一种基于端侧深度学习的手机全景拍摄与合成方法
1.本发明涉及虚拟现实技术领域,更确切地说,涉及一种基于端侧深度学习的手机全景拍摄与合成方法。
背景技术:
2.虚拟现实(vr)发展到今天,其主要是指360
°
视频,也称为全景视频。vr相结合,是未来vr的发展趋势。其应用很广泛,比如体育赛事、综艺节目、新闻现场、教育医疗、游戏电竞等。与此同时,端测推理引擎的出现能够让深度学习模型直接部署在手机上,使得通过手机来进行实时全景拍摄与合成成为可能,那么将vr带来的沉浸式体验与手机拍摄的低成本、低门槛相结合则成为目前研究的重点。
3.《一种用于vr全景直播的动态图像融合方法及系统》中提到,就目前而言,全景视频采集所用的都是专业的全景摄像机。不仅需要固定的架设位置且专业全景摄像机价格昂贵,导致全景拍摄的门槛较高。手机作为一种普及的电子产品,可以随时随地进行拍摄。然而手机前后摄像头参数不同,因此采集的图像数据会存在亮度不同,分辨率不同,色彩饱和度不同等问题导致拍摄的两幅图像具有一定的差异性,从而在拼接过程中将会引起伪影现象,而伪影的存在将极大的破坏用户视觉上的体验感。并且手机端镜头虽然有超广角模式,但目前手机前后摄拼接后拍摄范围仍然不足以覆盖360
°
全景,拼接画面中存在内容缺失。因此如何降低用户对拍摄设备的要求,又能获得完美的视觉感受和体验,也就成为了本领域内技术人员亟待解决的问题。
技术实现要素:
4.本发明正是为了解决上述技术问题而设计的一种基于端侧深度学习的手机全景拍摄与合成方法,利用端侧神经网络模型,对手机的前、后摄像头拍摄的图像进行拼接并对缺失的全景内容进行补全,实现了vr实时拍摄与合成的自由化和简单化。
5.本发明解决其技术问题所采用的技术方案是:
6.一种基于端侧深度学习的手机全景拍摄与合成方法,基于手机前后摄像头同时实时拍摄的视频图像,将各时间点下手机前、后摄像头同时拍摄的两原始图像按如下步骤执行,实现手机拍摄全景视频的获得:
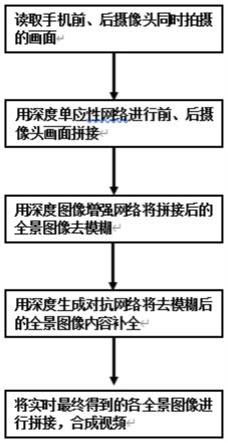
7.步骤1:读取手机前、后摄像头同时拍摄的两原始图像,进入步骤2;
8.步骤2:使用深度单应性网络对手机前、后摄像头同时拍摄的两原始图像以两幅图像之间对应全景场景所缺失的部分作为孔洞区域,实现两原始图像彼此尺寸对应的拼接处理,得到带有孔洞的全景拼接图像,进入步骤3;
9.步骤3:使用深度图像增强网络对带有孔洞的全景拼接图像进行去模糊处理,得到带有孔洞的去模糊全景拼接图像,进入步骤4;
10.步骤4:使用深度生成对抗网络将带有孔洞的去模糊全景拼接图像中孔洞部分进行补全,获得该时间点下手机拍摄的全景图像,进入步骤5;
11.步骤5:将获得的各时间点下手机拍摄的全景图像进行图像拼接,实现手机拍摄全景视频的获得。
12.作为本发明的一种优选技术方案,所述步骤2中得到带有孔洞的全景拼接图像,执行的步骤如下:
13.步骤2.1:训练深度单应性网络;
14.步骤2.2:以手机前、后摄像头同时拍摄的两原始图像分别对应的两灰度图像作为输入,经训练好的深度单应性网络,输出表示两原始图像拼接前后映射关系的单应性矩阵;
15.步骤2.3:根据单应性矩阵提供的映射关系对手机前、后摄像头同时拍摄的两原始图像以两幅图像之间对应全景场景所缺失的部分作为孔洞区域,实现两原始图像彼此尺寸对应的拼接处理,得到带有孔洞的全景拼接图像。
16.作为本发明的一种优选技术方案,所述深度单应性网络为通过4个卷积层和2个完全连接层连接,每个卷积层卷积核的个数依次为6、6、16、16,卷积核的大小为3x3,步长为1,填充方式为按0填充,激活函数采用relu函数。
17.作为本发明的一种优选技术方案,训练深度单应性网络的损失函数l1为:
[0018][0019]
式中,f
s
为待对比拼接方法后带有孔洞的全景拼接图像,f
l
为同一时间点下手机前摄像头拍摄的原始图像,f
r
为同一时间点下手机后摄像头拍摄的原始图像,n为训练深度单应性网络的数据集的样本总数,n为训练深度单应性网络的数据集的样本中第n个样本。
[0020]
作为本发明的一种优选技术方案,所述步骤3中得到带有孔洞的去模糊全景拼接图像,执行的步骤如下:
[0021]
步骤3.1:训练深度图像增强网络;
[0022]
步骤3.2:以带有孔洞的全景拼接图像作为输入,经训练好的深度单应性网络,输出一个3*3的滤波器;
[0023]
