一种基于表情驱动的3D虚拟形象生成方法
一种基于表情驱动的3d虚拟形象生成方法
技术领域
1.本发明属于3d虚拟形象生成领域,尤其是涉及一种基于表情驱动的3d虚拟形象生成方法。
背景技术:
2.3d虚拟形象生成涵盖了人脸识别、表情识别和表情动画、虚拟模型生成等方面。其中,3d虚拟形象生成利用3d人脸重建技术恢复出人脸的3d结构,同时和2d信息做有机融合,并基于此进行人脸属性分析,从各个维度分析出人脸特征,生成个性化的虚拟形象。同时,也会实时进行人脸的表情分析,用于驱动生成的虚拟形象。在此之上,还会借助人体姿势进行相关分析,通过真实渲染引擎与现实场景相融合,将匹配用户表情与动作的个性化3d虚拟形象实时呈现给用户。
3.公开号为cn106204698a的中国专利文献公开了一种为自由组合创作的虚拟形象生成及使用表情的实现方法,包括:从一虚拟形象器官集合中选择脸部器官或局部脸孔作为部件形成基础虚拟形象;选择特定表情;然后以符合条件的器官部件替代所述基础虚拟形象中的器官部件,使虚拟形象符合所选择的特定表情。公开号为cn111612876a的中国专利文献公开了一种表情生成方法包括:获取目标用户图像;根据所述目标用户的体貌特征元素,生成与所述目标用户图像关联的虚拟人物形象;基于所述虚拟人物形象,生成所述虚拟人物形象的表情图像。但是上述两种方法制作的表情均无法与用户真实的实时表情相对应。
4.基于真实人物的三维虚拟形象制作往往需要操作者具有计算机图形学技术背景以及能够使用专业的三维建模软件,消耗了大量的时间和精力。而依赖专业扫描设备来获取三维人脸模型的方法成本较高,且常常带有复杂噪声,依赖专业人员进行后期手动处理,致使生产周期过长。
5.脸部动画技术在电影虚拟人物表情制作以及面部动画驱动方面有着广泛的应用,其对面部真实表情的捕捉在泛娱乐领域有较好的发展前景。但是,使用昂贵的专业捕捉设备来实现的面部动画技术不具有实际应用性,基于骨骼和关节点的动画技术主要用于身体姿态的动画,在面部表情动画中不能很好复现褶皱等面部表情细节。
技术实现要素:
6.本发明提供了一种基于表情驱动的3d虚拟形象生成方法,可以通过人的面部运动来控制虚拟模型,使之产生的虚拟形象可以有人脸相似的表情效果。
7.一种基于表情驱动的3d虚拟形象生成方法,包括以下步骤:
8.(1)使用单目摄像头实时采集人脸视频;
9.(2)将单目摄像头捕捉的人脸模型与虚拟形象模型进行比例对齐,;建立人物的源网格s中的三角形面和目标虚拟形象网格t中三角形面的映射;
10.(3)将脸部划分为六个区域,对人物模型与虚拟形象模型中面部区域网格结构差
异较大的部分进行区域标记并优化,将人脸模型每个区域的三角面通过仿射变换映射在对应虚拟形象模型的面上,而后平移顶点,基于模型间映射变换共享顶点生成关键形状;
11.(4)对关键形状进行形变转移优化,获得与源人物模型相对应的虚拟形象融合模型;
12.(5)将形变传递算法应用到对应人脸网格模型的表情融合模型中,基于facs编码面部动作单元,通过线性组合拟合出虚拟形象的表情形状;
13.(6)在虚拟形象驱动模块中基于映射关系驱动虚拟形象融合模型产生动态表情、渲染动画效果,使之产生与原视频中人脸相同的表情动作。
14.进一步地,
15.步骤(2)中,建立人物的源网格s和目标虚拟形象网格t的映射时,将人脸用三维网格m(v,f)表示,v={v1,...v
n
}为三维顶点集合,f={f1,...,f
m
}为连接所有顶点的三角形面集合,发生形变后,相邻两个三角网格满足如下关系:
16.t
j
v
i
+d
j
=t
k
v
i
+d
k
j,k∈p(v
