建立复杂运动控制器的方法与流程
1.本发明关于角色的运动控制器,特别是一种在运动数据集以外建立符合物理现象的过渡的架构。
背景技术:
2.具有多样化运动能力的角色运动控制器常用于在动画、电玩游戏和电影的数字特效中。
3.传统上,为了从运动撷取(motion capture)数据合成新的动画,通常会创建一种内插(interpolation)结构,例如运动图(motion graph),其中节点代表由运动撷取数据明确定义的动作(action),连接两个节点的边定义动作之间的过渡(transition)。为了合成新的动画,可以从这个运动图中查找适当的动作。由于它是一种查找机制,因此运动图需要收集尽量多的互动才能发挥作用,所述互动是指角色与其周围环境之间可能的各种互动。然而,这样的运动图变得极为庞大且复杂。即使如此复杂,运动图仍然无法在未见过的场景中合成运动。此外,在运动图中搜索的复杂度限制了控制时的精细度。
4.即使在运动图中加入神经网络,如自回归(auto-regressive)模型、受限玻尔兹曼机(restricted boltzmann machine)、时间卷积(temporal convolution)或循环变异自编码器(recurrent variational auto-encoder)模型,这些方式仍旧难以产生长运动的序列,并且容易将运动平均化,导致角色的运动看起来紧张、僵硬或具有严重的足部滑动,另外,适用于二足动物的方法也无法适用于四足动物。
5.运动学(kinematic)控制器藉由减少在动作之间产生过渡的需求以解决运动图的标签问题,同时允许用户任意控制角色以产生所需的运动。此外,也可以使用基于物理的控制器有效地模拟复杂现象,物理模拟及环境约束能够使角色对外部干扰作出符合物理现象的反应,而无需事先收集这种反应的资料。现有的基于物理的控制器以运动学控制器为基础,并藉由生成对抗网络(generative adversarial networks,gan)保持运动的自然性,允许运动控制器产生符合物理现象且流畅自然的运动。
6.为了增加运动控制器的能力以产生丰富的运动,可以藉由添加新的运动数据来进行训练。然而,每次添加一笔新数据时,控制器都需要重新产生一个庞大的运动控制器的模型。另一种方式是添加新的基于物理的控制器作为模块,并且重新训练用于调制所有模块的门控网络(gating network)的多层感知器(multilayer perceptron,mlp)。然而,即使只增加一个新的模块,训练所有模块的mlp的复杂度仍然以指数成长,并且还要避免加入新模块后的训练影响词汇表中的现有运动。
技术实现要素:
7.有鉴于此,本发明提出一种建立复杂运动控制器的方法,其中包括过渡运动张量(transition motion tensor,后文简称为过渡张量),这是一种数据导向的架构(data-driven framework),可在运动数据集以外建立符合新的过渡。过渡张量保留了单个运动控
制器的稳健性(robustness),并在最合适的阶段切换到目标控制器。
8.依据本发明一实施例的一种建立复杂运动控制器的方法,包括以处理器执行下列步骤:取得一源控制器及一目标控制器,所述源控制器用于产生一源运动,所述目标控制器用于产生一目标运动;决定所述源控制器及所述目标控制器之间的一过渡张量,所述过渡张量具有多个索引,该些索引中的一者对应于所述源运动的多个相位;计算所述过渡张量的多个结果,并依据该些索引记录该些结果;依据该些结果计算多个过渡质量;以及在该些过渡质量中寻找一最佳过渡质量以建立一复杂运动控制器,所述复杂运动控制器用以产生对应于该些相位中的一者的一复杂运动。
9.本发明提出一种建立复杂运动控制器的方法,可在不修改现有运动的情况下有效而稳健地(robustly)建立新运动。给定几个不同的基于物理的运动控制器,本发明提出的过渡张量可作为在运动控制器之间切换的依据。藉由查询过渡张量以获得最佳过渡的方式可以建立一个统一(unified)的复杂运动控制器,所述控制器能够产生包含各种行为的新过渡,例如在角色进行更高的跳跃之前减速或立即跳跃以获得更好的响应。本发明适用于表现四足动物和两足动物的运动,对过渡质量进行定量和定性评估,并在遵循用户控制指令的同时具备处理复杂运动规划的能力。
