一种基于知识图谱的诈骗电话分析方法与流程
1.本发明涉及信息处理技术领域,具体涉及一种基于知识图谱的诈骗电话分析方法。
背景技术:
2.电信诈骗危害巨大,一直以来都为相关部门打击的重点,近年来,电信诈骗如何有效的防治已作为打击电信诈骗案件的重要手段,我国拥有数亿电信用户,如何针对海量的电信用户错综复杂的话单通讯网络以及海量的话单数据,筛选出疑似涉嫌电信诈骗的电话号码,成为当下反电诈研究的热点问题。
技术实现要素:
3.鉴于现有技术中存在的技术缺陷和技术弊端,本发明实施例提供克服上述问题或者至少部分地解决上述问题的一种基于知识图谱的诈骗电话分析方法,具体方案如下:
4.一种基于知识图谱的诈骗电话分析方法,所述方法包括:
5.步骤1,获取话单数据集d,所述话单数据集d包括预设时间段内的所有通话记录数据;
6.步骤2,获取历史电诈话单数据,通过历史电诈话单数据标记数据集d,得到新的话单数据集dn;
7.步骤3,基于话单数据集dn,选择主叫电话号码作为起始节点,被叫号码作为结束节点,通话记录作为边,通话记录中的属性作为边的属性,构建通话知识图谱g;
8.步骤4,通过划分连通子图的方式基于广度优先搜索算法将图谱g划分为若干个极大连通子图gi,其中,每个极大连通子图gi之间互不相连;
9.步骤5,针对极大连通子图gi中的任意节点vi,计算出vi的自我中心网络ego-network,基于自我中心网络ego-network筛选出疑似电诈号码节点;
10.步骤6,将疑似电诈号码节点与对应的边,按照特征集合t{节点出度、节点入度、主叫次数、月通话总次数、月通话总时长、日平均通话时长、最高每日通话频次、平均每日通话频次、通话频次方差}等特征组成样本s,将预设比例的样本s生成训练数据集s1,用于训练诈骗电话筛选的分类模型,剩下的样本s作为数据集s2用于验证诈骗电话筛选的分类模型;
11.步骤7,从样本集合s1中有放回地随机抽取m个样本组成训练集合s1i,从特征集合t中随机选取n个特征子集tj,基于特征子集tj和样本训练集合 s1i构建cart决策树;
12.步骤8,重复多次步骤7,将所有的分类结果进行聚合,计算每个预测目标的得票数,生成cart随机森林模型,将得到高票数的预测目标作为随机森林算模型的最终预测;
13.步骤9,将步骤6中的数据集s2用于cart随机森林模型的验证,输出最佳f1时的模型
14.进一步地,步骤1中,每条通话记录数据包括主叫号码、被叫号码、呼出地点、接受地点、呼叫时间和通话时长信息。
15.进一步地,步骤2中,所述话单数据集dn中包括正常通话记录、涉嫌电诈且已被标记的通话记录数据、涉嫌电诈但未被标记的通话记录数据。
16.进一步地,步骤4中,通话知识图谱g中的关系是有向的,由主叫号码实体指向被叫号码实体,通话号码实体节点中包括电话号码、运营商、注册地点、电话号码所有人姓名和身份证号码信息,通话知识图谱g中的事件,即通话事件call包含该次通话的呼出地点、接受地点、呼叫时间、接通时间、结束时间和通话时长信息。
17.进一步地,步骤5中,通过以下指标筛选出疑似电诈目标节点:
18.a,主叫频繁:即特定时间段内,发起多次的入网呼叫;
19.b,被叫号码不固定:即被叫号码具有一定的离散性;
20.c,主叫时间集中;
21.d,极大连通子图gi的alter节点之间的离散率少于对应的预设阈值;
22.e,极大连通子图gi的ego节点的入度与出度的比值低于对应的预设阈值;
23.其中,alter节点为极大连通子图gi的中心节点,ego节点为极大连通子图gi中除中心节点外的其他节点。
24.进一步地,计算极大连通子图gi的ego节点的入度与出度的比值e
out-in
公式如下:
25.e
out-in
∈[me-σ,me+σ]
[0026]
其中,me为历史诈骗电话ego节点入度与出度比值的平均值,σ为对应的标准差;
[0027]
计算极大连通子图gi的alter节点之间的离散率r
alter
的公式如下:
[0028][0029]