i
)
17.其中,j和k表示两个相邻的三角网格,v
i
表示两个三角形网格的共同顶点,p表示所有的三角形网格集合。
18.进一步地,人物的源网格s中的三角形和目标虚拟形象网格t中三角形的映射变换共享顶点,人物的源网格s与虚拟形象网格t具有对应关系,即:
19.m={(s1,t1),(s2,t2),...,(s
m
,t
m
)}
20.其中,s
m
为源网格中面的索引,t
m
为虚拟形象网格中面的索引。
21.步骤(3)中,将脸部划分为六个区域,分别为左眉毛、右眉毛、鼻子、右眼、左眼和嘴巴。
22.所述的仿射变换包括但不限于旋转、缩放和剪切。
23.基于模型间映射变换共享顶点生成关键形状时,损失函数为:
[0024][0025]
其中:
[0026]
v
i
和v
′
i
(i∈1,2,3)分别代表三角形面形变前后的三个顶点,l
k
是源网格的坐标集合,r(i)表示虚拟形象上的网格坐标索引,u
i
和u
′
i
分别代表源网格与虚拟形象网格上的位移向量,(v
i
)
s0
为源人物网格上的点,(v
i
)
sn
为中间过程中源网格融合模型上的点,(v
′
r(i)
)
tn
为中间过程中虚拟形象网格融合模型上的点。
[0027]
步骤(4)中,对关键形状进行形变转移优化时,重复最小化过程计算形变头像网格的新顶点坐标,迭代系数为ω,直至获得与源人物模型相对应的虚拟形象融合模型,最优化函数为:
[0028][0029]
其中,i为3
×
3变换矩阵,adj(i)是第i个面相邻面的集合,c
i
为源网格与虚拟形象
网格的最邻近点。
[0030]
步骤(5)中,虚拟形象的表情形状f表示为:
[0031][0032]
其中,表情融合模型表示为b=b0,b1,...,b
n
,其中b0表示自然表情形状,b
i
为其他表情形状,以α
i
表示第i个表情系数。
[0033]
与现有技术相比,本发明具有以下有益效果:
[0034]
本发明的方法,使得普通用户仅需要通过单目视频相机,就能够实时的将人的脸部表情映射到虚拟角色上,生成具有真实感的角色动画,具有较高易用性和可扩展性,满足动漫、影视、直播、虚拟现实等诸多领域的需求。
附图说明
[0035]
图1为本发明实施例中基于表情驱动的3d虚拟形象生成方法的框架图;
[0036]
图2为本发明实施例中基于表情驱动的3d虚拟形象生成方法的流程图;
[0037]
图3为本发明实施例中源网格和目标虚拟形象网格中三角形的映射示意图。
具体实施方式
[0038]
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
[0039]
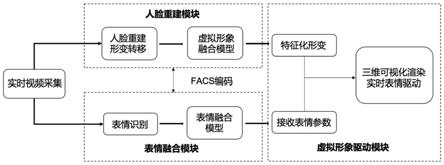
如图1所示,一种基于表情驱动的3d虚拟形象生成方法,实现过程分为三个模块,分别是人脸重建模块、表情融合模块和虚拟形象驱动模块。
[0040]
使用三维人脸模型重建技术可以在三维空间中重建出与真实人脸特征相似的三维模型,基于单目摄像头采集人脸进行人脸重建的主要问题在于人脸对齐、人脸姿态估计和模型参数估计。本发明提出一种基于面部区域位置的人脸重建模块,将人脸划分为左眉毛、右眉毛、鼻子、右眼、左眼和嘴巴6个部分进行测量,对源人物模型的所有关键形状重复最小化过程,得到与源模型相对应的虚拟形象融合模型,对于普通用户而言无需使用专业软件创建三维blandshape模型即可驱动虚拟形象。
[0041]
