基于分解的多目标信息处理方法、系统、计算机设备、终端
1.本发明属于计算机技术领域,尤其涉及一种基于分解的多目标信息处理方法、系统、计算机设备、终端。
背景技术:
2.目前,在某一个情境中,无法同时得到多个目标的最优值,在得到某一个目标更好的值的过程中其他目标的值会相应的变差。所以多目标优化算法得到的是一系列最优解而不是单个的最优解。所有的最优解组成一个面,叫做前沿面(pf:pareto front)。要注意的是,一些问题中,pf不连续或者不是一个规则的平面。
3.moea/d算法是一种经典的多目标优化算法,它在目标空间中生成一系列均匀的权重向量,之后在这些权重向量对应的方向上搜索解,从而得到一系列最优解。
4.但是moea/d算法会存在一系列问题,对于不规则的前沿面,得不到均匀的解,而对于不连续的前沿面,会得到一系列重复的解。对于这种情况,前人提出了随机初始向量自适应的基于分解的多目标算法(many
‑
objective evolutionary algorithm based on decomposition with random and adaptive weights:moea/d
‑
uraw)。这一算法首先是权重向量自适应的,即可以调整位置不合适的权重向量从而使得得到的解更加均匀。其次使用了新的随机初始向量生成方法。
5.具体的调整方法是,每次生成新的个体都用来更新归档集(ep),之后删去当前种群中拥挤度最大的个体和其对应的权重向量,计算归档集中的个体到当前种群中剩余个体之间的拥挤度,取出拥挤度值最小的归档集中的个体。之后使用ws变换得到这个归档集中的个体对应的权重向量,将这个个体加入当前种群,将这个权重向量加入当前的权重向量。拥挤度计算这里使用nsga
‑
ii算法中的方法。
6.其次使用了新的随机初始向量生成方法,即首先得到一组初始向量ω1,以目标空间维数m=3为例,首先本发明得到初始向量(1,0,0)、(0,1,0)、(0,0,1)、(1/3,1/3,1/3),之后在目标空间中随机生成5000个向量ω2,再求出ω2与ω1之间距离最大的向量,将其加入ω1,重复这一过程直到得到足够数量的权重向量。
7.但是这一算法存在问题,在算法的初始阶段,原始的moea/d方法中的切比雪夫分解算子会得到距离权重向量较远但是适应度函数值较小的解。这些个体会被选入归档集,通过这些解调整得到的权重向量,可能比原来的权重向量更加不均匀,从而得到质量更差的解。
8.在实际的工业优化问题中,使用多目标优化算法时,面对的问题往往是在两个相互冲突的变量之间做取舍。对于这类问题,不存在单一的最优解,而是一系列解,且分布在一个面上,称为前沿面。原始的算法由于初始阶段的算子不合理,可能得到解的均匀程度不够,或者无法覆盖整个前沿面。当我们得到了正确的前沿面时,对某一目标维度,其值固定时,我们可以得到另一维度上所能取得的最好的值。并且可以得到对应的设计参数。
9.通过上述分析,现有技术存在的问题及缺陷为:(1)原始的算法由于初始阶段的算
子不合理,导致得到解的均匀程度可能不够。从而无法得到前沿面的完整消息,而无法指导问题的解决。
10.(2)在汽车侧碰优化问题中,现有技术在优化车体的总重量(f(x))、所受到的撞击偏转速度(g2(x)~g4(x))、偏转量(g5(x)~g7(x))、腹部受力(g1(x))阴部受力(g8(x))以及v柱处的速度(g9(x)、g
10
(x))时,获得的解均匀程度较低,不能更好的为如何取舍车体重量和安全性提供依据。无法更好的指导汽车生产。
11.(3)在四杆桁架设计问题中,现有的技术在优化结构体积(f1(x))和接头的位移(f2(x))时,获得的解均匀程度较低,不能更好的为如何取舍结构体积和接头的位移提供依据。无法更好的指导机械设计。
12.解决以上问题及缺陷的难度为:
13.对于整个算法的实际应用来说,要得到更好的权重向量,可以通过改变初始阶段的算子实现,难度较大。
