近内存计算加速器、双列直插式内存模块以及计算设备
1.本技术涉及存储领域,尤其涉及一种近内存计算加速器、双列直插式内存模块以及计算设备。
背景技术:
2.存储层通常包括高速缓存(cache)、内存(dram memory)和非易失性存储器(nvm)。在传统计算机系统中,数据从非易失性存储器逐级加载到高速缓存中,然后由处理器(central processing unit,cpu)对其进行计算。由于数据需要从非易失性存储器逐级加载到高速缓存(cache)中,因此,cpu计算消耗数据的速度远高于内存读取数据的速度,严重制约着cpu发挥其应有的性能。
3.为了解决上述问题,现有技术提供了一种近内存计算加速系统,能够在内存附近设置具备计算能力的缓存芯片,由缓存芯片从内存取出数据,并对从内存取出数据进行计算,从而有效缩短数据从存取到计算的延迟。但是,现有的近内存计算加速系统只对向量维度较多的数据具有较好的加速作用,应用场景比较受限。
技术实现要素:
4.为了解决上述问题,本技术提供了一种近内存计算加速器、双列直插式内存模块以及计算设备,能够在数据量较多或者数据的向量维度较多时都能提升加速效果。
5.第一方面,提供了一种近内存计算加速器,包括:
6.多个控制器,用于并行获取多个内存块中的多个数据,其中,所述多个控制器中的一个控制器用于获取所述多个内存块中的一个内存块的数据;
7.计算模块,分别连接所述多个控制器,用于对所述多个数据进行计算,其中,
8.所述近内存计算加速器以及所述多个内存块位于同一块双列直插式内存模块dimm上。
9.上述方案中,近内存计算加速器中的计算模块通过多个控制器并发地从多个内存块获取多个数据,并对多个数据并行进行计算,因此,能够在数据量较多或者数据的向量维度较多时都能够提升加速效果。
10.在一些可能的设计中,所述计算包括:加法计算、乘法计算、除法计算、查找计算以及非线性计算中的至少一种。
11.上述方案中,近内存计算加速器的采用专有的指令集设计,指令集支持加法计算、乘法计算、除法计算、查找计算以及非线性计算等等计算,精简易用,无需复杂的解码设计,有利于减少芯片面积、功耗和成本。
12.在一些可能的设计中,所述加速器还包括指令解码器,所述指令解码器分别连接所述多个控制器,
13.所述指令解码器用于对通用处理器cpu发送的指令进行解码,得到解码结果,所述解码结果用于指示待进行计算的所述多个数据的地址以及计算类型;
14.所述多个控制器用于根据所述多个数据的地址并行从所述多个内存块中获取所述多个数据;
15.所述计算模块用于根据所述计算类型对所述多个数据执行相应的计算。
16.在一些可能的设计中,所述计算模块包括缓存单元,所述缓存单元用于缓存对所述多个数据进行计算得到的计算结果。
17.上述方案中,可以在缓存单元中缓存对所述多个数据进行计算得到的计算结果,在进行累加时,可以从缓存单元中读取计算结果继续进行累加,从而减少读取内存的次数,提高了数据处理的速度。
18.第二方面,提供了一种双列直插式内存模块dimm,包括:
19.多个内存块,用于存储多个数据,其中,所述多个内存块中的一个内存块用于存储所述多个数据中的一个数据;
20.近内存计算加速器,分别连接所述多个内存块,用于从所述多个内存块中并行获取所述多个数据,对所述多个数据进行计算。
21.在一些可能的设计中,所述计算包括:加法计算、乘法计算、除法计算、查找计算以及非线性计算中的至少一种。
22.在一些可能的设计中,所述近内存计算加速器,包括:
23.多个控制器,用于并行获取多个内存块中的多个数据,其中,所述多个控制器中的一个控制器用于获取所述多个内存块中的一个内存块的数据;
24.计算模块,分别连接所述多个控制器,用于对所述多个数据进行计算。
25.在一些可能的设计中,所述近内存计算加速器还包括指令解码器,所述指令解码器分别连接所述多个控制器,
26.所述指令解码器用于对通用处理器cpu发送的指令进行解码,得到解码结果,所述解码结果用于指示待进行计算的所述多个数据的地址以及计算类型;
27.所述多个控制器用于根据所述多个数据的地址并行从所述多个内存块中获取所述多个数据;
28.所述计算模块用于根据所述计算类型对所述多个数据执行相应的计算。
29.在一些可能的设计中,所述计算模块包括缓存单元,所述缓存单元用于缓存对所述多个数据进行计算得到的计算结果。
30.第三方面,提供了一种计算设备,包括:
31.通用处理器cpu,用于发送近内存计算指令;
32.双列直插式内存模块dimm,包括多个内存块以及近内存计算加速器,所述近内存计算加速器用于:
33.接收所述近内存计算指令,所述近内存计算指令用于指示待执行近内存计算的多个数据的地址以及计算类型;
34.根据所述多个数据的地址从所述多个内存块中并行获取所述多个数据;
35.根据所述计算类型对所述多个数据执行计算。
36.在一些可能的设计中,所述计算包括:加法计算、乘法计算、除法计算、查找计算以及非线性计算中的至少一种。
37.在一些可能的设计中,所述近内存计算加速器包括缓存单元,所述缓存单元用于
缓存对所述多个数据进行计算得到的计算结果。
38.在一些可能的设计中,所述多个内存块被配置为允许所述近内存计算加速器访问时,禁止所述cpu访问。
39.在一些可能的设计中,所述dimm还包括与所述多个内存块均不相同的一个或者多个内存块,所述一个或者多个内存块被配置为允许所述cpu访问时,禁止所述近内存计算加速器访问。
40.在一些可能的设计中,所述dimm被配置为允许所述近内存计算加速器访问所述多个内存块中的一个内存块时,所述cpu同步访问所述一个或者多个内存块。
41.在一些可能的设计中,所述近内存计算加速器满足以下条件中的一个或者多个;
42.所述近内存计算加速器访问所述多个内存块中的一个内存块的能耗低于所述cpu访问所述一个或者多个内存块的能耗。
43.第四方面,提供了一种近内存计算方法,所述方法包括:
44.接收近内存计算指令,所述近内存计算指令用于指示待执行近内存计算的多个数据的地址以及计算类型;
45.根据所述多个数据的地址从多个内存块中并行获取所述多个数据;
46.根据所述计算类型对所述多个数据执行近内存计算。