10.综上所述,本发明具有以下贡献或效果:
11.1.提出一种数据导向的方法,可在运动数据集以外建立符合物理现象且新颖的过渡;
12.2.提出一个可扩展的架构,将基于各种架构或训练过程的现有控制器统合到一个连贯的(coherent)、统一的控制器中,并减少扩展时的训练成本;以及
13.3.提出一种方案,其利用控制器解决复杂运动规划问题,同时满足用户控制指令及物理环境约束。
14.以上的关于本揭露内容的说明及以下的实施方式的说明系用以示范与解释本发明的精神与原理,并且提供本发明的专利申请范围更进一步的解释。
附图说明
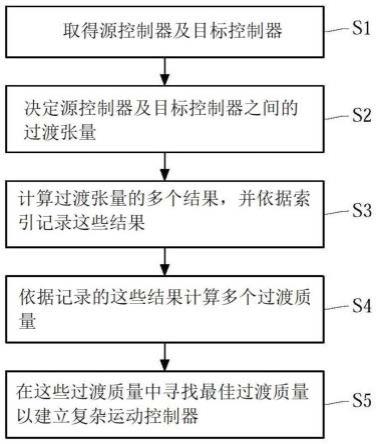
15.图1是本发明一实施例的建立复杂运动控制器的方法的流程图;
16.图2是训练模板控制器的过程中加入外部干扰的示意图;
17.图3是从源运动过渡到目标运动的过程中,过渡张量变化程度的示意图;
18.图4是过渡质量及其组成成分的热图及应用示意图;
19.图5是增加新的模板控制器的示意图;以及
20.图6是本发明一实施例的建立复杂运动控制器的方法的综合示意图。
21.元件标号说明
22.s1~s5:步骤
具体实施方式
23.有鉴于此,本发明提出一种建立复杂运动控制器的方法,其中包括过渡运动张量(transition motion tensor,后文简称为过渡张量),这是一种数据导向的架构(data-driven framework),可在运动数据集以外建立符合新的过渡。过渡张量保留了单个运动控
制器的稳健性(robustness),并在最合适的阶段切换到目标控制器。
24.依据本发明一实施例的一种建立复杂运动控制器的方法,包括以处理器执行下列步骤:取得一源控制器及一目标控制器,所述源控制器用于产生一源运动,所述目标控制器用于产生一目标运动;决定所述源控制器及所述目标控制器之间的一过渡张量,所述过渡张量具有多个索引,该些索引中的一者对应于所述源运动的多个相位;计算所述过渡张量的多个结果,并依据该些索引记录该些结果;依据该些结果计算多个过渡质量;以及在该些过渡质量中寻找一最佳过渡质量以建立一复杂运动控制器,所述复杂运动控制器用以产生对应于该些相位中的一者的一复杂运动。
25.本发明提出一种建立复杂运动控制器的方法,可在不修改现有运动的情况下有效而稳健地(robustly)建立新运动。给定几个不同的基于物理的运动控制器,本发明提出的过渡张量可作为在运动控制器之间切换的依据。藉由查询过渡张量以获得最佳过渡的方式可以建立一个统一(unified)的复杂运动控制器,所述控制器能够产生包含各种行为的新过渡,例如在角色进行更高的跳跃之前减速或立即跳跃以获得更好的响应。本发明适用于表现四足动物和两足动物的运动,对过渡质量进行定量和定性评估,并在遵循用户控制指令的同时具备处理复杂运动规划的能力。
26.综上所述,本发明具有以下贡献或效果:
27.1.提出一种数据导向的方法,可在运动数据集以外建立符合物理现象且新颖的过渡;
28.2.提出一个可扩展的架构,将基于各种架构或训练过程的现有控制器统合到一个连贯的(coherent)、统一的控制器中,并减少扩展时的训练成本;以及
29.3.提出一种方案,其利用控制器解决复杂运动规划问题,同时满足用户控制指令及物理环境约束。
30.以上的关于本揭露内容的说明及以下的实施方式的说明系用以示范与解释本发明的精神与原理,并且提供本发明的专利申请范围更进一步的解释。
31.【图式简单说明】
32.图1是本发明一实施例的建立复杂运动控制器的方法的流程图;
33.图2是训练模板控制器的过程中加入外部干扰的示意图;
34.图3是从源运动过渡到目标运动的过程中,过渡张量变化程度的示意图;
35.图4是过渡质量及其组成成分的热图及应用示意图;
36.图5是增加新的模板控制器的示意图;以及
37.图6是本发明一实施例的建立复杂运动控制器的方法的综合示意图。
