一种基于分布式存储的数据复制卸载方法及终端设备与流程
1.本发明涉及分布式存储领域,特别是涉及一种基于分布式存储的数据复制卸载方法、终端设备及计算机可读存储介质。
背景技术:
2.分布式存储系统(ceph)将上层业务数据切割成一个个独立的对象,保存在一个由若干服务器组成的集群中;分布式存储系统同时支持对象存储、块存储和文件系统。其中主要组件有:(1)rbd:rados block device,对外提供的块设备服务(类似于提供一块硬盘,即卷);rbd会按固定大小(默认4mb)将卷进行切块,并根据块偏移、卷名等元数据对块进行命名,即对象(每一小块就是一个对象),存储到分布式集群中,实现从卷操作到对象操作的转换。(2)rados:reliable autonomic distributed object store,可靠自主的分布式对象存储,是集群的统一抽象层,所有接口的数据经过这层处理后就以对象的形式存储在集群中。(3)osd:object storage device,对象存储设备,负责处理客户端读写请求的守护进程/程序,一个osd进程通常管理一块磁盘。(4)librados:提供上层访问可靠自主的分布式对象存储集群的各种库函数接口,封装了与可靠自主的分布式对象存储层交互的接口。
3.分布式存储系统的读写流程概述如下,以写流程为例,假设为保证数据安全和一致性,采用传统的三副本策略对数据进行保护:参考图1。(1)用户直接读写存储网关映射出来的卷,读写请求中包含操作的偏移和长度;(2)存储网关rbd层根据rbd元数据,结合对卷写请求的偏移和长度,解析出相应对象信息;(3)librados将相应对象操作封装为rados的对象操作请求;(4)根据对象名称和rados寻址算法找得到保存对象数据的三个osd;(5)将对象的写请求发送给主osd进行处理,主osd进行数据封装后再发送给从osd;(6)主osd根据对象名称和osd元数据找到对象在硬盘上的位置,并将对象数据写入硬盘;(7)根据rados的副本策略和rados的寻址算法,主osd2将副本分别发送给从osd1和osd3;(8)从osd将数据写入本地磁盘后,给主osd回复响应;(9)当所有osd写处理完成时,依次逆序回复完成确认消息给上级。
4.主要根据功能,将ceph rbd分层架构(layering)划分为librbd(ceph块设备接口库)、cache(缓存层)、objecter(对象接口层)和librados(rados接口库)四个层次。参考图2,librbd对上层用户封装符合linux块设备标准的卷接口,供用户操作,快照和克隆卷也是在librbd抽象的;cache层主要是为了提高读写性能,负责数据缓存;objecter负责将数据操作封装成符合分布式存储ceph集群的对象操作;librados负责真正与分布式存储集群进行业务交互。基于rbd的分层架构,rbd创建克隆卷时,采用写时复制机制(cow,copy on write);以实现快速创建卷。限制条件是只能基于快照创建克隆卷,形成快照和克隆卷的父子关系,共享相同的对象数据。
5.指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的镜像,只能读取。参考图3,快照(snapshot)可以是其所表示的数据的一个副本,也可以是数据的一个复制品。
6.在rbd层基于快照和写时复制技术克隆出一个可读写的卷,称为克隆卷。参考图4,此时克隆卷与父快照只是增加了映射关系的元数据(共用数据)。(一)flatten操作(拍扁操作),基于快照的克隆卷保留着对父快照的映射关系。当需要解除这种父快照与子克隆卷的映射关系,及将克隆卷修改成非克隆卷,就需要使用flatten操作;flatten操作是将父快照的信息拷贝一份保存到克隆卷,所以flatten操作会增加与父快照相同的空间使用量;当要删除的快照有克隆卷时,必须先进行flatten操作来解除克隆卷和父快照之间的映射关系。