一种基于序列到隐写序列的自然语言信息隐藏方法
1.本发明涉及信息安全领域,尤其涉及一种基于序列到隐写序列的自然语言信息隐藏系统及方法。
背景技术:
2.在当今社会,信息安全一直是不容忽视的一个问题,人们对秘密通信(即在通信过程中第三方无法知晓通信的存在及通信的内容)的需求越来越庞大。目前,保证秘密通信安全的技术手段主要有两种:密码技术和信息隐藏技术。其中,采用密码技术加密后的通信内容往往是杂乱无章的乱码,非授权用户不可读,从而保证通信内容的安全,但另一方面这种特殊性,也容易暴露秘密通信的事实,引起攻击者的注意和有针对性的攻击。而信息隐藏技术则克服了加密后的载体容易引起第三方攻击这一弊端,将秘密信息隐藏到某种正常的公开载体中,通过含密载体的传输实现安全的隐蔽通信。由于秘密信息的存在性被掩藏,从而不容易引起攻击者的怀疑进而进行攻击。以文本内容为载体的生成式自然语言信息隐藏方法发展较为迅速,尽管这类方法能够大大地提高生成的隐写文本的质量以及嵌入容量,但是这些方法局限在自动生成短文本,生成的隐写文本越长质量越差,且句子之间的语义相关性越来越低。为了保证隐写文本的质量,生成文本不宜过长,此时实际的可安全嵌入的秘密信息偏少。
3.为了解决高质量长隐写文本的生成问题以及提高隐写文本生成模型的通用性,本发明提出了基于序列到隐写序列模型的自然语言信息隐藏方法,可以适用于各种生成式自然语言信息隐藏方法,本发明自动生成的隐写摘要文本较长,可隐藏的秘密信息更多,同时隐写文本的质量更高,具有更好的隐蔽性。
技术实现要素:
4.为实现本发明之目的,采用以下技术方案予以实现:
5.一种基于序列到隐写序列的自然语言信息隐藏方法,包括以下步骤:
6.步骤1.数据预处理;
7.步骤2.语言编码;
8.步骤3.信息隐写;
9.其中步骤1包括:对文本数据集所包含的文本内容进行分词,并且对词的统计学信息进行搜集统计,得出词汇表、词频,利用语料库训练分布式词向量表示模型,获得词汇表中每个词的稠密低维词向量。
10.所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤2包括:
11.将长文本作为源文本发送给语言编码器,语言编码器将源文本通过分布式词向量模型转换成向量作为输入并进行编码,产生固定长度的语言编码器隐藏状态h
i
;
12.结合隐写器的隐藏状态s
t
,计算注意力分布:
[0013][0014]
其中,v,w
s
,w
h
,b
attn
都为神经网络学习到的参数,a
t
为注意力分布;
[0015]
语言编码器根据注意力分布产生一个语言编码器的隐藏状态加权和,即上下文向量
[0016][0017]
语言编码器输出一个上下文向量和一个注意力分布a
t
,这里的注意力分布视为输入序列的概率分布。
[0018]
所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤2还包括:
[0019]
语言编码器还计算一个概率覆盖向量c
t
:
[0020][0021]
使用概率覆盖向量更新注意力模块:
[0022][0023]
用公式(6)代替公式(3)中的第一步计算。
[0024]
所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤3包括:
[0025]
隐写器接收语言编码器输出的上下文向量将其和隐写器的隐藏状态s
t
一起通过两个线性层,产生词汇表概率分布p
vocab
:
[0026][0027]
p
vocab
是词汇表中所有单词的概率分布,b,b’都是神经网络学习到的参数。
[0028]
隐写器将所得到的上下文向量隐写器隐藏状态s
t
和隐写器当前时刻t的输入x
t
共同计算一个生成概率p
gen
∈[0,1]:
[0029][0030]
其中,σ是sigmoid激活函数,b
ptr
是神经网络学习到的参数。
[0031]
生成摘要中的词w的概率由词汇表概率分布和输入序列概率a
t
分布共同获得,如果w未在源文本中出现,则注意力分布词w的概率完全由生成的词汇表概率分布决定;如果w未在词汇表中出现,那么p
