卫生部门中患者检查设备的使用数据中的过程异常的基于人工智能的识别的制作方法
1.本发明涉及一种训练用于探测过程中的异常的机器学习算法的计算机实施的方法和一种用于探测过程中的异常的计算机实施的方法以及对应的数据处理系统,并且本发明还涉及一种用于探测过程中的异常的系统。
背景技术:
2.由多个不同的活动构成的过程或工作流程在不同的领域和学科中执行,以便实现期望的预定义的结果。例如,在制造过程中,可以依次或同时执行特定活动,如制造步骤、过程控制变量的设定等,以便从一个或多个原始物质或原始材料中制造预确定的产品。在应用过程中,也可以依次或同时执行特定活动,如措施、应用变量的设定等,以便在对象(例如产品、患者等)处实现预确定的应用结果。在借助于机器或设备或者在机器或设备处执行的过程中,通常收集大量数据、尤其记录数据,所述数据记录所执行的使用序列。在此,具有始终相同的过程步骤的标准化顺序的标准化过程通常被认为是有利的。
3.现代卫生保健和尤其临床诊断和治疗在很大程度上基于高度发展的技术检查设备,如诊断成像设备(例如超声设备、x射线设备、计算机断层扫描设备、磁共振断层扫描设备(mrt)、正电子发射断层扫描设备(pet)、数字病理学扫描仪、基因组排序设备/微阵列)和测量生物样本的健康相关的值的不同的自动化实验室设备。治疗设备、如机器人支持的手术系统、半自动或全自动移植工具等也可以按照预定义的工作步骤用于治疗。多个所述检查和治疗设备不仅对设备本身、而且对人员的培训要求显著投资。因此,卫生保健供应商对尽可能优化这种设备的使用感兴趣。
4.随着云技术的流行和朝向医疗物联网(miot)的趋势,这种设备提供越来越多的元数据(例如日志数据/记录数据),借助所述元数据,可以详细地监控检查的执行,或换言之,可以详细地监控过程。这意味着,需要不同的和变化的准备和测量步骤的不同类型的检查可以与计时、可能的错误或警告条件以及传感器测量一起观察。当多个这种设备运行时,卫生保健供应商对如下感兴趣:维持患者检查的“正常的”运行,并且获得关于对质量或效率产生负面影响的“异常的”患者检查的信息,以便能够尽可能快地消除(系统的)有错误的记录或过程。
5.在此可以示例性地引用放射学mrt检查。在日常例程中,在不同的mrt扫描仪处以不同的方法类型执行患者检查。每个方法由必须对于特定的检查类型执行的一系列记录步骤构成。在执行这种方法时,医务人员应遵循准则记录序列、也称为指南。准则记录序列规定,必须以哪个顺序执行哪些记录步骤。由此防止,缺乏临床诊断或对患者造成伤害。此外,扫描的注释变得更容易,并且扫描持续时间标准化,这对于成本效率和有效规划检查是前提条件。在临床运行中观察到的使用序列有时与期望的准则记录序列偏差。偏差可能归因于需要专门决定的医疗情况或通过不正确的设备操作引起。医疗专家对系统偏差、即异常感兴趣,因为系统偏差例如可能表明预设的准则记录序列中的错误或低效率,或对医务人
员的额外的培训要求。由于检查的大的数量,所记录的使用序列的手动分析通常不能执行或不切实际。
6.在形式上,从上述问题中得出所记录的使用序列的集合,可以将所述集合作为对过程的执行的观察建模。
技术实现要素:
7.因此,本发明的目的是自动化地确定过程中的异常。为此,本发明提供根据用于训练用于探测过程中的异常的机器学习算法的计算机实施的方法。对应的数据处理系统和计算机实施的方法、数据处理系统以及此外用于探测过程中的异常的系统是下面的描述的主题。本发明的改进方案和设计方案是对应的下面的描述的主题。
8.根据本发明的第一方面,用于训练用于探测过程中的异常的机器学习算法的计算机实施的方法包括以下步骤:
[0009]-提供过程的训练数据集,所述训练数据集包括第一数量n个训练使用序列,其中第一数量n大于一(n》1)。
[0010]-基于训练数据集借助于从训练数据集中随机抽取预定义的第三数量m个使用序列来创建预定义的第二数量k个自举数据集,其中第二数量k大于一(k》1),其中从第一数量n个训练使用序列中进行每次抽取。
[0011]-创建与第二数量k相同数量的过程树,其方式为,基于自举数据集中的一个自举数据集借助于过程挖掘算法来创建每个过程树。
[0012]
根据本发明的第二方面,用于训练用于探测过程中的异常的机器学习算法的计算机实施的方法包括以下步骤:
[0013]-提供过程的训练数据集,所述训练数据集包括第一数量n个训练使用序列,其中第一数量n大于一。
[0014]-创建第二数量k个过程树,其中第二数量k大于一(k》1),其方式为:基于训练数据集借助于过程挖掘算法来创建每个过程树,其中在每个过程树的每个算子节点中随机选择可能的分裂算子中的一个分裂算子。
[0015]
根据本发明的第三方面,数据处理系统包括用于执行根据本发明的第一方面或第二方面的方法的机构。
[0016]
根据本发明的第四方面,计算机程序产品包括指令,在通过计算机运行计算机程序产品时,所述指令促使所述计算机执行根据本发明的第一方面或第二方面的方法。
[0017]
根据本发明的第五方面,在计算机可读的数据载体上存储有根据本发明的第四方面的计算机程序产品。
[0018]
根据本发明的第六方面,用于探测过程中的异常的计算机实施的方法、尤其用于借助医疗设备探测过程中的异常的计算机实施的方法包括以下步骤:
[0019]-接收过程的使用序列。
[0020]-基于接收到的使用序列借助于经训练的机器学习算法来确定预测矢量,所述经训练的机器学习算法借助于根据本发明的第一方面或第二方面的方法被训练,其中对于经训练的mla的每个过程树,预测矢量包括如下值:所述值说明使用序列是否匹配于相应的过程树。
[0021]-从预测矢量和第二数量k来确定归一化适合度值。
[0022]-基于归一化适合度值对过程进行分类。
[0023]
根据本发明的第七方面,数据处理系统包括用于执行根据本发明的第六方面的方法的机构。
[0024]
根据本发明的第八方面,计算机程序产品包括指令,在通过计算机运行计算机程序产品时,所述指令促使所述计算机执行根据本发明的第六方面的方法。
[0025]
根据本发明的第九方面,在计算机可读的数据载体上存储有根据本发明的第八方面的计算机程序产品。
[0026]
根据本发明的第十方面,用于探测过程中的异常的系统包括医疗设备和根据本发明的第九方面的数据处理系统。医疗设备构成用于记录关于过程的使用序列。数据处理系统与医疗设备通信连接并且构成用于从医疗设备接收使用序列。
[0027]
根据本发明的第二方面的方法为对于根据本发明的第一方面的方法的替选方案。然而,两种方法可以不受限地彼此组合。因此,下文中的实施方案不受限地适用于两种所述方法。
[0028]