(二)克隆卷初次写,基于rbd的layering机制,由于快照是只读的,客户端要修改快照时,必须基于快照复制出克隆卷,对克隆卷进行写操作;克隆卷第一次写时,根据cow原理,需要先从快照parent中读出操作区域的原始数据,与客户端修改的数据进行合并,最终将合并数据写入克隆卷,如下图5所示;(1)客户端第一次写克隆卷,将要修改的数据的偏移及长度发送给存储网关;(2)存储网关rbd检测克隆卷对应区域的对象是否存在的;(3)分布式存储集群返回对象不存在的错误码给rbd;(4)rbd根据克隆关系中找到父快照;(5)rbd向父快照发起对目标域对象读请求;(6)分布式存储集群返回父快照对应区域的数据给rbd;(7)rbd将父快照数据与用户数据合并;(8)rbd将合并后的数据向分布式存储集群写入数据;(9)分布式存储集群返回写完成确认;(10)rbd向客户端返回写完成确认。(三)未flatten克隆卷读(克隆卷本身无相应数据),(1)客户端将要读取的数据的偏移及长度发送给存储网关;(2)存储网关rbd检测克隆卷对应区域的对象是否存在的;(3)分布式存储集群返回对象不存在的错误码给rbd;(4)rbd根据克隆关系中找到父快照;(5)rbd向父快照发起对目标域对象读请求;(6)分布式存储集群返回父快照对应区域的数据给rbd;(7)存储网关rbd将父快照数据返回给客户端。
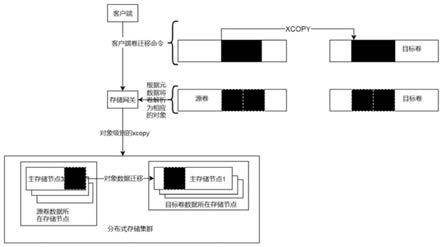
7.vmware xcopy原理(虚拟化软件vmware的数据复制(xcopy)原理),传统存储的数据复制(复制)是客户资源管理器将数据从源卷中读取出来,再写如到目标卷中,即首先通过源服务器从存储读取,然后跨网络传输到目标服务器,最后通过目标服务器写回存储。由于受制于这样的数据操作机制,当超过一定数量的虚拟机同时进行诸如迁移、克隆、备份、zeroing等操作的时候,往往会导致出现网络带宽资源消耗严重、cpu和内存资源被大量占用的问题。针对上述虚拟机迁移及克隆问题,vmware推出了vaai(vstorage apis for array integration也被称为硬件加速或硬件减负api),vaai的目的是将传统虚拟机文件搬移过程(从主机侧)卸载到共享存储阵列(通过减少冗余的io路径,使得据移动将消耗更少的cpu资源,更少的storage fabric带宽),这样不仅可以大大减轻主机侧cpu和内存的压力,同时还极大的降低了对网络资源的要求。数据复制是vaai基本类型之一,用于将复制任务卸载到存储。例如,可以使用数据复制将诸如虚拟机迁移、克隆等操作卸载到存储阵列或分布式存储集群,从而减少使用vsphere管理客户端资源来执行这些任务。参考图6(1)客户端给存储网关下发数据复制数据复制命令,包含了待迁移数据(源卷数据的偏移和长度)和数据迁入区域(目标卷的偏移,长度是源卷读取的长度);(2)存储网关从源卷中读取数据复制命令指定数据;(3)存储集群返回指定区域数据给存储网关;(4)存储网关将待迁移数据写入存储集群数据复制指定区域;(5)存储集群写入完成后给存储网关返回确认信息;(6)存储网关收到所有数据都完成的确认信息后给客户端回复响应。
8.scsi target框架(tgt,存储网关),参考图7,tgt是一个scsi网关,主要是解析对块设备操作的scsi命令,如将对卷指定区域读写的scsi命令解析为对对外提供的块设备服
务的卷的读写命令。
9.ceph现有基于对象的数据复制技术。分布式存储系统支持基于对象级别的复制卸载操作;用户需要将源对象和目标对象的信息封装成可靠自主的分布式对象存储的请求,发送给源对象所在主对象存储设备进行数据复制的操作。参考图8,源对象所在主对象存储设备接收到对象数据复制指令后,将源对象从存储介质中读取出来后,封装成对象存储设备间的写请求,发送给目标对象所在主对象存储设备;目标对象所在主对象存储设备将对象数据写入存储介质并保证事务性后,给源对象所在主对象存储设备回复完成确认;源对象所在主对象存储设备收到完成确认后给接口库客户端回复完成确认;结束基于对象的数据复制操作。现有技术的缺点在于,分布式存储系统基于对象的数据复制是在可靠自主的分布式对象存储层的接口,接口库只支持整个对象的数据复制,不支持卷级别的数据复制,数据复制的并发度和性能差。
技术实现要素:
10.为了弥补上述现有技术的数据复制并发度和性能的不足,本发明提出一种基于分布式存储的数据复制卸载方法、终端设备及计算机可读存储介质。
11.本发明的技术问题通过以下的技术方案予以解决:
12.本发明提出一种基于分布式存储的数据复制卸载方法,包括如下步骤:s1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;s2:根据对象信息解析出源对象主存储节点信息,存储网关把需要复制的数据位置、长度信息、目的对象的拷贝位置信息发送给源对象主存储节点;s3:根据源对象主存储节点收到的信息,获取目的对象对应的主存储节点信息,并从源对象主存储节点本地对应的存储介质读取数据,封装成写请求发送给目的对象主存储节点;s4:指使目的对象主存储节点根据收到所述写请求,完成相应对象写入操作后,给源对象主存储节点回复写入成功的响应;s5:指使源对象主存储节点收到所述目的对象主存储节点回复的响应,给网关节点回复数据复制处理成功的响应;s6:指使网关节点收到所有上述源对象主存储节点所回复的响应后,给客户端回复数据复制请求完成的响应。
13.在一些实施例,根据源卷、目的卷在网关侧是否有数据缓存、是否为克隆卷,存在四种场景,按照场景1
‑
4优先级进行匹配处理:场景1:源卷数据复制请求区域命中缓存数据;场景2:源卷为克隆卷;场景3:目的卷为克隆卷;场景4:源卷、目的卷都为非克隆卷。
14.在一些实施例,所述场景1中,其处理流程包括:a1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;a2:所述数据复制请求指令的数据命中网关缓存数据,从网关缓存层中读取数据,,封装成写请求发送给目的对象主存储节点;a3:指使目的对象主存储节点接收写请求,把数据持久化到磁盘并回复响应。
15.在一些实施例,所述场景2中,其处理流程包括:b1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;b2:指示网关结合数据迁移请求中的源克隆卷对象名,探测源克隆卷对象;b3:如源克隆卷对象不存在,则根据该卷元
数据信息,从克隆卷对应的父卷中找到相应对象,给父卷对象主存储节点发送数据读请求;如源克隆卷对象存在,对源克隆卷对象主存储节点发送读请求;b4:所述对象主存储节点接收到读请求,读取对象数据后给网关返回响应;b5:所述网关接收到读响应后构造写请求,发送给目的对象主存储节点;b6:指使目的对象主存储节点接收写请求,把数据持久化到磁盘后给网关回复响应。
16.在一些实施例,所述场景3中,其处理流程包括:c1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;c2:所述网关结合数据复制请求中的源卷对象信息,向源卷对象主存储节点发送读请求;c3:指示源卷对象主存储节点读取源卷对象数据后,给网关回复响应信息;c4:所述网关结合数据迁移请求中的目的克隆卷对象名,探测目的克隆卷对象;如目的克隆卷对象存在,则将源卷对象数据封装成写请求发送给目的克隆卷对象主存储节点;c5:如目的克隆卷对象不存在,则根据该卷元数据信息,解析出克隆卷对应的父卷对应对象,给父卷对象主存储节点发送读取对象数据请求;c6:所述网关将源卷对象数据和目的克隆卷父卷对象数据合并封装成写请求发送给目的克隆卷对象主存储节点;c7:目的克隆卷对象主存储节点接收写请求,把数据持久化到磁盘后给网关回复响应。
17.在一些实施例,所述场景4中,其处理流程包括:
18.d1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;
19.d2:根据对象信息解析出源对象主存储节点信息,存储网关把需要复制的数据位置、长度信息、目的对象的拷贝位置信息发送给源对象主存储节点;
20.d3:根据源对象主存储节点收到的信息,获取目的对象对应的主存储节点信息,并从源对象主存储节点本地对应的存储介质读取数据,封装成写请求发送给目的对象主存储节点;
21.d4:指使目的对象主存储节点根据收到所述写请求,完成相应对象写入操作后,给源对象主存储节点回复写入成功的响应;
22.d5:指使源对象主存储节点收到所述目的对象主存储节点回复的响应,给网关节点回复数据复制处理成功的响应;
23.d6:指使网关节点收到所有上述源对象主存储节点所回复的响应后,给客户端回复数据复制请求完成的响应。
24.本发明还提出一种基于分布式存储的数据复制卸载的终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现以上任一所述方法的步骤。