47.在一些可能的设计中,所述近内存计算包括:加法计算、乘法计算、除法计算、查找计算以及非线性计算中的至少一种。
附图说明
48.为了更清楚地说明本技术实施例或背景技术中的技术方案,下面将对本技术实施例或背景技术中所需要使用的附图进行说明。
49.图1是本技术涉及的一种近内存计算加速系统的结构示意图;
50.图2是图1所示的近内存计算加速系统的运作机制的示意图;
51.图3是本技术提供的一种计算设备的示意图;
52.图4是本技术提供的一种cpu的结构示意图;
53.图5是本技术提供的一种dimm的结构示意图;
54.图6是本技术提供的一种近内存计算指令的结构示意图;
55.图7是图1所示的近内存计算加速系统和图3所示的计算设备在各个场景下的加速效果的对比示意图;
56.图8是图3所示的计算设备分别在向量维度为16以及向量维度为1024时在不同的内存组数量下的加速效果的示意图;
57.图9是本技术提供的一种近内存计算方法的流程示意图。
具体实施方式
58.参见图1,图1是本技术本技术涉及的一种近内存计算加速系统的结构示意图。如图1所示,所述近内存计算加速系统包括cpu 110、多个双列直插式内存模块(dual inline memory modules,dimm)120以及ddr总线130。其中,cpu 110和dimm 120之间可以通过ddr总线130进行通信。
59.cpu 110是计算中心,具有较高的计算能力,可以包括用于缓存数据的高速缓存。dimm 120包括动态随机存取存储器(dynamic random access memory,dram)121以及缓存芯片122。缓存芯片122包括内存控制器和向量计算单元(nmp core)。其中,dram 121用于存储数据。缓存芯片122中的本地内存控制器根据有限状态机控制逻辑,将高层次的cpu的指令翻译成低层次的dram 121的c/a命令,以将数据从dram 121中读取至缓存芯片122中的向量计算单元中执行计算任务,并将该计算任务的计算结果写回dram 121中。由此可见,如果利用cpu 110进行计算,cpu 110需要将dimm 120的dram 121中的数据(从nvm中读取的)通过ddr总线130读取到cpu 110的高速缓存中才能进行计算。而缓存芯片122是设置在dimm 120中的,如果利用缓存芯片122进行计算,缓存芯片122可以直接访问dimm 120的dram 121中的数据(从nvm中读取的)并进行计算,有效缩短数据从读取到计算的延迟。
60.下面将结合图2对图1所示的近内存计算加速系统运作机制进行详细的说明。
61.假设近内存计算加速系统中dimm的数量为m个,每个dimm中缓存芯片122的数量均为一个,计算任务涉及的从nvm中读取的数据包括数据1、数据2、数据3、
…
、数据n。其中,数据1可以包括(子向量1、子向量2、
…
、子向量m),数据2可以包括(子向量1、子向量2、
…
、子向量m),
…
,数据n可以包括(子向量1、子向量2、
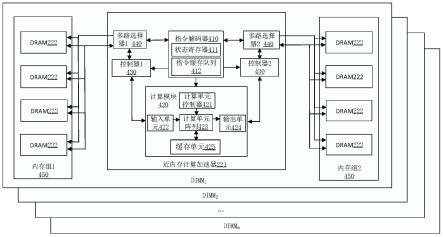
…
、子向量m)。并且,数据1的子向量1,数据2的子向量1,
…
,数据n的子向量1均必须存储于dimm1中;数据1的子向量2,数据2的子向量2,
…
,数据n的子向量2均必须存储于dimm2;
…
;数据1的子向量m,数据2的子向量m,
…
,数据n的子向量2均必须存储于dimmm。dimm1中缓存芯片1对数据1的子向量1,数据2的子向量1,
…
,数据n的子向量1进行处理,得到计算结果的子向量1;dimm2中缓存芯片2对数据1的子向量2,数据2的子向量2,
…
,数据n的子向量2进行处理,得到计算结果的子向量2;
…
;dimmm中缓存芯片m对数据1的子向量m,数据2的子向量m,
…
,数据n的子向量m进行处理,得到计算结果的子向量m。
62.在上述方案中,单个数据的各个子向量必须要分布存储在各个dimm中,才能达到加速的效果。但是,当单个数据的向量维度不足以分布到各个dimm的时候,例如,当单个数据的向量维度为1的时候,则只有dimm1中的缓存芯片1进行工作,其他dimm中的缓存芯片(例如,缓存芯片2至m)都处于空闲状态,加速的效果将会受到影响。
63.参见图3,图3是本技术提供的一种计算设备的示意图。如图3所示,本技术涉及的计算设备包括:cpu 210、一个或者多个dimm 220。其中,cpu 210和dimm 220之间可以通过总线230之间进行通信。
64.cpu 210的体系结构可以分为两类:一类为精简指令集计算机(reduced instruction set computer,risc),每条指令仅用于完成一项简单操作。对于经常使用的简单操作,risc结构的处理器可以以更快的速度执行指令,对不常用的操作,risc结构的处理器常通过组合指令来完成。另一类为复杂指令系统计算机(complex instruction set computer,cisc),每个指令可执行若干简单操作,例如从存储器读取、存储、和计算操作,全部集于单一复杂指令之中。cisc结构的处理器指令系统比较丰富,有专用指令来完成特定的功能。在一具体的实施例中,如图4所示,cpu 210用于处理dimm 220中存放的指令和数据。在一些实施例中,指令可以包括一个或多个指令格式。指令格式可以指示各种字段(位的数量、位的位置等)来指定待执行的数据处理的操作和操作数,其中该操作将在该操作数上被执行。一些指令格式可以进一步由指令模板(或子格式)定义。cpu 210包括存储器地址
寄存器301、存储器数据寄存器302、程序计数器303、指令寄存器304、指令译码器305、操作控制器307、计算单元308、通用寄存器309、累加器310、程序状态寄存器311、时序电路312以及处理器总线313。其中,处理器总线313也可以是数据总线、电源总线、控制总线或者状态信号总线等。
65.存储器地址寄存器301用于保存cpu 210当前所要访问的dimm 220中的内存的地址。
66.存储器数据寄存器302用于保存cpu 210从该地址中读取或写入的数据和读取或写入的指令,以便弥补cpu和存储器之间存在的操作速度上的差异。