当前,术语过程被理解为以实现预定义的或期望的结果为目的的多个活动或过程步骤的流程。过程可以是方法过程或应用过程、生产过程或制造过程等,以及由其中的一个或多个过程构成的组合。例如,过程可以是诊断过程或检查过程、治疗过程或医治过程、安装过程、分布过程、测量过程、检验过程、维护过程等,以及由其中的一个或多个过程构成的组合。
[0029]
在设备和尤其医疗设备处执行的过程(参见设备的用途)由设备本身或监控设备(“观察器”、“监视设备”)记录。在此,在执行过程期间借助(医疗)设备执行的活动作为使用序列记录。所记录的使用序列描述依次(顺序)地或同时(并行)地执行的活动的顺序。使用序列尤其可以示出为活动的矢量。
[0030]
因此,使用序列或训练使用序列可以分别包括在使用医疗设备来对患者进行诊断和/或治疗时的活动或过程步骤的顺序。例如,过程“颅骨或大脑的ct”的使用序列可以包括以下活动/过程步骤:
[0031]
a)将颅骨定位在ct扫描仪的等中心中;
[0032]
b)执行拓扑图(topogramm)/概览扫描;
[0033]
c)调整ct扫描仪的扫描参数;
[0034]
d)执行螺旋扫描;
[0035]
e)调整ct扫描仪的扫描参数;
[0036]
f)给予造影剂;
[0037]
g)执行螺旋扫描;
[0038]
h)调整ct扫描仪的扫描参数;
[0039]
i)执行螺旋扫描;
[0040]
j)将患者移出。
[0041]
例如,过程“负荷ekg”的使用序列可以包括以下活动/过程步骤:
[0042]
a)将电极安放在患者处;
[0043]
b)将血压袖带安放在患者处;
[0044]
c)将脉搏血氧仪安放在患者处;
[0045]
d)测量静息心率;
[0046]
e)测量静息血压;
[0047]
f)测量静息血氧饱和度;
[0048]
g)导出5s的静息ekg;
[0049]
h1)将自行车测力计的阻力增加10瓦;
[0050]
i1)测量负荷心率;
[0051]
j1)测量负荷血压;
[0052]
k1)测量负荷血氧饱和度;
[0053]
l1)导出10s长度的负荷ekg;
[0054]
h2)将自行车测力计的阻力增加10瓦;
[0055]
i2)测量静息心率;
[0056]
j2)测量静息血压;
[0057]
k2)测量静息血氧饱和度;
[0058]
l2)导出10s长度的负荷ekg;
[0059]
h3)将自行车测力计的阻力增加10瓦;
[0060]
i3)测量静息心率;
[0061]
j3)测量静息血压;
[0062]
k3)测量静息血氧饱和度;
[0063]
l3)导出10s长度的负荷ekg;
[0064]
...
[0065]hn
)将自行车测力计的阻力增加10瓦;
[0066]in
)测量静息心率;
[0067]jn
)测量静息血压;
[0068]kn
)测量静息血氧饱和度;
[0069]
ln)得出10s长度的静息ekg负荷ekg;
[0070]
m)在没有负荷的情况下等待60s长度;
[0071]
n)测量静息心率;
[0072]
o)测量静息血压;
[0073]
p)测量静息血氧饱和度;
[0074]
q)从患者移除脉搏血氧仪;
[0075]
r)从患者移除血压袖带;
[0076]
s)从患者移除电极。
[0077]
医疗设备(借助所述医疗设备或在所述医疗设备中,在医疗设备处执行的过程被记录为使用序列)例如可以是成像设备(例如mrt设备、ct设备、pet设备、spect设备、pet-mrt设备、pet-ct设备、x射线设备、乳腺x射线摄影设备等)、实验室诊断设备(例如自动化尿液分析设备、自动化血液分析设备、自动化免疫分析系统等)、肺功能测试设备、(负荷)ekg系统、步态分析系统等。
[0078]
因此,过程例如可以是成像过程(例如头部的mrt、膝盖的ct等),并且使用序列可
以是执行或已经执行以用于创建期望的图像的活动的顺序。
[0079]
术语机器学习算法(“machine learning algorithm”,mla)当前理解为通过训练机器学习算法创建的模型。根据本发明的经训练的机器学习算法、在此也称为“随机过程森林(英文:random process forest)”应能够将过程的在其上训练机器学习算法的执行过程分类为“正常的”或“异常的”。在此,如果执行过程对应于预设的标准化过程或如果所产生的使用序列类似于对应的准则记录序列,则执行过程或所产生的使用序列是“正常的”。相反,如果执行过程不对应于预设的标准化过程或如果所产生的使用序列不类似于对应的准则记录序列,则执行过程或所产生的使用序列是“异常的”,即存在异常。
[0080]
在训练机器学习算法时,原则上可以使用监督学习(“supervised learning”)、半监督学习(“semi-supervised learning”)或无监督学习(“unsupervised learning”)。
[0081]
在监督学习的情况下,训练数据集包括训练数据,所述训练数据分别设有标记(“label”)。标记分别说明,关于相应的训练数据的正确的结果是什么(例如在分类任务的情况下,相应的训练数据属于哪个类别)。因此,在基于监督学习来训练机器学习算法时,根据由算法预测的结果与正确的结果(标记)之间的差值来调整或训练算法。
[0082]
在无监督学习的情况下,训练数据集的训练数据不具有标记(“label”)。因此,无监督学习表示不具有事先已知的目标值以及不具有受到环境的奖励的机器学习。在无监督学习中尝试,识别与无结构噪声偏离的训练数据中的模型。无监督学习的典型代表是自动分区(集群(英文:clustering))或(训练数据的)压缩以用于维度减小。基于训练数据从多个不相关的决策树中创建“随机森林(英文:random forest)”同样是无监督学习的一个类型。经训练的随机森林是分类器,所述分类器包括多个不相关的决策树。在无监督学习过程期间,所有决策树在特定类型的随机化的条件下生长(创建)。对于分类,经训练的随机森林的每个决策树允许做出决定,并且具有最多票数的类别决定最终的分类。
[0083]
当前,过程的训练数据集包括第一数量n个训练使用序列。训练使用序列可以是应对异常进行检查的过程的n个执行的所存储的使用序列。第一数量n可以优选地在1,000和100,000之间(1,000《=n《=100,000),并且特别优选地在10,000至25,000之间(10,000《=n《=25,000)。例如,医院或诊所的医疗设备(例如mrt设备)的所记录的使用序列可以用作为训练数据集。因为使用无监督学习,所以使用序列不必(手动地)设有标记,并且可以借助作为训练数据集的未标记的使用序列来训练机器学习算法。
[0084]