25.本发明还提出一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现以上任一所述方法的步骤。
26.本发明与现有技术对比的有益效果包括:现有的分布式存储通常是在客户端或网关侧进行数据读写来实现数据复制指令,不能充分发挥分布式存储的优势,本发明通过把数据复制相关的操作卸载到各分布式存储节点进行,基于卷迁移请求中的数据拷贝偏移和
长度,计算源卷、目的卷数据信息所归属的对象信息,把需要复制的拷贝位置信息发送给源对象主存储节点,再给目的对象主存储节点发送写请求,目的对象主存储节点回复写入成功响应;能够减少客户端或网关侧的带宽压力,提高数据复制的并发度和性能;
27.在一些实施例,本发明与现有技术对比的有益效果包括:本发明将数据复制指令下沉到网关侧或存储集群;如缺少数据复制卸载的支持,虚拟化软件就需要自行将迁移数据读取出来,再写回存储;本发明的分布式存储系统支持虚拟化软件的数据复制指令,减少虚拟化软件管理程序的资源消耗,减少网络资源消耗和复制时延。
附图说明
28.图1是现有技术中的分布式存储系统的读写流程图;
29.图2是现有技术中的分布式存储系统的块设备服务分层架构图;
30.图3是现有技术中的快照示意图;
31.图4是现有技术中的克隆卷示意图;
32.图5是现有技术中的克隆卷初次写流程图;
33.图6是现有技术中的传统存储的数据复制示意图;
34.图7是现有技术中的分布式存储框架示意图;
35.图8是现有技术中的支持基于对象级别的复制卸载操作示意图;
36.图9是本发明实施例的对象状态解析示意图;
37.图10是本发明实施例的数据复制命中缓存场景数据复制处理流程示意图;
38.图11是本发明实施例的目的卷为克隆卷场景的数据复制处理流程示意图;
39.图12是本发明实施例的源卷为克隆卷且源对象不存在场景的数据复制处理流程示意图;
40.图13是本发明实施例的数据复制卸载到分布式存储存储处理流程示意图。
具体实施方式
41.下面对照附图并结合优选的实施方式对本发明作进一步说明。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
42.需要说明的是,本实施例中的左、右、上、下、顶、底等方位用语,仅是互为相对概念,或是以产品的正常使用状态为参考的,而不应该认为是具有限制性的。
43.现有的分布式存储通常在网关测的数据读写来实现数据复制指令,不能充分发挥分布式存储的优势,本发明通过把数据复制相关的操作从网关侧下移到各分布式存储节点进行,能够减少网关测的带宽压力,提高数据复制的并发度和性能。
44.本发明实施例的一种基于分布式存储的数据复制卸载方法,包括如下步骤:s1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;s2:根据对象信息解析出源对象主存储节点信息,存储网关把需要复制的数据位置、长度信息、目的对象的拷贝位置信息发送给源对象主存储节点;s3:根据源对象主存储节点收到的信息,获取目的对象对应的主存储节点信息,并从源对象主存储节点本地对应的存储介质读取数据,封装成写请求发送给目的对象主存储节点;s4:指使目的对象主存储节点根
据收到所述写请求,完成相应对象写入操作后,给源对象主存储节点回复写入成功的响应;s5:指使源对象主存储节点收到所述目的对象主存储节点回复的响应,给网关节点回复数据复制处理成功的响应;s6:指使网关节点收到所有上述源对象主存储节点所回复的响应后,给客户端回复数据复制请求完成的响应。
45.分布式存储系统的卷image由对外提供的块设备服务rbd实现的,相应卷image的元数据也是由对外提供的块设备服务rbd进行管理;在对外提供的块设备服务rbd的对象接口层objecter增加对卷级数据复制指令的支持。在对外提供的块设备服务rbd对象接口层objecter处增加一个状态机,根据源卷和目标卷状态,解析出源卷对应对象和目标卷对应对象的状态,再根据对象状态进入相应状态机的处理流程,如下图9所示。
46.根据源卷、目的卷在网关侧是否有缓存层、是否为克隆卷、克隆卷是否拍扁操作,存在四种场景,按照场景1
‑
4优先级进行匹配处理:场景1:源卷数据复制请求区域命中缓存数据;场景2:源卷为克隆卷;场景3:目的卷为克隆卷;场景4:源卷、目的卷都为非克隆卷。