14.解决以上问题及缺陷的意义为:
15.本发明在机械设计领域上:在齿轮传动设计问题中,可用于同时优化齿轮大小和传动误差,得到这一问题的前沿面,从而指导机械设计。在减速器设计问题中,可用于同时优化体积大小和轴上的应力,得到这一问题的前沿面,从而指导机械设计。具体来说,当得到了正确的前沿面时,对某一目标维度(例如齿轮大小或者减速器体积),其值固定时,可以得到另一维度(例如传动误差和轴上的应力)上所能取得的最好的值。并且可以得到对应的设计参数,从而指导实际生产。
技术实现要素:
16.针对现有技术存在的问题,本发明提供了一种基于分解的多目标信息处理方法、系统、计算机设备、终端。具体涉及一种带预处理的随机初始向量自适应的基于分解的多目标信息处理方法。
17.本发明是这样实现的,一种带预处理的随机初始向量自适应的基于分解的多目标信息处理方法,应用于信息数据处理终端,所述带预处理的随机初始向量自适应的基于分解的多目标信息处理方法包括:
18.步骤一,所述信息数据处理终端初始化种群,归档集和权重向量集;并且对初始权重向量集进行变换;假设目标空间为三维空间,则假设初始向量为λ,包含四个向量(1,0,0)、(0,1,0)、(0,0,1)、之后随机生成5000个向量的向量组λ
′
,计算λ
′
中每个个体到λ的距离,取出所有距离中最小的值最大的个体a,将a加入λ,并将a从λ
′
中删去,重复这一过程直到λ的个体数量足够。之后对λ进行ws变换,即假设有权重向量a=(λ1,λ2,...,λ
m
),其中m为目标空间维度,则ws变换后得到的向量为将ws变换之后的向量作为初始的权重向量。之后计算权重向量集中每个个体的相邻个体,参考点和极值点;权重向量集中每个个体的相邻个体即与每个权重向量欧几里得距离最近的个体,参考点和极值点即为当前种群在目标空间中每一维上的最小值和最大值。
19.步骤二,判断当前代数是否小于总代数乘以系数μ,即假设当前代数为gen,若gen
小于gen
max
×
μ,则转向步骤三;否则转向步骤四;
20.步骤三,标准化当前种群更新参考点和极值点,标准化方法为寻找距离几个坐标轴最近的点,之后计算这些点组成的平面与坐标轴的截距,之后将所有个体在目标空间中的值减去参考点的值,再对得到的值对每一维除以上面得到的截距即为归一化后的值,对当前的权重向量进行ws变换,生成子代并且使用moea/d
‑
du中的方法更新当前种群,即先挑选子代中距离权重向量近的个体,之后按照这一距离排序,先计算距离近的个体的适应度函数值,适应度函数的计算方法为x为个体,为参考点在第k维上的值,一旦子代的适应度函数值比原来权重向量对应的小,即用子代中个体替代父代中个体,更新过程结束;之后更新归档集,即将子代个体和原有归档集中的个体混合,计算混合后个体的拥挤度,拥挤度的计算方法为混合,计算混合后个体的拥挤度,拥挤度的计算方法为其中ind
j
为第j个个体,为第j个个体和第i个个体之间的欧几里得距离。即对某一个个体,其拥挤度为与其最近的m个个体与之距离的乘积。这一值越小越拥挤。之后将拥挤度大的个体删去直到归档集中个体数量合适,转向步骤七;
21.步骤四,判断当前代数gen是否小于gen
max
×
0.8,若小于,转向步骤五,反之转向步骤六;
22.步骤五,生成子代并且用切比雪夫算子更新当前种群,即计算子代个体的适应度函数值,计算方法为若比父代的适应度函数小,则用子代的个体更新父代的个体;更新归档集,方法同步骤三中的更新归档集方法;更新当前权重向量,即计算当前种群的拥挤度,每次删去固定数量的拥挤程度最大的个体和其对应的权重向量,之后计算归档集中个体到当前种群个体之间的拥挤度,每次将固定数量的拥挤度最大的个体进入当前种群,且将这些个体经过ws变换后的向量加入当前权重向量;转向步骤七;
23.步骤六,生成子代并且用切比雪夫算子更新当前种群,同步骤五中使用切比雪夫算子更新的方法;转向步骤七;