67.程序计数器303用于存放下一条指令的地址,当指令顺序执行时,每取一条指令后程序计数器303自动加上一条指令的字节数。当遇到转移指令时,程序计数器303通过转移指令中的地址码字段来指定下一条指令的地址。
68.时序电路312通过固定时钟为各部件提供一个时间基准,cpu 210执行一条指令的时间为一个指令周期。
69.指令寄存器304用于保存当前正在执行的指令。指令包括操作码和地址码两个字段,操作码部分由指令译码器305对操作码部分进行译码,以产生指令所要求操作的控制电位。操作控制器307可以根据指令译码器输出的控制电位信号和时序电路312产生的时序信号,生成各种操作控制信号,控制cpu 210其余部件完成取指令和执行指令的操作。
70.微指令是cpu 210执行指令的最小单位,一条指令可以是单个微指令,也可以由若干个微指令组成。由多条微指令组合的指令称为复杂指令,可以使用各种不同的机制来实现指令译码器305对复杂指令的解码。具体的解码机制包括但不限于查找表,硬件实现,可编程逻辑阵列(pla),微码只读存储器(rom)等方式。在一个实施例中,可以将复杂指令对应的微指令的步骤存储在微码只读存储器306中,指令译码器305在译码的过程中,可以从微码只读存储器306中查询并得到组成复杂指令的微指令的操作码和地址码,依次对微指令的操作码部分进行译码,产生微指令所要求操作的控制电位。
71.操作控制器307具有多个缓冲器,可以根据指令的种类,将解码后的指令送往各自的保留站中保存下来。并根据计算单元的硬件电路的状态和各指令能否提前执行的具体情况分析后,将能提前执行的指令调度给相应计算单元308执行。在这期间对指令流进行重新排序,以使指令流水线行进并被平滑调度。示例性地,对于整数计算的指令,操作控制器307可以使用整数保留站保存指令,并分配给整数计算单元执行计算;二对于浮点数计算的指令,操作控制器307可以使用浮点数保留站保存指令,并分配给浮点数计算单元执行计算。
72.通用寄存器组309用于根据指令的地址码,保存地址码对应的数据。计算单元308用于接收操作控制器307的操作控制信号并对保存在通用寄存器组309中的数据执行计算,包括算术计算(包括加减乘数等基本计算及其附加计算)和逻辑计算(包括移位、逻辑测试或两个值比较)。计算中产生的临时变量存放在累加器310中,产生的状态的信息存放在程序状态字寄存311中,例如计算结果进/借位标志(c)、计算结果溢出标志(o)、计算结果为零标志(z)、计算结果为负标志(n)、计算结果符号标志(s)等。程序状态字寄存器还用来保存中断和计算设备工作状态等信息,以便cpu 210及时了解机器运行状态和程序运行状态。
73.计算单元308中包含多种不同的电路模块,可以分别用于执行不同的指令。例如,整数计算单元3081以及浮点数计算单元3082,分别用于对整数和浮点数进行算术计算和逻
辑计算。
74.应理解,图4所示的cpu可以包括更多或者更少的部件,或者,图4中的多个部件可以集成为一个部件,此处不作具体限定。
75.如图5所示,dimm是由一个或者多个近内存计算加速器221以及多个dram 222组成的模块。
76.dram 222是一种半导体存储器,与大部分随机存取存储器(random access memory,ram)一样,属于一种易失性存储器(volatile memory)设备。dimm中的dram 222的数量通常为多个。为了方便对dram 222进行管理,可以引用内存块的概念。内存块可以包括第一内存块以及第二内存块,其中,第一内存块被配置为允许所述近内存计算加速器访问时,禁止所述cpu访问;第二内存块被配置为禁止近内存计算加速器访问时,允许cpu访问。并且,第一内存块被近内存计算加速器访问的同时,cpu可以同步访问第二内存块。这样,cpu与近内存计算加速器可以同时访问各自的内存地址空间,互不干扰,解决了现有技术cpu与近内存计算加速器无法同时访问内存,在近内存计算期间严重影响系统其余应用处理效率的问题。其中,内存块可以是将多个dram 222组成的内存组(rank),也可以是将单个dram 222进行划分得到的内存库(bank),也可以是dram等等。举个例子说明,dimm的正反两面都具有多个dram 222,可以将同一面的多个dram组成一个内存组。单个dram 222可以分成8个或16个内存库。可以理解,上述例子都仅仅作为具体的示例,在实际应用中,也可以将dimm的正反两面的dram 222分成4个内存组,8个内存组或者更少或更多内存组,也可以将单个dram 222可以分成2个内存库,4个内存库或者更少或更多内存库等等,此处不作具体限定。
77.近内存计算加速器221分别与dimm内的内存块相连,可并行访问第一内存块,从而增加内部等效数据访问带宽,并且,由于数据集中在近内存计算加速器221上处理,支持跨多个内存块数据访问与处理,数据分配无需限制在同一内存块上。
78.在一具体的实施例中,近内存计算加速器221包括指令解码器410、计算模块420、多个控制器430以及多个多路选择器440。
79.指令解码器410用于接收cpu通过ddr总线发送的指令,对cpu发送的指令进行解码,得到解码结果,所述解码结果用于指示待进行计算的所述多个数据的地址以及计算类型。在一更具体的实施例中,指令解码器410包括状态寄存器411以及指令缓存队列412。其中,指令包括普通指令以及近内存计算指令。如果指令是普通指令,指令解码器410将普通指令通过多路选择器440传递给对应的dram 222。如果指令是近内存计算指令,指令解码器410阻止该近内存计算指令到达dram 222,并将该近内存计算指令保存在指令缓存队列412中。状态寄存器411为内存可寻址的空间,当cpu向该地址发送读取请求,指令解码器410随即向cpu返回状态寄存器411中存储的近内存计算的工作状态。
80.计算模块420用于根据所述计算类型对所述多个数据执行相应的计算。计算模块420包括计算单元控制器421、输入单元422、计算单元阵列423、输出单元424以及缓存单元425。其中,计算单元控制器421用于控制计算单元阵列423执行近内存计算指令对相应的数据处理操作。输入单元422用于缓存从dram 222中读取准备用于执行近内存计算指令的数据。输出单元424用于缓存计算单元阵列423执行近内存计算指令之后得到的计算结果。缓存单元425用于存储执行近内存计算指令的数据处理过程中需要重复利用的数据。缓存单