47.对于场景1,其io处理流程如下图10所示,其处理流程包括:a1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;a2:所述数据复制请求指令的数据命中网关缓存数据,从网关缓存层中读取数据,封装成写请求发送给目的对象主存储节点;a3:指使目的对象主存储节点接收写请求,把数据持久化到磁盘并回复响应。
48.对于场景2,由于源卷为克隆卷,对于源对象不存在的情况,其主要处理流程如下图12所示,其处理流程包括:b1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;b2:指示网关结合数据迁移请求中的源克隆卷对象名,探测源克隆卷对象;b3:如源克隆卷对象不存在,则根据该卷元数据信息,从克隆卷对应的父卷中找到相应对象,给父卷对象主存储节点发送数据读请求;如源克隆卷对象存在,对源克隆卷对象主存储节点发送读请求;b4:所述对象主存储节点接收到读请求,读取对象数据后给网关返回响应;b5:所述网关接收到读响应后构造写请求,发送给目的对象主存储节点;b6:指使目的对象主存储节点接收写请求,把数据持久化到磁盘后给网关回复响应。
49.对于场景3,由于目的卷为克隆卷,有可能对应目的对象不存在,需要做拷贝处理,因此需要把数据复制请求转成正常的读写请求(写请求包含了对拷贝的处理流程),其处理流程如下图11所示,其处理流程包括:c1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;c2:所述网关结合数据复制请求中的源卷对象信息,向源卷对象主存储节点发送读请求;c3:指示源卷对象主存储节点读取源卷对象数据后,给网关回复响应信息;c4:所述网关结合数据迁移请求中的目的克隆卷对象名,探测目的克隆卷对象;如目的克隆卷对象存在,则将源卷对象数据封装成写请求发送给目的克隆卷对象主存储节点;c5:如目的克隆卷对象不存在,则根据该卷元数据信息,解析出克隆卷对应的父卷对应对象,给父卷对象主存储节点发送读取对象数据请求;c6:所述网关将源卷对象数据和目的克隆卷父卷对象数据合并封装成写请求发送给目的克隆卷对象主存储节点;c7:目的克隆卷对象主存储节点接收写请求,把数据持久化到磁盘后给网关回复响应。
50.对于场景4,如果源对象存在(源卷进行过flatten操作或覆盖写过),其处理流程和场景3是一致的,把数据复制请求(包含相关快照信息)卸载给源对象所在主对象存储设备来处理,流程如下图13所示。场景4中,源对象和目标对象都存在。场景4中,其处理流程包括:d1:客户端向存储网关发送的数据复制请求指令,指示存储网关根据对应源卷、目的卷元数据信息;及数据复制请求中的数据拷贝偏移和长度,解析出所述源卷、目的卷所映射的对象信息;d2:根据对象信息解析出源对象主存储节点信息,存储网关把需要复制的数据位置、长度信息、目的对象的拷贝位置信息发送给源对象主存储节点;d3:根据源对象主存储节点收到的信息,获取目的对象对应的主存储节点信息,并从源对象主存储节点本地对应的存储介质读取数据,封装成写请求发送给目的对象主存储节点;d4:指使目的对象主存储节点根据收到所述写请求,完成相应对象写入操作后,给源对象主存储节点回复写入成功的响应;d5:指使源对象主存储节点收到所述目的对象主存储节点回复的响应,给网关节点回复数据复制处理成功的响应;d6:指使网关节点收到所有上述源对象主存储节点所回复的响应后,给客户端回复数据复制请求完成的响应。
51.本发明实施例的分布式存储系统支持虚拟化软件vmware数据复制指令,减少虚拟化软件vmware管理程序的资源消耗,减少网络资源消耗和复制时延。
52.本发明实施例的一种基于分布式存储的数据复制卸载的终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现以上任一所述方法的步骤。
53.本发明实施例的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现以上任一所述方法的步骤。
54.以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1