一种敏感数据接口爬虫识别方法及装置与流程
1.本发明涉及爬虫识别领域,更具体涉及一种敏感数据接口爬虫识别方法及装置。
背景技术:
2.现有技术中,可以通过网络爬虫等手段来获取网络中的数据,按照一定的规则,自动地抓紧去网站信息的程序或者脚本。现有技术大部分是针对爬虫的拦截,但爬虫还是可以通过改变程序或者模拟真实用户的行为进行绕过,尤其是网站的接口存在一定有价值的敏感信息。
3.现有技术爬虫识别方法可以大致归为两类,其中一类为专家规则引擎方案,通过对业务日志采集数据,并配置单个或多个属性的事件进行数量累加,通过阈值类规则对超过阈值的事件进行拦截;或通过属性、ip、useragent等属性采集的黑名单进行拦截。由于技术逐渐提升,黑产使用模拟器,特殊软件进行风控规则引擎试探并绕过,难以持续保证网站信息安全,尤其是网站的接口存在一定有价值的敏感信息的情况下,更加难以维持网站的信息安全。
4.另一类是基于用户行为序列的异常检测识别爬虫方案,通过构建用户访问行为路径,使用概率模型等技术方案计算行为路径概率,使用无监督学习方法输出异常的用户及相关用户的访问路径。但该技术方案存在大量的误报,人工二次分析的工作量更加大和复杂,导致难以维持存在敏感信息的网站接口的信息安全。
5.中国专利授权公告号cn108712426b,公开了一种基于用户行为埋点的爬虫识别方法及系统,其中方法包括:s1、客户端接收用户发起的访问请求,并将访问请求向后端服务系统异步发送;s2、后端服务系统在接收到访问请求后,同步用户的访问日志,访问日志包括用户的访问行为数据;s3、后端服务系统通过规则引擎聚合访问行为数据;s4、后端服务系统根据聚合后的访问行为数据判断用户是否属于爬虫,若是则根据访问日志聚合出用于标识用户为爬虫的爬虫特征数据,然后将爬虫特征数据通过消息队列异步推送至所述客户端中的爬虫列表;s5、客户端根据爬虫列表响应访问请求。该发明通过同步访问日志,并聚合日志中的访问行为数据后识别爬虫,提高爬虫识别率和准确。但是并不是所有的爬虫都需要拦截,该方案只是对爬虫进行识别,并不能识别具有敏感数据的爬虫。
6.综上所述,现有技术大部分是针对爬虫的拦截,不能识别具有敏感数据的爬虫,从而导致难以保证网络信息安全。
技术实现要素:
7.本发明所要解决的技术问题在于现有技术缺乏对具有敏感信息的接口进行爬虫识别的方法。
8.本发明通过以下技术手段实现解决上述技术问题的:一种敏感数据接口爬虫识别方法,所述方法包括以下步骤:
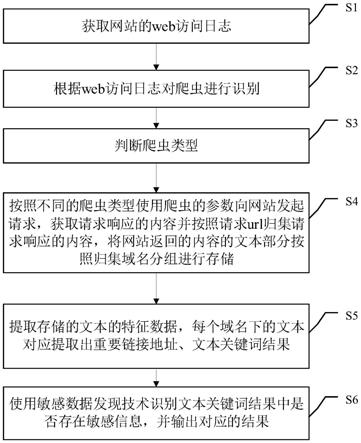
9.步骤一:获取网站的web访问日志;
10.步骤二:根据web访问日志对爬虫进行识别;
11.步骤三:判断爬虫类型;
12.步骤四:按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储;
13.步骤五:提取存储的文本的特征数据,每个域名下的文本对应提取出重要链接地址、文本关键词结果;
14.步骤六:使用敏感数据发现技术识别文本关键词结果中是否存在敏感信息,并输出对应的结果。
15.本发明按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储,使用敏感数据发现技术识别文本关键词结果中是否敏感信息,输出是否涉敏,涉敏数据类型,从而对爬虫动机进行有效识别,识别出涉及敏感信息的爬虫行为,保障网络信息安全。
16.进一步地,所述web访问日志包括请求的时间、ip地址、用户身份信息、sessionid、requestbody、responbody、method、status,用户身份信息包括账号、cookie、uuid。
17.进一步地,所述步骤二中采用基于用户行为序列的异常检测方法或者规则引擎方法识别爬虫。
18.进一步地,所述步骤三中爬虫类型包括修改url中的参数进行页面切换或者相同url通过修改post内容请求传不同参数进行页面切换。
19.更进一步地,所述步骤四包括:
20.步骤401:按照不同的爬虫类型使用爬虫的参数向网站发起request请求,请求中包含额外的headers信息,从而进行爬虫请求模拟;
21.步骤402:对爬虫访问的网站进行页面解析,获取网站页面返回的信息,得到请求响应的内容;
22.步骤403:按照请求url归集请求响应的内容,如果是通过修改url中的参数进行页面切换模式的爬虫地址,则保留爬虫地址的非参数部分,作为归集域名,如果通过修改post内容请求传不同参数进行页面切换模式的爬虫地址,直接使用爬虫地址的域名作为归集域名;将网站返回的多个文本部分按照归集域名分组进行存储。
