用于训练脸部辨识的深度学习网络的方法和装置与流程
1.本公开关于机器学习,尤指一种基于知识蒸馏技巧,从而实现具备脸部对齐效果的脸部辨识网络模型的训练方法与相关装置。
背景技术:
2.现今的脸部辨识算法主要针对脸部图像进行身份识别。为了让脸部辨识的深度学习网络,尽量得到相同环境下的脸部图像,一般会在脸部辨识网络模型之前,加上脸部坐标检测器(landmark detector),此检测器可基于脸部重要特征(如:眼耳口鼻等)的坐标,进行脸部对齐(face alignment)处理。如图1所示的架构,来源图像会先经过脸部检测器10,脸部检测器10会从来源图像中找出脸部图形,并将其从来源图像中撷取出来。接着,撷取出的脸部图形会被输入至脸部坐标检测器20,脸部坐标检测器20会对脸部图形进行脸部对齐。其中,脸部坐标检测器20依据脸部重要特征的坐标,对脸部图形进行平移、缩放、或者是二维/三维旋转等几何处理。经过脸部对齐处理后的图像,才会被输入脸部辨识网络模型30,进行脸部辨识。脸部对齐的目的在于避免图形歪斜或比例错误等问题,对脸部辨识网络模型30造成负面影响,进而提升辨识正确率。然而,若要实现脸部坐标检测器20,则需要从系统中配置运算资源来进行:脸部五官坐标的深度学习模型的运算、基于五官坐标计算脸部图形需要进行多少角度的旋转、以及利用计算出的角度对图像进行旋转等操作。对于运算资源相对有限的嵌入式平台来说,额外加上模块来实现脸部对齐会让系统的整体运算效率显著降低。
3.公开内容
4.有鉴于此,本公开的目的在于提供一种脸部辨识的深度学习网络模型的训练方法。通过本公开的训练方法,可以省略脸部辨识算法中,对于脸部对齐处理的需求。其中,本公开采用知识蒸馏(knowledge distillation),利用已经对齐处理后的脸部图像,预先训练一教师模型(teacher model)。接着,再利用已经训练完成的教师模型以及未经对齐处理的脸部图像,训练一学生模型(student model)。由于采用未经脸部对齐处理的脸部图像进行训练,所以提升了学生模型对于角度歪斜或者是比例错误的脸部图像的适应能力。后续在运用学生模型进行脸部辨识时,便可在省略已知架构中的脸部坐标检测器(landmark detector)前提下,实现同等良好的识别能力。
5.本公开的一实施例提供一种用于训练一脸部辨识的深度学习网络的方法,该方法包括:使用一脸部坐标检测器(landmark detector)对至少一个撷取图像进行脸部对齐处理,从而输出至少一个对齐图像;将该至少一个对齐图像输入一教师模型,以获得一第一输出向量;将该至少一个撷取图像输入对应于该教师模型的一学生模型,以获得一第二输出向量;以及依据该第一输出向量与该第二输出向量,调整该学生模型的参数设定。
6.本公开的一实施例提供一种用于训练一脸部辨识的深度学习网络的装置,该装置包括:一存储单元以及一处理单元。该存储单元用以存储一程序代码。该处理单元用以执行该程序代码,以至于该处理单元得以执行以下操作:对至少一个撷取图像进行脸部对齐处
理,从而输出至少一个对齐图像;将该至少一个对齐图像输入一教师模型,以获得一第一输出向量;将该至少一个撷取图像输入对应于该教师模型的一学生模型,以获得一第二输出向量;以及依据该第一输出向量与该第二输出向量,调整该学生模型的参数设定。
附图说明
7.图1示出已知脸部辨识的深度学习网络的简略架构。
8.图2示出在本公开实施例中如何运用经过脸部对齐处理后的图像训练教师模型。
9.图3示出在本公开实施例中如何运用训练完成的教师模型以及未经脸部对齐处理的图像训练学生模型。
10.图4示出本公开实施例的训练脸部辨识的深度学习网络的方法。
11.图5示出本公开实施例的训练脸部辨识的深度学习网络的装置。
具体实施方式
12.在以下描述中,描述了许多具体细节以提供阅读者对本公开实施例的透彻理解。然而,本领域技术人员将能理解,如何在缺少一个或多个具体细节的情况下,或者利用其他方法或组件或材料等来实现本公开。在其他情况下,众所周知的结构、材料或操作不会被示出或详细描述,从而避免模糊本公开的核心概念。