38.【实施方式】
39.以下在实施方式中详细叙述本发明的详细特征以及特点,其内容足以使任何熟习相关技艺者了解本发明的技术内容并据以实施,且根据本说明书所揭露的内容、申请专利范围及图式,任何熟习相关技艺者可轻易地理解本发明相关的构想及特点。以下的实施例进一步详细说明本发明的观点,但非以任何观点限制本发明的范畴。
40.本发明建立的复杂运动控制器可用于控制电影、游戏中的虚拟角色,或控制真实世界中的机器人。
41.图1是本发明一实施例的建立复杂运动控制器的方法的流程图,所述方法是以处
理器执行图1所示的步骤s1~s5。步骤s1是「取得源控制器及目标控制器」,步骤s2是「决定源控制器及目标控制器之间的过渡张量」,步骤s3是「计算过渡张量的多个结果,并依据索引记录这些结果」,步骤s4是「依据记录的这些结果计算多个过渡质量」,步骤s5是「在这些过渡质量中寻找最佳过渡质量以建立复杂运动控制器」,以下分别介绍各步骤的实施细节。
42.步骤s1是「取得源控制器及目标控制器」,源控制器依据角色的当前状态及控制目标产生源运动,目标控制器依据角色的当前状态及控制目标产生目标运动。举例来说:源运动是走路,目标运动是跑步,而复杂运动则是从走路过渡到跑步。控制目标的输入包含至少一物理参数控制量,例如跑步的秒速,从高处掉下的重力加速度。
43.源控制器及目标控制器都是一种模板控制器(template controller),以下详述模板控制器的细节:
44.为了使角色能够在模拟的物理环境中执行复杂运动,常见的做法是训练基于物理的控制器以适应多种类型的运动。但是使用单一控制器输出多种复杂运动需要大量的训练成本,而且在训练过程中,可能会因为各种运动的类型差异太大而增加训练的困难度。为了避免上述问题,本发明将每一个运动都分配给一个基于物理的控制器,称之模板控制器。这种策略可将训练复杂度限制在单一个控制器内,从而使训练过程更易于处理和独立作业。
45.在训练模板控制器之前,需使用运动学(kinematic)控制器收集多个参考运动片段。在每个参考运动片段中,控制角色重复执行各自的运动,但每次重复时对速度、方向和高度的输入参数略有不同。为了可以在动态环境中产生真实的运动,本发明使用深度强化学习(deep reinforcement learning,drl)的技术训练模板控制器,模板控制器π(a
t
|s
t
,c
t
)输出运动a
t
∈a,其中t为给定的时阶(time step),s
t
∈s为给定角色的当前状态,c
t
为控制目标(control objective),a和s分别代表运动域和状态域。当前状态s
t
储存角色的位置、旋转量、速度及角速度。控制目标其中σ为目标移动速度(例如以公尺/秒为单位),θ为目标方向(例如以弪度为单位),为目标质心(center of mass,com)的高度(例如以公尺为单位)。
46.本发明透过对指定的参考运动片段执行「模仿学习」(imitation learning)来初始化模板控制器。在此过程中,模板控制器的目标是匹配运动学角色和仿真角色的关节位置,本发明使用运动学角色的两个连续帧作为低阶控制器的目标。一旦收敛,本发明进一步微调模板控制器以遵循高级运动控制指令(包括如:速度、方向和目标质心的高度等参数)。由于控制目标的值来自参考运动片段,因此不需要在所有时间设定所有值。例如,在快走(trot)或慢跑(canter)等运动时目标质心的高度可以保持不变,但是在跳跃运动中目标质心的高度则需要随时间调整。
47.为了保证每个模板控制器的稳健性,本发明在训练过程中引入了外部干扰,例如从随机方向朝角色投掷各种大小的物体,如图2所示。采用上述方式将得到一组可控制的且稳健的模板控制器ψ={π1...π6},各自属于词汇集v={快走,慢跑,跳跃,慢步,站立,坐下}中的一个控制词汇。
48.针对模板控制器的训练,本发明使用近端策略优化(proximal policy optimization)、广义优势估计器gae(λ)(generalized advantage estimator)、多步返回td(λ)(multi-step returns)等技术。为了提高取样效率并防止模板控制器陷入于对整体