元425的容量可以根据需要进行设置,例如,可以是4千字节。计算单元阵列423总的数据吞吐带宽与dimm条内所有内存组450并发访问数据总带宽相同,来自一个或多个内存组450的数据集中在计算单元阵列423进行处理。
81.控制器430接受指令解码器410发送过来的所述多个数据的地址和计算模块420输出的计算结果,生成对dram 222读写数据的操作命令。控制器430的数量为多个,例如,两个,三个或者更多。在一具体的实施例中,控制器430的数量可以与内存组450的数量相同,即,每个内存组450均具有独立的控制器430。或者,控制器430的数量可以与内存库的数量相同,即,每个内存库均具有独立的控制器430。或者,控制器430的数量可以与dram 222的数量相同,即,每个dram 222均具有独立的控制器430。
82.多路选择器440用于根据指令解码器410的控制信号,选择将控制器430或者cpu的访存命令发送给dram 222,以及,从dram 222中获取需要发送给控制器430以及cpu的数据。在一具体的实施中,多路选择器440的数量可以与控制器430的数量相同。在其他的实施例中,控制器430的数量也可以多于或者少于多路选择器440的数量,此处不作具体限定。
83.可以理解,图5所示dimm仅仅作为一个具体的实例,在实际应用中,dimm可以包括更多的内存组、更多的近内存计算加速器,并且,近内存计算加速器可以包括更多或者更少的部件,此处不作具体限定。
84.近内存计算指令是cpu发送给dimm的,属于dimm支持的近内存计算指令集中的指令。其中,近内存计算指令集可以包括一条或者多条近内存计算指令。不同的近内存计算指令集可以支持不同的近内存计算指令。近内存计算指令集中指令的内容以及指令的数量等等均可以根据用户的需求进行设置。当近内存计算指令集越复杂,则dimm支持的近内存计算越复杂,但是,dimm的电路的设计越复杂,计算的效率越低;相反,当近内存计算指令集越简单,则dimm支持的近内存计算越简单,但是,dimm的电路的设计越简单,计算的效率越高。在一具体的实施例中,近内存计算指令集支持的计算包括加法计算、乘法计算、除法计算、查找计算以及非线性计算中的至少一种。
85.近内存计算指令通常包括操作码、子操作码、非线性操作码、向量维度、输入地址1、输入地址2,输出地址,常数1以及常数2。其中,操作码用于指示可以进行近内存计算的计算类型,例如,操作码可以指示加法计算、乘法计算、除法计算以及查找计算等等计算类型中的一种或者多种。子操作码用于指示每种计算类型包括的子计算类型,例如,当操作码为加法时,子操作码可以包括(从内存读,写回缓存)、(从缓存读,写回缓存)、(从缓存读,写回内存)、(从内存读,写回内存)等等子计算类型中的一种或者多种。当操作码为乘法时,子操作码可以包括向量对应元素积、向量数乘、向量内积等等子计算类型中的一种或者多种。当操作码为除法时,子操作码可以包括向量对应元素相除、向量按元素除以常数、常数按元素除以向量等等子计算类型中的一种或者多种。当操作码为查找时,子操作码可以包括归纳和匹配等等子计算类型中的一种或者多种。非线性操作码可以与操作码结合,用于指示是否需要对该操作码对应的计算进行非线性计算。向量维度用于指示进行近内存计算的数据的向量维度。输入地址1为进行近内存计算的第一数据所在的地址。输入地址2为进行近内存计算的第二数据所在的地址。输出地址为近内存计算的计算结果的存储地址。常数1和常数2为进行近内存计算的常数。
86.近内存计算指令集按照指令执行的功能分可以包括:加法操作、乘法操作、除法操
作、查找操作等等。因此,可以用2位二进制数的操作码来表示。每种操作对应的子操作数量最多为4种,因此,也可以用2位二进制数子操作码的来表示。综合来说,采用4位二进制数可以表示近内存计算指令集支持的所有操作。非线性操作一般是在计算结果的基础上进行的,因此,加法操作对应的指令、乘法操作对应的指令和除法操作对应的指令之外还需要额外的2位二进制数的非线性操作码指示是否需要对计算结果进行非线性变换,以及采用何种非线性变换函数。在内存bl8访问模式下,一次访存可返回64字节的数据,因此,指令中的向量维度最大值设置为64,可以采用6位二进制数或者7位二进制数的向量维度来进行表示。这样一条指令可以多次迭代执行,每次执行按字节索引的地址值增加64,从而可以通过一条指令访问4千字节的物理页空间。对于大于4千字节的数据,需要分多条指令完成访问。在双倍速率sdram(double-data-rate fourth generation synchronous dynamic random access memory,ddr4 sdram)的规范中,行地址最多有18位二进制数,列地址为10位二进制数,库组(bank group,bg)和库(bank,ba)索引各2位二进制数,再加上cs0-cs4共4位内存组的片选信号,地址的长度最多为36位二进制数。根据不同的指令,36位二进制数的地址的低32位也可用于传输32位二进制数的数据。综合上述,近内存计算指令的长度最多有121位二进制数:4位二进制数(操作码+子操作码)+2位二进制数(非线性操作码)+7位二进制数(向量维度)+36位二进制数(输入地址1)+36位二进制数(输入地址2)+36位二进制数(输出地址)。ddr接口的双向数据控制引脚(bi-directional data strobe,dq)总线位宽为64-bit,因此可以通过2个ddr时钟周期传输128位二进制数数据,用128位二进制数数据来存储近内存计算指令。
87.如图6所示,近内存计算指令可以采用如下格式:4位的操作码字段、2位的非线性操作码字段、7位的向量维度字段、36位的第一输入字段、36位的第二输入字段、36位的输出字段以及6位的保留字段。其中,操作码字段用于存储操作码以及子操作码。非线性操作码字段用于存储非线性操作码。向量维度字段用于存储向量维度。第一输入字段用于存储输入地址1或者常数1。第二输入字段用于存储输入地址2或者常数2。输出字段用于存储输出地址。