23.进一步地,所述步骤五包括:
24.通过公式
[0025][0026]
计算词语频率,提取存储的文本中词语频率超过阈值的词语作为特征数据,每个域名下的文本按照词语频率对应提取出重要链接地址、文本关键词结果;其中,n
i,j
表示词语t
i
在文本j中出现的次数,表示文本j中所有词语频词和,表示语料库中所有词语频数之和,nt
i
表示词语t
i
在语料库中出现的总频数。
[0027]
进一步地,所述敏感信息包括手机号码、姓名、地址、车牌号、身份证号码。
[0028]
进一步地,所述敏感数据接口爬虫识别方法还包括步骤七:
[0029]
对步骤六识别出的具有敏感数据接口的爬虫统计url归集请求数量、访问速率、请求ip地址个数、ip访问url数量、请求useragent个数、返回200数量、访问referer数量、访问method类型、url涉敏感数据类型,根据统计结果输出爬虫风险等级以及攻击类型。
[0030]
本发明还提供一种敏感数据接口爬虫识别装置,所述装置包括:
[0031]
日志获取模块,用于获取网站的web访问日志;
[0032]
爬虫识别模块,用于根据web访问日志对爬虫进行识别;
[0033]
判断模块,用于判断爬虫类型;
[0034]
爬虫请求模拟模块,用于按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储;
[0035]
特征提取模块,用于提取存储的文本的特征数据,每个域名下的文本对应提取出重要链接地址、文本关键词结果;
[0036]
涉敏判断模块,用于使用敏感数据发现技术识别文本关键词结果中是否存在敏感信息,并输出对应的结果。
[0037]
进一步地,所述web访问日志包括请求的时间、ip地址、用户身份信息、sessionid、requestbody、responbody、method、status,用户身份信息包括账号、cookie、uuid。
[0038]
进一步地,所述爬虫识别模块中采用基于用户行为序列的异常检测方法或者规则引擎方法识别爬虫。
[0039]
进一步地,所述判断模块中爬虫类型包括修改url中的参数进行页面切换或者相同url通过修改post内容请求传不同参数进行页面切换。
[0040]
更进一步地,所述爬虫请求模拟模块包括:
[0041]
请求模拟单元,用于按照不同的爬虫类型使用爬虫的参数向网站发起request请求,请求中包含额外的headers信息,从而进行爬虫请求模拟;
[0042]
请求响应单元,用于对爬虫访问的网站进行页面解析,获取网站页面返回的信息,得到请求响应的内容;
[0043]
分组存储单元,用于按照请求url归集请求响应的内容,如果是通过修改url中的参数进行页面切换模式的爬虫地址,则保留爬虫地址的非参数部分,作为归集域名,如果通过修改post内容请求传不同参数进行页面切换模式的爬虫地址,直接使用爬虫地址的域名作为归集域名;将网站返回的多个文本部分按照归集域名分组进行存储。
[0044]
进一步地,所述特征提取模块还用于:
[0045]
通过公式
[0046][0047]
计算词语频率,提取存储的文本中词语频率超过阈值的词语作为特征数据,每个域名下的文本按照词语频率对应提取出重要链接地址、文本关键词结果;其中,n
i,j
表示词
语t
i
在文本j中出现的次数,表示文本j中所有词语频词和,表示语料库中所有词语频数之和,nt
i
表示词语t
i
在语料库中出现的总频数。
[0048]
进一步地,所述敏感信息包括手机号码、姓名、地址、车牌号、身份证号码。
[0049]
进一步地,所述敏感数据接口爬虫识别装置还包括统计模块,用于对涉敏判断模块识别出的具有敏感数据接口的爬虫统计url归集请求数量、访问速率、请求ip地址个数、ip访问url数量、请求useragent个数、返回200数量、访问referer数量、访问method类型、url涉敏感数据类型,根据统计结果输出爬虫风险等级以及攻击类型。
[0050]
本发明的优点在于:本发明按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储,使用敏感数据发现技术识别文本关键词结果中是否敏感信息,输出是否涉敏,涉敏数据类型,从而对爬虫动机进行有效识别,识别出涉及敏感信息的爬虫行为,保障网络信息安全。
附图说明
[0051]