在根据本发明的第一方面的方法中,创建预定义的数量k个自举数据集,其中k大于一(k》1)。为此,基于训练数据集来执行所谓的自举。从具有n个训练使用序列的训练数据集中为自举数据集中的每个自举数据集分别随机抽取m个训练使用序列。在此,分别有回置地抽取,由此从(完整的)第一数量n个训练使用序列中进行每个随机抽取。换言之,每次在从训练数据集中随机抽取训练使用序列中的一个训练使用序列并且存储在自举数据集中的一个自举数据集中之后,将所抽取的使用序列返还到训练数据集中。因此,相同的使用序列可以在自举数据集中出现多次。在此,自举数据集的随机抽取的使用序列的第三数量m大于一(m》1)。
[0085]
随后基于k个自举数据集创建k个过程树。为此,基于自举数据集中的每个自举数据集借助于过程挖掘算法创建恰好一个过程树。用于创建过程树的可能的过程挖掘算法是归纳挖掘算法、阿尔法挖掘算法、启发式挖掘算法、进化树挖掘算法等。
[0086]
过程树是块结构化的工作流程的紧凑和抽象的表示,换言之,所述过程树是呈树的形式的过程的模型。过程树是petri网的子类型,所述petri网满足健全性(“soundness”)的标准,并且所述过程树包括部位或活动节点、也称为叶子,其具有活动或无声活动和转换或算子节点、也称为内部节点,其具有分裂算子。活动可以是可以作为所记录的使用序列存在的可观察的动作、步骤和措施。无声活动可以是可以隐含地存在于使用序列中的不可观察的动作、步骤和措施。算子节点分别设有分裂算子。因此,借助于分裂算子,算子节点说明,状态节点的活动可以或必须以哪个顺序执行。得出以下四个类型的分裂算子:
[0087]-顺序组合(“sequence”或seq);
[0088]-排他选择(xor);
[0089]-并行组合(“parallel”或par);
[0090]-循环(“redo”或loop)。
[0091]
在此,如果满足以下标准,则满足健全性的标准:
[0092]-安全性:每个部位/活动节点不能够同时保持多个令牌。
[0093]-符合规定的结束:在每次模型执行之后,模型在结束部位/最后的活动节点处仅包含一个令牌。
[0094]-用于结束的选项:模型执行可以从每个状态结束。
[0095]-不存在空段:模型不包含永不能到达的转换/算子节点。
[0096]
通过随机抽取使用序列和预定义的数量k个自举数据集,将随机性引入到所创建的过程树中,即引入到所创建的过程模型中。这确保,尽管训练使用序列的数量n有限,但是过程的或其使用序列的被视为正常的尽可能多的不同的执行过程也由经训练的机器学习算法识别或分类为正常。
[0097]
在根据本发明的第二方面的方法中,不创建自举数据集并且直接从训练数据集中创建第二数量k个过程树。然而,为了保证产生的过程树中的随机性,在借助过程挖掘算法创建过程树时,在每个算子节点中随机选择可能的分裂算子中的一个分裂算子。替代在每个分裂节点中确定性地选择分裂算子(例如首先检验xor是否可能,如果是,则选择xor,如果否,则检验seq是否可能,如果是,则选择seq,如果否,则检验par是否可能,如果是,则选择par,如果否,则检验loop是否可能,如果是,则选择loop),对于每个算子节点首先确定,分裂算子中的哪些分裂算子是可能的,并且从所述分裂算子中随机选择可能的分裂算子中的一个分裂算子。
[0098]
通过在k个过程树中的每个过程树的每个算子节点中随机选择可能的分裂算子中的一个分裂算子,将随机性引入到所创建的过程树中、即所创建的过程模型中。这确保,尽管训练使用序列的数量n有限,但是过程的或其使用序列的被视为正常的尽可能多的不同的执行过程也由经训练的机器学习算法识别或分类为正常。
[0099]
如上文中描述的那样被训练成探测过程中的异常的完成训练的机器学习算法(“随机过程森林(英文:random process forest)”)具有k个不相关的过程树、即不同的过程模型。如果向经训练的机器学习算法输送使用序列作为输入,则所述机器学习算法检验,所述机器学习算法的过程树中的哪些过程树可以创建所输送的使用序列,换言之,所输送的使用序列匹配于哪些过程树。经训练的机器学习算法创建对应的预测矢量作为输出,所述预测矢量包括用于过程树中的每个过程树的各一个二进制值,其中如果过程树匹配于所
输送的使用序列,则将一(“1”)输入到对应部位处的预测矢量中,并且如果过程树不匹配于所输送的使用序列,则将零(“0”)输入到对应部位处的预测矢量中。
[0100]
在此,待检验的使用序列可以从(医疗)设备直接发送给数据处理系统,在所述数据处理系统上执行用于探测过程中的异常的方法或经训练的机器学习算法(“随机过程森林(英文:random process forest)”)。替选地,可以首先将使用序列发送给中央系统(例如诊所管理系统),并且由所述中央系统转发给用于探测过程中的异常的数据处理系统。
[0101]
基于预测矢量和第二数量k个过程树,为所输送的使用序列计算归一化适合度值。为此,将预测矢量的二进制值相加,并且随后除以第二数量k(归一化)。所产生的归一化适合度值是概率值,并且说明,所检验的使用序列来自过程的正常执行的概率有多大,或者所检验的使用序列来自过程的概率有多大:从所述过程的存储的使用序列中创建训练数据集。
[0102]
基于归一化适合度值,过程或所述过程的如下执行可以被分类为“正常的”或“异常的”:使用序列来自所述执行。如果其归一化适合度值大于或等于预定义的极限值,则过程/其执行过程被分类为“正常的”,并且如果其归一化适合度值小于预定义的极限值,则过程/其执行过程被分类为“异常的”并且探测到异常。
[0103]
如果多个使用序列与经训练的机器学习算法(“随机过程森林(英文:random process forest)”)(作为批次)被共同检验,则所检验的使用序列的所产生的预测矢量分别合并成预测矩阵。在此,所检验的使用序列的预测矢量可以绘制为预测矩阵的行或列。随后借助第二数量k对预测矩阵(逐行或逐列)归一化成适合度矢量。适合度矢量对于所检验的使用序列中的每个使用序列包括适合度值。
[0104]
用于探测过程中的异常的机器学习算法(“随机过程森林(英文:random process forest)”)可以根据本发明基于无监督(“unsupervised”)学习基于未标记(“unlabelled”)的训练使用序列来创建或训练。因此,不需要工作耗费和时间耗费地标记使用序列以用于提供训练数据集。
[0105]
根据本发明的一个改进方案,根据本发明的第一方面或第二方面的方法包括以下步骤:
[0106]-提供过程的训练数据集,所述训练数据集包括第一数量n个训练使用序列,其中第一数量n大于一(n》1)。
[0107]-基于训练数据集借助于从训练数据集中随机抽取预定义的第三数量m个使用序列来创建预定义的第二数量k个自举数据集,其中第二数量k大于一(k》1),其中从第一数量n个训练使用序列中进行每次抽取。
