跨场景识别模型训练方法、跨场景道路识别方法以及装置
1.本发明涉及人工智能、信息处理技术、自动驾驶技术领域,具体涉及一种跨场景识别模型训练方法、跨场景道路识别方法以及装置。
背景技术:
2.近年来,基于图像识别的人工智能技术在自动驾驶领域发挥着越来越大的作用。基于深度神经网络的道路识别方法,在大量标签的城市街道图像数据进行有监督训练,为自动驾驶提供了高性能的道路识别模型,极大的推进了自动驾驶的技术发展。
3.在一种具体基于深度神经网络道路识别算法中,往往基于具有标签信息的城市道路或者高速道路大量图片作为样本,输入卷积神经网络对其进行特征提取,得到图像中的每个像素点为道路区域的概率,根据输出概率作为道路识别区域的判定标准。例如,专利号为cn107808140 b的发明“一种基于图像融合的单目视觉道路识别算法”中提出的基于标签样本有监督训练所得深度神经网络模型完成对道路的识别。该种方式需要大量的有标签图像数据,成本高、效率低,且所训练模型使用的训练数据集和验证数据集需要服从独立同分布设定,当实际输入不满足独立同分布设定时,即新场景下的道路识别性能往往会很差。专利号为cn106558058的发明“分割模型训练方法_道路分割方法_车辆控制方法及装置”中所提出的分割模型新联方法则是采用无监督“自由区域分割方法”对训练样本进行自由区域分割,所得到的分割图像作为训练图像的标签信息完成对模型的训练,即基于伪标签进行训练。该方面中所提方法“自由区域分割方法”无法保证所输出分割图像作为伪标签的准确性进而会导致其分割模型的无法完成预期训练。
4.此外,智能驾驶系统对各种场景下的道路都应具备有效识别的能力,例如,场景复杂的城市街景道路,高速道路,经济欠发达地域的山区道路等,但是采集各种条件下的标签样本是不可能,且在以某一个特定场景道路(如城市街景道路)训练的识别系统无法直接应用于新的场景(如山区道路)。
技术实现要素:
5.为了克服前述技术问题,本发明提供的一种跨场景识别模型训练方法、跨场景道路识别方法以及装置。
6.本发明的目的至少通过如下技术方案之一实现。
7.一种跨场景识别模型训练方法,以源领域图像x
s
和源领域真实标签图y
s
以及跨场景的无标签目标领域图像x
t
作为训练数据,采用前向传导和链式反向梯度传导更新方法,分别在像素级、局部级与图像级计算输出跨场景识别的预测以及识别损失值和领域适配的预测以及领域适配损失值;分别在区域水平和样本水平联合跨场景识别和领域适配的像素级、局部级与图像级的预测以及损失值进行跨场景识别模型的迭代训练,最终得到训练完成的区域水平和样本水平跨场景识别模型。
8.进一步地,跨场景识别模型包括多尺度特征提取器g、高分辨率聚合特征提取器m、
像素级识别器f
p
、像素级领域分类器d
p
、局部级识别器f
l
、局部级领域分类器d
l
、图像级识别器f
g
以及图像级领域分类器d
g
,p表示pixel的简写,l表示local的简写,g表示global的简写;所述跨场景识别模型用于对输入图像的多尺度特征提取高分辨率聚合特征,在像素级、局部级以及图像级对高分辨率聚合特征进行识别预测以及计算识别损失值和领域分类预测以及计算领域适配损失值。
9.进一步地,多尺度特征提取器g包括深度卷积神经网络,用于对源领域样本x
s
和目标领域样本x
t
提取n个源领域和目标领域多尺度特征f
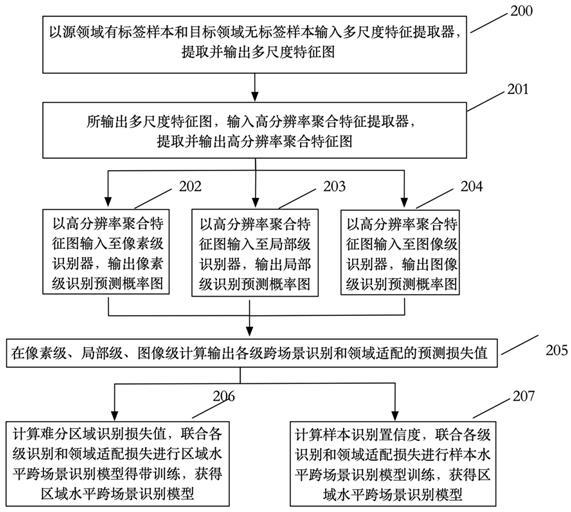
ns
和f
nt
,其中s代表源领域、t代表目标领域、n代表多尺度特征个数,源领域和目标领域多尺度特征f
ns
和f
nt
的通道量和尺度相同;高分辨率聚合特征提取器m包括多尺度特征聚合层以及空洞卷积神经网络,分别将n个源领域和目标领域多尺度特征f
ns
和f
nt
分别聚合成高分辨率源领域特征o
s
和目标领域聚合特征o
t
;多尺度特征聚合层包括动态参数变量和卷积神经网络,动态参数变量用于存储对不同尺度特征进行卷积操作的卷积神经参数,卷积神经网络以多尺度特征作为输入进行特征计算并对动态参数变量进行参数的读写;像素级识别器f
p
、局部级识别器f
l
和图像级识别器f
g
均分别包括全卷积神经网络和激活函数;将源领域和目标领域聚合特征o
s
和o
t
均输入像素级识别器f
p
、局部级识别器f
l
和图像级识别器f
g
,像素级识别器f
p
输出源领域和目标领域像素级识别预测概率图p
spixel
和p
tpixel
,局部级识别器输出源领域和目标领域局部级识别预测概率图p
slocal
和p
tlocal
,图像级识别器f
g
输出源领域和目标领域图像级识别预测概率图p
sglobal
和p
tglobal
。
10.进一步地,在像素级、局部级以及图像级对高分辨率聚合特征进行识别预测以及计算识别损失值和领域分类预测以及计算领域适配损失值,具体包括:s1、以源领域像素级识别预测概率图p
spixel
和源领域真实标签图y
s
作为输入,通过像素级识别损失函数l
pixel
输出像素级识别损失值,像素级识别函数定义为:;其中,w和h分别为概率图的宽和高;以源领域和目标领域像素级识别预测概率图p
spixel
和p
tpixel
作为输入,输入至像素级领域分类器d
p
,输出领域分类预测概率h
spixel
和h
tpixel
至像素级领域适配损失函数l
padapt
计算像素级领域适配损失值,h
spixel
和h
tpixel
分别为源领域和目标领域像素级领域分类预测概率;像素级领域适配损失函数定义为:其中,l
dp
是交叉熵损失函数,1为源领域标签,0为目标领域标签;s2、以源领域局部级识别预测概率图p
slocal
和源领域真实标签图y
s
作为输入,通过局部级识别损失函数l
local
输出局部级识别损失值,局部级识别损失函数定义为: ;其中,x={x