88.可以理解,图6所示的近内存计算指令的各个字段的长度,各个字段的内容,总的字段的数量均可以按照需要进行设置,此处不作具体限定。
89.下面将以表1所示的近内存计算指令集为例,对近内存计算指令集中的各个近内存计算指令进行详细的介绍:
90.表1近内存计算指令集
[0091][0092][0093]
接下来,将对每一条指令进行详细说明:
[0094]
指令1表示从内存(dram)的输入地址1和内存(dram)的输入地址2分别读取两个数据,将两个数据按元素进行相加得到计算结果,计算结果保存在近内存计算加速器的缓存单元的输出缓存地址中。
[0095]
指令2表示从内存(dram)的输入地址1中读取数据1,从近内存计算加速器的缓存单元的输入缓存地址读取数据2,将两个数据按元素进行相加得到计算结果,计算结果保存在近内存计算加速器的缓存单元的输出缓存地址中。
[0096]
指令3表示从内存(dram)的输入地址1中读取数据1,从近内存计算加速器的缓存单元的输入缓存地址读取数据2,将两个数据按元素进行相加得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0097]
指令4表示从内存(dram)的输入地址1和内存(dram)的输入地址2分别读取两个数据,将两个数据进行相加得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0098]
指令5表示从内存(dram)的输入地址1和内存(dram)的输入地址2分别读取两个数据,将两个数据的对应元素进行相乘得到计算结果,计算结果保存在内存(dram)的输出内
存地址中。
[0099]
指令6表示从内存(dram)的输入地址1中读取数据1,将数据1和常数进行数乘得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0100]
指令7表示从内存(dram)的输入地址1和内存(dram)的输入地址2分别读取两个数据,将两个数据进行内积计算得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0101]
指令8表示从内存(dram)的输入地址1和内存(dram)的输入地址2分别读取两个数据,将两个数据的对应元素进行相除得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0102]
指令9表示从内存(dram)的输入地址1中读取数据1,将数据1按元素除以除数得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0103]
指令10表示从内存(dram)的输入地址2中读取数据2,将被除数按元素除以数据2的各个子向量得到计算结果,计算结果保存在内存(dram)的输出内存地址中。
[0104]
指令11表示从内存(dram)的输入地址1中读取数据1,数据1中的一个元素代表一条源顶点到目标顶点的边,数据1由连续的边数据组成。将数据1按元素与输入的待归纳数据进行比较,按元素与输入的待归纳数据(即目标顶点索引)进行比较,若目标顶点与边数据匹配,则记录相应的源顶点索引,并保存到近内存计算加速器的缓存单元中。在完成对数据1存储的边数据比较后,所有匹配的源顶点索引从近内存计算加速器的缓存单元中读出,并写回内存(dram)的输出内存地址中。
[0105]
指令12表示从内存(dram)的输入地址1中读取数据1,将数据1按元素与输入的待匹配数据进行比较,统计与输入数据相匹配的数据1中的子向量的个数。在完成对数据1中的子向量的个数的比较后,统计数量写回内存(dram)的输出内存地址中。
[0106]
下面将以指令6为例详细介绍指令是如何执行的。以图神经网络领域(graph convolutional network,gcn)算法的顶点更新过程为例:
[0107][0108]
使用指令6从内存(dram)中读取顶点的特征向量与指令输入的常系数进行数乘操作得到的顶点更新特征向量并将写回内存(dram)的输出内存地址中。
[0109]
上述近内存计算指令均以简单指令为例进行说明,实际上近内存计算指令还可以是复杂指令,即,近内存计算指令可以是多个简单指令的组合,例如,聚合(gather)指令、嵌入(embedding)指令等等。
[0110]
下面详细说明如何使用上述表1所示的近内存计算指令集完成聚合(gather)指令的操作。
[0111]
以gcn算法的聚合过程为例:
[0112][0113]
其中,表示第l层顶点特征向量,表示第l+1层顶点特征向量,v代表源顶点,
u代表目标顶点,v
→
u表示v是目标顶点u的相邻顶点。
[0114]
假设目标顶点u的相邻顶点v数量较多,首先,使用指令1将保存在内存(dram)中的两个相邻的顶点特征向量读取到近内存计算加速器中,并按元素进行相加得到第一计算结果,并将第一计算结果保存在近内存计算加速器的缓存单元的输出缓存地址中。
[0115]
然后,使用多条指令2,继续从内存中逐条加载新的相邻的顶点特征向量,并与保存在近内存计算加速器的缓存单元中的计算结果按元素进行相加得到第二计算结果,并将第二计算结果保存在近内存计算加速器的缓存单元的输出缓存地址中。如此,可以重复利用近内存计算加速器的缓存单元的中间计算结果,避免每次累加操作都需要读写计算结果。
[0116]
当加载最后一个相邻顶点特征向量时,使用指令3从内存中加载最后一个相邻的顶点特征向量,并与保存在近内存计算加速器的缓存单元中的计算结果按元素进行相加得到第三计算结果,并将第三计算结果写回内存(dram)的输出内存地址中。
[0117]
假如目标顶点u只有一个相邻顶点,则直接使用指令4,将保存在内存(dram)中的相邻的顶点特征向量和目标顶点的特征向量读取到近内存计算加速器中,并按元素做加法操作得到第四计算结果,并将第四结果直接写回内存(dram)的输出内存地址中。
[0118]
在上述计算设备中,无论是数据的向量维度比较多(不论数据量比较少还是数据量比较多)时,或者,数据的量比较大(不论数据的向量维度比较少还是数据的向量维度比较多)时,加速的效果都非常好。