vocab
为0,词w的概率由输入序列的概率分布决定,即词w的概率为从输入序列中复制w的概率,词w的生成概率的具体计算过程见公式(9),
[0032][0033]
通过上述过程,隐写器预测得到当前时刻生成词的概率分布,然后再利用预先设计好的基于多候选的动态隐写编码方法和秘密信息,对词概率分布进行选择,解码并输出所选择词概率对应的词,从而生成含秘密信息的隐写摘要文本。
[0034]
所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤3还包括基于多
候选的动态隐写编码方法:1)动点判断、2)不动点优化输出、3)动点隐写编码;其中,
[0035]
1)动点判断:假设t
‑
1时刻生成的第i个候选隐写序列为i表示候选隐写位置的序号,根据训练好的序列到隐写序列模型,预测t时刻的生成词概率分布,取概率最高的k个词作为候选词;设按降序排列后的候选词分别为:w
i1
,w
i2
,...,w
ik
,记候选词与候选隐写序列组成的联合序列即候选嵌入位置为秘密信息嵌入条件定义如下:
[0036][0037]
其中p(st
ij
)表示词序列st
ij
的概率值,由隐写器根据词序列st
ij
中每个词的生成概率值计算得出;α、β为阈值,如果满足上述条件的候选嵌入位置st
i
的数量至少有2个,则当前t时刻为动点,将用来嵌入信息;否则为不动点,不能用来嵌入信息;对每个生成时刻进行动点与不动点的判定,从而在文本生成过程中动态地选择时刻嵌入秘密信息;
[0038]
2)不动点优化输出:
[0039]
对于不动点时刻t,设t时刻k个候选嵌入位置为st1,...,st
i
,...st
k
,其中按照序列概率值p(st
ij
)对k
×
k个联合序列st
ij
降序排序,st'
11
,...,st'
1k
,...,st'
k1
,...,st'
kk
,最后选择概率值最高的k个序列st'
11
,...,st'
1k
作为当前时刻的输出,即其中
[0040]
3)动点隐写编码
[0041]
对于动点时刻t,设t
‑
1时刻生成的候选隐写序列为候选隐写序列的概率值为t时刻的k个候选嵌入位置为st1,...,st
i
,...st
k
,其中计算每个满足嵌入条件的候选嵌入位置st
i
中所有候选项的平均概率值根据候选嵌入位置的平均概率值,选择最高的两个候选嵌入位置st
a
和st
b
来编码秘密信息,其中
[0042][0043]
a表示平均概率值最大的候选嵌入位置,b表示平均概率值次大的候选嵌入位置;两个候选嵌入位置st
a
和st
b
分别编码为0和1,具体编码规则如下:
[0044]
其中c(
·
)表示编码值。
[0045]
所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤3还包括:
[0046]
嵌入步骤:
[0047]
(1)确定当前t时刻是动点还是不动点;
[0048]
(2)如果当前时刻是动点,则进行秘密信息嵌入。当待嵌入的秘密信息比特为m=0时,选择st
a
中的k个候选序列作为t时刻的输出,即
当待嵌入的秘密信息比特为m=1时,选择st
b
中的k个候选序列作为t时刻的输出,即中的k个候选序列作为t时刻的输出,即
[0049]
(3)如果当前时刻是不动点,在当前时间步长t,隐写器对全部的候选嵌入位置st={st1,...,st1,
…
,st
k
}中的全部k
×
k个候选隐写序列进行排序,选择排序后前k个概率值最高的候选序列记为作为t时刻的输出,
[0050]
所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤3还包括:
[0051]
(4)重复进行步骤(1)到步骤(3)的操作,直到将秘密信息全部嵌入完毕,进入步骤(5);
[0052]
(5)在遇到结束符或达到最大长度之前,将之后的所有时刻视为不动点来进行信息嵌入,最终得到k个候选隐写摘要文本,选择概率值最高的候选隐写摘要文本作为最终隐写摘要文本y。
[0053]