i
:i=1,2,
…
,n}和y={y
i
:i=1,2,
…
,n},分别以局部块方式在概率预测图p
slocal
和源领域真实标签图y
s
上获取的局部预测值,n表示局部块个数,μ
x
,μ
y
分别是局部预
测值x, y的均值和标准偏差,σ
xy
是局部预测值的协方差,c1和c2为超参;以源领域和目标领域局部级识别预测概率图p
slocal
和p
tlocal
作为输入,输入至局部级领域分类器d
l
,输出领域分类预测概率h
slocal
和h
tlocal
至局部级领域适配损失函数l
ladapt
计算局部级领域适配损失值,h
slocal
和h
tlocal
分别为源领域和目标领域局部级领域分类预测概率;局部级领域适配损失函数定义为:其中,l
dl
是交叉熵损失函数,1为源领域标签,0为目标领域标签;s3、以源领域图像级识别预测概率图p
sglobal
和源领域真实标签图y
s
作为输入,通过图像级识别损失函数l
global
输出图像级识别损失值,图像级识别损失函数定义如下: ;其中,w和h分别为概率图的宽和高;以源领域和目标领域图像级识别预测概率图p
sglobal
和p
tglobal
作为输入,输入图像级领域分类器d
g
,输出领域分类预测概率h
sglobal
和h
tglobal
至图像级领域适配损失函数l
gadapt
计算图像级领域适配损失值,h
sglobal
和h
tglobal
分别为源领域和目标领域图像级领域分类预测概率;图像级领域适配损失函数定义为:其中,l
dg
是交叉熵损失函数,1为源领域标签,0为目标领域标签。
11.进一步地,在区域水平联合跨场景识别和领域适配的像素级、局部级与图像级的预测以及损失值进行跨场景识别模型的迭代训练,指以源领域像素级、局部级以及图像级识别预测概率图p
spixel
、p
slocal
和p
sglobal
作为输入,经过难分区域训练损失函数l
region
得到难分区域训练损失值;区域水平跨场景识别模型的整体训练损失定义如下:分区域训练损失值;区域水平跨场景识别模型的整体训练损失定义如下:分区域训练损失值;区域水平跨场景识别模型的整体训练损失定义如下:其中,l
seg
为跨场景识别模型识别功能的训练损失,l
adapt
为跨场景领域适配的训练损失,l
rtotal
为区域水平跨场景识别模型的整体训练损失,此处为region的简写,l
region
为难分区域训练损失函数;难分区域训练损失函数l
region
定义为:其中,p
s
=1/3p
spixel
+3p
slocal
+1/3p
sglobal
,是难分区域概率条件超参,γ为超参;区域水平训练可以让训练过程关注到困难的、容易识别错误的像素区域,输出训练完成的区域水平跨场景识别模型;在样本水平联合跨场景识别和领域适配的像素级、局部级与图像级的预测以及损失值进行跨场景识别模型的迭代训练,以源领域和目标领域图像级识别预测概率图p
sglobal
和p
tglobal
计算每个输入到样本水平跨场景识别模型的样本的预测置信度权重z,样本水平跨场景识别模型的整体训练损失定义如下:跨场景识别模型的整体训练损失定义如下:跨场景识别模型的整体训练损失定义如下:其中,l
itotal
为样本水平跨场景识别模型的整体训练损失,此处i为instance的简写,z的计算函数定义为:zp
global
具体根据样本所属领域取值p
sglobal
和p
tglobal
,若训练样本来自源领域,则p
global
=p
sglobal
,若训练样本来自目标领域,则p
global
=p
tglobal
;c为超参;样本水平训练可以让训练过程关注到困难的、容易识别错误的图像样本,输出训练完成的样本水平跨场景识别模型。
12.跨场景道路识别方法,包括以下步骤:a1、接收目标领域待识别道路图像数据x;a2、将目标领域待识别道路图像数据x分别输入由跨场景识别模型训练方法得到的训练完成的区域水平跨场景识别模型和样本水平跨场景识别模型,分别输出区域水平预测图p
rmask
和样本水平预测图p
imask
;a3、根据区域水平预测图p
rmask
,获取区域水平连通区域个数n
r
和每个区域水平连通区域所对应面积k
r
;根据样本水平预测图p
imask
,获取样本水平连通区域个数n
i
和每个样本水平连通区域所对应面积k
i
;a4、根据区域水平和样本水平连通区域个数n
r
和n
i
以及区域水平和样本水平连通区域所对应面积k
r
和k
i
,根据判定策略,输出目标领域待识别道路图像数据i道路识别的结果。
13.进一步地,步骤a3中,采用连通区域分析算法,获取区域水平连通区域个数n
r
、每个区域水平连通区域所对应面积k
r
、样本水平连通区域个数n
i
和每个样本水平连通区域所对应面积k
i
。
14.进一步地,步骤a4中,判定策略具体如下:j1策略、若区域水平连通区域个数n
r
=1且区域水平连通区域面积k
r >样本水平连通区域所对应面积k
i
,k
min
为待识别道路图像数据x最小安全通行区域面积,则输出区域水平预测图p
rmask
为目标领域待识别道路图像数据x道路识别的结果,否则触发j2策略;j2策略、若样本水平连通区域个数n
i
= 1且样本水平连通区域面积k
i
满足k
i
>区域水平连通区域面积k
r
,则输出样本水平预测图p
smask
作为目标领域待识别道路图像数据x道路识别的结果,否则认为同时不满足j1策略和j2策略,以警告信号e作为目标领域待识别道路图像数据x道路识别的结果。
15.进一步地,k
min
= k
r
*β,β为待识别道路图像数据x分辨率与物理长度换算比,k
r
为真实道路中最小安全通行区域面积,此处为real简写,k
r = l
r
*h