步骤3.3:使用3*3的滤波器对带有孔洞的全景拼接图像进行滤波去模糊,得到带有孔洞的去模糊全景拼接图像。
[0024]
作为本发明的一种优选技术方案,所述深度图像增强网络为通过8个卷积层和1个完全连接层连接,每个卷积层卷积核的个数依次为8、8、36、36,卷积核的大小为3x3,步长为2,填充方式为按0填充,激活函数采用relu函数。
[0025]
作为本发明的一种优选技术方案,训练深度图像增强网络的损失函数l2为:
[0026][0027]
式中,f为待对比方法增强后的图像,f
′
为深度图像网络增强后的图像,t为训练深度图像增强网络的数据集的样本总数,t为训练深度图像增强网络的数据集的样本中第t个样本。
[0028]
作为本发明的一种优选技术方案,所述步骤4中获得该时间点下手机拍摄的全景图像,执行步骤如下:
[0029]
步骤4.1:训练深度生成对抗网络;
[0030]
步骤4.2:以带有孔洞的去模糊全景拼接图像作为输入,经训练好的深度单应性网络,将带有孔洞的去模糊全景拼接图像中孔洞部分进行补全,获得该时间点下手机拍摄的全景图像。
[0031]
作为本发明的一种优选技术方案,所述深度生成对抗网络包括生成对抗网络、判别器网络,所述生成对抗网络为通过4个卷积层进行连接,第一个卷积层由1024个4x4大小的卷积核构成,第二个卷积层由512个8x8大小的卷积核构成,第三个卷积层由256个16x16大小的卷积核构成,第四个卷积层由3个64x64大小的卷积核构成,卷积填充方式为按0填充,激活函数采用relu函数;
[0032]
判别器网络为通过4个卷积层和1个完全连接层连接,每个卷积层卷积核的个数依次为8、8、36、36,卷积核的大小为3x3,步长为2,填充方式为按0填充,激活函数采用relu函数。
[0033]
作为本发明的一种优选技术方案,训练深度生成对抗网络的损失函数l
loss
有两部分构成,即对抗网络损失函数l
adv
和感知损失函数l
c
,
[0034]
对抗网络损失函数l
adv
为:
[0035][0036]
式中,λ固定取值为10,z为输入的噪声,x为专业全景相机拍摄出的图像,为在z和x之间随机插值取样,g()为生成器、d()为判别器、pz(z)表示噪声z的数据分布,pdata(x)表示图像x的数据分布;
[0037]
感知损失函数l
c
为:
[0038][0039]
式中,使用imagenet进行预训练vgg19,是在vgg19网络中第i个最大池化层之前的第j个卷积获得的特征图,w
i,j
是在vgg19网络中第i个最大池化层之前的第j个卷积获得的特征图的宽,h
i,j
是在vgg19网络中第i个最大池化层之前的第j个卷积获得的特征图的高,i
b
是有孔洞的全景拼接图像,i
s
是由专业的全景相机获取的清晰图像,a指代vgg19网络中第i个最大池化层之前的第j个卷积获得的各个特征图对应的各个宽,b指代vgg19网络中第i个最大池化层之前的第j个卷积获得的各个特征图对应的各个高;
[0040]
深度生成对抗网络的损失函数l
loss
为:
[0041]
l
loss
=l
adv
+βl
c
[0042]
式中,β为超参数,取1*10
‑3。
[0043]
本发明的有益效果是:本发明提出的一种基于端侧深度学习的手机全景拍摄与合成方法,降低了vr拍摄与合成的门槛,每个用户使用手机即可进行vr全景拍摄。本发明主要利用基于端侧推理框架与深度神经网络模型对手机前后摄拍摄内容进行图像拼接、图像增强去模糊以及图像内容补全,还原最真实的拍摄与合成场景,不仅能够扩大拍摄的视野范围,观察视角也能改变,给用户一种临场感,并且无需任何专业的全景拍摄设备,随时随地打开手机就可以进行拍摄。
附图说明
[0044]
图1为本发明的全景拍摄与合成流程图;
[0045]
图2为本发明的全景拍摄与合成框架图。
具体实施方式
[0046]
以下结合附图对本发明进行进一步说明。
[0047]
一种基于端侧深度学习的手机全景拍摄与合成方法,基于手机前后摄像头同时实时拍摄的视频图像,将各时间点下手机前、后摄像头同时拍摄的两原始图像按如下步骤执行,如需要可采用安装鱼眼镜头协助拍摄,如图1所示,实现手机拍摄全景视频的获得的过程如下:
[0048]
步骤1:读取手机前、后摄像头同时拍摄的两原始图像,进入步骤2;
[0049]
当前、后摄像头拍摄两组视频图像存在帧数不同时,将帧数少的一组视频图像相对于另一组视频图像缺少的帧数平均分配在现有的各帧数之间,由该缺少帧数前面的一帧或者后面的一帧作为该帧进行替补,继续完成以下操作。