[0119]
下面将结合图5所示的计算设备为例,并以数据的向量维度比较长为例,对图5所示的计算设备的工作过程进行详细的介绍。
[0120]
假设计算设备中dimm的数量为m个,每个dimm中包括两个内存组,每个内存组包括4个dram,数据1的向量维度为8m,数据2的向量维度为8m。其中,
[0121]
数据1的子向量a1被存储在dimm1的内存组1的dram1中,数据1的子向量a2被存储在dimm1的内存组1的dram2中,数据1的子向量a3被存储在dimm1的内存组1的dram3中,数据1的子向量a4被存储在dimm1的内存组1的dram4中,数据1的子向量a5被存储在dimm1的内存组2的dram1中,数据1的子向量a6被存储在dimm1的内存组2的dram2中,数据1的子向量a7被存储在dimm1的内存组2的dram3中,数据1的子向量a8被存储在dimm1的内存组2的dram4中;
[0122]
数据1的子向量a9被存储在dimm2的内存组1的dram1中,数据1的子向量a
10
被存储在dimm2的内存组1的dram2中,数据1的子向量a
11
被存储在dimm2的内存组1的dram3中,数据1的子向量a
12
被存储在dimm2的内存组1的dram4中,数据1的子向量a
13
被存储在dimm2的内存组2的dram1中,数据1的子向量a
14
被存储在dimm2的内存组2的dram2中,数据1的子向量a
15
被存储在dimm2的内存组2的dram3中,数据1的子向量a
16
被存储在dimm2的内存组2的dram4中;
[0123]
…
;
[0124]
数据1的子向量a
8m-7
被存储在dimmm的内存组1的dram1中,数据1的子向量a
8m-6
被存储在dimmm的内存组1的dram2中,数据1的子向量a
8m-5
被存储在dimmm的内存组1的dram3中,数据1的子向量a
8m-4
被存储在dimmm的内存组1的dram4中,数据1的子向量a
8m-3
被存储在dimmm的内存组2的dram1中,数据1的子向量a
8m-2
被存储在dimm2的内存组2的dram2中,数据1的子向量a
8m-1
被存储在dimmm的内存组2的dram3中,数据1的子向量a
8m
被存储在dimmm的内存组2的dram4中。
[0125]
同理,数据2的子向量b1被存储在dimm1的内存组1的dram1中,数据2的子向量b2被存储在dimm1的内存组1的dram2中,数据2的子向量b3被存储在dimm1的内存组1的dram3中,数据2的子向量b4被存储在dimm1的内存组1的dram4中,数据2的子向量b5被存储在dimm1的内存组2的dram1中,数据2的子向量b6被存储在dimm1的内存组2的dram2中,数据2的子向量b7被存储在dimm1的内存组2的dram3中,数据2的子向量b8被存储在dimm1的内存组2的dram4中;
[0126]
数据2的子向量b9被存储在dimm2的内存组1的dram1中,数据2的子向量b
10
被存储在dimm2的内存组1的dram2中,数据2的子向量b
11
被存储在dimm2的内存组1的dram3中,数据2的子向量b
12
被存储在dimm2的内存组1的dram4中,数据2的子向量b
13
被存储在dimm2的内存组2的dram1中,数据2的子向量b
14
被存储在dimm2的内存组2的dram2中,数据2的子向量b
15
被存储在dimm2的内存组2的dram3中,数据2的子向量b
16
被存储在dimm2的内存组2的dram4中;
[0127]
…
;
[0128]
数据2的子向量b
8m-7
被存储在dimmm的内存组1的dram1中,数据2的子向量b
8m-6
被存储在dimmm的内存组1的dram2中,数据2的子向量b
8m-5
被存储在dimmm的内存组1的dram3中,数据2的子向量b
8m-4
被存储在dimmm的内存组1的dram4中,数据2的子向量b
8m-3
被存储在dimmm的内存组2的dram1中,数据2的子向量b
8m-2
被存储在dimm2的内存组2的dram2中,数据2的子向量b
8m-1
被存储在dimmm的内存组2的dram3中,数据2的子向量b
8m
被存储在dimmm的内存组2的dram4中。
[0129]
dimm1中的计算模块通过控制器1控制多路选择器1从内存组1中的dram1至dram4中读取数据1的子向量a1至子向量a4,以及数据2的子向量b1至子向量b4,并保存在输入单元中。dimm1中的计算模块通过控制器2控制多路选择器2从内存组2中的dram1至dram4中读取数据1的子向量a5至子向量a8,以及数据2的子向量b5至子向量b8,并保存在输入单元中。计算单元阵列将数据1的子向量a1至子向量a8,数据2的子向量b1至子向量b8分别进行计算处理,得到计算结果,并将计算结果保存在输出单元或者缓存单元中;
[0130]
dimm2中的计算模块通过控制器1控制多路选择器1从内存组1中的dram1至dram4中读取数据1的子向量a9至子向量a
12
,以及数据2的子向量b9至子向量b
12
,并保存在输入单元中。dimm2中的计算模块通过控制器2控制多路选择器2从内存组2中的dram1至dram4中读取数据1的子向量a
13
至子向量a
16
,以及数据2的子向量b
13
至子向量b
16
,并保存在输入单元中。计算单元阵列将数据1的子向量a9至子向量a
16
,数据2的子向量b9至子向量b
16
分别进行计算处理,得到计算结果,并将计算结果保存在输出单元或者缓存单元中;
[0131]
…
;
[0132]
dimmm中的计算模块通过控制器1控制多路选择器1从内存组1中的dram1至dram4中读取数据1的子向量a
m-7
至子向量a
m-4
,以及数据2的子向量b
m-7
至子向量b
m-4
,并保存在输入单元中。dimmm中的计算模块通过控制器2控制多路选择器2从内存组2中的dram1至dram4中读取数据1的子向量a
m-3
至子向量am,以及数据2的子向量b
m-3
至子向量bm,并保存在输入单元中。计算单元阵列将数据1的子向量a
m-7