r , h
r
为地面交通工具通行所需道路宽度,如左右车轮间距,l
r
为向前安全制动距离,l
r = v * t,v为当前每秒速率,t
为安全制动总时间。
16.跨场景识别模型训练装置,其特征在于,包括:训练数据输入处理单元,将源领域图像x
s
和像素级真实标签图y
s
以及不同场景的无标签目标领域图像x
t
数据输入至多尺度特征提取单元;多尺度特征提取单元,对输入的训练数据提取多个尺度的特征并输入高分辨率聚合特征提取单元;高分辨率聚合特征提取单元,对输入的多个尺度的特征聚合成高分辨率聚合特征;高分辨率聚合特征提取单元包括多尺度特征聚合模块和空洞卷积计算模块,多尺度特征聚合模块用于对多个尺度特征进行变换聚合,空洞卷积计算模块用于提高聚合特征分辨率;多级跨场景识别和领域分类预测以及损失计算单元,以高分辨率聚合特征作为输入,在像素级、局部级和图像级通过前向传导分别输出对应级别的识别概率图,进而以像素级、局部级和图像级的识别概率图、源领域样本真实标签图以及领域标签作为输入分别计算用于更新跨场景识别模型参数的像素级、局部级和图像级识别损失以及领域适配损失;区域水平跨场景识别模型联合训练单元,在区域水平联合像素级、局部级和图像级训练单元实现识别模型执行识别和跨场景领域适配的并行迭代训练,输出区域水平跨场景识别模型;样本水平跨场景识别模型联合训练单元,在样本水平联合像素级、局部级和图像级训练单元实现识别模型执行识别和跨场景领域适配的并行迭代训练,输出样本水平跨场景识别模型;模型存储单元,存储来自区域水平跨场景识别模型联合训练单元所输出的区域水平跨场景识别模型以及存储来自样本水平跨场景识别模型联合训练单元所输出的样本水平跨场景识别模型。
17.进一步地,所述多尺度特征聚合模块包括特征尺度变换处理子模块、动态参数存储子模块、卷积计算子模块和特征聚合处理子模块;特征尺度变换处理子模块用于对多个尺度的特征进行尺度缩放变换;动态参数存储子模块用于存储对不同尺度特征进行卷积操作的神经元参数;卷积计算子模块以不同尺度特征作为输入进行特征计算并对动态参数存储子模块进行神经元参数的读取和写入;特征聚合处理子模块用于完成多个特征的聚合操作。
18.跨场景道路识别装置,包括:待识别跨场景图像接收单元,用于接收目标领域待识别道路图像数据x;跨场景道路图像识别单元,用于将目标领域待识别道路图像数据x输入至区域水平和样本水平跨场景识别模型,分别输出区域水平道路识别结果和样本水平道路识别结果;连通区域计算单元,用于将区域水平和样本水平路识别结果进行连通区域计算,输出区域水平连通区域个数以及对应区域水平连通区域面积和样本水平连通区域个数以及对应样本水平连通区域面积;结果判定单元,用于判断区域水平和样本水平的连通区域个数以及区域水平和样本水平的连通区域面积是否满足判定策略,根据判定策略输出识别结果;
识别结果存储单元,用于储存来自结果判定单元输出的识别结果。
19.相比于现有技术,本发明的优点在于:本发明提供了一种跨场景识别模型训练方法,一方面,以有标签的源领域数据和无标签的目标领域数据作为输入,经过多尺度特征提取器和高分辨率聚合特征提取可获得一个高分辨率聚合特征,其可以为识别预测和领域适配提供丰富的特征信息,进一步,在像素级、局部级、图像级计算输出各级跨场景识别和领域适配的预测损失,在迭代训练中可有效提高了跨场景识别模型的预测结果在前背景识别置信度、边缘识别置信度;优选地,以区域水平联合所述各级跨场景识别和领域适配的预测损失进行跨场景识别模型训练,可以让训练过程关注到困难的、容易识别错误的像素区域,进一步提升跨场景识别性能;优选地,以样本水平联合所述各级跨场景识别和领域适配的预测损失进行跨场景识别模型训练,可以让训练过程关注到困难的、容易识别错误的图像样本,进一步提升跨场景识别性能;另一方面,以区域水平和样本水平跨场景识别模型所构建的跨场景道路识别方法,通过对区域水平和样本水平预测识别结果进行连通区域计算,根据连通区域个数和对应面积,基于判定策略输出精准且安全的识别结果,可以为智能驾驶系统在新场景下提供有效的数据支撑。
附图说明
20.图1为本发明实施例提供的跨场景识别模型示意图。
21.图2为本发明实施例提供的跨场景识别模型训练流程图。
22.图3为本发明实施例公开的一种跨场景道路识别方法流程图。
23.图4为本发明实施例公开的一种跨场景识别模型训练装置示意图。
24.图5 为本发明实施例公开的多尺度特征聚合模块示意图。
25.图6 为本发明实施例公开的一种跨场景道路识别装置示意图。
具体实施方式
26.在下面的描述中结合具体图示阐述了技术方案以便充分理解本发明申请。但是本发申请能够以很多不同于在此描述的的其他方法来实施,本领域普通技术人员在没有作出创造性劳动前提下所做类似推广实施例,都属于本发明保护的范围。
27.在本说明书中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本说明。在本说明书一个或多个实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本说明书一个或多个实施例中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
28.应当理解,尽管在本说明书一个或多个实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语,这些术语仅用与区别类似的对象,不必用于本说明书一个或多个实施例所描述特征的先后顺序或次序。此外,术语“具备”、“包含”以此相似表达,意图在于说明覆盖不排它的一个范围,例如,包含了一系列的步骤或者模块的过程、方法、系统、产品或设备不必限于详细列出的内容,而是可包括没有列出的对于这些步骤或模块所涉及的固有内容。