[0050]
步骤2:使用深度单应性网络对手机前、后摄像头同时拍摄的两原始图像以两幅图像之间对应全景场景所缺失的部分作为孔洞区域,实现两原始图像彼此尺寸对应的拼接处理,得到带有孔洞的全景拼接图像,进入步骤3;
[0051]
所述步骤2中得到带有孔洞的全景拼接图像,确定各组能反映两图像间拼接前后映射关系对应的的各样本构成的数据集,执行的步骤如下:
[0052]
步骤2.1:训练深度单应性网络;
[0053]
步骤2.2:以手机前、后摄像头同时拍摄的两原始图像分别对应的两灰度图像作为输入,经训练好的深度单应性网络,输出表示两原始图像拼接前后映射关系的单应性矩阵;
[0054]
将原始图像的rgb图像三通道的值进行平均,3个通道(rgb)转换成1个通道,得到该图像的灰度图像。
[0055]
步骤2.3:根据单应性矩阵提供的映射关系对手机前、后摄像头同时拍摄的两原始图像以两幅图像之间对应全景场景所缺失的部分作为孔洞区域,实现两原始图像彼此尺寸对应的拼接处理,得到带有孔洞的全景拼接图像。
[0056]
所述深度单应性网络为通过4个卷积层和2个完全连接层连接,每个卷积层卷积核的个数依次为6、6、16、16,卷积核的大小为3x3,步长为1,填充方式为按0填充,激活函数采用relu函数。以两幅堆叠的灰度图像作为输入,产生一个8自由度的单应性,用于将像素从第一幅图像映射到第二幅图像。在图像拼接时,通过深度单应性网络,输出对应单应性矩阵,单应性矩阵为前后摄画面与拼接画面的映射关系。
[0057]
根据单应性矩阵提供的映射关系进行前后摄画面拼接,生成初始全景拼接画面。
[0058]
作为本发明的一种优选技术方案,训练深度单应性网络的损失函数l1为:
[0059][0060]
式中,f
s
为待对比拼接方法后带有孔洞的全景拼接图像,f
l
为同一时间点下手机前摄像头拍摄的原始图像,f
r
为同一时间点下手机后摄像头拍摄的原始图像,n为训练深度单
应性网络的数据集的样本总数,n为训练深度单应性网络的数据集的样本中第n个样本。
[0061]
步骤3:使用深度图像增强网络对带有孔洞的全景拼接图像进行去模糊处理,得到带有孔洞的去模糊全景拼接图像,进入步骤4;
[0062]
所述步骤3中得到带有孔洞的去模糊全景拼接图像,确定图像去模糊增强对应的的深度图像增强网络的数据集,执行的步骤如下:
[0063]
步骤3.1:训练深度图像增强网络;
[0064]
步骤3.2:以带有孔洞的全景拼接图像作为输入,经训练好的深度单应性网络,输出一个3*3的滤波器;
[0065]
步骤3.3:使用3*3的滤波器对带有孔洞的全景拼接图像进行滤波去模糊,得到带有孔洞的去模糊全景拼接图像。使去模糊全景拼接图像画面增强。
[0066]
所述深度图像增强网络为通过8个卷积层和1个完全连接层连接,每个卷积层卷积核的个数依次为8、8、36、36,卷积核的大小为3x3,步长为2,填充方式为按0填充,激活函数采用relu函数。
[0067]
训练深度图像增强网络的损失函数l2为:
[0068][0069]
式中,f为待对比方法增强后的图像,f
′
为深度图像网络增强后的图像,t为训练深度图像增强网络的数据集的样本总数,t为训练深度图像增强网络的数据集的样本中第t个样本。
[0070]
步骤4:使用深度生成对抗网络将带有孔洞的去模糊全景拼接图像中孔洞部分进行补全,获得该时间点下手机拍摄的全景图像,进入步骤5;
[0071]
所述步骤4中获得该时间点下手机拍摄的全景图像,确定图像恢复补全对应的的深度生成对抗网络的数据集,执行步骤如下:
[0072]
步骤4.1:训练深度生成对抗网络;
[0073]
步骤4.2:以带有孔洞的去模糊全景拼接图像作为输入,经训练好的深度单应性网络,将带有孔洞的去模糊全景拼接图像中孔洞部分进行补全,获得该时间点下手机拍摄的全景图像。
[0074]
该方法通过训练完毕的生成器模型对图像的缺失区域进行补全,生成器利用孔洞周围像素对缺失部分进行填充。使得补全后的全景图像呈现自然。如以下两文献所涉及该技术。
[0075]
(1)junbo zhao,michael mathieu,ross goroshin,etal.stacke what
‑
whereauto
‑
encoders[j].computer science,2015,15(1):3563
‑
3593.
