一种使用SIMD指令提高缓存利用率的方法与流程
本发明涉及数据存储,特别涉及一种使用simd指令提高缓存利用率的方法。
背景技术:
1、在现有技术中,在向量计算过程中,常常要求取平方根倒数,例如将向量归一化。c数学函数库中的平方根倒数方法具有高精度,但是在追求计算速度的情况下可能无法满足快速计算的要求。平方根倒数速算法(fast inverse square root)是用于快速计算平方根倒数的一种算法,(输入的待计算数据需符合ieee 754标准格式的32位单精度浮点数),该算法在保证足够的精度的同时,提高了运算速度。此算法最早被认为是由约翰·卡马克所发明,但后来的调查显示,该算法在这之前就于计算机图形学的硬件与软件领域有所应用,此算法不仅原作者不明,而且至今为止仍未能确切知晓算法中所使用的特殊常数的起源,该特殊常数被称为“魔术数字”。
2、此外,目前平方根倒数速算法普遍使用c语言实现,即首先接收一个符合ieee 754标准格式的32位单精度浮点数,然后将其作为一个32位整数看待,再将其向右进行一次逻辑移位取半,并用十六进制“魔术数字”0x5f3759df减去取半的结果,得到输入浮点数的平方根倒数的首次近似值;而后重新将其作为浮点数,以牛顿迭代法反复迭代,以求出更精确的近似值,直至求出匹配精确度要求的近似值。在计算浮点数的平方根倒数的同一精度的近似值时,此算法比直接使用浮点数除法要快四倍。
3、但是,在处理数据的过程中,经常采用的c语言编程,其中平方根倒数速算方法一次只能处理一个数据,造成缓存浪费,数据交互时间长从而造成运算速度慢,在一些硬件资源有限的平台或芯片上无法运行,特别是针对很多芯片厂商而言,针对不同需求使用不同的芯片,例如北京君正集成电路股份有限公司(简称:北京君正)的芯片上,采用c语言会大大限制芯片的速度,造成缓存浪费。
4、现有技术中的常用术语如下:
5、1.simd全称single instruction multiple data,单指令多数据流,能够一次处理多个操作数,并把它们打包在大型寄存器的一组指令集。
6、2.牛顿迭代法又称为牛顿-拉夫逊(拉弗森)方法,它是牛顿在17世纪提出的一种在实数域和复数域上近似求解方程的方法。
7、设r是f(x)=0的根,选取x0作为r的初始近似值,过点(x0,f(x0))做曲线y=f(x)的切线l,l:y=f(x0)+f’(x0)(x-x0),则l与x轴交点的横坐标x1=x0-f(x0)/f’(x0),称x1为r的一次近似值。过点(x1,f(x1))做曲线y=f(x)的切线,并求该切线与x轴交点的横坐标x2=x1-f(x1)/f’(x1),称x2为r的二次近似值。重复以上过程,得r的近似值序列,其中,x(n+1)=xn-f(xn)/f’(xn),称为r的n+1次近似值,上式称为牛顿迭代公式。
技术实现思路
1、为了解决上述问题,本方法的目的在于:使用simd指令实现快速求解平方根倒数,可以提高缓存利用率,一次性加载多个数据,减少硬盘与内存数据的交互时间,从而大大提高了运算速度,占用少量资源,在硬件资源有限的情况下也能高效运行。
2、具体地,本发明提供一种使用simd指令提高缓存利用率的方法,所述方法使用simd指令实现快速求解平方根倒数的方法以提高缓存利用率,其中使用的simd指令集能够一次加载512的整数倍的bit数据,使用至少一个寄存器完成加载,在计算时一次对512bit数据进行相同操作;并用十六进制魔术数字0x5f3759df减去对寄存器中的数据进行直接逻辑右移1位操作后的结果,得到输入浮点数的平方根倒数的首次近似值;而后重新将其作为浮点数,以牛顿迭代法反复迭代,直至求出匹配精确度要求的近似值并存储到寄存器中,最后将寄存器中的数据存储到内存中。