29.首先,对本发明一个或多个实施例设计的专业术语进行说明。
30.源领域:指具有标签且数据分布符合独立同分布的道路图像数据集,如来自城市街道的道路图像;目标领域:指没有标签且数据分布与源领域数据分布不同,如来自乡村山地的道路图像;跨场景道路识别:当基于源领域训练的道路识别无法直接应用于目标领域的道路图像识别,此时,需要基于源领域和目标领域数据对道路识别模型进行跨场景迭代训练,得到的跨场景道路识别模型可以应用于目标领域的道路识别,为智能驾驶系统在新场景中应用提供重要依据。
31.实施例1:本实施例1中所采用的是本发明提供的一种跨场景识别模型训练方法,为了方便本领域技术人员更好的理解该方法,首先对该方法重要组成部分进行详细解释:本实施例1中,训练样本包括采集来自城市街景的源领域图像和像素级真实标签图,以及采集来自偏远山区的不同场景的无标签目标领域图像,采集场景仅作为实施例1说明,本发明不做严格限定;本实施例1中,以源领域图像x
s
和源领域真实标签图y
s
以及跨场景的无标签目标领域图像x
t
作为训练数据,采用前向传导和链式反向梯度传导更新方法,分别在像素级、局部级与图像级计算输出跨场景识别的预测以及识别损失值和领域适配的预测以及领域适配损失值;分别在区域水平和样本水平联合跨场景识别和领域适配的像素级、局部级与图像级的预测以及损失值进行跨场景识别模型的迭代训练,最终得到训练完成的区域水平和样本水平跨场景识别模型。
32.本实施例1中,跨场景识别模型如图1所示,包括多尺度特征提取器g、高分辨率聚合特征提取器m、像素级识别器f
p
、像素级领域分类器d
p
、局部级识别器f
l
、局部级领域分类器d
l
、图像级识别器f
g
以及图像级领域分类器d
g
,p表示pixel的简写,l表示local的简写,g表示global的简写;所述跨场景识别模型用于对输入图像的多尺度特征提取高分辨率聚合特征,在像素级、局部级以及图像级对高分辨率聚合特征进行识别预测以及计算识别损失值和领域分类预测以及计算领域适配损失值。
33.多尺度特征提取器g包括深度卷积神经网络,多尺度特征提取器可以采用各类主流深度卷积网络,本发明不做严格先定,本实施例1中采用的为res2net50,用于对源领域样本x
s
和目标领域样本x
t
提取n个源领域和目标领域多尺度特征f
ns
和f
nt
,其中s代表源领域、t代表目标领域、n代表多尺度特征个数,源领域和目标领域多尺度特征f
ns
和f
nt
的通道量和尺度相同;本实施例1中,,分别在由res2net50网络中的block2、block3、block4、block5输出多尺度特征为(f
1s
,f
1s
)、(f
2s
,f
2s
)、(f
3s
,f
3s
)、(f
4s
,f
4s
),特征通道数分别为256、512、1024、2048,特征之间尺度比例为1、1/2、1/4、1/8;本实施例1中,高分辨率聚合特征提取器m包括两个多尺度特征聚合层以及一个空洞卷积神经网络,分别将n个源领域和目标领域多尺度特征f
ns
和f
nt
分别聚合成高分辨率源领域聚合特征o
s
和目标领域聚合特征o
t
;
本实施例1中,多尺度特征聚合层包括一个特征尺度变换函数、一个动态参数变量和多个卷积神经网络,动态参数变量用于存储对不同尺度特征进行卷积操作的卷积神经参数,卷积神经网络以多尺度特征作为输入进行特征计算并对动态参数变量进行参数的读写;本实施例1中,特征尺度变换函数采用双线性插值进行缩放计算,动态参数变量由实际源领域和目标领域尺度特征f
ns
或f
nt
通道数决定,卷积神经网络个数由源领域和目标领域多尺度特征f
ns
或f
nt
个数决定,本实施例1中为4个卷积神经网络,动态参数变量尺度可表示为(in,out,1,1),in为输入所述多尺度特征聚合层的多尺度特征通道数之和,out为所述多尺度特征聚合层卷积计算后输出多尺度特征通图道数之和,本实施例1中第一多尺度特征聚合层l1的动态参数变量尺度为(3840,1920,1,1),本实施例1中第二多尺度特征聚合层l2的动态参数变量尺度为(1920,1920,1,1)即输入输出特征通图道数不变,本实施例1中源领域多尺度特征f
ns
包含4个尺度的特征,即n=(1,2,3,4),f
1s
、f
2s
、f
3s
和f
4s
分别表示源领域第一尺度特征、第二尺度特征、第三尺度特征和第四尺度特征,对源领域多尺度特征f
ns
的聚合操作举例如下:b1、f
1s
对应的特征尺度(256,h,w)作为输入至由动态参数变量1中索引位为(1/15in, 1/15out)的参数作为卷积核conv(1)参数,输出卷积后的第一尺度降维特征f
1s_1
,其尺度为(128,h,w);按照f
2s
、f
3s
、f
4s
对应的特征尺度(高、宽)对f
1s
的特征尺度经特征尺度变换函数进行1/2、1/4、1/8倍变换后,分别作为输入至由动态参数变量1中索引位为(2/15in,2/15out)、(4/15in,4/15out)、(8/15in,8/15out)的参数作为卷积核conv(1)参数,输出卷积后的第一尺度降维特征的1/2尺度缩放特征f
1s_2
、第一尺度降维特征的1/4尺度缩放特征f
1s_3
和第一尺度降维特征的1/8尺度缩放特征f
1s_4
,f
1s_2
的尺度为(256, 1/2h, 1/2w),f
1s_3
的尺度为(512, 1/4h, 1/4w),f
1s_4
的尺度为(1024, 1/8h, 1/8w);b2、f
2s
对应的特征尺度(512,1/2h, 1/2w)作为输入至由动态参数变量1中索引位为2/15in,2/15out的参数作为卷积核conv(1)参数,输出卷积后的第二尺度降维特征f
2s_2
,其尺度为(256,1/2h, 1/2w);按照f