[0076]
(2)chao yang,xin lu,zhe lin,et al.high resolution image inpainting using multi
‑
scaleneural patch synthesis[c].proceedings of ieee conference on computer vision and pattern recognition,honolulu,jul 21
‑
26,2017.piscataway:ieee press,2017:6721
‑
6729.
[0077]
所述深度生成对抗网络包括生成对抗网络、判别器网络,所述生成对抗网络为通过4个卷积层进行连接,第一个卷积层由1024个4x4大小的卷积核构成,第二个卷积层由512
个8x8大小的卷积核构成,第三个卷积层由256个16x16大小的卷积核构成,第四个卷积层由3个64x64大小的卷积核构成,卷积填充方式为按0填充,激活函数采用relu函数;
[0078]
判别器网络为通过4个卷积层和1个完全连接层连接,每个卷积层卷积核的个数依次为8、8、36、36,卷积核的大小为3x3,步长为2,填充方式为按0填充,激活函数采用relu函数。
[0079]
训练深度生成对抗网络的损失函数l
loss
有两部分构成,即对抗网络损失函数l
adv
和感知损失函数l
c
,
[0080]
为使训练过程更好的收敛,采用的是wgan
‑
gp中的对抗网络损失,对每个样本独立的施加梯度惩罚,对抗网络损失函数l
adv
为:
[0081][0082]
式中,λ固定取值为10,z为输入的噪声,x为专业全景相机拍摄出的图像,为在z和x之间随机插值取样,g()为生成器、d()为判别器、pz(z)表示噪声z的数据分布,pdata(x)表示图像x的数据分布;
[0083]
感知损失函数l
c
为:
[0084][0085]
采用感知损失来帮助恢复图像内容,感知损失是基于生成和目标图像特征映射的差异。
[0086]
式中,使用imagenet进行预训练vgg19,是在vgg19网络中第i个最大池化层之前的第j个卷积获得的特征图,w
i,j
是在vgg19网络中第i个最大池化层之前的第j个卷积获得的特征图的宽,h
i,j
是在vgg19网络中第i个最大池化层之前的第j个卷积获得的特征图的高,i
b
是有孔洞的全景拼接图像,i
s
是由专业的全景相机获取的清晰图像,a指代vgg19网络中第i个最大池化层之前的第j个卷积获得的各个特征图对应的各个宽,b指代vgg19网络中第i个最大池化层之前的第j个卷积获得的各个特征图对应的各个高;
[0087]
深度生成对抗网络的损失函数l
loss
为:
[0088]
l
loss
=l
adv
+βl
c
[0089]
式中,β为超参数,取1*10
‑3。
[0090]
步骤5:将获得的各时间点下手机拍摄的全景图像进行图像拼接,实现手机拍摄全景视频的获得。
[0091]
如图2所示为本发明的全景拍摄与合成框架图。
[0092]
上述技术方案所设计的一种基于端侧深度学习的手机全景拍摄与合成方法,降低了vr拍摄与合成的门槛,每个用户使用手机即可进行vr全景拍摄。本发明主要利用基于端侧推理框架与深度神经网络模型对手机前后摄拍摄内容进行图像拼接、图像增强去模糊以及图像内容补全,还原最真实的拍摄与合成场景,不仅能够扩大拍摄的视野范围,观察视角也能改变,给用户一种临场感,并且无需任何专业的全景拍摄设备,随时随地打开手机就可以进行拍摄。
[0093]
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下
做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1