24.步骤七,代数加1,并判断当前代数gen是否小于gen
max
,若是,则返回步骤二;否则,即可输出计算结果。
25.本发明的另一目的在于提供一种带预处理的随机初始向量自适应的基于分解的多目标信息处理系统,应用于信息数据处理终端,包括:
26.初始化模块,初始化种群,归档集和权重向量集;并且对初始权重向量集进行变换;计算权重向量集中每个个体的相邻个体,参考点和极值点;
27.迭代计算模块,判断当前代数是否小于总代数乘以系数μ,若小于,则进行:转向更新当前种群模块;否则转向当前代数判断模块;
28.更新当前种群模块,标准化当前种群更新参考点和极值点,对当前的权重向量进行ws变换,生成子代并且使用moea/d
‑
du中的方法更新当前种群,更新归档集,转向gen
max
模块判断模块;
29.当前代数判断模块,用于判断当前代数是否小于gen
max
×
0.8,若小于,转向更新当前权重向量模块,反之转向更新当前种群模块;
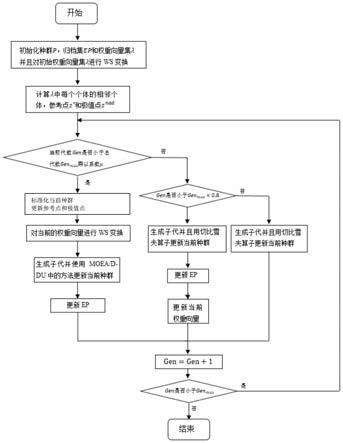
30.更新当前权重向量模块,用于生成子代并且用切比雪夫算子更新当前种群;更新归档集;更新当前权重向量;转向gen
max
模块判断模块;
31.更新当前种群模块,用于生成子代并且用切比雪夫算子更新当前种群;转向gen
max
模块判断模块;
32.总代数最大值判断模块,用于代数加1,并判断当前代数是否小于gen
max
,若是,则返回迭代计算模块;否则,即可输出计算结果。
33.本发明另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行所述带预处理的随机初始向量自适应的基于分解的多目标信息处理方法。
34.本发明另一目的在于提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行所述带预处理的随机初始向量自适应的基于分解的多目标信息处理方法。
35.本发明另一目的在于提供一种信息数据处理终端,其特征在于,所述信息数据处理终端用于实现所述的任意一项所述带预处理的随机初始向量自适应的基于分解的多目标信息处理方法。
36.结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明使用moea/d
‑
du算法中新的筛选解的方法,得到更加趋近于当前权重向量的结果,从而生成位置更合适的新权重向量。最终得到质量更高的计算结果。以具体的机械设计问题为例,这一方法可以得到更加合理分配方案。
37.下面是对比的技术效果或者实验效果。
38.这里本发明需要优化一个实际问题——汽车侧面碰撞问题。
39.假设对汽车的侧面进行碰撞,则会对假人造成冲击。加大车壁的厚度可以减小冲击,但是会增加重量,从而提高燃油成本。
40.本发明需要同时优化车体的总重量(f(x))和假人所受到的撞击偏转速度(g2(x)~g4(x))、偏转量(g5(x)~g7(x))、腹部受力(g1(x))阴部受力(g8(x))以及v柱处的速度(g9(x)、g
10
(x))。
41.优化结果可以用下面的折线图6表示,每一条折线代表一个解,横轴上的刻度代表每一个待优化的目标空间维度,而纵轴上读出来的值代表每个解在这个维度上对应的实际值。要注意的是,由于要优化的目标有多维,而且这些目标之间互相冲突,所以这类问题的解不会是单个的解,而是一组解。
42.对于汽车侧碰优化问题的一组解(如图6)直接观察很难判断其好坏。于是,对于多目标优化问题,本发明使用解质量的评价参数来评价得到的解。这里使用三种评价参数:δ
p
、gd、spread,这三个参数的值越小,对应的解的质量越高。
43.下面是新的算法和旧的算法的比较。种群大小设置为346,最大演化代数maxfe=173000,δ设置为0.8,全部的算法都测试30次。括号前的值为30次试验得到的评价参数平均值,括号中的值为评价参数的标准差。可见,在所有参数上新算法都得到了更小的评价参数平均值,即对应更好的结果。
