基于空间感知与时间差异学习的视频去雨方法
1.本发明属于图像处理和计算机视觉领域,涉及一种基于空间感知与时间差异学习的视频去雨方法。
背景技术:
2.随着科学技术的发展,图像和视频的概念正逐渐被应用在众多活动当中,比如上班打卡时的面部识别技术,驾驶时需要的倒车影像,交通安全的监察监控系统等等。伴随其中的,便是许多与图像设备、视频处理等有关的技术也在不断地发展与进步,既而反作用推动整个图像领域应用范围的越来越广。然而,视觉领域中有一个很大的一个限制就是恶劣天气。当遇到诸如大雨、雾霾、暴雪之类的天气情况的时候,不仅人们肉眼的辨识辨物会受到影响,摄像机、照相机的清晰度、可见性也会大打折扣,于是这些技术与图像,特别是户外环境采集到的图像便会受到很大的影响导致画质的变化。而在一般应用当中,对于实际拍摄的图像与视频进行操作时很少会去考虑户外的天气影响,这就会导致计算机视觉系统的效果变差受限,使得最终获得的图像变得模糊、不清晰,对比度变小,细节减少或丢失,出现图片质量降低、图像噪声增加、重要背景信息遮挡丢失等情况,从而极大地影响了图像分割,所需目标识别,特定目标跟踪等等大部分的视觉处理算法的性能。
3.因此,去雨对于图像的处理而言具有重要的现实意义,也具有很大的发展前景。他不仅可以作为一项单独的任务,如视频监控系统中雨天拍摄的车牌照的复原等等,也可以应用在许多计算机视觉系统任务的预处理步骤,防止因细节丢失而带来的信息不准确等等问题,保证性能准确有效。但因为雨在空间上是随机分布没有规律,并且雨还处于高速下落的状态,容易与运动物体混淆,因此,去雨工作即雨滴的检测和去除都具有非常大的难度。
4.现在也已经有人提出了许多种方法来进行去雨,这些方法总体来说可以被分成两类:基于视频的去雨方法和基于单幅图像的去雨方法。
5.基于图像的方法主要是利用雨水本身的物理特性的不同,进行信号的分离。 yu li等人在2016年《ieee conference on computer vision and pattern recognition》发表的“rain streak removal using layer priors”利用高斯模型对背景图像和雨线的先验信息进行编码,处理不同尺度的雨线。但由于该方法是采用方差提取雨条纹块,可靠性较低。专利cn108765327a利用稀疏编码来实现去雨,他通过将图像分解为低频和高频并进一步形成去雨字典,然后再基于稀疏编码去分解字典的成分,并利用景深进行一定的修正。但这种方法会引起输出图片一定程度上的色彩失真。深度学习的出现和发展提供了一些新的方法。专利cn106204499a通过训练一个三层的卷积神经网络,对原始图像进行重叠取块输入,并进行平均加权最终得到无雨图像。专利cn110838095a通过构建密集网络模型,提取雨纹信息,并与长短记忆网络模型串联得到子网络模型,以此反复循环迭代最终得到循环密集神经网络完成去雨。除此之外也有专利利用生成对抗网络完成去雨,例如专利 cn112258402a设计了一种密集残差和lstm相结合的生成器子网络,采用多次迭代进行特征提取和生成无雨图像。专利cn110992275a在利用编解码结构的同时增加了辅助的雨纹估计
网络和图像细化网络对结果进行进一步的细化。
6.基于视频的方法与单幅图像去雨类似,但不同的是,来自视频序列的时间冗余信息可以为雨水去除提供更多的可能性。最早有将背景相同的雨帧进行平均,以此来简单地利用时间信息完成去雨的。此外,也有人分别采用稀疏编码、方向梯度先验和低秩等传统物理方法实现了视频中的雨滴的去除。专利 cn103729828a通过检测相邻帧之间的光照变化,判断光照下像素是否被雨滴覆盖,进而去除雨滴。例如专利cn110070506a提出了混合指数模型来多尺度地模拟雨信息,再利用优化算法进行优化和最终的加权。专利cn105335949a利用快速模糊c均值聚类算法对已经从rgb转换为ycbcr色彩空间的图像像素进行分割,完成去雨。在深度学习的领域,同样出现了众多基于网络数据训练的方法, jie chen在2018年《ieee conference on computer vision and pattern recognition》发表的“robust video content alignment and compensation for rain removal in acnn framework”利用超像素级对齐算法完成去雨,将降雨图像分割成超像素,然后执行一致性约束并补偿这些对齐的超像素上丢失的细节。wenhan yang在 2018年《ieee conference on computer vision and pattern recognition》发表的“erase or fill deep joint recurrent rain removal and reconstruction in videos”利用深度循环卷积网络设计了一个联合循环网络集成去雨和背景的重建。但事实上,这些方法大多都只关注最终的结果性能,并以此来得到时间信息有被有效地利用的结论。但是这些基于神经网络的程序是黑盒状态,它们对时间信息的利用方式缺少可解释性。并且由于网络层数的增加也不可避免地出现了运行时间长、运行效率低等问题。
