一种基于数据迁移的风力发电功率预测方法及装置与流程
1.本发明属于新能源风力发电领域,特别是涉及到一种基于数据迁移的风力发电功率预测方法及装置。
背景技术:
2.有关风力发电的功率预测目前大多采用传统的机器学习算法如线性模型(lasso)、树模型(gbm)等和前沿的深度学习如cnn、 lstm等。虽然算法的表达能力和泛化能力都在逐步变强,但这些算法有一个大的假设前提即训练集和测试集满足独立同分布,而实际这个假设是不可能满足的,因此会影响风电功率预测的准确性。
3.为了解决训练集和测试集分布不同的问题,还采用了其他类型的算法如tca、jda和基于深度学习相关的迁移算法。但是这些算法也各有优缺点,tca和jda适合数据量不大的情景如几百到上千的数据,因为其需要很大的计算资源;而深度学习一般需要大量的数据才能使模型有较强的泛化性。
技术实现要素:
4.本发明提出一种基于数据迁移的功率预测方法及装置,通过树模型的方法来改善训练集、测试集分布不一致的问题,从而使风电功率预测的准确率有了较大提高。
5.为达到上述目的,本发明的技术方案是这样实现的:一种基于数据迁移的风力发电功率预测方法,使用数据集构建功率预测模型,在功率预测模型建模前,使用树模型进行数据集的预处理,所述预处理过程具体包括:s1、数据集根据时间戳划分训练集、验证集和测试集;进行数据清洗;s2、使用树模型对训练集建模;s3、用该模型对测试集样本进行预测,统计每个样本的路径长度,然后对路径长度进行排序;s4、针对s3的排序结果,选取下p分位数的样本,采用最近邻方法寻找训练集中数据,生成新样本加入到训练集中。
6.进一步的,还包括:s5、将训练集数据进行特征工程处理。
7.进一步的,构建功率预测模型后,根据风机本身功率曲线参数,对预测数据进行后处理。
8.更进一步的,所述后处理包括:根据风机本身功率曲线的拐点把曲线分为若干段,每段根据损失函数进行优化。
9.进一步的,步骤s4中所述新样本的生成方法包括:对训练集用最近邻算法建模,对于满足下p分位数的数据用建好的模型遴选数据,作为新样本加入到训练集中。
10.本发明另一方面还提出一种基于数据迁移的风力发电功率预测装置,包括功率预测模型构建模块和数据预处理模块;
功率预测模型构建模块,用于使用数据集构建功率预测模型;数据预处理模块,用于使用树模型进行数据集的预处理,其包括:数据划分单元,用于将数据集根据时间戳划分训练集、验证集和测试集;进行数据清洗;树模型建模单元,用于使用树模型对训练集建模;测试集排序单元,用于用树模型建模单元构建的模型对测试集样本进行预测,统计每个样本的路径长度,然后对路径长度进行排序;新样本生成单元,用于针对测试集排序单元的排序结果,选取下p分位数的样本,采用最近邻方法寻找训练集中数据,生成新样本加入到训练集中。
11.进一步的,所述数据预处理模块还包括:特征工程单元,用于将训练集数据进行特征工程处理。
12.进一步的,本装置还包括后处理模块,用于构建功率预测模型后,根据风机本身功率曲线参数,对预测数据进行后处理。
13.更进一步的,所述后处理模块根据风机本身功率曲线的拐点把曲线分为若干段,每段根据损失函数进行优化。
14.进一步的,所述新样本单元对训练集用最近邻算法建模,对于满足下p分位数的数据用建好的模型遴选数据,作为新样本加入到训练集中。
15.与现有技术相比,本发明具有如下的有益效果:1.本发明创新性的用树模型解决训练集和测试集分布不一致的状况,比现有的方法更快且数据规模要求低;2.本发明提出了后处理模块,该模块弥补了模型和算法的表达能力,使预测精度更高,准确率有了较大提高。
附图说明
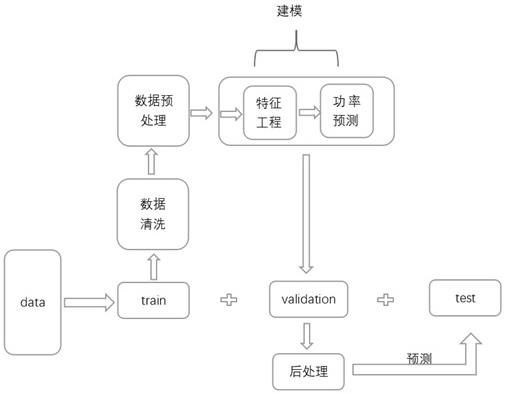
16.图1是本发明实施例的流程示意图;图2是本发明实施例的数据预处理的算法图一;图3是本发明实施例的数据预处理的算法图二;图4是本发明实施例的数据预处理的算法图三;图5是本发明实施例的特征工程算法图;图6是本发明实施例的后处理的损失函数公式图。
具体实施方式
17.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
18.为使本发明专利的目的、特征更明显易懂,下面结合附图对本发明专利的具体实施方式作进一步的说明。
19.本发明的设计思想在于(1)通过树模型解决训练集和测试集分布不一致的状况;(2)通过后处理弥补功率预测模型的表达能力。在提高准确率的前提下,本发明对数据规模没有要求,而且空间复杂度和时间复杂度都较低。
20.实施例一:如图1所示为本发明的流程示意图,具体说明如下:首先获得用于构建功率预测模型的数据集,数据集可以包括风速,温度,风向,湿度,压强,单站点数据和空间数据,其中空间数据是指根据经纬度插值的数据;把数据集分成训练集、验证集和测试集,划分依据是根据时间戳进行划分;训练集:验证集:测试集一般比例为6:2:2,或者划分比例为6:3:1。