44.表1评价参数
[0045] 旧算法新算法δ
p
6.0298e+1(9.12e
‑
2)6.0130e+1(9.52e
‑
2)gd3.2500e+0(4.94e
‑
3)3.2401e+0(5.26e
‑
3)spread6.6802e
‑
1(1.21e
‑
2)6.3696e
‑
1(1.20e
‑
2)
[0046]
这里本发明优化了另一个实际问题——四杆桁架设计问题。
[0047]
该桁架的设计以结构体积f1(x)和接头位移f2(x)为目标函数,并受到与构件应力相关的四个约束。构件横截面面积作为设计变量。同样,这一问题的解也是一组解,直接观察很难判断其好坏。于是,本发明使用解质量的评价参数来评价得到的解。这里使用两种评价参数:spacing、spread,这两个参数的值越小,对应的解的质量越高。可见,在所有参数上新算法都得到了更小的评价参数平均值,即对应更好的结果。
[0048]
表2评价参数
[0049] 旧算法新算法spacing9.6200e+0(1.25e+0)
‑
3.3218e+0(3.49e
‑
1)spread8.7846e
‑
1(5.15e
‑
2)
‑
7.0789e
‑
1(1.05e
‑
2)
附图说明
[0050]
为了更清楚地说明本技术实施例的技术方案,下面将对本技术实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
[0051]
图1是本发明实施例提供的调整前的个体示意图。
[0052]
图2是本发明实施例提供的调整后的个体示意图。
[0053]
图3是本发明实施例提供的带预处理的随机初始向量自适应的基于分解的多目标信息处理方法原理图。
[0054]
图4是本发明实施例提供的带预处理的随机初始向量自适应的基于分解的多目标信息处理方法流程图。
[0055]
图5是本发明实施例提供的带预处理的随机初始向量自适应的基于分解的多目标信息处理系统结构示意图;
[0056]
图中:1、初始化模块;2、迭代计算模块;3、更新当前种群模块;4、当前代数判断模块;5、更新当前权重向量模块;6、更新当前种群模块;7、总代数最大值判断模块。
[0057]
图6是本发明实施例提供的对于汽车侧碰优化问题的一组解示意图。
具体实施方式
[0058]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0059]
针对现有技术存在的问题,本发明提供了一种带预处理的随机初始向量自适应的基于分解的多目标信息处理方法,下面结合附图对本发明作详细的描述。
[0060]
在本发明一实施例中,叙述问题的处理流程:
[0061]
步骤一,所述信息数据处理终端初始化种群(这里输入每个任务对应的成本和收益,之后随机选择预定数量的任务作为一个个体,重复选择n次得到n个个体,得到初始的种群),归档集和权重向量集(由于这里需要优化的目标只有两个,权重向量集为二维的);并且对初始权重向量集进行变换;之后计算权重向量集中每个个体的相邻个体,参考点和极值点(参考点和极值点分别为初始种群中个体对应的最低的和最高的总花费和总收益)。
[0062]
步骤二,判断当前代数是否小于总代数乘以系数μ,即假设当前代数为gen,若gen小于gen
max
×
μ,则转向步骤三;否则转向步骤四;
[0063]
步骤三,标准化当前种群更新参考点和极值点(这里的标准化,即将所有个体的总花费和收益投影在一个平面上),对当前的权重向量进行ws变换,生成子代并且使用moea/d
‑
du中的方法更新当前种群;之后更新归档集(去除那些花费和收益值被支配的个体),转向步骤七;
[0064]
步骤四,判断当前代数gen是否小于gen
max
×
0.8,若小于,转向步骤五,反之转向步骤六;