所述的基于序列到隐写序列的自然语言信息隐藏方法,其中步骤3还包括:
[0054]
提取步骤:
[0055]
接收方在接收到发送方通过公开渠道所发送的源文本即原始长文本和含有秘密信息的隐写摘要文本后,再根据发送方秘密提供的秘密信息长度、起始标志符等参数信息以及训练好的序列到隐写序列模型提取隐写摘要文本中秘密信息,具体的提取步骤如下:
[0056]
(1)把源文本输入到训练好的语言编码器中,得到t时刻上下文向量和注意力分布a
t
,并输入隐写器,结合t时刻之前生成的候选摘要序列,预测得到词汇表和源文本中所有词作为t时刻生成词的概率分布;
[0057]
(2)隐写器进行动点判断:
[0058]
如果当前t时刻是动点,则隐写器根据动点隐写编码的规则对两个候选嵌入位置st
a
和st
b
进行编码,设隐写摘要文本中当前t时刻的词为w
t
',则遍历st
a
和st
b
中t时刻预测生成的候选词w
a1
,w
a2
,...,w
ak
和w
b1
,w
b2
,...,w
bk
,如果w
t
'=w
aj
,j∈[1,k],则当前t时刻提取的秘密信息比特值m=c(st
a
)=0,并输出st
a
中的k个候选序列作为下一时刻隐写器的输入;如果w
t
'=w
bj
,j∈[1,k],则当前t时刻提取的秘密信息比特值m=c(st
b
)=1,并输出st
b
中的k个候选序列作为下一时刻隐写器的输入;
[0059]
如果当前t时刻是不动点,则表示该位置没有嵌入信息,不进行信息提取,按照不动点优化输出的原则,输出当前时刻概率最高的k个摘要生成序列
[0060]
(3)重复步骤(1)和(2),直到秘密信息提取完毕。
附图说明
[0061]
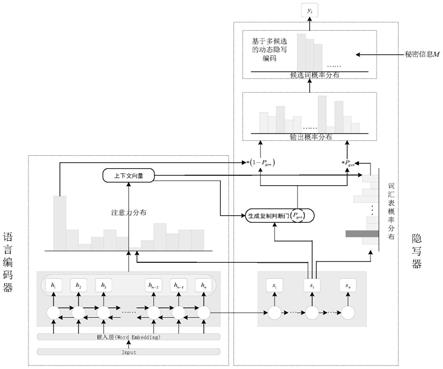
图1为基于序列到隐写序列的自然语言信息隐藏方法的生成框架示意图;
[0062]
图2(a)为序列到隐写序列模型的训练模式示意图;
[0063]
图2(b)为序列到隐写序列模型的信息嵌入模式示意图;
[0064]
图2(c)为序列到隐写序列模型的信息提取模式示意图;
[0065]
图3为基于多候选的动态隐写编码示例图。
具体实施方式
[0066]
下面结合附图对本发明的具体实施方式进行详细说明。
[0067]
如图1所示,基于序列到隐写序列模型的自然语言信息隐藏方法是基于序列到隐写序列模型框架实现的,该序列到隐写序列模型框架主要包括语言编码器和隐写器。语言编码器将模型的输入编码,得到编码器的隐藏状态。隐写器根据编码器的隐藏状态进行解码,将秘密信息值编码在解码出的输出词中。如图2所示,序列到隐写序列模型有三种工作模式,隐写自由模式、隐写强制模式和隐写解码模式。给定输入语句x={x1,x2,
…
x
l
},其中x
t
表示输入的第t个词;语言编码器在每个时间步t,将输入语句x编码成隐藏状态h
t
。将语言编码器的隐藏状态输入隐写器,在秘密信息m={m1,m2,
…
m
n
}的控制下,获得目标隐写语句y={y1,y2,
…
y
n
},其中y
t
表示生成的第t个隐写词。为了通过学习编码x、在解码生成y时成功编码m,需要建模条件概率分布p(y|(x,m))。因此需要先训练序列到隐写序列模型,如图2(a)所示,再生成目标隐写序列,如图2(b)所示,从隐写序列中提取秘密信息,则如图2(c)所示,即序列到隐写序列模型将工作在三种模式下:训练过程的隐写自由模式;信息嵌入过程的隐写强制模式;信息提取过程的隐写解码模式。
[0068]
具体的,基于序列到隐写序列模型的自然语言信息隐藏方法包括以下步骤:
[0069]
步骤1.数据预处理
[0070]
对文本数据集(例如网络上已公开的文本数据集)所包含的文本内容进行分词,并且对词的统计学信息进行搜集统计,得出词汇表、词频。利用语料库训练分布式词向量表示模型,获得词汇表中每个词的稠密低维词向量。本发明采用word2vec模型进行词向量化操作。
[0071]
根据训练好的word2vec模型,对每个单词进行编码,将每个字符编码成长度为m的向量,得到分布式词向量模型。例如对于“to whom is”中的“is”,使用word2vec模型向量化编码后,得到的向量为[0.28079075,