[0108]-创建与第二数量k相同数量的过程树,其方式为:基于自举数据集中的一个自举数据集借助于过程挖掘算法来创建每个过程树,其中在每个过程树的每个算子节点中随机选择可能的分裂算子中的一个分裂算子。
[0109]
在训练机器学习算法时,不仅(根据本发明的第一方面)创建自举数据集,而且(根据本发明的第二方面)在每个过程树的每个算子节点中随机选择可能的分裂算子中的一个分裂算子。因此,在训练机器学习算法时,似乎在两个部位处引入随机性。
[0110]
通过组合根据本发明的用于训练的两个方法,借此训练的机器学习算法(“随机过程森林(英文:random process forest)”)可以还更可靠地将使用序列分类为“正常的”或“异常的”,从而还更精确地确定过程中的异常。
[0111]
根据本发明的一个改进方案,过程挖掘算法是归纳挖掘算法。
[0112]
归纳挖掘算法或“基于归纳挖掘直接跟随(inductive miner directly follows based)”(imdfb)算法基于(训练)使用序列创建过程树。为此,首先基于数据集(训练数据集或自举数据集)的使用序列的活动的不同的顺序创建直接跟随图形。直接跟随图形反映不同的活动之间的相关性。如果两个活动中的一个活动直接由另一活动跟随,则在两个不同的活动之间插入指引线。直接跟随图形是用于将使用序列转换成过程树的归纳挖掘算法中的重要的步骤。
[0113]
四个分裂算子中的每个分裂算子提供特定的转换特征,所述转换特征可以在直接跟随图形中观察到。通过将直接跟随图形重复细分成分区,即划分成活动的不重叠的细分,检验四个分裂算子中的一个分裂算子是否可以作为活动的联接存在。例如,xor算子表示直接跟随图形中的多个未连接的活动的适当的联接,而seq算子表示直接跟随图形中的在其间具有定向连接的多个活动的适当联接。相反地,par算子表示用于彼此连接的、但是在直接跟随图形中也具有共同的输出方向的块的适当联接。以类似的方式,loop算子为在直接跟随图形中彼此连接并且具有特定的开始活动和结束活动的多个活动的适当联接,然而,对于所述联接不允许取捷径。因此,过程树可以从直接跟随图形中产生。
[0114]
归纳挖掘算法可以实现从训练数据集或自举数据集中特别有效且鲁棒地创建过程树。
[0115]
根据本发明的一个改进方案,机器学习算法是包括第二数量k个过程树的随机森林算法。
[0116]
借助于用于训练用于探测过程中的异常的机器学习算法的方法创建随机森林算法。随机森林算法包括第二数量k个过程树,所述过程树分别基于训练数据集或各个自举数据集的训练使用序列被创建。与此对应地训练的机器学习算法被称为“随机过程森林(英文:random process forest)”。
[0117]
根据本发明的一个改进方案,第二数量k处于50至200的范围内(50<k<200)。第二数量k优选地等于100(k=100)。
[0118]
为机器学习算法(“随机过程森林(英文:random process forest)”)创建的第二数量k个过程树(从而第二数量k个自举数据集)随着变量的增加相对于最优值收敛。在此,计算耗费同样随着第二数量k的增加而增大。从经验试验中得出,50至200并且尤其100的第二数量k足以在合理的计算耗费的同时对使用序列进行鲁棒分类。
[0119]
根据用于训练用于探测过程中的异常的机器学习算法的方法的一个改进方案,第三数量m等于第一数量n(m=n)。替选地,第三数量m小于第一数量n(m<n)。
[0120]
自举数据集中的使用序列的第三数量m等于训练数据集的使用序列的第一数量n(m=n)。优选地,尤其当训练数据集中的使用序列的第一数量n非常大(n》10,000)时,自举数据集中的使用序列的第三数量m小于训练数据集的使用序列的第一数量n(m《n)。然而,自举数据集中的使用序列的第三数量m始终大于1。
[0121]
通过减小自举数据集中的使用序列的第三数量m,可以明显减小计算耗费和对于训练机器学习算法(“随机过程森林(英文:random process forest)”)所需的时间,然而,其中经训练的机器学习算法将待检验的使用序列可靠地进行分类。因此,如果第三数量m小
于第二数量n,则机器学习算法的计算耗费或训练持续时间减小。
[0122]
根据本发明的一个改进方案,使用序列是医疗设备、尤其医疗成像设备的使用序列。
附图说明
[0123]
本发明的上述特性、特征和优点以及如何实现所述特性、特征和优点的方式和方法结合以下对实施例的描述变得更清晰和更清楚地容易理解,所述实施例结合附图更详细地阐述。
[0124]
附图示出:
[0125]
图1至图3示出根据本发明的第一方面和根据本发明的第二方面的方法的示例性的实施方式;
[0126]
图4示出图3中的方法的另一示图;
[0127]
图5示出直接跟随图形的示意图;
[0128]
图6示出过程树的示意图;
[0129]
图7示出根据本发明的第三方面的数据处理系统的示例性的实施方式;
[0130]
图8示出根据本发明的第五方面的计算机可读的数据载体的示例性的实施方式;
[0131]
图9示出根据本发明的第六方面的方法的示例性的实施方式;
[0132]
图10示出图9中的方法的另一示图;
[0133]
图11示出根据本发明的第七方面的数据处理系统的示例性的实施方式;
[0134]
图12示出根据本发明的第九方面的计算机可读的数据载体的示例性的实施方式;
[0135]
图13示出根据本发明的第十方面的系统的示例性的实施方式;以及
[0136]
图14示出借助经训练的机器学习算法进行实验的图表。
具体实施方式
[0137]
在图1中示意性地示出根据本发明的第一方面的用于训练用于探测过程中的异常的机器学习算法(英文:machine learning algorithm,mla)的计算机实施的方法和根据本发明的第四方面的对应的计算机程序产品的示例性的实施方式。所述方法包括如下步骤:提供s1训练数据集td;创建s2预定义的第二数量k个自举数据集bd;以及创建s3a一定数量的过程树pt。
[0138]
在提供s1训练数据集td的步骤中,提供训练数据集td。训练数据集td可以从存储器、例如诊所管理系统的存储器中调用或转发。训练数据集td包括过程的呈使用序列的形式的数据,例如头部的磁共振断层扫描(mrt)检查。使用序列表示在执行过程时实施的活动的所执行的流程。为此,在使用序列中,各个活动以矢量的形式以如下顺序存储,以所述顺序执行所述各个活动。因此,每个使用序列反映过程的(实际进行的)执行。训练数据集包括过程的(实际执行的)执行的第一数量n个训练使用序列,其中第一数量n在1,000和100,000之间(1,000《=n《=100,000)。例如,训练数据集td可以包括过程(头部的mrt检查)的(实际执行的)执行的17,000个训练使用序列(n=17,000)。