图1为本发明实施例所公开的一种敏感数据接口爬虫识别方法的流程图。
具体实施方式
[0052]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0053]
实施例1
[0054]
一种敏感数据接口爬虫识别方法,所述方法包括以下步骤:
[0055]
s1:获取网站的web访问日志;所述web访问日志包括请求的时间、ip地址、用户身份信息、sessionid、requestbody、responbody、method、status,用户身份信息包括账号、cookie、uuid。
[0056]
s2:根据web访问日志对爬虫进行识别;本实施例中采用现有技术进行爬虫识别,这个爬虫识别过程不涉及敏感信息的识别,可以采用现有任何成熟的能够进行爬虫识别的技术,具体是采用基于用户行为序列的异常检测方法或者规则引擎方法识别爬虫,例如背景技术中列举的专利文献公开的方案。
[0057]
s3:判断爬虫类型;爬虫类型包括修改url中的参数进行页面切换或者相同url通过修改post内容请求传不同参数进行页面切换。如地址为http://www.xxx.com.cn/service/api/getmoreinfo.action?project_id=ab922d56d&id=b7fb6e72ddcdb4&startid=4c8dsd4147148。通过修改url的参数project,id,startid的值来切换访问的域名,实现不同页面的切换,从而在不断尝试更改url的参数project,id,startid的值的过程中获得不同页面的信息,这些信息就有可能存在敏感信息。如地址http://www.xxx.com.cn/login/,在请求中,通过修改post参数{
‘
account_name’:’123456789’}来收集来自不通account_name的返回结果,比如某用户的账号是手机号,但是不同软件登录
密码可能不同,通过修改post参数(本具体实例中post参数为密码),不断尝试,则会获取该用户在不同软件上的信息。
[0058]
s4:按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储;具体过程为:
[0059]
步骤401:按照不同的爬虫类型使用爬虫的参数向网站发起request请求,请求中包含额外的headers信息,从而进行爬虫请求模拟;
[0060]
步骤402:对爬虫访问的网站进行页面解析,获取网站页面返回的信息,类型包括html,json字符串,二进制数据(如图片视频)等类型,从而得到请求响应的内容;
[0061]
步骤403:按照请求url归集请求响应的内容,如果是通过修改url中的参数进行页面切换模式的爬虫地址,则保留爬虫地址的非参数部分,作为归集域名,如果通过修改post内容请求传不同参数进行页面切换模式的爬虫地址,直接使用爬虫地址的域名作为归集域名;将网站返回的多个文本部分按照归集域名分组进行存储。
[0062]
s5:提取存储的文本的特征数据,每个域名下的文本对应提取出重要链接地址、文本关键词结果;
[0063]
传统方法tf
‑
idf所求的权值一般很小接近0,精确度也不是很高,在本质上idf是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。idf的简单结构并不能使提取的关键词,十分有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被掩盖。例如:语料库d中教育类文章偏多,而文本j是一篇属于教育类的文章,那么教育类相关的词语的idf值将会偏小,使提取文本关键词的召回率更低,导致关键词提取结果不准确。本发明在此基础上,提出词语逆频率方式计算加权算法,即
[0064]
通过公式
[0065][0066]
计算词语频率,提取存储的文本中词语频率超过阈值的词语作为特征数据,每个域名下的文本按照词语频率对应提取出重要链接地址、文本关键词结果;其中,n
i,j
表示词语t
i
在文本j中出现的次数,表示文本j中所有词语频词和,表示语料库中所有词语频数之和,nt
i
表示词语t
i
在语料库中出现的总频数。
[0067]
本发明这种加权方法降低了语料库中同类型文本对词语权重的影响,更加精确地表达了这个词语在待查文档中的重要程度。公式的计算结果刚好能解决最后权值过小的问题,实际应用中,保留6位有效数字,使得计算结果更加精确。