技术实现要素:
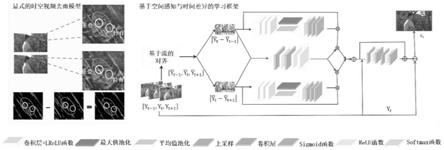
7.本发明建立了一个明确的显式时空视频去雨模型,并进一步提出了一个基于空间感知与时间差异的学习框架。具体来说,从集合的角度提出了一种新的视频去雨模型,以此来显式地描述不同相邻帧之间的降雨区域存在的关系。并以此设计了一个端到端视频去雨网络,首先利用注意力机制学习序列下时间差异中的相关性,然后进一步利用空间感知去恢复清晰图像,完成一个端到端的时间信息与空间信息集成的去雨过程。
8.具体方案如下:
9.一种基于空间感知与时间差异学习的视频去雨方法,步骤如下:
10.第一步,根据时间差异性做减法得到初始雨条纹;
11.从一个新的角度来描述雨帧,将帧按照空间位置看作是一个大的集合,然后根据该位置上是否有雨条纹再进行划分,具体表示为,
12.π(y
t
)=π
r
(y
t
)∪π
b
(y
t
),
ꢀꢀ
(1)
13.π(y
t
)表示当前帧对于空间位置的集合表示。π
r
(y
t
)是当前帧中被雨水覆盖的位置。π
b
(y
t
)则表示当前帧中没有雨条纹的位置,也就是后续不再需要进行处理的位置。对于π
r
(y
t
)而言,视频序列中相邻帧不仅在背景信息上存在重叠关系,在雨线的分布上同样存在重叠。因此,参考相邻帧信息,π
r
(y
t
)可以表示为,
[0014][0015]
π
r
(y
adjacent
)是视频序列中相邻帧的雨线位置的集合表示。交集∩表示当前帧和相
邻帧之间雨线的重叠区域,而则表示当前帧的独有的与相邻帧无关的雨线位置。通过该模型,便可以通过简单的减法就可以去除重叠的雨纹,
[0016]
第二步,利用注意力机制学习其中的时间相关性,获得更准确的雨线图;
[0017]
第三步,基于空间感知的集成去雨模块,利用空间信息,完成去雨任务。
[0018]
本发明的有益效果是:
[0019]
1)口本发明集合的角度提出了一种新的视频去雨模型,以此来显式地描述不同相邻帧之间的降雨区域的潜在关系,更好地利用时间信息。同时提出了能够实现端到端的视频去雨网络并且算法的性能优越,通过消融研究验证了不同网络模块的有效性。
[0020]
2)本发明针对视频去雨的问题提出的去雨方法在处理小雨和大雨情况下都有很好的表现效果,不仅能够将当前帧的各种方向堆叠的雨线去除干净,而且还能够很好地恢复当前帧的背景信息,保留较为完整的细节信息。并且运行速度快,效率高。
附图说明
[0021]
图1为方案整体流程图;
[0022]
图2为方案流程效果图;
[0023]
图3为本发明在合成数据上的结果展示示意图,(a)表示输入雨图,(b)表示该发明的实验结果;
[0024]
图4为本发明在真实数据上的结果展示示意图,(a)表示输入真实的雨图,(b) 表示该发明的实验结果。
具体实施方式
[0025]
本发明基于时间差异与空间感知,以相邻帧作为输入,利用自注意和相互注意机制引导学习其中的时间相关性,同时去除运动引入的背景信息。最后,空间感知的集成网络对输出结果进行补偿,恢复最终的清晰帧,具体实施方案如下:方案网络具体流程如图1,具体操作如下:
[0026]
第一步,根据时间差异性做减法得到初始雨条纹;
[0027]
定义三个雨输入帧[y
t
‑1,y
t
,y
t+1
]和基于流的估计网络。基于流的对齐过程可以表述为:
[0028][0029]
表示对其以后的相邻帧。表示训练过的spynet网络,为了更好地适应雨场景,spynet的网络参数也参与了学习过程。根据雨的位置在相邻帧的相同和差异,对对齐后的进行相减可以得到初始雨条纹提取,
[0030][0031]
第二步,利用注意力机制学习其中的时间相关性,获得更准确的雨线图;
[0032]
注意驱动的时间相关学习可以对不同框架下的雨区进行学习,并去除背景信息。公式为:
[0033]
[0034][0035]
代表自注意机制,代表相互注意机制。在与输入元素相乘之后,就可以接收目标结果了。同时,对不同注意网络得到的中间结果进行进一步的处理,引入了一种权重学习机制——相互注意。
[0036][0037]
第三步,基于空间感知的集成去雨模块,利用空间信息,完成去雨任务;
[0038]
为了充分利用空间信息,实现去训练的任务,还定义了以下的空间感知集成去训练:
[0039][0040]
是空间感知的集成去雨网络,表示经过空间感知网络后的当前帧的条纹。对于该模块的网络架构,构建了两个残差模块(conv+relu+conv)。最后由输入当前雨帧y
t
减去便可以得到最终的去雨结果x
t
。
[0041]
损失函数。
[0042]
网络是以l1范数作为损失函数,在与无雨图像的比较指导下逐步去训练,训练的损失函数可以表示为:,
[0043][0044][0045][0046]
λ
α
、λ
β
、λ为平衡每一项的加权参数。表示表示表示
[0047]
这个损失函数将指导网络学习从输入的雨的视频去除雨条纹。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1