[0139]
在创建s2预定义的第二数量k个自举数据集bd的步骤中,创建预定义的第二数量k个自举数据集bd。第二数量k对应于随后应创建的过程树pt的数量。从具有n个训练使用序
列的训练数据集td中通过随机有返还地抽取、也称为自举来依次创建k个自举数据集bd。为此,对于每个自举数据集bd,从训练数据集td中随机抽取第三数量m个训练使用序列,其中将所抽取的每个训练使用序列再次返还到训练数据集td中,从而每次从第一数量n个训练使用序列中进行抽取。因此,各个训练使用序列可以在自举数据集bd中出现多次。自举数据集bd的所抽取的训练使用序列的第三数量m始终大于一且小于或等于训练数据集td的训练使用序列的第一数量n(1《m《=n)。
[0140]
在创建s3a一定数量的过程树pt的步骤中,创建与第二数量k相同数量的过程树pt。过程树pt或自举数据集bd的第二数量k始终大于1(k》1),并且可以优选地大于或等于50且小于或等于200(50《=k《=200)。在此,第二数量k例如可以等于100(k=100)。基于k个自举数据集bd借助于过程挖掘算法、在此例如借助于归纳挖掘算法来创建第二数量k个过程树pt。在此,从k个自举数据集bd中的每个自举数据集中创建恰好一个过程树pt。所创建的过程树pt的整体得出经训练的机器学习算法、称为“随机过程森林(英文:random process forest)”,其中每个过程树表示或模拟过程的可能的流程。
[0141]
通过从通过有返还地随机抽取(自举)而具有一定的随机性的自举数据集bd中创建机器学习算法(“随机过程森林(英文:random process forest)”)的过程树pt,在所创建的过程树pt中同样存在一定的随机性。因此,过程的由过程树pt建模的可能的流程经受一定的随机性。由此解决了训练数据集td的局限性,所述训练数据集仅包括用于训练机器学习算法(“随机过程森林(英文:random process forest)”)的过程的有限数量的不同流程(通过n个训练使用序列)。在此,在提供训练数据集td时,不需要对使用序列进行耗费的标记(“labelling”),因为机器学习算法(“随机过程森林(英文:random process forest)”)被无监督(“unsupervised”)地训练。借助经训练的机器学习算法(“随机过程森林(英文:random process forest)”),可以将过程的使用序列可靠且鲁棒地分类为“正常的”或“异常的”。
[0142]
在图2中示意性地示出根据本发明的第二方面的用于训练用于探测过程中的异常的机器学习算法(英文:machine learning algorithm,mla)的计算机实施的方法和根据本发明的第四方面的对应的计算机程序产品的示例性的实施方式。所述方法为对于根据本发明的第一方面和如图1中所示的方法的替选方案,并且所述方法具有与后者的一些共同点。因此,在下文中仅示出与根据本发明的第一方面和如图1中所示的方法的不同之处。所述方法包括提供s1训练数据集td和创建s3b第二数量k个过程树pt的步骤。
[0143]
提供s1训练数据集td的步骤对应于根据本发明的第一方面和如图1中所示的方法的提供s1训练数据集td的步骤。
[0144]
与根据本发明的第一方面和如图1中所示的方法相比,所述方法不包括创建s2预定义的第二数量k个自举数据集bd的步骤,即不包括训练数据集td的自举(bootstrapping)。
[0145]
在创建s3b第二数量k个过程树pt的步骤中,创建第二数量k个过程树pt。过程树pt的第二数量k始终大于1(k》1),并且可以优选地大于或等于50且小于或等于200(50《=k《=200)。在此,第二数量k例如可以等于100(k=100)。基于训练数据集td借助于过程挖掘算法、在此例如借助于归纳挖掘算法来创建第二数量k个过程树pt。在此,分别从(一个)训练数据集td中创建所有过程树pt。在此,在每个过程树pt的每个算子节点中随机选择分别可
能的分裂算子中的一个分裂算子。因此,在创建每个过程树pt时在其每个算子节点中首先确定,在相应的算子节点中四个分裂算子xor算子、seq算子、par算子和loop算子中的哪些分裂算子是可能的,并且随后选择在相应的算子节点中可能的分裂算子中的一个分裂算子。所创建的过程树pt的整体得出经训练的机器学习算法、称为“random process forest”,其中每个过程树表示或建模过程的可能的流程。
[0146]
通过借助于在过程树pt的每个算子节点中随机选择分别可能的分裂算子中的一个分裂算子来创建机器学习算法(“随机过程森林(英文:random process forest)”)的过程树pt,在所创建的过程树pt中存在一定的随机性。因此,过程的由过程树pt建模的可能的流程经受一定的随机性。由此解决训练数据集td的局限性,所述训练数据集仅包括用于训练机器学习算法(“随机过程森林(英文:random process forest)”)的过程的有限数量的不同流程(通过n个训练使用序列)。在此,在提供训练数据集td时,不需要对使用序列进行耗费的标记(“labelling”),因为机器学习算法(“随机过程森林(英文:random process forest)”)被无监督(“unsupervised”)地训练。借助经训练的机器学习算法(“随机过程森林(英文:random process forest)”),可以将过程的使用序列可靠且鲁棒地分类为“正常的”或“异常的”。
[0147]
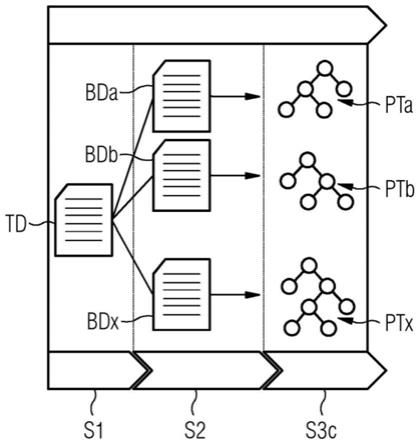
在图3中示意性地示出根据本发明的第一方面或第二方面的用于训练用于探测过程中的异常的机器学习算法(英文:machine learning algorithm,mla)的计算机实施的方法的和根据本发明的第四方面的对应的计算机程序产品的改进方案的示例性的实施方式。所述方法表示根据本发明的第一方面和第二方面和如图1至图2中所示的方法的组合。因此,在下文中仅示出与根据本发明的第一方面或第二方面和如图1或图2中所示的方法的不同之处。所述方法包括如下步骤:提供s1训练数据集td、创建s2预定义的第二数量k个自举数据集bd和创建s3c第二数量k个过程树pt。提供s1训练数据集td和确定预定义的第二数量k个自举数据集bd的步骤对应于根据本发明的第一方面和如图1中所示的方法的所述步骤。
[0148]