而言较差的局部最优解,本发明采用“xue bin peng,pieter abbeel,sergey levine,and michiel van de panne.2018.deepmimic:example-guided deep reinforcement learning of physics-based character skills.acm transactions on graphics(tog)37,4(2018),143.”此文献中提到的提前终止(early termination)和参考状态初始化(reference state initialization)等技术。
49.本发明将每个模板控制器作为一个分层策略(hierarchical policy)来实现,每个模板控制器都具有以基元(primitive)表示的低阶控制器,控制目标直接被指派至低阶控制器。一个模板控制器通常需要四个基元,跳跃运动则是例外,它需要八个基元来解决额外的运动复杂度。
50.模板控制器只允许角色执行特定运动。因此,单一模板控制器并无法解决需要整合多个运动的复杂运动的任务。例如,控制角色跳过一个大坑洞并快速奔跑到目的地,则角色需要先跑得足够快,然后跳跃,并在落地后朝着目的地奔跑。然而,知道角色何时在奔跑和跳跃之间过渡(转换)并不是一项简单的任务,因为角色的状态直接影响过渡结果。简单的过渡可能会产生看起来奇怪或甚至失败的复杂运动。因此,本发明在步骤s2提出了一个数据导向的过渡张量(transition tensor),藉由仔细检查过渡的关键时间点来引导角色成功地从一个运动过渡到另一个运动。
51.步骤s2是「决定源控制器及目标控制器之间的过渡张量」,过渡张量(后文简称张量)具有多个索引,这些索引中的一者对应于源运动的多个相位。举例来说,源运动为抬起左手,其包含了肘关节旋转0度、1度、2度、3度
…
直到可旋转的角度上限等多个相位。
52.在从源控制器切换到目标控制器的过程中,角色与源控制器处于特定的状态(相位),而且目标控制器可能从未见过这种状态,当目标状态器试图从这种新状态恢复时就产生了一个新的过渡运动。此新的过渡运动既不存在于源控制器中也不存在于目标控制器中。也就是说,在两个控制器的配对之间切换产生了过渡运动,如图3所示。
53.然而,任意地地开关器会产生不稳定的过渡,因为运动的难度各不相同。虽然可以藉由分配兼容于源运动及目标运动的控制目标来改进切换过程,例如插入运动速度以在不同的运动步态之间进行过渡。然而,这种策略对于需要更精细和准确的落下时机的运动无效,而此种情况适合用角色的阶段标签来描述。例如,在慢跑和跳跃之间是否能成功过渡取决于角色的脚是否接触地面。因此,当角色在空中时,从跳跃回到慢跑的复杂运动可能会提高目标控制器的复杂性,导致稳定时间更长,施力过大,偏离控制目标,甚至导致角色坠落。
54.为了描述源运动和目标运动之间成功过渡的可能性,本发明定义一个具有四个维度的张量t来记录过渡的结果,如下方式一所示。
55.式一:t
m,,n,ω
=(η,δt,e,α)
56.张量t的四个索引包括:代表源控制器的m∈v,代表目标控制器的n∈v,其中v为词汇集,代表源控制器的相位的φ∈[0,1),代表目标控制器的相位的ω∈[0,1)。每个组合(η,δt,e,α)取决于w=(m,φ,n,ω),即:η≡ηw。
[0057]
张量中的每个元素tw都是一个4维向量,代表在w处的过渡结果。第一个结果η记录了过渡之后的存活指标(alive state),若角色的头部、躯干和背部不接触地面而成功过渡,则η=1,若角色跌倒,则η=0。第二个结果δt代表从切换过程开始到目标控制器稳定时结束的过渡时间(duration)。第三个结果e代表过渡的耗能成本(effort),例如过渡时间中
所有关节扭矩的总和,如下方式二所示。
[0058]
式二:
[0059]