1s
、f
3s
、f
4s
对应的特征尺度(高、宽)对f
2s
的特征尺度经特征尺度变换函数进行2、1/2、1/4倍变换后,分别作为输入至由动态参数变量1中索引位为(1/15in, 1/15out)、(4/15in,4/15out)、(8/15in,8/15out)的参数作为卷积核conv(1)参数,输出卷积后的特征第二尺度降维特征的2倍尺度缩放特征f
2s_1
、第二尺度降维特征的1/2倍尺度缩放特征f
2s_3
和第二尺度降维特征的1/4倍尺度缩放特征f
2s_4
,f
2s_1
的尺度为(128, h, w),f
2s_3
的尺度为(512, 1/4h, 1/4w),f
2s_4
的尺度为(1024, 1/8h, 1/8w);b3、f
3s
对应的特征尺度(1024, 1/4h, 1/4w)作为输入至由动态参数变量1中索引位为(4/15in,4/15out)的参数作为卷积核conv(1)参数,输出卷积后的第三尺度降维特征f
3s_3
,其尺度为(512, 1/4h, 1/4w);按照f
1s
、f
2s
、f
4s
对应的特征尺度(高、宽)对f
3s
的特征尺度经特征尺度变换函数进行4、1/2、1/4倍变换后,分别作为输入至由动态参数变量1中索引位为(1/15in, 1/15out)、(2/15in,2/15out)、(8/15in,8/15out)的参数作为卷积核conv(1)参数,输出卷积后的特征第三尺度降维特征的4倍尺度缩放特征f
3s_1
、第三尺度降维特征的1/2倍尺度缩放特征f
3s_2
和f
3s_4
,第三尺度降维特征的1/4倍尺度缩放特征f
3s_1
的尺度为(128, h, w),f
3s_2
的尺度为(256, 1/2h, 1/2w),f
3s_4
的尺度为(1024, 1/8h, 1/8w);b4、f
4s
对应的特征尺度(2048,1/8h, 1/8w)作为输入至由动态参数变量1中索引位
为1/8h, 1/8w的参数作为卷积核conv(1)参数,输出卷积后的第四尺度降维特征f
4s_4
,其尺度为(1024, 1/8h, 1/8w);按照f
1s
、f
2s
、f
3s
对应特征尺度(高、宽)对f
4s
的特征尺度经特征尺度变换函数进行8、4、2倍变换后,分别作为输入至由动态参数变量1中索引位为(1/15in, 1/15out)、(2/15in,2/15out)、(4/15in,4/15out)的参数作为卷积核conv(1)参数,输出卷积后的特征第四尺度降维特征的8倍尺度缩放特征f
4s_1
、第四尺度降维特征的4倍尺度缩放特征和第四尺度降维特征的2倍尺度缩放特征,f
4s_1
的尺度为(128, h, w),的尺度为(256,1/2h, 1/2w),的尺度为(512, 1/4h, 1/4w);b5、将相同尺度的特征进行聚合操作和空洞卷积计算,(f
1s_1
, f
2s_1
, f
3s_1
,f
4s_1
)聚合以及空洞卷积输出特征为f
1s’,(f
1s_2
, f
2s_2
, f
3s_2
,f
4s_2
)聚合以及空洞卷积输出特征为f
2s’,(f
1s_3
, f
2s_3
, f
3s_3
,f
4s_3
)聚合以及空洞卷积输出特征为f
3s’,(f
1s_4
, f
2s_4
, f
3s_4
,f
4s_4
)聚合以及空洞卷积输出特征为f
4s’,本实施例中聚合操作为求和;b6、f
2s’、 f
3s’、 f
4s’按照f
1s’尺度分别经特征尺度变换函数进行2、4、8倍变换后,变换后的4个特征分别作为输入至由动态参数变量2中索引位为(1/15in,1/15out)、(2/15in,2/15out)、(4/15in,4/15out)、(8/15in,8/15out)的参数作为卷积核conv(1)参数进行卷积计算并进行聚合计算,输出高分辨率的聚合特征o
s
;像素级识别器f
p
、局部级识别器f
l
和图像级识别器f
g
均分别包括全卷积神经网络和激活函数;将源领域和目标领域聚合特征o
s
和o
t
均输入像素级识别器f
p
、局部级识别器f
l
和图像级识别器f
g
,像素级识别器f
p
输出源领域和目标领域像素级识别预测概率图p
spixel
和p
tpixel
,局部级识别器输出源领域和目标领域局部级识别预测概率图p
slocal
和p
tlocal
,图像级识别器f
g
输出源领域和目标领域图像级识别预测概率图p
sglobal
和p
tglobal
。
34.本实施例1中,像素级识别器f
p
,由一个全卷积网络conv(1)和sigmoid激活函数构成,用于输出像素级识别预测概率图;局部级识别器f
l
,由一个全卷积网络conv(1)和sigmoid激活函数构成,用于输出局部级识别预测概率图;图像级识别器f
g
,由一个全卷积网络conv(1)和sigmoid激活函数构成,用于输出图像级识别预测概率图;像素级领域分类器d
p
,由两个全卷积网络conv(1和sigmoid激活函数组成,用于输出像素级的领域分类预测;局部级领域分类器d
l
,由两个全卷积网络conv(1和sigmoid激活函数组成,用于输出局部级的领域分类预测;图像级领域分类器d
g
,由两个全卷积网络conv(1和sigmoid激活函数组成,用于输出图像级的领域分类预测。
35.本实施例1中,跨场景识别模型训练如图2所示,具体如下:步骤200、以源领域样本x
s
和目标领域样本x
t
输入多尺度特征提取器,输出输出多尺度特征为(f
1s
,f
1s
)、(f
2s
,f
2s
)、(f
3s
,f
3s
)、(f
4s
,f
4s
);步骤201、将步骤200输出特征输入高分辨率聚合特征提取器,输出源领域和目标领域高分辨率聚合特征o
s
和o
t
;