21.对数据进行数据清洗,主要包括异常值剔除、缺失值处理等。其中,(1)对于异常值,可以使用很多剔除方法,例如isolation forest孤立森林算法,其通过数据的“疏离”程度去识别和判定异常值,然后进行剔除。(2)对于缺失值的处理,可以采用均值填充,临近值填充,中位数填充和直接删除等方法。
22.然后是本发明中的重要步骤
‑‑
执行数据迁移的预处理过程;执行数据迁移主要是处理分布不同的问题,具体过程为:1、使用树模型对训练集建模,该树模型同样选择孤立森林,建模原理如下:假设训练集样本个数 ψ ,随机选择一个特征作为起始节点,并在该特征的值域里随机选择一个值,对ψ个样本进行二叉划分,将样本中小于该取值的样本划到左分支,样本中大于该取值的划到右分支。然后在左右两个分支重复这样的二叉划分操作。直到达到满足如下条件:1)数据本身不可再分割;2)二叉树达到限定的最大深度,如图2、图3即是本步骤具体实施时可采用的建模算法的参考内容。
23.2、训练集建模后,用该模型对测试集样本进行预测,统计每个样本的路径长度,然后对路径长度进行排序;如图4所示即是本步骤具体实施时可参考采用的主要算法内容。
24.3、由于路径长度越大说明样本所在区域密度越大,模型越容易预测,所以只针对路径长度短的样本进行数据迁移,数据迁移的第一步要确定一个下p分位数以及属于该下p分位数的样本,计算方法为:1)将路径长度数据从小到大排列;2)确定一个下p分位数的位置,该下p分位数相当于从小开始的p分位数,参数p依据数据集而定;3)确定该下p分位数具体的数值,即属于该下p分位数的样本。
25.数据迁移的第二步是针对属于下分位数p的样本采用最近邻方法找到训练集中的数据,然后生成新的样本加入到训练集中。具体过程包括:采用knn算法,首先对训练集用knn建模,然后针对属于该下p分位数的样本m,用建好的knn模型遴选k个数据,生成新样本有两种策略:1)直接把这mk个样本加入到训练集中;2)通过smote算法生成新的mk个样本加入到训练集中。
26.在完成数据迁移后,构建风电功率预测模型前,还需要将生成新样本后的训练集数据进行特征工程处理,构造新的特征,本发明中特征工程主要思想是stacking:首先训练多个不同的模型,可以用不同特征组合进行训练,例如风向、压强等,然后再以各个模型的输出为输入来训练一个模型,以得到一个最终的输出作为新特征,例如不同高度的风速构造成的新特征;或者用相同高度的所有特征构造成新的特征等等。
27.如图5所示是stacking方法进行特征工程的步骤:步骤中first
‑
level算法尽量选择不同的算法,如可以选择gbdt,randomforest, lasso,svm.stacking。
28.在经过特征工程后构造成新的特征后,将原有的特征加上新构造的特征进行风电
功率预测的建模,本实施例中选择的模型是xgboost,功率建模后,本发明另一个重要步骤为后处理的过程,主要用于解决模型表达能力不足问题。风的功率预测曲线类似s型曲线(物理曲线是三次函数),现有的模型对大风速和小风速预测精度并不高,后处理的过程就是处理该问题。可根据风机本身功率曲线参数,对预测数据进行后处理。风机本身功率曲线参数是由厂商提供的一组数据,就是风速和功率的理论对应数据。因为功率曲线类似sigmoid曲线,有两个拐点,根据风机本身功率曲线的拐点把曲线分为3段,每段根据损失函数进行优化。
29.建模的损失函数为rmse或者mae,如图6所示为这两种损失函数的公式。
30.实施例二:在实施例二中,本发明提出了用于实现实施例一所述基于数据迁移的风力发电功率预测方法的一种装置,该装置包括数据预处理模块、功率预测模型构建模块、后处理模块。
31.1、数据预处理模块,用于使用树模型进行数据集的预处理,具体包括如下单元:数据划分单元,用于将数据集根据时间戳划分训练集、验证集和测试集;进行数据清洗;树模型建模单元,用于使用树模型对训练集建模;测试集排序单元,用于用树模型建模单元构建的模型对测试集样本进行预测,统计每个样本的路径长度,然后对路径长度进行排序;新样本生成单元,用于针对测试集排序单元的排序结果,选取下p分位数的样本,采用最近邻方法寻找训练集中数据,生成新样本加入到训练集中;特征工程单元,用于将训练集数据进行特征工程处理;2、功率预测模型构建模块,用于使用数据集(包括通过新样本生成单元生成的训练集新样本,以及经特征工程单元新构造的特征)构建功率预测模型;3、后处理模块,用于构建功率预测模型后,根据风机本身功率曲线参数,对预测数据进行后处理。所述后处理模块根据风机本身功率曲线的拐点把曲线分为3段,每段根据损失函数进行优化。
32.实施例二中所述装置可以实现实施例一中所述的所有方法步骤。
33.通过上述实施例的内容,可以看出本发明的实际创新点在于:1,数据迁移,在样本密度估计中方法有很多,但本发明使用树模型是效率最高的而且可以并行处理,适合大量数据;2,由于风力发电功率预测比较复杂,现有的模型表达能力不足以使整体效果最好,本发明通过加入后处理模块,把曲线分为3段,采用逐段学习的思路来使整体效果最好。
34.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1