3、所述完成加载的寄存器一共有32个,能够重复使用。
4、所述simd指令集包括加、减、乘、取绝对值、最大值、最小值的算术运算,包括与、或、非、异或、移位的逻辑运算,包括小于、等于、小于等于的比较运算,对于复杂运算需求通过多个指令结合实现。
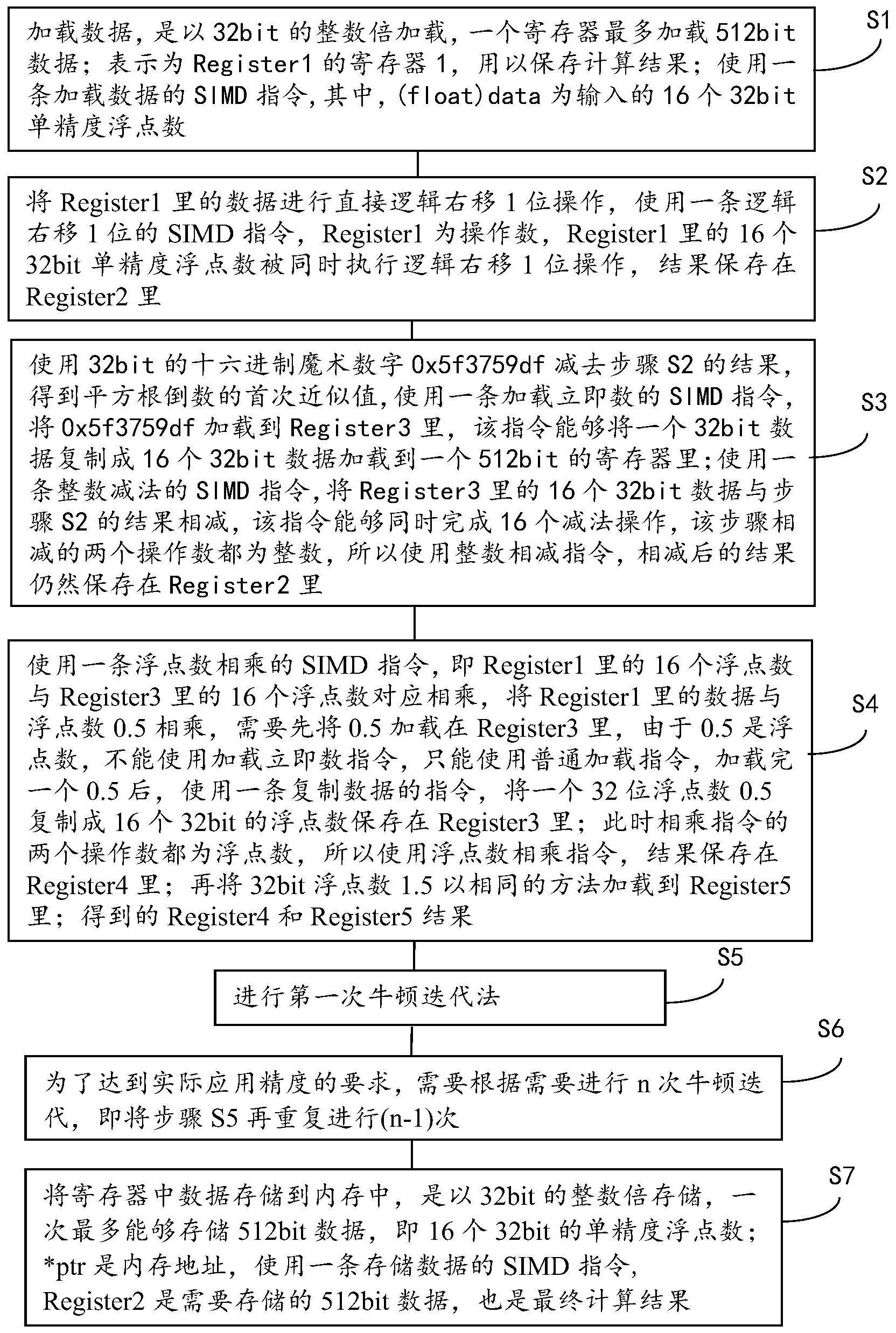
5、所述方法包括以下步骤:
6、s1.加载数据,是以32bit的整数倍加载,一个寄存器最多加载512bit数据;
7、表示为register1的寄存器1,用以保存计算结果;
8、使用一条加载数据的simd指令,表示为:
9、register1=ingenic_simd512_load((float)data),
10、其中,(float)data为输入的16个32bit单精度浮点数;
11、s2.将register1里的数据进行直接逻辑右移1位操作,
12、使用一条逻辑右移1位的simd指令,表示为:
13、register2=ingenic_simd512_logical_shift_right_1_bit(register1)register1为操作数,register1里的16个32bit单精度浮点数被同时执行逻辑右移1位操作,结果保存在表示为register2的寄存器2里;
14、s3.使用32bit的十六进制魔术数字0x5f3759df减去步骤s2的结果,得到平方根倒数的首次近似值,
15、使用一条加载立即数的simd指令,表示为:
16、register3=ingenic_simd512_load_immediate(0x5f3759df),
17、将0x5f3759df加载到register3里,该指令能够将一个32bit数据复制成16个32bit数据加载到一个512bit的寄存器里;
18、使用一条整数减法的simd指令,表示为:
19、register2=ingenic_simd512_int_sub(register3,register2),
20、将register3里的16个32bit数据与步骤s2的结果相减,该指令能够同时完成16个减法操作,该步骤相减的两个操作数都为整数,所以使用整数相减指令,相减后的结果仍然保存在register2里;
21、s4.使用一条浮点数相乘的simd指令,即register1里的16个浮点数与register3里的16个浮点数对应相乘,表示为:
22、register4=ingenic_simd512_float_mul(register1,register3),
23、将register1里的数据与浮点数0.5相乘,需要先将0.5加载在register3里,由于0.5是浮点数,不能使用加载立即数指令,只能使用普通加载指令,表示为:
24、register3=ingenic_simd512_load(0.5),
25、加载完一个0.5后,使用一条复制数据的repeat指令,表示为:register3=ingenic_simd512_repeat(register3),
26、将一个32位浮点数0.5复制成16个32bit的浮点数保存在register3里;
27、此时相乘指令的两个操作数都为浮点数,所以使用浮点数相乘指令,结果保存在register4里;
28、再将32bit浮点数1.5以相同的方法加载到register5里,表示为:
29、register5=ingenic_simd512_load(1.5),
30、register5=ingenic_simd512_repeat(register5);
31、该步骤得到的register4和register5结果为下面进行牛顿迭代法做准备;
32、s5.进行第一次牛顿迭代法:
33、使用浮点数相乘的simd指令:ingenic_simd512_float_mul指令将步骤s3的register2里的数据与register2里的数据相乘得到平方的结果,这一步是将register2里的16个32bit数据进行平方操作,将结果保存在register6里,再与register4里的数据相乘,结果仍然保存在register6里,再使用浮点数相减指令,即register5里的16个浮点数减去register6里对应的16个浮点数,表示为:ingenic_simd512_float_sub指令,将register5数据减去register6数据,该指令两个操作数都是浮点数,所以使用浮点相减指令,结果保存在register6里,再将register6数据与register2数据相乘,结果保存在register2里;
34、这里的寄存器存储的都是16个32bit的单精度浮点数,每条指令都是同时操作16个浮点数;表示为:
35、register6=ingenic_simd512_float_mul(register2,register2);
36、register6=ingenic_simd512_float_mul(register4,register6);
37、register6=ingenic_simd512_float_sub(register5,register6);
38、register2=ingenic_simd512_float_mul(register2,register6);
39、s6.为了达到实际应用精度的要求,需要根据需要进行n次牛顿迭代,即将步骤s5再重复进行(n-1)次;
40、s7.将寄存器中数据存储到内存中,是以32bit的整数倍存储,一次最多能够存储512bit数据,即16个32bit的单精度浮点数;*ptr是内存地址,使用一条存储数据的simd指令,表示为:
41、*ptr=ingenic_simd512_store(register2),
42、register2是需要存储的512bit数据,也是最终计算结果。
43、所述步骤s6,进一步包括:能够进行三次牛顿迭代,将步骤s5再重复进行两次,表示为:
44、第二次牛顿迭代:
45、register6=ingenic_simd512_float_mul(register2,register2);
46、register6=ingenic_simd512_float_mul(register4,register6);
47、register6=ingenic_simd512_float_sub(register5,register6);
48、register2=ingenic_simd512_float_mul(register2,register6);
49、第三次牛顿迭代:
50、register6=ingenic_simd512_float_mul(register2,register2);
51、register6=ingenic_simd512_float_mul(register4,register6);
52、register6=ingenic_simd512_float_sub(register5,register6);
53、register2=ingenic_simd512_float_mul(register2,register6)。
54、由此,本技术的优势在于:使用simd指令集,特别是采用北京君正研发的芯片中的ingenic_simd512指令集,对平方根倒数速算法进行优化和改进,提高缓存利用率,资源消耗少,计算速度是c语言平方根倒数速算法的50倍,可以在硬件资源有限的平台上高效运行。
- 还没有人留言评论。精彩留言会获得点赞!