步骤202、将步骤201输出的源领域和目标领域聚合特征o
s
和o
t
作为输入,经过像素级识别器f
p
后输出源领域和目标领域像素级识别预测概率图p
spixel
和p
tpixel
;步骤203、将步骤201输出的源领域和目标领域聚合特征o
s
和o
t
作为输入,经过局部级识别器f
l
输出源领域和目标领域局部级识别预测概率图p
slocal
和p
tlocal
;步骤204、将步骤201输出的源领域和目标领域聚合特征o
s
和o
t
作为输入,经过图像级识别器f
g
输出源领域和目标领域图像级识别预测概率图p
sglobal
和p
tglobal
;步骤205、在像素级、局部级以及图像级计算输出各级跨场景识别和领域适配的预测损失,具体如下:步骤205
‑
1、以步骤202输出的源领域像素级识别预测概率图p
spixel
作为输入,通过像素级识别损失函数输出像素级识别损失值,像素级识别函数函数定义如下:;其中,y
s
是源领域样本像素级真实标签图,w,h为概率图的宽、高;步骤205
‑
2、以步骤202输出的源领域和目标领域像素级识别预测概率图p
spixel
和p
tpixel
作为输入,输入至像素级领域分类器d
p
,作用是在像素级实现源领域和目标领域的领域分类预测,输出领域分类预测概率h
spixel
和h
tpixel
至像素级领域适配损失函数l
padapt
计算像素级领域适配损失值,h
spixel
和h
tpixel
分别为源领域和目标领域分类预测概率,像素级领域适配损失函数定义如下:其中,l
dp
是像素级交叉熵损失函数,1为源领域标签,0为目标领域标签;步骤205
‑
3、以步骤203输出的源领域局部级识别预测概率图p
slocal
作为输入,通过局部级识别损失函数输出局部级识别损失值,局部级识别损失函数定义如下:;其中,x={x
i
:i=1,2,
…
,n}和y={y
i
:i=1,2,
…
,n},分别以局部块方式在所述概率预测图p
slocal
和所述源领域真实标签图y
s
上获取的局部预测值,n表示局部块个数,μ
x
,μ
y
分别是所述局部预测值x, y的均值和标准偏差,σ
xy
是所述局部预测值的协方差,c1和c2为超参;步骤205
‑
4、以步骤203输出的源领域和目标领域局部级识别预测概率图p
slocal
和p
tlocal
作为输入,输入至局部级领域分类器d
l
,作用是在局部级实现源领域和目标领域的领域分类预测,输出领域分类预测概率h
slocal
和h
tlocal
至局部级领域适配损失函数l
ladapt
计算局部级领域适配损失值,h
slocal
和h
tlocal
分别为源领域和目标领域局部级域分类预测概率;局部级领域适配损失函数定义如下:其中,l
dl
是局部级交叉熵损失函数,1为源领域标签,0为目标领域标签;步骤205
‑
5、以步骤204输出的源领域图像级识别预测概率图p
sglobal
作为输入,通过图像级识别损失函数输出图像级识别损失值,图像级识别损失函数定义如下:
;其中,p
sglobal
为图像级识别预测概率图,y
s
为源领域真实标签图,w和h分别为概率图的宽和高;步骤205
‑
6、以步骤204输出的源领域和目标领域像图像级识别预测概率图p
sglobal
和p
tglobal
作为输入,输入图像级领域分类器,作用是在图像级实现源领域和目标领域的领域分类预测,输出领域分类预测概率h
sglobal
和h
tglobal
至图像级领域适配损失函数l
gadapt
计算图像级领域适配损失值,h
sglobal
和h
tglobal
分别为源领域和目标领域图像级领域分类预测概率;图领域适配损失函数定义如下:其中,l
dg
是交叉熵损失函数,1为源领域标签,0为目标领域标签;步骤206、将步骤202、步骤203以及步骤204输出的源领域像素级、局部级以及图像级识别预测概率图p
spixel
、p
slocal
和p
sglobal
作为输入,经过难分区域训练损失函数l
region
得到损失值,在区域水平联合步骤205中的各级跨场景识别和领域适配的预测损失进行跨场景识别模型训练,区域水平跨场景识别模型的整体训练损失定义如下:识别模型训练,区域水平跨场景识别模型的整体训练损失定义如下:识别模型训练,区域水平跨场景识别模型的整体训练损失定义如下:其中,l
seg
为跨场景识别模型识别功能的训练损失,l
adapt
为跨场景领域适配的训练损失,l
rtotal
为区域水平跨场景识别模型的整体训练损失(此处为region的简写),l
region
为难分区域训练损失定义如下:其中,p
s
=1/3p
spixel
+3p
slocal
+1/3p
sglobal
,是难分区域概率条件超参,γ为超参;本实施例中ρ=0.5,γ = 0.25,所述区域水平训练可以让训练过程关注到困难的、容易识别错误的像素区域,输出训练完成的区域水平跨场景识别模型;步骤207、将步骤204输出的图像级识别预测概率图p
sglobal
和p
tglobal
计算每个输入到样本水平跨场景识别模型的样本的预测置信度权重z,在样本水平联合步骤205中的各级跨场景识别和领域适配的预测损失进行样本水平跨场景识别模型训练,样本水平跨场景识别模型的整体训练损失定义如下:别模型的整体训练损失定义如下:别模型的整体训练损失定义如下:
其中,l
stotal
为样本水平跨场景识别模型的整体训练损失(此处s为sample的简写),z的计算函数定义为:z在训练过程中惩罚每个样本对应的损失上,p
global
具体根据样本所述领域取值p
sglobal
和p
tglobal
,若训练样本来自源领域p
global
=p
sglobal
,若训练样本来自目标领域,则p
global
=p