‑
0.2484336,0.52032655,0.46205002,
‑
0.50065434,
…
,
‑
0.61036223,
‑
0.48353505,0.7677468,0.5001733,0.16053177]。
[0072]
步骤2.语言编码
[0073]
将长文本作为源文本,经过数据预处理步骤,转换成词向量形式,输入到语言编码器,语言编码器用bi
‑
lstm(双向长短期记忆模型)进行编码,由此产生固定长度的语言编码器隐藏状态h
i
,其中长文本中的每一个词向量对应一个语言编码器隐藏状态h
i
。再结合隐写器的隐藏状态s
t
,计算注意力分布:
[0074][0075]
其中,v,w
s
,w
h
,b
attn
都为神经网络学习到的参数,为摘要文本中第t个词与源文本中第i个词的相关性,注意力分布a
t
可以看作是输入序列概率分布,可以表示长文本(源文本)中每一个词的重要程度,隐写器可据此去确定在哪里寻找产生摘要中的下一个词。
[0076]
语言编码器根据注意力分布产生一个语言编码器的隐藏状态加权和,即上下文向量
[0077][0078]
上下文向量可以看作是在当前步骤下从源文本中读取到的信息的一个聚合。
[0079]
经过上述过程后,编码器最终输出一个上下文向量和一个输入序列概率分布a
t
(即注意力分布)。
[0080]
为了解决文本摘要中存在重复性的问题,本发明还计算一个概率覆盖向量(coverage vector):
[0081][0082]
概率覆盖向量是隐写器t时刻之前所有注意力分布之和,c
t
是代表分布在源文本中词的覆盖程度。使用概率覆盖向量去更新注意力分布计算公式(3):
[0083][0084]
用公式(6)代替公式(3)中的第一步计算,能够优化注意力分布a
t
的值。这将使得注意力机制更容易避免关注重复相同的位置,从而避免产生重复的文本。
[0085]
步骤3.信息隐写
[0086]
隐写器接收语言编码器输出的上下文向量再由其和隐写器的隐藏状态s
t
一起通过两个线性层,产生词汇表概率分布p
vocab
:
[0087][0088]
p
vocab
是词汇表中所有单词的概率分布,即词汇表中的所有单词在源文本的每个词向量位置处出现的概率,b,b’都是神经网络学习到的参数。
[0089]
隐写器将所得到的上下文向量隐写器隐藏状态s
t
和隐写器当前时刻t的输入x
t
共同计算一个生成概率p
gen
∈[0,1]:
[0090][0091]
x
t
是摘要文本向量,t=0,x
t
为预定义的起始词向量,t>0,x
t
为上一时刻隐写器输出词对应的词向量;b
ptr
是神经网络学习到的参数。
[0092]
生成概率p
gen
∈[0,1]可看作一个软开关,在生成摘要时,根据p
gen
可以选择是通过从p
vocab
中取样以从词汇表中生成一个单词,或者,从输入序列概率分布a
t
中取样,以从输入序列(源文本)中复制一个单词。
[0093]
生成摘要文本中当前时刻的词w的概率由词汇表概率分布和输入序列概率a
t
分布共同获得,如果w未在源文本中出现,即源文本中任意词w
i
≠w,则注意力分布如果w未在词汇表中出现,那么p
vocab
为0。
[0094][0095]
p(w)表示词w作为摘要文本中t时刻生成词的预测概率值;通过公式(9)将计算词
汇表和源文本中所有词的预测概率值。当pgen=0,只从词汇表中选择单词,pgen=1,从输入序列(源文本)复制单词。
[0096]
通过上述过程,隐写器将预测得到t时刻生成词的概率分布,然后再利用设计好的基于多候选的动态隐写编码方法和秘密信息,对词概率分布进行选择,解码并输出所选择词概率对应的词,从而生成含秘密信息的隐写摘要文本。
[0097]
生成的含有秘密信息的隐写文本的安全性,即隐蔽性和抗隐写分析能力,与隐写文本的质量直接相关。已有生成式自然语言信息隐藏研究通常是通过秘密信息控制下一个生成词的选择,选择不同的生成词则成功编码不同的秘密信息,这意味着生成的隐写文本将随着秘密信息的不同动态改变,从而生成的隐写文本质量存在一定程度的差异。