[0065]
步骤五,生成子代并且用切比雪夫算子更新当前种群(即计算新个体和旧个体的总花费和总收益对应的适应度函数值,若新个体的小,用新个体替换旧个体);更新归档集;更新当前权重向量(使用归档集中个体的花费和收益生成新的权重向量);转向步骤七;
[0066]
步骤六,生成子代并且用切比雪夫算子更新当前种群;转向步骤七;
[0067]
步骤七,代数加1,并判断当前代数gen是否小于gen
max
,若是,则返回步骤二;否则,即可输出计算结果。
[0068]
在本发明中,图1是本发明实施例提供的调整前的个体示意图。图2是本发明实施例提供的调整后的个体示意图。图3是本发明实施例提供的带预处理的随机初始向量自适应的基于分解的多目标信息处理方法原理。
[0069]
如图4所示,本发明实施例提供的带预处理的随机初始向量自适应的基于分解的多目标信息处理方法包括以下步骤:
[0070]
s101,初始化种群,归档集和权重向量集;并且对初始权重向量集进行变换;计算权重向量集中每个个体的相邻个体,参考点z
*
和极值点z
nad
;
[0071]
s102,判断当前代数是否小于总代数乘以系数μ,若小于,则转向步骤s103;否则转向步骤s104;
[0072]
s103,标准化当前种群更新参考点和极值点,对当前的权重向量进行ws变换,生成子代并且使用moea/d
‑
du中的方法更新当前种群,更新归档集,转向步骤s107;
[0073]
s104,判断当前代数是否小于gen
max
×
0.8,若小于,转向步骤s105,反之转向步骤s106;
[0074]
s105,生成子代并且用切比雪夫算子更新当前种群;更新归档集;更新当前权重向量;转向步骤s107;
[0075]
s106,生成子代并且用切比雪夫算子更新当前种群;转向步骤s107;
[0076]
s107,代数加1,并判断当前代数是否小于gen
max
,若是,则返回步骤s102;否则,即可输出计算结果。
[0077]
步骤s101中,初始化种群,归档集和权重向量集;并且对初始权重向量集进行变
换;假设目标空间为三维空间,则假设初始向量为λ,包含四个向量(1,0,0)、(0,1,0)、(0,0,1)、之后随机生成5000个向量的向量组λ
′
,计算λ
′
中每个个体到λ的距离,取出所有距离中最小的值最大的个体a,将a加入λ,并将a从λ
′
中删去,重复这一过程直到λ的个体数量足够。之后对λ进行ws变换,即假设有权重向量a=(λ1,λ2,...,λ
m
),其中m为目标空间维度,则ws变换后得到的向量为将ws变换之后的向量作为初始的权重向量。之后计算权重向量集中每个个体的相邻个体,参考点和极值点;权重向量集中每个个体的相邻个体即与每个权重向量欧几里得距离最近的个体,参考点和极值点即为当前种群在目标空间中每一维上的最小值和最大值。
[0078]
步骤s102中,判断当前代数是否小于总代数乘以系数μ,即假设当前代数为gen,若gen小于gen
max
×
μ,则转向步骤s103;否则转向步骤s104;
[0079]
步骤s103中,标准化当前种群更新参考点和极值点,标准化方法为寻找距离几个坐标轴最近的点,之后计算这些点组成的平面与坐标轴的截距,之后将所有个体在目标空间中的值减去参考点的值,再对得到的值对每一维除以上面得到的截距即为归一化后的值,对当前的权重向量进行ws变换,生成子代并且使用moea/d
‑
du中的方法更新当前种群,即先挑选子代中距离权重向量近的个体,之后按照这一距离排序,先计算距离近的个体的适应度函数值,适应度函数的计算方法为x为个体,为参考点在第k维上的值,一旦子代的适应度函数值比原来权重向量对应的小,即用子代中个体替代父代中个体,更新过程结束;之后更新归档集,即将子代个体和原有归档集中的个体混合,计算混合后个体的拥挤度,拥挤度的计算方法为其中ind
j