13.说明书中提到的“一实施例”意味着该实施例所描述的特定特征、结构或特性可能被包括在本公开的至少一个实施例中。因此,本说明书中各处出现的“在一实施例中”不一定意味着同一个实施例。此外,前述的特定特征、结构或特性可以以任何合适的形式在一个或多个实施例中结合。
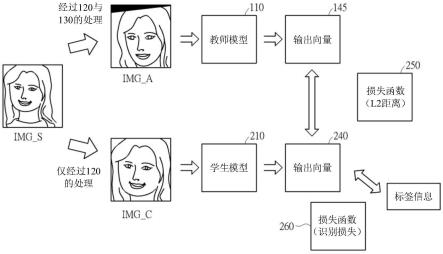
14.请参考图2与图3,这些图示出本公开实施例如何利用知识蒸馏技巧,训练用于进行脸部辨识的深度学习网络。其中,由本公开训练后的脸部辨识的深度学习网络可以用于进行身份识别,其可根据一输入脸部图像产生一维的输出向量,并且将该输出向量与数据库中所有已注册的向量进行比对。当该输出向量与某个已注册向量之间的l2距离小于预设的临界值时,便可认定该输入脸部图像相符于该已注册向量所关联的身份。
15.如图2所示,本公开实施例会先对教师模型(teacher model)110进行训练。在训练的过程中,一个或多个来源图像img_s会被输入至脸部检测器120,脸部检测器120会从来源图像img_s中找到包括有人脸特征的部分,将其撷取后,输出撷取图像img_c至脸部坐标检测器130。脸部坐标检测器130会识别撷取图像img_c中,关于脸部的重要特征(如:眼耳口鼻等)的坐标,并且视需求进行脸部对齐。例如,当撷取图像img_c中的脸部图形存在角度歪斜或者比例不正确等问题时,脸部坐标检测器130会对撷取图像img_c进行平移、缩放、或者是二维/三维旋转等几何处理。据此,脸部坐标检测器130将经过脸部对齐处理后的对齐图像img_a输入至教师模型110。当对齐图像img_a输入至教师模型110之后,教师模型110会产生一输出向量140。输出向量140会与相对应于来源图像img_s的标签(label)信息(即,来源图像img_s实质上所对应的身份类别)进行比较,从而产生一损失函数150(即,识别损失(identification loss))。而教师模型110的参数设定会根据当前的损失函数150而被调整,从而实现对教师模型110的训练。在使用大量不同的来源图像img_s训练教师模型110,使得损失函数150低于一预定值后,便可完成教师模型110的训练。接着,基于知识蒸馏
(knowledge distillation)的技巧,从训练完成的教师模型110提取出一个简化的学生模型(student model)210。相较于教师模型110,学生模型210的结构较为精简且运算复杂度低,对于系统整体运算资源的占用比例也低。由于学生模型210是从教师模型110所蒸馏而出,其具有实质上近似教师模型110的识别能力。
16.请参考图3,该图示出本公开如何训练学生模型。其中,脸部检测器120撷取从一个或多个来源图像img_s提取脸部图形,从而产生撷取图像img_c。撷取图像img_c会在未经脸部对齐处理的情况下,直接被输入至学生模型210。学生模型210会根据撷取图像img_c产生一输出向量240。与此同时,撷取图像img_c也会经过脸部坐标检测器130的对齐处理后,产生对齐图像img_a。而对齐图像img_a则被输入至教师模型110,从而产生相应的输出向量145。基于输出向量145与输出向量240的差异(如:l2距离),可获得相应的损失函数250。根据损失函数250,可以调整学生模型210的参数设定。另一方面,输出向量240还会与相关联于来源图像img_s的标签信息进行比较。基于两者的差异(如:识别损失),将产生另一个损失函数260。根据损失函数260,也可以调整学生模型210的参数。通过损失函数250与260,可以实现对学生模型210的训练。当使用大量不同的来源图像img_s训练学生模型210,使得损失函数250与260低于个别的预定值后,便可完成学生模型210的训练。请注意,在训练学生模型210的过程中,教师模型110仅作为推论(inference only),其参数设定在此期间不会被调整。