[0098]
为了提高生成的隐写文本质量,一方面考虑到某些时刻可供选择用于嵌入信息的词概率相差过大,不适合用于嵌入信息,另一方面考虑到词之间的长距离依赖关系不能仅仅依赖当前时刻的预测概率来判断长词序列的质量,本发明提出了基于多候选的动态隐写编码方法(multi
‑
candidates
‑
based dynamic steganographic coding method mcdsc)。该方法包括:1)动点判断:根据预测的概率分布的集中程度,判断候选嵌入位置是否满足隐写的要求,动态选择合适的嵌入位置;2)不动点优化输出:对于不动点,对所有候选嵌入位置的候选词,按照一定的规则进行排序,选择相对合适的多个候选词作为输出;3)动点隐写编码:对于动点,利用具有多个候选词的候选嵌入位置的编码,使多个候选词将编码相同的秘密信息以增加编码冗余,提高生成隐写文本的多样性,尽力避免陷入局部最优。
[0099]
mcdsc包括三个部分操作:1)动点判断、2)不动点优化输出、3)动点隐写编码。下面从这三部分详细介绍mcdsc的原理。
[0100]
1)动点判断
[0101]
在隐写摘要文本生成过程中,mcdsc每个时刻将输出k个序列,作为候选嵌入位置。t=0时刻,不嵌入秘密信息,初始化k个起始序列。对于第i(0<i≤k)个候选嵌入位置,mcdsc根据t
‑
1时刻生成的候选词作为隐写器的输入,利用隐写器预测该候选嵌入位置在t时刻词汇表和源文本中所有词作为生成词的概率分布{p(w),w∈词汇表与源文本所有词的并集},然后选择词概率分布最高的k个作为候选词概率,记为{p'(w),w∈词汇表与源文本所有词的并集}。根据候选词概率分布{p'(w),w∈词汇表与源文本所有词的并集},mcdsc将评估每个候选嵌入位置是否适合嵌入秘密信息。只有所有候选嵌入位置均满足嵌入条件的时刻才允许在文本生成过程中嵌入信息。因此,mcdsc引入动点和不动点的概念。具体定义如下:
[0102]
定义1:动点指满足秘密信息嵌入要求的候选嵌入位置数大于1个的词生成时刻。
[0103]
定义2:不动点指满足秘密信息嵌入要求的候选嵌入位置数小于2个的词生成时刻。
[0104]
根据上述定义可知,动点适合嵌入秘密信息。可用于嵌入信息的候选嵌入位置数越多,则动点嵌入的秘密信息越多,即每一个候选嵌入位置可编码秘密信息的一种取值状态。因此,动点需要至少包括2个可用的候选嵌入位置,即编码1比特信息的两种取值状态“0”和“1”。从而可以根据候选嵌入位置的选择,可嵌入不同的秘密信息值。当可用的候选嵌入位置仅1个时,则为不动点,无法嵌入秘密信息。
[0105]
mcdsc在衡量候选嵌入位置是否满足秘密信息嵌入要求时,不仅考虑了该候选嵌
入位置的各候选词之间的概率差异,还考虑了与前面时刻已生成隐写文本序列的联合概率。假设t
‑
1时刻生成的第i个候选嵌入位置的隐写序列为i表示候选位置的序号,根据训练好的序列到隐写序列模型,预测t时刻的词概率分布,取概率最高的k个词作为候选词。设按降序排列后的候选词分别为:w
i1
,w
i2
,...,w
ik
,记候选词与候选隐写序列组成的联合序列即候选嵌入位置为秘密信息嵌入条件定义如下:
[0106][0107]
其中p(st
ij
)表示词序列st
ij
的概率值,由隐写器根据词序列st
ij
中每个词的生成概率值计算得出;α、β为阈值。如果满足上述条件的候选嵌入位置st
i
的数量至少有2个,则当前t时刻为动点,将用来嵌入信息;否则为不动点,不能用来嵌入信息。根据嵌入条件mcdsc将对每个生成时刻进行动点与不动点的判定,从而在文本生成过程中动态地选择时刻嵌入秘密信息。如图2所示,t=1时刻有k个候选嵌入位置对于每一个候选嵌入位置需要根据训练好的序列到隐写序列模型,预测t=1时刻的词概率分布,取概率最高的k个词作为候选词w
i1
,w
i2
,...,w
ik
来判断该嵌入位置是否满足条件(10)。当k个候选嵌入位置st1,...,st1,
…
,st
k
中最多只有一个满足条件(10),则t=1时刻为不动点,当k个候选嵌入位置st1,...,st1,