为第j个个体,为第j个个体和第i个个体之间的欧几里得距离。即对某一个个体,其拥挤度为与其最近的m个个体与之距离的乘积。这一值越小越拥挤。之后将拥挤度大的个体删去直到归档集中个体数量合适,转向步骤s107;
[0080]
步骤s105中,生成子代并且用切比雪夫算子更新当前种群,即计算子代个体的适应度函数值,计算方法为若比父代的适应度函数小,则用子代的个体更新父代的个体;更新归档集,方法同步骤s103中的更新归档集方法;更新当前权重向量,即计算当前种群的拥挤度,每次删去固定数量的拥挤程度最大的个体和其对应的权重向量,之后计算归档集中个体到当前种群个体之间的拥挤度,每次将固定数量的拥挤度最大的个体进入当前种群,且将这些个体经过ws变换后的向量加入当前权重向量;转向步骤步骤s107。
[0081]
如图5所示,本发明实施例提供的带预处理的随机初始向量自适应的基于分解的多目标信息处理系统包括:
[0082]
初始化模块1,初始化种群,归档集和权重向量集;并且对初始权重向量集进行变换;计算权重向量集中每个个体的相邻个体,参考点和极值点;
[0083]
迭代计算模块2,判断当前代数是否小于总代数乘以系数μ,若小于,则进行:转向更新当前种群模块;否则转向当前代数判断模块;
[0084]
更新当前种群模块3,标准化当前种群更新参考点和极值点,对当前的权重向量进行ws变换,生成子代并且使用moea/d
‑
du中的方法更新当前种群,更新归档集,转向gen
max
模块判断模块;
[0085]
当前代数判断模块4,用于判断当前代数是否小于gen
max
×
0.8,若小于,转向更新当前权重向量模块五,反之转向更新当前种群模块;
[0086]
更新当前权重向量模块5,用于,生成子代并且用切比雪夫算子更新当前种群;更新归档集;更新当前权重向量;转向gen
max
模块判断模块;
[0087]
更新当前种群模块6,用于生成子代并且用切比雪夫算子更新当前种群;转向gen
max
模块判断模块;
[0088]
总代数最大值判断模块7,用于代数加1,并判断当前代数是否小于gen
max
,若是,则返回迭代计算模块;否则,即可输出计算结果。
[0089]
下面结合具体实施例对本发明的技术效果作进一步描述。
[0090]
实施例1:
[0091]
下面举一个目标空间维度为2的实际例子,假设有如表3的权重向量,和如同下面式子的前沿面,那么经过足够的演化代数,就能够得到这些权重向量如表3在pf上的对应的解。由于要观察权重向量调整对于解的影响,这里考虑演化代数足够之后的最终解,即表中在pf上的对应解的情况。这些解的hv值为0.1925。hv为超立方体积值,越大代表解质量越好。
[0092][0093]
表3调整前的权重向量和其对应的在pf上的解
[0094][0095]
另外,假设有如同表4中的当前个体和归档集。将归档集和当前种群以及当前的权重向量均如图1所示。
[0096]
表4当前种群中的个体和归档集中的个体
[0097]
[0098][0099]
之后开始调整权重向量,每次调整20%的权重向量,即调整一个。这里当前种群的拥挤度值最小的个体是(1.4615,1.1768),其对应的权重向量为(1/2,1/2),那么本发明删掉这个个体和其对应的权重向量。之后,计算归档集中个体与当前种群剩余个体之间的拥挤度,取出拥挤度最小的个体(0.5116,1.5265)加入当前种群,由这个个体生成的权重向量加入当前的权重向量,新的权重向量和权重向量对应的在pf上的解如表5,具体的调整后的个体如图2。
[0100]
表5调整后的权重向量和其对应的在pf上的解
[0101]
[0102][0103]
计算调整后,在pf上的对应解的情况。这些解的hv值为0.1609。这意味着,调整向量过后,得到的解的质量下降了。调整之后,权重向量变得更加不均匀。
[0104]
所以本发明考虑在算法的初始阶段加入moea/d
‑
du的算子,得到更加靠近权重向量的种群和归档集。从而提高解的质量。
