获得性能最好的,且参数较少。表3中,bicubic代表双三次插值法,passrnet方法来自“l. wang, y. wang, z. liang, z. lin, j. yang, w. an, and y. guo, learning parallax attention for stereo image super
‑
resolution, in ieee, cvpr 2019, pp. 12 250
–
12 259”,san方法来自“t. dai, j. cai, y. zhang, s. xia, and l. zhang, second
‑
order attention network for single image super
‑
resolution, in cvpr 2019, pp. 11 065
–
11 074”,sam方法来自“x. ying, y. wang, l. wang, w. sheng, w.表3
an, and y. guo, a stereo attention module for stereo image super
‑
resolution, ieee signal process. letter, vol. 27, pp. 496
–
500, 2020”。/ 符号的左右两个数值分别代表psnr和ssim两个参考指标。passrnet方法是专门为双目超分设计的方法,可以看出级联注意力双目超分网络在各个方面都领先与它。此外,与本发明的方法类似,sam也是一个嵌入单张超分辨率模型中的通用立体注意力模块。对比srresnet+sam和srresnet+pmda可以发现,pmda比sam具有更强的双目视觉交叉信息利用能力,带来更大的重建效果增益。级联注意力双目超分网络在模型大小,运行时间开销上都取得了极好的效果,证明了该模型是一个轻量级的模型。对比实验的结果证明,级联注意力双目超分网络(pasr模型)能在模型参数和性能之间实现了良好的平衡。
36.在本发明中,介绍了一个视差多维度注意力模块(pmda),这是个通用的模块,用于探索双目输入图像对之间的内在相关性。具体地说,所提出的pmda模块可以捕获通道或空间位置之间的多维度依赖关系。得益于此,现有的单张图像超分方法可以通过直接在网络中插入一个pmda来适应于双目超分任务。通过这样做,单张视图内部和两张视图之间的信息就能被联合挖掘出来,进而提高最终图像超分辨率的性能。实验结果表明,本发明提出的方法在重建效果和模型复杂度上取得了很好的效果,在现有的单张超分方法中加入pmda后,双目超分重建的性能有了显著的提高,但只增加了有限的复杂度。
37.本发明的工作原理及过程为:本发明提出一个新颖的视差多维度注意力模块(parallax multi
‑
dimensional attention module,pmda),它可以准确地捕捉到两个不同视角图片的多维度视差信息。具体来说,除了常用的沿着通道维度的依赖关系,pmda还聚合了空间维度(高度和宽度)之间的交互特征。尽管pmda能捕获立体图像的两个视图之间的交叉视图信息。然而,也应该考虑图像帧内的有用特征。基于pmda,本发明还提出了视觉多维度自注意力模块(self multi
ꢀ‑
dimensional attention,smda),它能在单张图像内部捕捉多维度的信息。得益于pmda和smda,内部视图和帧间的视差信息能够被很好地被生成,这些信息被送到网络的后部分来辅助最终高清图像的复原。由于最近的单张图片超分辨率网络大量使用级联模块,pmda和smda可以很容易地插入到这些网络中以挖掘交叉视图信息,帮助单张图片超分辨率网络扩展到双目超分辨率任务来。
38.本发明的有益效果为:(1)本发明提出一个通用的视差多维度注意力模块,充分挖掘了不同视点产生的双目图像的视差信息,很好地捕捉了双目视差信息在特征空间的多维度表示问题。视差多维度注意力模块可以直接集成到不同的单张图片超分辨率网络中进行多阶段的特征融合,以更好地模拟交叉视图信息交互。
39.(2)基于视差多维度注意力模块,本发明还提出视觉多维度自注意力模块,它能够自适应地从单张图像中学习更多有用的内部视点先验信息。
40.(3)基于视差多维度注意力模块和视觉多维度自注意力模块,本发明还提出一个轻量级的级联注意力双目超分网络,它在模型参数和重建效果上达到很好的平衡。
41.本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1