17.图4示出了本公开实施例的训练脸部辨识的深度学习网络的方法。如图所示,本公开的训练方法包括以下的简化流程:
18.s310:使用一脸部坐标检测器对至少一个撷取图像进行脸部对齐处理,从而输出至少一个对齐图像;
19.s320:将该至少一个对齐图像输入一教师模型,以获得一第一输出向量;将该至少一个撷取图像输入对应于该教师模型的一学生模型,以获得一第二输出向量;以及
20.s330:依据该第一输出向量与该第二输出向量,调整该学生模型的参数设定。
21.由于上述步骤的原理以及具体细节已于先前实施例中详细说明,故在此不进行重复描述。应当注意的是,上述的流程可能可以通过添加其他额外步骤或者是进行适当的变化与调整,更好地实现对脸部辨识网络模型的训练,更进一步提升其识别能力。再者,前述本公开实施例中所有的操作,都可以通过图5所示的装置400来实现。其中,装置400中的存储单元410可用于存储程序代码、指令、变量或数据。而装置400中的硬件处理单元420则可执行存储单元410所存储的程序代码与指令,并参考其中的变量或数据来执行前述实施例中所有的操作。
22.总结来说,本公开提供了一种脸部辨识的深度学习网络模型的训练方法。通过本公开的训练方法,可以省略脸部辨识算法中,对于脸部对齐处理的需求。其中,本公开利用已经过脸部对齐处理的脸部图像,预先训练教师模型。接着,再利用已经训练完成的教师模型以及未经脸部对齐处理的脸部图像,训练一学生模型。由于采用未经脸部对齐处理的脸部图像进行训练,因此提升了学生模型对于角度歪斜或者是比例错误的脸部图像的适应能力。后续在学生模型进行脸部辨识时,便可在省略已知架构中的脸部坐标检测器的前提下,达成同样良好的识别能力。如此一来,本公开有效地降低了脸部辨识网络模型对于系统运算资源的占用比例。
23.本公开的实施例可使用硬件、软件、固件以及其相关结合来完成。藉由适当的一指令执行系统,可使用存储于一内存中的软件或固件来实现本公开的实施例。就硬件而言,则是可应用下列任一技术或其相关结合来完成:具有可根据数据信号执行逻辑功能的逻辑门的一个别运算逻辑、具有合适的组合逻辑门的一特定应用集成电路(application specific integrated circuit,asic)、可程序门阵列(programmable gate array,pga)或一现场可程序门阵列(field programmable gate array,fpga)等。
24.说明书内的流程图中的流程和方块示出了基于本公开的各种实施例的系统、方法和计算机软件产品所能实现的架构,功能和操作。在这方面,流程图或功能方块图中的每个方块可以代表程序代码的模块,区段或者是部分,其包括用于实现指定的逻辑功能的一个或多个可执行指令。另外,功能方块图以及/或流程图中的每个方块,以及方块的组合,基本上可以由执行指定功能或动作的专用硬件系统来实现,或专用硬件和计算机程序指令的组合来实现。这些计算机程序指令还可以存储在计算机可读媒体中,该媒体可以使计算机或其他可编程数据处理装置以特定方式工作,使得存储在计算机可读媒体中的指令,实现流程图以及/或功能方块图中的方块所指定的功能/动作。
25.以上所述仅为本公开的较佳实施例,凡依本公开权利要求所做的均等变化与修饰,皆应属本公开的涵盖范围。
26.【符号说明】
27.10、120:脸部检测器
28.20、130:脸部坐标检测器
29.30:脸部辨识网络模型
30.110:教师模型
31.210:学生模型
32.140、145、240:输出向量
33.150、250、260:损失函数
34.img_s:来源图像
35.img_c:撷取图像
36.img_a:对齐图像
37.s310~s330:步骤
38.400:装置
39.410:存储单元
40.420:硬件处理单元。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1