在创建s3c第二数量k个过程树pt的步骤中,创建与第二数量k相同数量的过程树pt,所述步骤是步骤s3a和s3b的组合。基于k个自举数据集bd借助于过程挖掘算法、在此例如借助于归纳挖掘算法来创建第二数量k个过程树pt。在此,从k个自举数据集bd中的每个自举数据集中创建恰好一个过程树pt。此外,在每个过程树pt的每个算子节点中随机选择分别可能的分裂算子中的一个分裂算子。因此,在创建每个过程树pt时在其每个算子节点中首先确定,在相应的算子节点中四个分裂算子xor算子、seq算子、par算子和loop算子中的哪些分裂算子中是可能的,并且随后选择在相应的算子节点中可能的分裂算子中的一个分裂算子。所创建的过程树pt的整体得出经训练的机器学习算法、称为“random process forest”,其中每个过程树表示或建模过程的可能的流程。所创建的过程树pt的整体得出经训练的机器学习算法、称为“random process forest”,其中每个过程树表示或建模过程的可能的流程。
[0149]
通过从通过有返还地随机抽取(自举)而具有一定的随机性的自举数据集bd中创建机器学习算法(“随机过程森林(英文:random process forest)”)的过程树pt,在所创建的过程树pt中同样存在一定的随机性。此外,通过借助于在过程树pt的每个算子节点中随机选择分别可能的分裂算子中的一个分裂算子来创建机器学习算法(“随机过程森林(英文:random process forest)”)的过程树pt,在所创建的过程树pt中引入另一随机性。因
此,过程的由过程树pt建模的可能的流程经受“组合的”随机性。由此解决训练数据集td的局限性,所述训练数据集仅包括用于训练机器学习算法(“随机过程森林(英文:random process forest)”)的过程的有限数量的不同流程(通过n个训练使用序列)。在此,在提供训练数据集td时,不需要对使用序列进行耗费的标记(“labelling”),因为机器学习算法(“随机过程森林(英文:random process forest)”)被无监督(“unsupervised”)地训练。借助经训练的机器学习算法(“随机过程森林(英文:random process forest)”),可以将过程的使用序列可靠且鲁棒地分类为“正常的”或“异常的”。
[0150]
在图4中再次示意性地示出图3中的方法。在步骤s2中,通过有返还地随机抽取(自举)从在步骤s1中提供的具有n个训练使用序列的(一个)训练数据集td中创建分别包括m个使用序列的k个自举数据集bd。在此,第三数量m例如可以等于第一数量n。随后在步骤s3c中,借助于过程挖掘算法、尤其借助于归纳挖掘算法从k个自举数据集bd中的每个自举数据集中创建“随机过程森林(英文:random process forest)”的恰好一个过程树pta,ptb,
…
,tpx。“随机过程森林(英文:random process forest)”的k个不相关的过程树pta,ptb,
…
,tpx中的每个过程树对过程的分别具有流程中的一定的随机性的可能的流程、即k个不同的流程建模。因此,通过无监督(“unsupervised”)学习训练的“随机过程森林(英文:random process forest)”包括k个不相关的过程树pta,ptb,
…
,tpx,所述过程树通过上文中描述的自举和随机选择可能的分裂算子而具有一定的“组合的”随机性,由此解决训练数据集td的局限性。因此,借助经训练的“随机过程森林(英文:random process forest)”,过程的使用序列可以可靠且鲁棒地分类为“正常的”或“异常的”。
[0151]
在图5中示意性地示出直接跟随图形dfg,所述直接跟随图形借助于归纳挖掘直接跟随算法的第一步骤从数据集(训练数据集td或自举数据集bd中的一个自举数据集)中创建。
[0152]
在此,四个(n=4)使用序列{三次《a,b,d,e》;《a,d,b,e》;《a,d,c,e》;《a,c,d,e》}示例性地包括在数据集td、bd中。使用序列中的每个使用序列包括活动a、b、c、d和e的呈矢量形式的顺序。从数据集td、bd中创建直接跟随图形dfg。跟随活动a的始终是活动b、c和d的组合,并且随后是活动e。附加地,在直接跟随图形dfg中在活动之间的连接(指引线)处频率可以作为数值给出。
[0153]
在图6中示意性地示出过程树pt,所述过程树借助于归纳挖掘算法的第二步骤从直接跟随图形dfg、在此图5中的直接跟随图形dfg中创建。
[0154]
数据集td、bd的活动b、c和d仅可以如在直接跟随图形dfg中所示的那样顺序地跟随活动a。活动e似乎仅可以顺序地跟随活动b、c和d。因此,具有活动a的活动节点经由具有分裂算子seq(
→
)的算子节点与具有活动e的活动节点连接。因为由活动b、c和d构成的组合在顺序的活动a与e之间进行,所以具有分裂算子seq(
→
)的算子节点与具有分裂算子par(+)的算子节点连接,所述具有分裂算子par(+)的算子节点将具有活动d的活动节点与如下算子节点连接:所述算子节点将具有活动b和c的两个活动节点连接。具有活动d的活动节点经由具有分裂算子par(+)的算子节点与如下算子节点连接:所述算子节点将具有活动b和c的两个活动节点连接,因为活动d不仅可以在活动b和活动c之前进行,而且也可以跟随在活动b和活动c之后,从而与之并行进行。具有活动b的活动节点经由具有分裂算子xor(x)的算子节点与具有活动c的活动节点连接,因为活动b或活动c要么在活动d之前进行,要么跟随
在活动d之后,即与所述活动d并行进行。
[0155]
如果四个分裂算子中的多个分裂算子在算子节点中是可能的,则在传统的归纳挖掘算法中(例如在根据本发明的第一方面的方法中),预设的顺序xor、seq、par、loop在第一可能的分裂算子之后被分配给相应的算子节点(“greedy”)。在根据本发明的第二方面的改变的归纳挖掘算法中,在算子节点中可能的分裂算子中的一个分裂算子被随机分配(例如,如果在算子节点中,xor或par是可能的,则随机选择两个可能的分裂算子中的一个分裂算子)。
[0156]
在图7中示意性地示出根据本发明的第三方面的数据处理系统10的示例性的实施方式。数据处理系统10可以执行根据本发明的第一方面或第二方面和如图1至图3中所示的方法的步骤s1、步骤s2和步骤s3a、s3b或s3c中的一个步骤。
[0157]
数据处理系统10可以是个人计算机(pc)、笔记本电脑、平板电脑、服务器、分布式系统(例如云系统)等。数据处理系统10包括中央计算单元(central processing unit,cpu)11、具有随机存取存储器(ram)12和非易失性存储器(mem,例如硬盘)13的存储器、人机界面(human interface device,hid,例如键盘、鼠标、触摸屏等)14、输出设备(mon,例如监视器、打印机、扬声器等)15和用于接收和发送数据的接口(输入/输出、i/o,例如usb、蓝牙、wlan等)16。cpu 11、ram 12、hid 14、mon 15和i/o 16经由数据总线通信连接。ram 12和mem 13经由另一数据总线通信连接。