其中,vi与vj为ego节点在自我中心网络ego-network中的alter节点, alter(vi)表示以节点vi为ego节点的自我中心网络ego-network的alter 节点集合,sum表示两个自我中心网络ego-network中alter节点并集。
[0030]
进一步地,步骤9中,若在数据集s2验证中,cart随机森林模型的f1 值未能达到预设阈值,则重复步骤7和8,直至预测目标集合中真实涉嫌电诈节点的比例超过预设阈值,完成训练过程,从而输出最佳f1时的模型。
[0031]
进一步地,f1值计算公式如下:
[0032][0033]
其中,tp表示预测正确且真实正确的,fp表示预测正确但是实际错误的,fn表示预测为错误且实际是正确的,precision表示精确度,recall 表示召回率。
[0034]
本发明具有以下有益效果:
[0035]
本发明针对海量话单数据构建的通话知识图谱,采用结合了 ego-network进行节点初筛,基于较少历史数据,通过构建cart随机森林模型实现了对一段时间内海量通话数据中诈骗电话的预测。应用此方法可基于海量电信话单数据与少量的电诈历史话单数据,挖掘存量话单数据中隐藏的诈骗电话,实现对异常电话号码的快速筛选与甄别,有效助力反电诈“阻断”环节,提高相关部门电信诈骗案件防治效能。
附图说明
[0036]
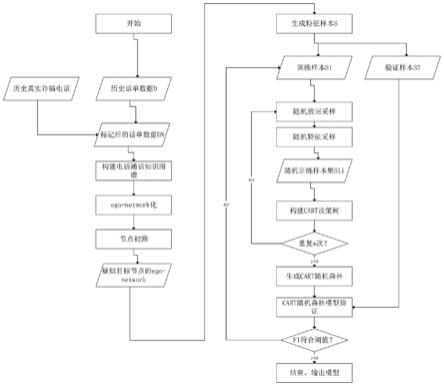
图1为本发明实施例提供的一种基于知识图谱的诈骗电话分析方法的流程图;
[0037]
图2为本发明实施例提供的通话知识图谱案例示意图;
[0038]
图3为本发明实施例提供的通话知识图谱结构示意图;
[0039]
图4为本发明实施例提供的广度优先遍历(bfs)在图中的遍历顺序示意图;
[0040]
图5为本发明实施例提供的一种划分前的完整的电话通话知识图谱示意图;
[0041]
图6为本发明实施例提供的划分后的完整的电话通话知识图谱示意图;
[0042]
图7为本发明实施例提供的通话知识图谱实例示意图;
[0043]
图8~14分别为本发明实施例提供的以a、b、c、e、e、f、g为中心节点ego-network示意图;
[0044]
图15为本发明实施例提供的样本生成与决策树构建示意图;
[0045]
图16为本发明实施例提供的随机森林分类示意图。
具体实施方式
[0046]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0047]
如图1所示,为本发明实施例提供的一种基于知识图谱的诈骗电话分析方法,所述方法包括:
[0048]
步骤1,话单数据整理,选取一段时间内某地区的话单数据集d,所述话单数据集d包括预设时间段内的所有通话记录数据,每条通话记录数据包括主叫号码,被叫号码,呼出地点,接受地点,呼叫时间,通话时长等信息。
[0049]
步骤2,历史异常数据标记,在本文中的异常数据为涉嫌电信诈骗的历史话单数据。利用该地区同一时间段内部分涉嫌电信诈骗的历史话单数据中的电话号码去标记数据集d,得到新的数据集,即话单数据集dn,则标记过的话单数据集dn应包含:正常通话记录,涉嫌电诈且已被标记的通话记录,涉嫌电诈的但未被标记的通话记录。
[0050]
步骤3,通话知识图谱构建,根据话单数据集dn,选择主叫电话号码作为起始节点,被叫号码作为结束节点,通话记录作为边,通话记录中其他属性作为边的属性,构建通话知识图谱g,如图2和3所述。
[0051]
在通话知识图谱g中,关系call即通话事件是有向的,由主叫号码实体指向被叫号码实体。在一段时间内,可能存在相同两个号码实体之间多次通话的情况,通话号码实体节点中包括从话单数据中抽取的电话号码、运营商、注册地点、电话号码所有人姓名和身份证号码等信息,通话事件call 包含该次通话的呼出地点、接受地点、呼叫时间、接通时间、结束时间和通话时长等信息。
[0052]
上述实施例中,将话单数据按照上述实体、关系的属性划分,分别进行知识抽取,最终将话单通话数据整理为实体节点数据与通话事件边数据(rdf 三元组形式),借助nubulagraph图数据库,建立电话通话知识图谱,并完事上述节点数据与边数据的加载导入。
[0053]