其中,j为角色的关节数量,j为关节标签,位于第j关节的比例积分控制器(proportional derivative controller,pd controller)的扭矩在给定时间t被表示为为了评估角色遵循控制目标的程度,本发明分别定义速度、方向和高度奖励如下方式三、式四及式五所示。
[0060]
式三:
[0061]
式四:
[0062]
式五:
[0063]
其中,‖.‖为l2范数(norm),vc为角色的质心速度,u=(cos(θ),-sin(θ))为投影到二维运动平面的目标方向,h,为角色在过渡前后的质心高度。本发明将控制奖励定义为式三、式四及式五的平均,如下方式六所示。
[0064]
式六:
[0065]
最后,张量t的第四个结果α为角色的控制精确度,其计算方式为目标控制器的两个稳定状态之间的控制奖励的总和。本发明在过渡后(post-transition)量测控制精确度,因为本发明假设在过渡期间没有控制精确度的数据,控制精确度定义如下方式七所示。
[0066]
式七:
[0067]
在步骤s3计算每一过渡张量的四个结果之前,本发明使用稳健性测试评估模板控制器。例如:每0.1秒从随机方向投掷大小和密度不同的物体,若角色存活至少10秒,则此模板控制器通过了稳健性测试。
[0068]
图3是从源运动过渡到目标运动的过程中,过渡张量变化程度的示意图。此示意图的记录开始于角色执行源运动(慢跑)。在切换到目标控制器之前,先等待源控制器稳定下来。在切换时,输入角色的当前状态和取材自目标运动片段的高级控制目标,并在所有相位中均匀取样。接下来,记录控制器的反应,并记录角色的脚部落下的轨迹,质心位置,关节扭矩(torque),和控制精确度(如式七)。在控制器切换过程的5秒后终止记录,因为大多数控制器此时已经稳定或出现故障。
[0069]
步骤s3是「计算过渡张量的多个结果,并依据索引记录这些结果」。处理器采用蒙地卡罗(monte carlo)法计算多个结果,每一结果包括存活指标η、过渡时间δt、耗能成本e及控制精确度α。
[0070]
为了找出过渡的所有可能性,藉由在支持物理模拟的环境中使用蒙地卡罗(monte carlo)法,本发明计算大量的(如数百万个)过渡张量的样本来填充张量。每个成对过渡在源运动及目标阶段的多个相位中均匀取样。
[0071]
步骤s4是「依据记录的结果计算多个过渡质量」,其中每一过渡质量包括稳定度(stability)及结果(outcome)值,结果值系处理器依据存活指标、过渡时间、耗能成本及控制精确度计算得到。
[0072]
如式一所示,对于在源控制器及目标控制器之间的过渡,一个用于描述此过渡的可能性的4维张量可用于统合(unify)两个模板控制器,让角色能够执行词汇集v中的运动的组合。并且在步骤s5建立复杂运动控制器时利用统合后的模板控制器来引导角色。为了实现此目标,本发明在步骤s4中将过渡张量的四个维度合并为一个结果值,如下式八所示:
[0073]
式八:
[0074]
其中,γw为基于索引w的结果值。
[0075]
另一方面,本发明希望确保相邻样本中的结果值和存活机率具有一致性。因此,本发明定义局部邻域(local neighborhood)γw(δ),其为γ邻近于w的二维子张量,w∈{m,φ
±
δ,n,ω
±
δ},其中φ
±
δ代表源运动m中关联于相位φ的多个邻近的参考相位,ω
±
δ代表目标运动n中关联于相位ω的多个邻近的参考相位。
[0076]
然后,本发明计算过渡结果ζw(δ)的一致性,作为在γw(δ)中所有样本的变异数(variance)。
[0077]
类似地,本发明计算一个过渡的存活机率ηw(δ),作为tw(δ)中存活指针η=1的样本的比例。
[0078]
因此,稳定度如下方式九所示:
[0079]
式九:ψw(δ)=ηw(δ)
×
exp(-βζw(δ))
[0080]
其中β=0.015。整合稳定度和结果值,在w处的过渡质量如下方式十所示。
[0081]
式十:qw=ψw(δ)
×
γw[0082]
步骤s5是「在这些过渡质量中寻找最佳过渡质量以建立复杂运动控制器」,复杂运动控制器用于产生对应于源运动的多个相位中的一者的复杂运动。
[0083]