[0158]
根据本发明的第四方面的可以存储在计算机可读介质20(参见图8)上的计算机程序产品可以存储在mem 13中,并且可以从所述mem或计算机可读介质20加载到ram 12中。根据所述计算机程序产品,cpu 11执行步骤s1、步骤s2以及步骤s3a、s3b或s3c中的一个步骤。所述执行可以通过用户(救援控制中心的人员)经由hid 14初始化和控制。所执行的计算机程序的状态和结果可以通过mon 15显示给用户或经由i/o 16转发给用户。所执行的计算机程序的结果可以永久地存储在非易失性mem 13或另一计算机可读介质上。
[0159]
尤其地,用于执行计算机程序的cpu 11和ram 12可以包括多个cpu 11和多个ram 12、例如计算集群或云系统中的多个cpu和多个ram。用于控制计算机程序的执行的hid 14和mon 15可以由与数据处理系统10(例如云系统)通信连接的另一数据处理系统、如终端包括。
[0160]
在图8中示意性地示出计算机可读的数据载体20的示例性的实施方式。在此,根据本发明的第四方面的计算机程序产品示例性地存储在计算机可读的存储盘20上,如压缩光盘(cd)、数字视频光盘(dvd)、高清dvd(hd dvd)或蓝光光盘(bd)上,所述计算机程序产品包括指令,当所述指令由数据处理系统(计算机)执行时,所述指令促使数据处理系统执行步骤s1、步骤s2和步骤s3a、s3b或s3c中的一个步骤。
[0161]
然而,计算机可读的数据载体20也可以是数据存储器,如磁存储器(例如磁芯存储器、磁带、磁卡、磁条、磁泡存储器、滚轮存储器、硬盘、软盘或可替换存储器)、光学存储器(例如全息存储器、光学带、透明胶带、激光光盘、相变光存储(phasewriter dual,pd)或超密度光盘(udo))、磁光学存储器(例如小型光盘或磁光盘(mo disk))、易失性半导体/固态存储器(例如随机存取存储器(ram)、动态ram(dram)或静态ram(sram))或非易失性半导体/固态存储器(例如只读存储器(rom)、可编程rom(prom)、可擦除prom(eprom)、电eprom(eeprom)、闪存eeprom(例如usb记忆棒)、铁电ram(fram)、磁阻ram(mram)或相变ram)。
[0162]
在图9中示意性地示出根据本发明的第六方面的用于探测过程中的异常的计算机实施的方法、尤其用于探测借助医疗设备的过程中的异常的计算机实施的方法的示例性的实施方式。所述方法包括如下步骤:接收s10使用序列、确定s20预测矢量pv、确定s30归一化适合度值fv以及对过程进行分类s40。
[0163]
在接收s10使用序列的步骤中,接收过程或过程的执行的使用序列。也可以接收多个过程/过程执行的多个使用序列。
[0164]
在确定s20预测矢量pv的步骤中,基于接收到的一个或多个使用序列借助于经训练的机器学习算法(“随机过程森林(英文:random process forest)”)来确定预测矢量pv或预测矩阵pm,所述经训练的机器学习算法借助于根据第一方面或第二方面和如图1至图3中所示的方法被训练。对于经训练的机器学习算法(“随机过程森林(英文:random process forest)”)的每个过程树pt,所确定的预测矢量pv或所确定的预测矩阵pm包括如下值:所述值说明,使用序列或使用序列中的相应的使用序列是否匹配于相应的过程树pt。因此,如果接收到的使用序列/接收到的使用序列中的相应的使用序列可以来自通过相应的过程树pt建模的过程,则将预测矢量pv/预测矩阵pm的对应的值置为等于一(“1"),并且如果不是这种情况,则置为等于零("0")。
[0165]
在确定s30归一化适合度值fv的步骤中,从所确定的预测矢量pv或所确定的预测矩阵pm和第二数量k确定归一化适合度值fval或归一化适合度矢量fv。为此,将预测矢量pv或预测矩阵的属于接收到的使用序列/接收到的使用序列的相应的使用序列的各个值相加并除以过程树pt的第二数量k。归一化适合度值pval或归一化适合度矢量pv的归一化适合度值对应于各一个概率。所述概率说明,对应的使用序列来自过程的概率有多大,其中值一(pval=1)对应于100%[百分比]的概率,并且值零(pval=0)对应于0%的概率。
[0166]
在对过程进行分类s40的步骤中,基于归一化适合度值fval对过程或过程执行进行分类。在此,过程或其执行在如下情况下被分类为“正常的”:即当其归一化适合度值fval大于或等于0.5(pval》=0.5)、优选地大于或等于0.66(pval》=0.66)、特别优选地大于或等于0.75(pval》=0.75)。否则过程或所述过程的执行被分类为“异常的”从而探测到异常。
[0167]
在图10中再次示意性地示出图9中的方法。在步骤s20中,借助于经训练的“随机过程森林(英文:random process forest)”从过程的多个执行过程的在步骤s10中接收到的多个使用序列中为接收到的使用序列中的每个使用序列确定呈预测矩阵pm的形式的对应的预测矢量pv。对于每个使用序列,将相应的预测矢量pv的如下各个值相加:所述值说明,相应的使用序列是否匹配于经训练的“随机过程森林(英文:random process forest)”的k个过程树pt中的相应的过程树。随后在步骤s30中将相加的值除以经训练的“随机过程森林(英文:random process forest)”的过程树pt的第二数量k,以便确定使用序列的相应的适合度值pval,其中将使用序列的各个适合度值pval在适合度矢量fv中总结。然后,基于说明相应的使用数据来自过程的概率的各个适合度值pval,相应的过程或所述过程的相应的执行可以在此处未示出的步骤s40中被分类为“正常的”或“异常的”。
[0168]
在图11中示意性地示出根据本发明的第七方面的数据处理系统30的示例性的实施方式。数据处理系统30可以执行根据本发明的第六方面和如图10中所示的方法的步骤s10、步骤s20、步骤s30和步骤s40。
[0169]
数据处理系统30可以是个人计算机(pc)、笔记本电脑、平板电脑、服务器、分布式
系统(例如云系统)等。数据处理系统30包括中央计算单元(英文:central processing unit,cpu)31、具有随机存取存储器(ram)32和非易失性存储器(mem,例如硬盘)33的存储器、人机界面(英文:human interface device,hid,例如键盘、鼠标、触摸屏等)34、输出设备(mon,例如监视器、打印机、扬声器等)35和用于接收和发送数据的接口(输入/输出、i/o,例如usb、蓝牙、wlan等)36。cpu 31、ram 32、hid 34、mon 35和i/o 36经由数据总线通信连接。ram 32和mem 313经由另一数据总线通信连接。