至子向量am,数据2的子向量b
m-7
至子向量bm分别进行计算处理,得到计算结果,并将计算结果保存在输出单元或者缓存单元中。
[0133]
从上述实施例可以看出,在数据的向量维度比较长的情况下,可以将数据的子向量分别设置在不同的内存组中,近内存计算加速器通过多个控制器分别从多个内存组中同步读取数据的子向量并进行计算,从而起到很好的加速效果。
[0134]
下面将结合图5所示的计算设备为例,并以数据的数据量比较多为例,对图5所示的计算设备的工作过程进行详细的介绍。
[0135]
假设计算设备中dimm的数量为m个,每个dimm中包括两个内存组,每个内存组包括4个dram,数据的数量为16m。其中,
[0136]
数据1被存储在dimm1的内存组1的dram1中,数据2被存储在dimm1的内存组1的dram2中,数据3被存储在dimm1的内存组1的dram3中,数据4被存储在dimm1的内存组1的dram4中,数据5被存储在dimm1的内存组2的dram1中,数据6被存储在dimm1的内存组2的dram2中,数据7被存储在dimm1的内存组2的dram3中,数据8被存储在dimm1的内存组2的dram4中;
[0137]
数据9被存储在dimm2的内存组1的dram1中,数据10被存储在dimm2的内存组1的dram2中,数据11被存储在dimm2的内存组1的dram3中,数据12被存储在dimm2的内存组1的dram4中,数据13被存储在dimm2的内存组2的dram1中,数据14被存储在dimm2的内存组2的dram2中,数据15被存储在dimm2的内存组2的dram3中,数据16被存储在dimm2的内存组2的dram4中;
[0138]
…
;
[0139]
数据8m-7被存储在dimmm的内存组1的dram1中,数据8m-6被存储在dimmm的内存组1的dram2中,数据8m-5被存储在dimmm的内存组1的dram3中,数据8m-4被存储在dimmm的内存组1的dram4中,数据8m-3被存储在dimmm的内存组2的dram1中,数据8m-2被存储在dimm2的内存组2的dram2中,数据8m-1被存储在dimmm的内存组2的dram3中,数据8m被存储在dimmm的内存组2的dram4中;
[0140]
数据8m+1被存储在dimm1的内存组1的dram1中,数据8m+2被存储在dimm1的内存组1的dram2中,数据8m+3被存储在dimm1的内存组1的dram3中,数据8m+4被存储在dimm1的内存组1的dram4中,数据8m+5被存储在dimm1的内存组2的dram1中,数据8m+6被存储在dimm1的内存组2的dram2中,数据8m+7被存储在dimm1的内存组2的dram3中,数据8m+8被存储在dimm1的内存组2的dram4中;
[0141]
数据8m+9被存储在dimm2的内存组1的dram1中,数据8m+10被存储在dimm2的内存组1的dram2中,数据8m+11被存储在dimm2的内存组1的dram3中,数据8m+12被存储在dimm2的内存组1的dram4中,数据8m+13被存储在dimm2的内存组2的dram1中,数据8m+14被存储在dimm2的内存组2的dram2中,数据8m+15被存储在dimm2的内存组2的dram3中,数据8m+16被存储在dimm2的内存组2的dram4中;
[0142]
…
;
[0143]
数据16m-7被存储在dimmm的内存组1的dram1中,数据16m-6被存储在dimmm的内存组1的dram2中,数据16m-5被存储在dimmm的内存组1的dram3中,数据16m-4被存储在dimmm的内存组1的dram4中,数据16m-3被存储在dimmm的内存组2的dram1中,数据16m-2被存储在dimm2的内存组2的dram2中,数据16m-1被存储在dimmm的内存组2的dram3中,数据16m被存储在dimmm的内存组2的dram4中。
[0144]
dimm1中的计算模块通过控制器1控制多路选择器1从内存组1中的dram1至dram4中读取数据1至数据4,以及数据8m+1至数据8m+4,并保存在输入单元中。dimm1中的计算模块通过控制器2控制多路选择器2从内存组2中的dram1至dram4中读取数据5至数据8,以及数据8m+5至数据8m+8,并保存在输入单元中。计算单元阵列将数据1至数据8,数据8m+1至数据8m
+8分别进行计算处理,得到计算结果,并将计算结果保存在输出单元或者缓存单元中;
[0145]
dimm2中的计算模块通过控制器1控制多路选择器1从内存组1中的dram1至dram4中读取数据9至数据12,以及数据8m+9至数据8m+12,并保存在输入单元中。dimm2中的计算模块通过控制器2控制多路选择器2从内存组2中的dram1至dram4中读取数据13至数据16,以及数据8m+13至数据8m+16,并保存在输入单元中。计算单元阵列将数据9至数据16,数据8m+9至数据8m+16分别进行计算处理,得到计算结果,并将计算结果保存在输出单元或者缓存单元中;
[0146]
…
;
[0147]
dimmm中的计算模块通过控制器1控制多路选择器1从内存组1中的dram1至dram4中读取数据8m-7至数据8m-4,以及数据16m-7至数据16m-4,并保存在输入单元中。dimmm中的计算模块通过控制器2控制多路选择器2从内存组2中的dram1至dram4中读取数据8m-3至数据8m,以及数据16m-3至数据16m,并保存在输入单元中。计算单元阵列将数据8m-7至数据8m,数据16m-7至数据16m分别进行计算处理,得到计算结果,并将计算结果保存在输出单元或者缓存单元中。
[0148]
从上述实施例可以看出,在数据的数量比较多的情况下,可以将数据分别设置在不同的内存组中,近内存计算加速器通过多个控制器分别从多个内存组中同步读取数据并进行计算,从而起到很好的加速效果。
[0149]
为了便于说明本技术实施例提供的计算设备的加速效果,下面以图神经网络领域的gcn算法为例进行仿真,并通过仿真结果来观察本技术实施例提供的计算设备的加速效果。
[0150]
图神经网络领域的gcn算法可以表示为如下几个步骤:
[0151]
更新顶点:
[0152][0153]
分散:
[0154]
申请边:edge
l+1
=edge
l
;
[0155]
聚合:
[0156]
更新顶点:
[0157]
其中,聚合(gather)操作对目标顶点的相邻顶点的特征向量进行累加,更新顶点(applyvertex)操作是对顶点的特征向量进行线性变换。若将聚合(gather)操作和更新顶点(applyvertex)操作卸载到近内存计算加速器,可以极大地减少cpu与内存之间搬运的数据量。
[0158]
因此,基于模拟器搭建了计算设备的仿真测试平台,在仿真测试平台上实现并部署gcn算法中的聚合操作和更新顶点操作,以评估近内存计算加速器对gnn算法的关键函数的加速效果。
[0159]
在一具体的实施中,可以采用科拉(cora)数据集以及雷迪特(reddit)作为测试数据集测试本实施例中的计算设备采用近内存计算加速器对gcn算法中的聚合操作和更新顶点操作进行加速的加速作用的大小。其中,科拉数据集是数据量比较少的数据集,雷迪特数据集是数据量比较多的数据集。此外,通过调整gcn隐藏层的向量维度分别为16、1024来研究向量维度的大小对近内存计算加速器的加速效果的影响。因此,通过不同数据集与向量维度的组合,可以涵盖低数据量低向量维度、低数据量高向量维度、高数据量低向量维度、高数据量高向量维度四种不同的应用场景。以表2为例,科拉数据集以及雷迪特数据集可以是:
[0160]
表2测试数据集
[0161][0162][0163]
参见图7,图7是图1所示的近内存计算加速系统和图3所示的计算设备在各个场景下的加速效果的对比示意图。将表2所示的两个不同的科拉数据集以及雷迪特数据集分别采用16维的向量维度和1024维的向量维度对将图1所示的近内存计算加速系统和图3所示的计算设备的加速效果进行仿真可以得到的如图7所示的对比示意图。明显可见,在采用科拉数据集,向量维度为16时,图1所示的近内存计算加速系统和图3所示的计算设备的加速效果基本相同;在采用科拉数据集,向量维度为1024时,图3所示的计算设备的加速效果优于图1所示的近内存计算加速系统的加速效果;在采用雷迪特数据集,向量维度为16时,图3所示的计算设备的加速效果优于图1所示的近内存计算加速系统的加速效果;在采用雷迪特数据集,向量维度为1024时,图3所示的计算设备的加速效果优于图1所示的近内存计算加速系统的加速效果。所以,在数据量较多或者数据的向量维度较多时,图3所示的计算设备都能够保证比较好的加速效果。
[0164]
参见图8,图8是图3所示的计算设备分别在向量维度为16以及向量维度为1024时在不同的内存组数量下的加速效果的示意图。明显地,在向量维度为16以及向量维度为1024时,如果其他的参数都不变,只有dimm中的内存组的数量不相同,则dimm中的内存组的数量越多,计算设备的加速效果越好。
[0165]
下面将结合图3至图5所示的计算设备,对该计算设备内如何进行近内存计算进行详细的说明。参见图9,图9是本技术提供的一种近内存计算方法的流程示意图。如图9所示,本技术实施例中的近内存计算方法包括如下步骤:
[0166]
s101:通用处理器cpu向dimm中的近内存计算加速器中发送近内存计算指令。相应地,dimm中的近内存计算加速器接收cpu发送的近内存计算指令。
[0167]
在一具体的实施例中,通用处理器cpu、dimm、近内存计算加速器以及指令解码器的结构可以参见图4、图5以及相关描述,此处不在展开描述。
[0168]
在一具体的实施例中,近内存计算指令的详细内容请参见上文,此处不在展开描述。
[0169]
s102:近内存计算加速器对近内存计算指令进行解码,得到解码结果。其中,所述解码结果指示多个数据的地址以及计算类型。
[0170]
在一具体的实施例中,近内存计算加速器可以通过内部的指令解码器对近内存计算指令进行解码,得到解码结果。
[0171]
在一具体的实施例中,多个数据的地址被设置为允许近内存计算加速器进行访问,禁止cpu进行访问。
[0172]
在一具体的实施例中,计算类型为加法计算、乘法计算、除法计算、查找计算以及非线性计算中的至少一种。并且,计算类型需为近内存计算指令集支持的类型。近内存计算指令集的相关内容可以参见上文中的相关介绍。
[0173]
s103:近内存计算加速器根据所述多个数据的地址从所述多个内存块中并行获取所述多个数据。
[0174]
在一具体的实施例中,内存块可以是cpu以及近内存计算加速器均可以访问的,也可以是,近内存计算加速器允许访问,而,cpu禁止访问的。
[0175]
s104:近内存计算加速器根据所述计算类型对所述多个数据执行计算。
[0176]
在一具体的实施例中,近内存计算加速器可以先确定计算类型是加法计算、减法计算、乘法计算以及除法计算中的任意一种。当计算类型是加法计算时,再确定其子计算类型是(从内存读,写回缓存)、(从缓存读,写回缓存)、(从缓存读,写回内存)、(从内存读,写回内存)中的任意一种。当计算类型是乘法计算时,再确定其子计算类型是向量对应元素积、向量数乘、向量内积等等子计算类型中的一种或者多种。当计算类型是为除法时,再确定其子计算类型是向量对应元素相除、向量按元素除以常数、常数按元素除以向量中的任意一种。当计算类型为查找计算时,再确定其子计算类型是归纳和匹配中的任意一种。如果计算类型是加法计算、减法计算、乘法计算以及除法计算中的任意一种时,还需要确定是否需要对计算结果进行非线性计算。
[0177]
为了简便起见,本实施例中的近内存计算方法并没有进行详细的介绍,具体请参见图3-图8以及相关描述。
[0178]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本技术实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、存储盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态存储盘solid state disk(ssd))等。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1