步骤4,极大子图划分,基于海量话单数据集dn构建的通话知识图谱g 的规模是巨大的,这将严重影响分析过程的效率,因此需要通过划分连通子图的方式基于广度优先搜索算法(bfs)将图谱g划分为若干个极大连通子图gi,每个极大连通子图gi之间互不相连,因此可用于分布式图计算,加速整个分析过程;
[0054]
广度优先遍历,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。利用广度优先算法(bfs) 用于实现对电话通话图谱的极大连通子图的划分,广度优先遍历(bfs)在图中的遍历顺序如图4所示。
[0055]
一般情况下,支持可并发计算的图往往是可分割的,在针对大规模知识图谱的复杂图计算的场景中,可以将待计算的图谱划分为若干个不相关的子图,通过对这若干个不相关的图谱分别进行计算,以实现对整个图谱的计算,其中,对若干个子图的计算又可分别由不同的计算服务进行,借此来达到分布式计算的效果,提升整体计算效率,图谱划分前后对比如图5和6所示。
[0056]
步骤5,节点的自我中心网络构建,针对子图gi中的任意节点vi,计算出vi的自我中心网络ego-network,并剔除正常社交,工作通讯等模式节点;
[0057]
ego network,又称自我中心网络,网络节点由唯一的一个中心节点ego 以及这个节点的邻居alters组成,边只包括ego与alter之间,以及alter 与alter之间的边,以社交网络为例,针对某个人而言,将此人以及其朋友看作是节点,只考虑这个人和他朋友,以及他朋友之间的连边,就可以得到一个以a为中心的网络,即自我中心网络,如图7~图14所示。
[0058]
ego-network以自我节点为中心,能够很好地反映中心节点的社群关系。
[0059]
网间话务通过网间的信令监测系统分析,可以发现大量的疑似诈骗电话。电信诈骗通话通常具有如下特征:
[0060]
1)主叫频繁:即特定时间段内,发起多次的入网呼叫。
[0061]
2)被叫号码不固定:被叫号码可能离散性很强,诈骗份子很可能是采用广泛撒网的模式,去触碰可能容易上当受骗的人群。
[0062]
3)主叫时间集中:诈骗电话主叫的时间往往是全天性的不停拨打,但是节假日呼叫量减少明显。
[0063]
如图7~图14所示,只有以节点g为中心的ego-network满足“主叫频繁”、“被叫离散”等特点。基于此,我们可以将正常工作社交的ego-network 中心节点剔除,其节点ego-network特征包括:
[0064]
1)alter节点之间存在较少关联;
[0065]
2)ego节点的入度远与出度比值较低;
[0066]
上述特征按照历史诈骗电话ego平均入度出度比值e
out-in
与历史诈骗电话alter节点离散率r
alter
两个指标来衡量,即有:
[0067]eout-in
∈[me-σ,me+σ]
[0068]
其中,me为历史诈骗电话ego节点入度与出度比值的平均值,σ为对应的标准差;
[0069][0070]
其中,vi与vj为ego节点在自我中心网络ego-network中的alter节点, alter(vi)
表示以节点vi为ego节点的自我中心网络ego-network的alter 节点集合,sum表示两个自我中心网络ego-network中alter节点并集的规模。上述公式可以在一定程度上表示ego中心网络中任意两个节点alter 节点之间的关联度,r
alter
越低表示ego中心网络中alter节点越离散。
[0071]
按照上述指标,可筛选出疑似电诈目标节点(即电话号码);
[0072]
步骤6,将疑似电诈号码节点与边,按照特征集合t{节点出度、节点入度、主叫次数、月通话总次数、月通话总时长、日平均通话时长、最高每日通话频次、平均每日通话频次、通话频次方差}等特征组成样本s,将70%的 s样本生成训练数据集s1用于训练诈骗电话筛选的分类模型,剩下的样本作为数据集s2用于验证诈骗电话筛选的分类模型;
[0073]
步骤7,从样本集合s1中有放回地随机抽取m个样本组成训练集合sli,从特征集合t中随机选取n个特征tj(在样本集合sli中进行特征采样),用于构建cart决策树,如图15所示。