…
,st
k
中至少有两个满足条件(10),则t=1时刻为动点。
[0108]
2)不动点优化输出
[0109]
对于不动点时刻t,设t时刻k个候选嵌入位置为st1,...,st
i
,...st
k
,其中mcdsc将按照序列概率值p(st
ij
)对k
×
k个联合序列st
ij
降序排序,st'
11
,...,st'
1k
,...,st'
k1
,...,st'
kk
,最后选择概率值最高的k个序列st'
11
,...,st'
1k
作为当前时刻的输出,即其中如图5所示的t=1不动点时刻。
[0110]
3)动点隐写编码
[0111]
对于动点时刻t,设t
‑
1时刻生成的候选隐写序列为候选隐写序列的概率值为t时刻的k个候选嵌入位置为st1,...,st
i
,...st
k
,其中计算每个满足嵌入条件的候选嵌入位置st
i
中所有候选项的平均概率值根据候选嵌入位置的平均概率值,选择最高的两个候选嵌入位置st
a
和st
b
来编码秘密信息。其中
[0112][0113]
a表示平均概率值最大的候选嵌入位置,b表示平均概率值次大的候选嵌入位置。
[0114]
两个候选嵌入位置st
a
和st
b
分别编码为0和1,具体编码规则如下:
[0115]
其中c(
·
)表示编码值。
[0116]
嵌入时:
[0117]
(1)根据动点判断中的定义1与定义2,确定当前t时刻是动点还是不动点。
[0118]
(2)如果当前时刻是动点,则进行秘密信息嵌入。当待嵌入的秘密信息比特为m=0时,mcdsc选择st
a
中的k个候选序列作为t时刻的输出,即中的k个候选序列作为t时刻的输出,即当待嵌入的秘密信息比特为m=1时,mcdsc选择st
b
中的k个候选序列作为t时刻的输出,即中的k个候选序列作为t时刻的输出,即
[0119]
(3)如果当前时刻是不动点,在当前时间步长t,隐写器会对全部的候选嵌入位置st={st1,...,st1,
…
,st
k
}中的全部k
×
k个候选隐写序列进行排序,选择排序后前k个概率值最高的候选序列记为作为t时刻的输出,具体细节如图2中不动点模块所示。
[0120]
(4)重复进行步骤(1)到步骤(3)的操作,直到将秘密信息全部嵌入完毕,进入步骤(5)。
[0121]
(5)在遇到结束符或达到最大长度之前,将之后的所有时刻视为不动点来进行信息嵌入,最终得到k个候选隐写摘要文本,选择概率值最高的候选隐写摘要文本作为最终隐写摘要文本y。
[0122]
提取时:
[0123]
接收方在接收到发送方通过公开渠道所发送的源文本(原始长文本)和含有秘密信息的隐写摘要文本后,再根据发送方秘密提供的秘密信息长度、起始标志符等参数信息以及训练好的序列到隐写序列模型提取隐写摘要文本中秘密信息,具体的提取步骤如下:
[0124]
(1)把源文本输入到训练好的语言编码器中,得到t时刻上下文向量和注意力分布a
t
,并输入隐写器,结合t时刻之前生成的候选摘要序列,预测得到词汇表和源文本中所有词作为t时刻生成词的概率分布。
[0125]
(2)隐写器使用mcdsc方法进行动点判断:
[0126]
如果当前t时刻是动点,则隐写器根据动点隐写编码对两个候选嵌入位置st
a
和st
b
进行编码,然后进行信息提取。设隐写摘要文本中当前t时刻的单词为w
t
',则遍历st
a
和st
b
中t时刻预测生成的候选词w
a1
,w
a2
,...,w
ak
和w
b1
,w
b2
,...,w
bk
。如果w
t
'=w
aj
,j∈[1,k],则当前t时刻提取的秘密信息比特值m=c(st
a
)=0,并输出st
a
中的k个候选序列作为下一时刻隐写器的输入;如果w
t
'=w
bj
,j∈[1,k],则当前t时刻提取的秘密信息比特值m=c(st
b
)=1,并输出st
b
中的k个候选序列作为下一时刻隐写器的输入。
[0127]
(3)重复步骤(1)和(2),直到秘密信息提取完毕。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1