[0170]
根据本发明的第八方面的可以存储在计算机可读介质40(参见图12)上的计算机程序产品可以存储在mem 33中,并且可以从所述mem或计算机可读介质40加载到ram 32中。根据所述计算机程序产品,cpu 31执行步骤s10、步骤s20、步骤s30及步骤s40。所述执行可以通过用户(救援控制中心的人员)经由hid 34初始化和控制。所执行的计算机程序的状态和结果可以通过mon 35显示给用户或经由i/o 36转发给用户。所执行的计算机程序的结果可以永久地存储在非易失性mem 33或另一计算机可读介质上。
[0171]
尤其地,用于执行计算机程序的cpu 31和ram 32可以包括多个cpu 31和多个ram 32、例如计算集群或云系统中的多个cpu和多个ram。用于控制计算机程序的执行的hid 34和mon 35可以由与数据处理系统30(例如云系统)通信连接的另一数据处理系统、如终端包括。
[0172]
在图12中示意性地示出计算机可读的数据载体40的示例性的实施方式。在此,根据本发明的第八方面的计算机程序产品示例性地存储在计算机可读的存储盘40,如压缩光盘(cd)、数字视频光盘(dvd)、高清dvd(hd dvd)或蓝光光盘(bd)上,所述计算机程序产品包括指令,当所述指令由数据处理系统(计算机)执行时,所述指令促使数据处理系统执行步骤s10、步骤s20、步骤s30和步骤s40。
[0173]
然而,计算机可读的数据载体40也可以是数据存储器,如磁存储器(例如磁芯存储器、磁带、磁卡、磁条、磁泡存储器、滚轮存储器、硬盘、软盘或可替换存储器)、光学存储器(例如全息存储器、光学带、透明胶带、激光光盘、相变光存储(phasewriter dual,pd)或超密度光盘(udo))、磁光学存储器(例如小型光盘或磁光盘(mo disk))、易失性半导体/固态存储器(例如随机存取存储器(ram)、动态ram(dram)或静态ram(sram))或非易失性半导体/固态存储器(例如只读存储器(rom)、可编程rom(prom)、可擦除prom(eprom)、电eprom(eeprom)、闪存eeprom(例如usb记忆棒)、铁电ram(fram)、磁阻ram(mram)或相变ram)。
[0174]
在图13中示意性地示出根据本发明的第十方面的用于探测过程中的异常的系统50的示例性的实施方式。系统50包括医疗设备51和根据本发明的第七方面和如图11中所示的数据处理系统30。
[0175]
医疗设备51可以是医疗成像设备、尤其mrt设备。医疗设备51构成用于记录关于过程或所述过程的执行的使用序列。
[0176]
数据处理系统30借助于i/o 36(可能间接地经由中央系统,如诊所管理系统)与医疗设备51或医疗设备51的控制设备通信连接。
[0177]
数据处理系统30从医疗设备51(间接地)接收使用序列并且为了探测异常执行根据本发明的第六方面和如图10中所示的方法。
[0178]
在图14中示出用于借助经训练的机器学习算法的实验的图表。已训练了六个机器学习算法(“随机过程森林(英文:random process forest)”)rpf1、rpf5、rpf20、rpf50、
rpf100和rpf200,其中rpf1具有第二数量k为1(k=1)的过程树pt,rpf5具有第二数量k为5(k=5)的过程树pt,rpf20具有第二数量k为20(k=20)的过程树pt,rpf50具有第二数量k为50(k=50)的过程树pt,rpf100具有第二数量k为100(k=100)的过程树pt,以及rpf200具有第二数量k为200(k=200)的过程树pt。所有六个机器学习算法(“随机过程森林(英文:random process forest)”)借助所观察的过程(例如膝盖的mrt检查)的相同的训练数据集td根据图3和图4中的方法被训练。
[0179]
在横坐标上绘制过程树的第二数量k(整体尺寸),并且在纵坐标上绘制六个机器学习算法(“随机过程森林(英文:random process forest)”)的性能结果(“performance”)。已经证实,rpf50、rpf100和rpf200的性能彼此接近,从而在50至200之间的第二数量k(50《=k《=200)是优选的。还已经证实,rpf100的在对过程的执行的使用序列进行分类时的性能仅比rpf200的在对过程的执行的使用序列进行分类时的性能稍差。然而,因为在借助rpf200训练和分类时的计算耗费从而持续时间明显高于在rpf100的情况下,所以第二数量k等于100(k=100)是特别优选的。
[0180]
尽管在此已经图解说明和描述了特定的实施方式,但是对于本领域技术人员显然的是,存在多个替选方案和/或等效的实现方案。应理解,示例性的设计方案或实施方式仅是实例并且不旨在以任何方式限制范围、可用性或配置。更确切地说,以上概述和详细的描述为本领域技术人员提供用于实现至少一个优选的实施方式的充分说明,其中应理解,在示例性的设计方案中描述的元件的功能和设置的不同的变化不超出所附权利要求及其合法等效方案中所示的应用范围。通常,本技术旨在涵盖在此讨论的特定实施方式的所有调整方案或变型方案。
[0181]
在上文的详细描述中,不同的特征在一个或多个实例中总结,以便保持公开简洁。应理解,以上描述应是说明性的,并且不应是限制性的。所述描述应涵盖可以包含在本发明的范围内的所有替选方案、变型方案和等效方案。在研究上述公开时,多个其他实例对于本领域技术人员是明显的。
[0182]
为了可以实现对本发明的广泛的理解,使用在上述公开中使用的特定术语。然而,鉴于其中包含的说明书对于本领域技术人员明显的是,不需要应用本发明的具体细节。因此,本发明的特定实施方式的上述描述出于说明和描述的目的示出。所述描述不旨在详尽的或将本发明限制于上文中公开的精确的实施方式;显然,关于上述教导,多个修改方案和变型方案是可行的。选择和描述实施方式,以便最好地解释本发明的原理及其实际应用,从而以便向其他专家提供最好地应用本发明和具有不同的修改方案和显现适合用于相应的用途的不同的实施方式的可能性。在整个说明书中,术语“包含”和“其中”用作为相应的术语“包括”或“在其中”的等价物。此外,术语“第一”、“第二”、“第三”等仅用作为名称,并且不旨在对对象提出数字要求或预设特定优先次序。结合本说明书和权利要求,连接词“或”应理解为接纳(“和/或”),而不应理解为排他(“要么
……
要么”)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1