tglobal
;c为超参,所述样本水平训练可以让训练过程关注到困难的、容易识别错误的图像样本,输出训练完成的样本水平跨场景识别模型。
36.本实施例1中,在进行跨场景识别模型的迭代训练过程中,采用前向传导和链式反向梯度传导更新方法对模型参数进行更新,其中对识别模型参数更新所涉及的梯度更新采用随机梯度下降方法,对领域分类器d
p
、d
l
、d
g
参数更新所涉及的梯度更新采用自适应矩估计方法;优选地,分别在区域水平和样本水平联合像素级、局部级、图像级三个级别实现了跨场景识别模型的训练过程,基于步骤206区域水平训练输出的识别模型可以在跨场景识别任务中更加关注到困难的、容易识别错误的像素区域,基于步骤207样本水平训练输出的识别模型可以在跨场景识别任务中更加关注到困难的、容易识别错误的图像样本;优选地,本发明实施例1在区域水平和样本水平联合像素级、局部级、图像级三个级别训练得到的区域水平和样本水平跨场景识别模型可以应用新领域的识别任务,例如将其设置为一款车载应用,以本实施例1所述目标领域为新场景,利用区域水平和样本水平跨场景识别模型可以可靠地执行偏远山区的道路识别;下面可通过实施例2进行描述。
37.实施例2:本发明实施例2提供了一种跨场景道路识别方法,该跨场景道路识别方法采用的前述实施例1提供的训练方法得到的区域水平和样本水平跨场景识别模型;以图3所示,一种跨场景道路识别方法,包括以下步骤:步骤301、接收目标领域待识别道路图像数据x;步骤302、将目标领域待识别道路图像数据x作为输入,输入至区域水平跨场景识别模型中,输出区域水平预测图p
rmask
;步骤303、将目标领域待识别道路图像数据x作为输入,输入至样本水平跨场景识别模型中,输出样本水平预测图p
smask ;步骤304、以步骤302输出的区域水平预测图p
rmask
作为输入,计算单连通区域,输出区域水平连通区域个数n
r
,以及每个区域水平连通区域所对应面积k
r
;步骤305、以步骤303输出的样本水平预测图p
imask
作为输入,计算单连通区域,输出样本水平连通区域个数n
i
,以及每个样本水平连通区域所对应面积k
i
;步骤306、以步骤304和305输出的区域水平和样本水平连通区域个数n
r
和n
i
以及区域水平和样本水平连通区域所对应面积k
r
和k
i
作为输入,根据判定策略,输出目标领域待识别道路图像数据i道路识别的结果。
38.采用连通区域分析算法,获取区域水平连通区域个数n
r
、每个区域水平连通区域所对应面积k
r
、样本水平连通区域个数n
i
和每个样本水平连通区域所对应面积k
i
。
39.本实施例2中,采用的连通区域分析算法为two
‑
pass方法。
40.本实施例2中的判定策略,用于判定输出哪类结果,具体如下:j1策略、若区域水平连通区域个数n
r
=1且区域水平连通区域面积k
r >样本水平连通区域所对应面积k
i
,k
min
为待识别道路图像数据x最小安全通行区域面积,则输出区域水平预测图p
rmask
为目标领域待识别道路图像数据i道路识别的结果,否则触发j2策略;j2策略、若样本水平连通区域个数n
i
= 1且样本水平连通区域面积k
i
满足k
i
>区域水平连通区域面积k
r
,则输出样本水平预测图p
smask
作为目标领域待识别道路图像数据i道路识别的结果,否则认为同时不满足j1策略和j2策略,以警告信号e作为目标领域待识别道路图像数据i道路识别的结果。
41.前述步骤302、303中,根据区域水平和样本水平跨场景识别模型首先分别会得到待识别图像i在像素级、局部级、图像级的预测概率图p
rpixel
、p
rlocal
和p
rglobal
和p
spixel
、p
slocal
和p
sgloba
,此处r表示来自区域水平跨场景识别模型的输出预测,s表示来自样本水平跨场景识别模型的输出预测,本实施例2中前述步骤302、303的预测图计算方式为:p
rmask =1/3p
rpixell
+1/3p
rlocal
+1/3p
rglobal
,p
smask =1/3p
spixell
+1/3p
slocal
+1/3p
sglobal
;前述步骤304和步骤305中,对预测图p
rmask
,p
imask
计算单连通区域所采用方法可以为任意的连通区域方法,本发明不做严格限定。
42.前述j1策略中,k
min
= k
r
*β,β为待识别道路图像数据x分辨率与物理长度换算比,k
r
为真实道路中最小安全通行区域面积,此处为real简写,k
r = l
r
*h
r , h
r
为地面交通工具通行所需道路宽度,如左右车轮间距,l
r
为向前安全制动距离,l
r = v * t,v为当前每秒速率,t为安全制动总时间。
43.如表1所示,本实施例以有标签源领域采集来自城市街景以及无标签目标领域图像采集来自偏远山区作为训练数据,以所述训练方法得到的区域水平和样本水平的跨场景识别模型,通过所述跨场景道路识别方法,跨场景道路识别准确率有显著的提升。
44.表1方法山区道路识别结果仅源领域训练模型42.06%本实施例72.56%实施例3:本实施例3公开了一种跨场景识别模型训练装置,如图4所示,包括:训练数据输入处理单元41,将源领域图像x
s
和像素级真实标签图y
s
以及不同场景的无标签目标领域图像x
t
数据输入至多尺度特征提取单元42;多尺度特征提取单元42,对输入的训练数据提取多个尺度的特征并输入高分辨率聚合特征提取单元43;高分辨率聚合特征提取单元43,对输入的多个尺度的特征聚合成高分辨率聚合特征;本实施例3中,高分辨率聚合特征提取单元包括第一多尺度特征聚合模块431、空洞卷积计算模块432和第二多尺度特征聚合模块433,多尺度特征聚合模块用于对多个尺度特征进行变换聚合,空洞卷积计算模块用于提高聚合特征分辨率;多级跨场景识别和领域分类预测以及损失计算单元44,以高分辨率聚合特征作为输入,在像素级、局部级和图像级通过前向传导分别输出对应级别的识别概率图,进而以像素级、局部级和图像级的识别概率图、源领域样本真实标签图以及领域标签作为输入分别