[0074]
决策树是一种典型的单分类器,该分类器的生成和决策过程分为三个部分,首先是通过对训练集进行递归分析,生成一棵状如倒立的树状结构;然后分析这棵树从根节点到叶子结点的路径,产生一系列规则;最后,根据这些规则后,对新数据进行分类或预测。从本质上讲,决策树的分类思想其实是通过产生一系列规则,然后通过这些规则进行数据分析的数据挖掘过程。
[0075]
决策树可视为一个树状模型,树中包括三种节点:根节点、中间节点、叶子节点。树中每个节点表示对象的属性,而从每个节点出发的分叉路径则代表的某个可能的属性值,而每个叶子结点则对应从根节点到该叶子节点所经历的路径所表示的对象的值。从根节点出发,经过若干中间节点后,到达叶子节点的路径表示某个规则,整个树表示由训练样本决定的规则的集合。决策树仅有单一输出,也就是从根节点出,只能到达唯一的叶子节点,即规则是唯一的,这样就可以用于数据的分类和预测。
[0076]
cart决策树作为决策树的一种,在算法上衣id3、c4.5算法存在一定差距,主要差距表现在它在进行节点分裂时,采用的分裂规则是gini指标最小原则。
[0077]
cart算法将分裂属性的取值划分为两个子集,然后从这两个子集出发,计算由训练集决定的gini指标,然后采用二分递归的方式,将当前训练集分成两个子集,从而产生左右两个分枝的子树。当节点发生分裂时,该算法使用gini指标来度量数据划分,其计算过程如下:
[0078]
1)计算样本的gini系数:
[0079][0080]
其中,pi代表类别cj在样本集s中出现的概率。
[0081]
2)计算每个划分的gini系数
[0082]
如果s被分隔成两个子集s1与s2,则此次划分的gini系数为:
[0083][0084]
在cart算法,叶子节点产生的规则如下:
[0085]
1)当前数据集的样本个数小于某个给定的值;
[0086]
2)当前数据集的样本都属于同一类;
[0087]
3)当前数据集的属性变量为0;
[0088]
4)决策树的深度大于用户设定的值。
[0089]
步骤8,重复多次步骤7,将所有的分类结果进行聚合,计算每个预测目标的得票数再选择模式(最常见的目标变量),生成cart随机森林模型,将得到高票数的预测目标作为随机森林模型的最终预测;
[0090]
决策树算法适用于离散型数据,能够提取出列数据中蕴含的规则,不需要先验知识,比神经网络等方法更容易解释,在解决分类问题时,决策树算法具有计算复杂度不高,便于使用且高效的优点。但是决策树算法在处理缺失数据时很困难,此外,可能会对样本空间过度分割导致过拟合的问题。通过剪枝的方法避免决策树的过拟合问题又会提高算法的复杂性。所以决策树算法的性能提升有一定的局限性
[0091]
随机森林模型在以决策树为基学习器构建bagging集成的基础上,进一步在决策树的训练过程中引入随机属性的选择。随机森林算法简单、易于实现、计算开销小,在很多现实任务中展现出强大的性能。
[0092]
随机森林分类是由很多决策树分类模型组成的组合分类模型,每个决策树分类模型都有一票投票权来选择最优的分类结果。随机森林分类的基本思想:首先,利用bootstrap抽样从原始训练集抽取m个样本,每个样本的样本容量都与原始训练集一样;然后,对m个样本分别建立n个决策树模型,得到k种分类结果;最后,根据k种分类结果对每个记录进行投票表决决定其最终分类,如图16所示。
[0093]
步骤9,将步骤6中的验证数据集s2用于随机森林模型的验证,若在 s2中随机森林模型的f1值未能达到阈值,重复7,8步骤,直至预测目标集合中真实涉嫌电诈节点的比例超过阈值,完成训练过程,输出最佳f1时的模型;
[0094]
其中f1值计算方式如下:
[0095][0096]
其中,tp表示预测正确且真实正确的,fp表示预测正确但是实际错误的,fn表示预测为错误且实际是正确的,precision表示精确度,recall 表示召回率。
[0097]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1