[0105]
具体的流程如图3,新算法在前gen
max
×
μ代使用moea/d
‑
du的算子。
[0106]
4.实验情况
[0107]
实验将新算法与与之相关的moea/d、moea/d
‑
awa、moea/d
‑
uraw算法进行对比。使用的测试集为wfg和dtlz,实验分别在5/10/15/20目标空间维度上进行,μ取0.35,σ取0.8,种群大小取120,迭代次数为60000,每个例子分别计算30次,结果如下(括号前的值为30次的平均值):
[0108]
表6实验结果对比
[0109]
[0110]
[0111]
[0112][0113]
根据表6实验结果可知,moea/d
‑
pauraw算法与原来的算法相比有较大的改进(在一共64个问题中,经过wilcox秩和检验,moea/d
‑
pauraw比moea/d
‑
uraw相比结果为10个差,28个好,26个平,其他算法表现比moea/d
‑
uraw更差;而单纯考虑得到最好的解,见表,在64个问题中的34个moea/d
‑
pauraw得到了最好的解,moea/d
‑
uraw在其中的18个问题上得到了最好的解,其他算法表现比moea/d
‑
uraw更差)。
[0114]
实施例2
[0115]
本发明需要优化一个实际问题——汽车侧面碰撞问题。
[0116]
假设对汽车的侧面进行碰撞,则会对假人造成冲击。加大车壁的厚度可以减小冲击,但是会增加重量。
[0117]
表7决策变量
[0118]
决策变量变量范围b柱内部厚度(x1)0.5≤x1≤1.5b柱加固厚度(x2)0.45≤x2≤1.35地板内侧厚度(x3)0.5≤x3≤1.5横梁厚度(x4)0.5≤x4≤1.5门梁厚度(x5)0.875≤x5≤2.625门带线加固厚度(x6)0.4≤x6≤1.2车顶纵梁厚度(x7)0.4≤x7≤1.2
[0119]
表8固定参数
[0120]
固定参数具体值b柱材料(x8)0.345地板内侧材料(x9)0.192障碍物高度(x
10
)0障碍物碰撞位置(x
11
)0
[0121]
表9目标参数
[0122][0123]
于是这里本发明需要同时优化车体的总重量(f(x))和假人所受到的撞击偏转速度(g2(x)~g4(x))、偏转量(g5(x)~g7(x))、腹部受力(g1(x))阴部受力(g8(x))以及v柱处的速度(g9(x)、g
10
(x))。
[0124]
优化结果可以用下面的折线图6表示,每一条折线代表一个解,横轴上的刻度代表每一个待优化的目标空间,而纵轴上读出来的值代表每个解在这个维度上对应的解。由于要优化的目标有多维,而且这些目标之间互相冲突,所以这类问题的解不会是单个的解,而是一组解。
[0125]
对于汽车侧碰优化问题的一组解(如图6)直接观察很难判断其好坏。于是,对于多目标优化问题,本发明使用解质量的评价参数来评价得到的解。这里使用三种评价参数:δ
p
、gd、spread,这三个参数的值越小,对应的解的质量越高。
[0126]
实施例3
[0127]
本发明需要优化一个实际问题——四杆桁架设计问题。
[0128]
表10决策变量
[0129][0130]
表11固定参数
[0131]
固定参数具体值受力(f)10压强1(e)2
×
105杆长(l)200压强2(σ)10
[0132]
表12目标参数
[0133][0134]
该桁架的设计以结构体积f1(x)和接头位移f2(x)为目标函数,并受到与构件应力相关的四个约束。构件横截面面积作为设计变量。同样,这一问题的解也是一组解,直接观察很难判断其好坏。于是,本发明使用解质量的评价参数来评价得到的解。这里使用两种评价参数:spacing、spread,这两个参数的值越小,对应的解的质量越高。
[0135]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1