[0068]
s6:使用敏感数据发现技术识别文本关键词结果中是否存在敏感信息,并输出对应的结果。所述敏感信息包括手机号码、姓名、地址、车牌号、身份证号码。
[0069]
作为本发明进一步地改进,所述敏感数据接口爬虫识别方法还包括s7:
[0070]
对s6识别出的具有敏感数据接口的爬虫统计url归集请求数量、访问速率、请求ip
地址个数、ip访问url数量、请求useragent个数、返回200数量、访问referer数量、访问method类型、url涉敏感数据类型,根据统计结果输出爬虫风险等级以及攻击类型,具体的爬虫风险等级可以根据实际需要选择一个或者多个指标进行判断,例如,可以选择url归集请求数量、访问速率、返回200数量这三个指标,对于url归集请求数量超过第一预设值、访问速率超过第二预设值以及返回200数量超过第三预设值的爬虫归为高风险。
[0071]
通过以上技术方案,本发明按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储,使用敏感数据发现技术识别文本关键词结果中是否敏感信息,输出是否涉敏,涉敏数据类型,从而对爬虫动机进行有效识别,识别出涉及敏感信息的爬虫行为,保障网络信息安全。
[0072]
实施例2
[0073]
基于实施例1,本发明实施例2还提供一种敏感数据接口爬虫识别装置,所述装置包括:
[0074]
日志获取模块,用于获取网站的web访问日志;
[0075]
爬虫识别模块,用于根据web访问日志对爬虫进行识别;
[0076]
判断模块,用于判断爬虫类型;
[0077]
爬虫请求模拟模块,用于按照不同的爬虫类型使用爬虫的参数向网站发起请求,获取请求响应的内容并按照请求url归集请求响应的内容,将网站返回的内容的文本部分按照归集域名分组进行存储;
[0078]
特征提取模块,用于提取存储的文本的特征数据,每个域名下的文本对应提取出重要链接地址、文本关键词结果;
[0079]
涉敏判断模块,用于使用敏感数据发现技术识别文本关键词结果中是否存在敏感信息,并输出对应的结果。
[0080]
具体的,所述web访问日志包括请求的时间、ip地址、用户身份信息、sessionid、requestbody、responbody、method、status,用户身份信息包括账号、cookie、uuid。
[0081]
具体的,所述爬虫识别模块中采用基于用户行为序列的异常检测方法或者规则引擎方法识别爬虫。
[0082]
具体的,所述判断模块中爬虫类型包括修改url中的参数进行页面切换或者相同url通过修改post内容请求传不同参数进行页面切换。
[0083]
更具体的,所述爬虫请求模拟模块包括:
[0084]
请求模拟单元,用于按照不同的爬虫类型使用爬虫的参数向网站发起request请求,请求中包含额外的headers信息,从而进行爬虫请求模拟;
[0085]
请求响应单元,用于对爬虫访问的网站进行页面解析,获取网站页面返回的信息,得到请求响应的内容;
[0086]
分组存储单元,用于按照请求url归集请求响应的内容,如果是通过修改url中的参数进行页面切换模式的爬虫地址,则保留爬虫地址的非参数部分,作为归集域名,如果通过修改post内容请求传不同参数进行页面切换模式的爬虫地址,直接使用爬虫地址的域名作为归集域名;将网站返回的多个文本部分按照归集域名分组进行存储。
[0087]
具体的,所述特征提取模块还用于:
[0088]
通过公式
[0089][0090]
计算词语频率,提取存储的文本中词语频率超过阈值的词语作为特征数据,每个域名下的文本按照词语频率对应提取出重要链接地址、文本关键词结果;其中,n
i,j
表示词语t
i
在文本j中出现的次数,表示文本j中所有词语频词和,表示语料库中所有词语频数之和,nt
i
表示词语t
i
在语料库中出现的总频数。
[0091]
具体的,所述敏感信息包括手机号码、姓名、地址、车牌号、身份证号码。
[0092]
具体的,所述敏感数据接口爬虫识别装置还包括统计模块,用于对涉敏判断模块别出的具有敏感数据接口的爬虫统计url归集请求数量、访问速率、请求ip地址个数、ip访问url数量、请求useragent个数、返回200数量、访问referer数量、访问method类型、url涉敏感数据类型,根据统计结果输出爬虫风险等级以及攻击类型。
[0093]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1