本发明在表情融合上分为头部和表情两个部分进行参数化,头部变化是指人物头部的平移、旋转等刚性变化;表情变化则基于facs编码面部动作单元,通过线性组合拟合出人脸的常见表情,而后在虚拟形象驱动模块中基于上述映射关系驱动可形变虚拟模型产生动态表情、渲染动画效果,使之产生与原视频中人脸相同的表情动作。
[0042]
为适配包含卡通3d形象、游戏怪兽形象等五官与人类差异较大的虚拟形象,本发明提出一种基于表情驱动的3d虚拟形象生成方法,流程如图2所示。
[0043]
在模型表示上,本发明将人脸用三维网格m(v,f)表示,v={v1,...v
n
}为三维顶点集合,f={f1,...,f
m
}为连接所有顶点的三角形面集合。由于形变建立在三角形网格上,人物的源网格s中的三角形需要和目标虚拟形象网格t中的三角形建立映射,如图3所示,发生形变后,相邻两个三角网格满足如下关系:
[0044]
t
j
v
i
+d
j
=t
k
v
i
+d
k
j,k∈p(v
i
)
[0045]
j和k表示两个相邻的三角网格,v
i v
i
表示两个三角形网格的共同顶点,p表示所有的三角形网格集合。
[0046]
基于s与t之间映射变换共享顶点,人物的源网格与虚拟形象网格具有对应关系,即:
[0047]
m={(s1,t1),(s2,t2),...,(s
m
,t
m
)}
[0048]
人脸模型对虚拟模型的匹配即为人物的源网格与虚拟形象网格具有对应关系的求解。本发明提出基于面部区域重定位的虚拟模型映射方法,首先将虚拟形象模型与单目摄像头捕捉的人脸模型进行比例对齐,将脸部划分为左眉毛、右眉毛、鼻子、右眼、左眼和嘴巴6个区域,将人脸模型每个区域的三角面通过旋转、缩放和剪切等仿射变换映射在对应虚拟形象模型的面上,而后平移顶点,基于模型间映射变换共享顶点生成关键形状。区域坐标位置定向过程的公式表达如下:
[0049]
以v
i
和v
′
i
(i∈1,2,3)分别代表三角形面形变前后的三个顶点,损失函数为:
[0050][0051]
其中:
[0052]
l
k
是源网格的坐标集合,r(i)表示虚拟形象上的网格坐标索引,u
i
和u
′
i
分别代表源网格与虚拟形象网格上的位移向量,(v
i
)
s0
为源人物网格上的点,(v
i
)
sn
为中间过程中源网格融合模型上的点,(v
′
r(i)
)
tn
为中间过程中虚拟形象网格融合模型上的点。
[0053]
而后对关键形状进行形变转移优化,重复最小化过程计算形变头像网格的新顶点坐标,迭代系数为ω,直至获得与源人物模型相对应的虚拟形象融合模型。最优化函数为:
[0054][0055]
其中,i为3
×
3变换矩阵,adj(i)是第i个面相邻面的集合,c
i
为源网格与虚拟形象网格的最邻近点。
[0056]
当完成源人物模型与虚拟形象模型的关键形状映射后,进入表情融合阶段。对于符合facs标准的表情融合模型,每一个基表情对应于facs的一个动作单元,具有相应的语义特征。基于此,应用形变传递算法到特定的人脸网格模型的表情融合模型制作中,将表情融合模型表示为b=b0,b1,...,b
n
,其中b0表示自然表情形状,b
i
为其他表情形状,以α
i
表示第i个表情系数,则虚拟形象的表情形状f可以表示为:
[0057][0058]
基于此,自然表情形状和其他表情形状以一定系数按公式进行线性组合,即可生成新的表情形状。
[0059]
通过上述步骤,普通用户仅需要通过单目视频相机,就能够实时的将人的脸部表情映射到虚拟角色上,生成具有真实感的角色动画,具有较高易用性和可扩展性,满足泛娱
乐产业发展需求。
[0060]
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1