计算用于更新跨场景识别模型参数的像素级、局部级和图像级识别损失以及领域适配损失;区域水平跨场景识别模型联合训练单元45,在区域水平联合像素级、局部级和图像级训练单元实现识别模型执行识别和跨场景领域适配的并行迭代训练,输出区域水平跨场景识别模型;样本水平跨场景识别模型联合训练单元46,在样本水平联合像素级、局部级和图像级训练单元实现识别模型执行识别和跨场景领域适配的并行迭代训练,输出样本水平跨场景识别模型;模型存储单元47,存储来自区域水平跨场景识别模型联合训练单元45所输出的区域水平跨场景识别模型以及存储来自样本水平跨场景识别模型联合训练单元46所输出的样本水平跨场景识别模型。
45.本实施例3中,第一多尺度特征聚合模块431和第二多尺度特征聚合模块433均包括特征尺度变换处理子模块、动态参数存储子模块、卷积计算子模块和特征聚合处理子模块;特征尺度变换处理子模块用于对多个尺度的特征进行尺度缩放变换;动态参数存储子模块用于存储对不同尺度特征进行卷积操作的神经元参数;卷积计算子模块以不同尺度特征作为输入进行特征计算并对动态参数存储子模块进行神经元参数的读取和写入;特征聚合处理子模块用于完成多个特征的聚合操作。
46.本实施例3中,所述多级跨场景识别和领域分类预测以及损失计算单元44,具体包括:像素级训练模块,所述像素级训练模块包括像素级识别预测子模块、像素级识别损失函数计算子模块、像素级领域预测子模块、像素级领域适配损失函数计算子模块,所述像素级识别预测子模块以每个训练样本的高分辨率聚合特征作为输入,输出像素级识别预测概率图,像素级识别损失函数计算子模块以像素级识别预测概率图和源领域样本真实标签图作为输入计算像素级识别损失值,像素级领域预测子模块以像素级识别预测概率图作为输入,输出像素级领域预测概率图,像素级领域适配损失函数计算子模块以像素级领域预测概率图和领域标签作为输入计算素级领域适配损失值;局部级训练模块,所述局部级训练模块包含局部级识别预测子模块、局部级识别损失函数计算子模块、局部级领域预测子模块、局部级领域适配损失函数计算子模块,所述局部级识别预测子模块以每个训练样本的高分辨率聚合特征作为输入,输出局部级识别预测概率图,所述局部级识别预测概率图和源领域样本真实标签图以网格形式进行取值作为输入至所述局部级识别损失函数计算子模块计算局部级识别损失值,局部级领域预测子模块以局部级识别预测概率图作为输入,输出局部级领域预测概率图,局部级领域适配损失函数计算子模块以局部级领域预测概率图和领域标签作为输入计算局部级域适配损失值;图像级训练模块,所述图像级训练模块包含图像级识别预测子模块、图像级识别损失函数计算子模块、图像级领域预测子模块、图像级领域适配损失函数计算子模块,所述图像级识别预测子模块以每个训练样本的高分辨率聚合特征作为输入,输出图像级识别预测概率图,所述图像级识别预测概率图和源领域样本真实标签图作为输入至所述局部级识别损失函数计算子模块计算图像级识别损失值,图像级领域预测子模块以图像级识别预测
概率图作为输入,输出图像级领域预测概率图,图像级领域适配损失函数计算子模块以图像级领域预测概率图和领域标签作为输入计算图像级域适配损失值;本实施例3中,所述区域水平跨场景识别模型联合训练单元45,具体包括:难分区域损失函数计算模块,用于以源领域像素级、局部级以及图像级识别预测概率图作为输入,输出难分区域训练损失值;参数更新模块,用于以所述难分区域训练损失值、像素级、局部级、图像级识别损失和领域适配损失作为输入计算区域水平跨场景识别模型联合训练迭代过程中参数更新所需梯度值;本实施例3中,所述样本水平跨场景识别模型联合训练单元46,具体包括:难分样本损失函数计算模块,用于以源领域像素级、局部级以及图像级识别预测概率图作为输入,输出难分样本训练损失值;参数更新模块,用于以所述难分样本训练损失值、像素级、局部级、图像级识别损失和领域适配损失作为输入计算样本水平跨场景识别模型联合训练迭代过程中参数更新所需梯度值。
47.实施例4:本实施例4公开了一种跨场景道路识别装置,参见图6所示,包括:待识别跨场景图像接收单元61,用于接收目标领域待识别道路图像数据i;跨场景道路图像识别单元62,用于将目标领域待识别道路图像数据i输入至区域水平和样本水平跨场景识别模型,分别输出区域水平道路识别结果和样本水平道路识别结果;连通区域计算单元63,用于将区域水平和样本水平路识别结果进行连通区域计算,输出区域水平连通区域个数以及对应区域水平连通区域面积和样本水平连通区域个数以及对应样本水平连通区域面积;结果判定单元64,用于判断区域水平和样本水平的连通区域个数以及区域水平和样本水平的连通区域面积是否满足判定策略,根据判定策略输出识别结果;识别结果存储单元65,用于储存来自结果判定单元64输出的识别结果。
48.需要说明的是,对于实施例中跨场景识别模型训练方法、跨场景道路识别方法、实施例,为了简便描述,故将其都表述为一系列的步骤或操作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本技术,某些步骤或操作可以采用其它顺序或者同时进行。
49.以上公开的本技术优选实施例只是用于帮助理解本发明及核心思想。对于本领域的一般技术人员,依据本发明的思想,在具体应用场景和实施操作上均会有改变之处,本说明书不应理解对本发明的限制。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1