为了产生从源运动到目标运动之间的过渡,需要在众多的张量的中寻找最佳过渡。给定目标运动卷标n以及相位为φ的源运动m的信息,处理器可以藉由查看子张量q
m,φ
±
∈,n
来找到最佳转换,其中∈是用于搜索空间的可调整的参数,并定位具有最佳过渡质量的目标相位,如图4所示。依据最佳过渡质量,可以在两个控制器之间执行可靠的过渡。对所有运动组成的每个配对的过渡重复相同的策略,可将模板控制器统合为单一的复杂运动控制器,其用于产生复杂的运动。
[0084]
图4是过渡质量及其组成成分(结果值、稳定度)的热图及应用示意图。以源运动的相位作为纵轴,目标运动的相位作为横轴,处理器可绘制结果值、稳定度以及依据结果值及稳定度计算得到的过渡质量的热图(heat map)。本发明从过渡质量的热图的多个像素中找
出像素值在门坎值以上的过渡质量所对应的过渡张量,按这种方式可筛选出效果较好(例如存活指标为1、耗能成本较低、过渡时间较短、控制精确度较高)的一或多个过渡。
[0085]
图5是增加新的模板控制器(新的运动)的示意图。使用过渡张量,可以简单地增加新的运动而不会增加训练成本,只需要使用模板控制器描述新增的运动并透过过渡张量统合到原有的模板控制器。图5的范例是:依据本发明提出的方法,先前已建立由运动1、运动2及运动3之间的两者所组成的配对的六个过渡张量(运动1到运动2、运动1到运动3、运动2到运动3、运动2到运动1、运动3到运动1、运动3到运动2,注意配对顺序不同组成的过渡张量也不同),本发明在增加运动4时仅需花费建立新运动4与运动1、2、3之间的过渡张量的成本。此过程不需要额外的训练过程,并且新增更多运动不会改变先前配置好的运动和过渡。因此,本发明可以容易地沿着张量的源运动标签m的维度、以及目标运动卷标n的维度扩展运动词汇集v,如图5所示。
[0086]
整体而言,请参考图6,其为本发明一实施例的建立复杂运动控制器的方法的综合示意图。图6左方展示了收集多个过渡张量,每个过渡张量的内容包括存活指标、过渡时间、耗能成本及控制精确度。每个过渡张量对应于一个源控制器及目标控制器的配对,若控制器的数量为n,则过渡张量的收集数量上限为n
×
(n-1)。图6中间展示了建立完成的多个过渡张量。图6右方为一个产生统合控制器(unified controller)的范例:假设先前的统合控制器并不晓得从源运动2的某个相位过渡到目标运动3应所述如何进行,如过渡可行性矩阵第二列第三行所标示的问号所示,则处理器可透过在多个过渡张量中找到对应于源运动2和目标运动3的过渡张量,然后在这个过渡张量的所有可能性中找出过渡质量最好的一或数个目标运动的相位,从而实现从源运动2到目标运动3的过渡。
[0087]
本发明提出一种建立复杂运动控制器的方法,可在不修改现有运动的情况下有效而稳健地(robustly)建立新运动。给定几个不同的基于物理的运动控制器,本发明提出的过渡张量可作为在运动控制器之间切换的依据。藉由查询过渡张量以获得最佳过渡的方式可以建立一个统合的复杂运动控制器,所述控制器能够产生包含各种行为的新过渡,例如在角色进行更高的跳跃之前减速或立即跳跃以获得更好的响应。本发明适用于表现四足动物和两足动物的运动,对过渡质量进行定量和定性评估,并在遵循用户控制指令的同时具备处理复杂运动规划的能力。
[0088]
综上所述,本发明具有以下贡献或效果:
[0089]
1.提出一种数据导向的方法,可在运动数据集以外建立符合物理现象且新颖的过渡;
[0090]
2.提出一个可扩展的架构,将基于各种架构或训练过程的现有控制器统合到一个连贯的(coherent)、统一的控制器中,并减少扩展时的训练成本;以及
[0091]
3.提出一种方案,其利用控制器解决复杂运动规划问题,同时满足用户控制指令及物理环境约束。
[0092]
虽然本发明以前述的实施例揭露如上,然其并非用以限定本发明。在不脱离本发明的精神和范围内,所为之更动与润饰,均属本发明的专利保护范围。关于本发明所界定的保护范围请参考所附的申请专利范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1